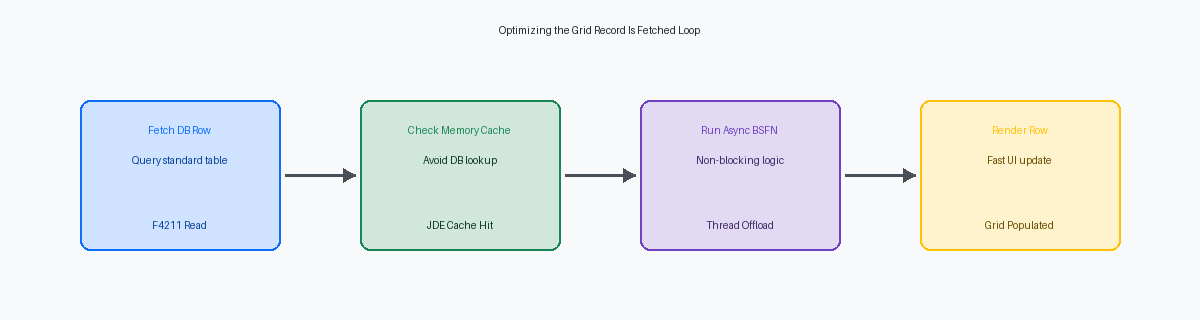
Wenn ein benutzerdefiniertes Grid in einer Anwendung wie P554210 mehr als zehn Sekunden benötigt, um 500 Datensätze zu laden, geben Basis-Teams sofort Datenbankindizes oder WebLogicEin Java-basierter Anwendungsserver von Oracle, der als Plattform für JD Edwards Webumgebungen dient. JVM-Heap-GrößenDer zugewiesene Arbeitsspeicher für die Java Virtual Machine, in der der JDE-Webserver läuft. die Schuld. In der überwiegenden Mehrheit der Performance-Audits, die unter EnterpriseOne 9.2 durchgeführt wurden, ist die Infrastruktur völlig in Ordnung; der Engpass sind synchrone Event Rules (ER)Die proprietäre Skriptsprache von JD Edwards, mit der Geschäftslogik in Anwendungen und Berichten definiert wird., die für jede einzelne Zeile auf dem JAS-ServerJava Application Server; die Komponente in JD Edwards, die die Weboberfläche für den Browser bereitstellt. ausgeführt werden. Um Antwortzeiten im Sub-Sekunden-Bereich zu erreichen, muss man von der Schuldzuweisung an die Infrastruktur wegkommen und sich auf das JD Edwards APPL Grid Performance Tuning für große Datensätze innerhalb der JDE-Runtime-Engine selbst konzentrieren.
Eine effektive Grid-Optimierung beruht auf der Eliminierung des Overheads durch iterative Datenbank-Roundtrips und synchrone Business Function (BSFN)Wiederverwendbare Programmodule in JD Edwards, die in C oder Event Rules geschrieben sind, um komplexe Logik auszuführen. Ausführungen. Durch die Verlagerung schwerer Validierungslogik vom Event Grid Record Is Fetched auf asynchrone Tabellen-I/OBezeichnet Lese- und Schreibvorgänge (Input/Output) in der Datenbank. oder Hintergrundverarbeitung können Entwickler Datenbankaufrufe um 70 % bis 80 % reduzieren. Wenn Ihr Entwicklungsteam immer noch prozedurale ER-Schleifen schreibt, die für jede Grid-Zeile dieselbe Konstanten-Tabelle abrufen, verschlechtern sie die Benutzererfahrung massiv.
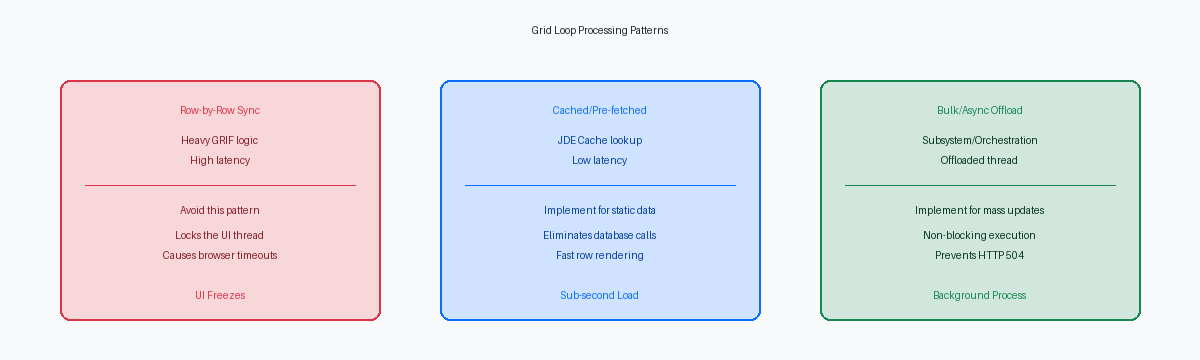
Die Grid-Schleifen-Falle und Zeile-für-Zeile-Ausführung
Technische Audits von benutzerdefinierten APPLs offenbaren häufig hunderte Zeilen von Event Rules, die direkt in das Event Grid Record Is Fetched (GRIF) eingefügt wurden. Dieses Event wird synchron für jede einzelne abgerufene Datenbankzeile ausgelöst, bevor diese auf dem Bildschirm gerendert wird. Wenn ein Benutzer 500 Verkaufsauftragszeilen in einer benutzerdefinierten Version von P4210 abfragt, ist die JAS-Engine gezwungen, diesen gesamten ER-Block 500 Mal hintereinander auszuführen, bevor die Daten im Browser angezeigt werden.
Die Performance-Einbußen potenzieren sich, wenn Entwickler schwere Master Business Functions oder benutzerdefinierte C-BSFNsIn der Programmiersprache C geschriebene Business Functions für performante Logikausführung in JD Edwards. wie GetAuditInfo (B9800100) innerhalb dieser Schleife platzieren. Was ein sauberer SQL-Datenbankabruf von zwei Sekunden sein sollte, degradiert schnell zu einem Browser-Freeze von fast einer Minute. Diese Latenz wird durch ständige Netzwerk-Roundtrips zwischen dem HTML-Server und dem Enterprise-Logic-Server verursacht, da jede einzelne Zeile ihre eigene Roundtrip-SerialisierungDer Prozess der Umwandlung von Datenstrukturen in ein Format, das über ein Netzwerk übertragen werden kann. erfordert, um die Geschäftslogik auszuführen.
Um diesen Engpass zu beheben, verschieben Sie nicht essenzielle Validierungslogik vollständig aus dem GRIF-Event. Die Verlagerung visueller Formatierungen in das Event Write Grid Line-Before stellt sicher, dass JDE nur die 10 bis 20 Zeilen verarbeitet, die tatsächlich im aktuellen Grid-Seiten-ViewportDer aktuell sichtbare Bereich einer Webseite oder Anwendung im Browserfenster. sichtbar sind. Bei komplexen Berechnungen kann deren asynchrone Ausführung oder die Verschiebung bis zur Auswahl einer Zeile die anfänglichen Ladezeiten um 75 % bis 80 % reduzieren.
Wenn Sie Werte beim Abrufen berechnen müssen, konfigurieren Sie die Grid-Eigenschaften auf Page-at-a-TimeEine Einstellung, bei der Daten blockweise geladen werden, anstatt den gesamten Datensatz auf einmal abzurufen.-Verarbeitung, anstatt den gesamten Datensatz zu laden. Diese Änderung beschränkt die synchrone GRIF-Ausführung auf die aktive Grid-Seitengröße und verhindert, dass der Web-Client bei Tabellen mit zehntausenden Datensätzen kapituliert.

Optimierung der Datenselektion durch selektives Lesen
Einem Benutzer zu erlauben, eine ungefilterte Suche in einem Find/Browse-Formular über eine F4211- oder F0911-Tabelle mit mehreren Millionen Zeilen auszuführen, stellt ein erhebliches Betriebsrisiko dar. Die resultierende offene SQL-Abfrage zwingt den JAS-Server, Heap-Speicher für hunderttausende Grid-Zeilen zuzuweisen, was einen Java OutOfMemoryErrorEin Fehler, der auftritt, wenn die Java Virtual Machine nicht mehr genügend Arbeitsspeicher für neue Objekte zuweisen kann. auslöst und die aktive HTML-Sitzung zum Absturz bringt. In einem kürzlich durchgeführten technischen Audit lösten wir ein Problem, bei dem eine Handvoll gleichzeitiger offener Abfragen auf der F4211 den JVM-Speicher erschöpften und eine gesamte HTML-Instanz lahmlegten, was Dutzende aktiver Benutzer beeinträchtigte.
Um Full Table ScansEin Datenbankvorgang, bei dem jede Zeile einer Tabelle gelesen wird, was bei großen Datenmengen sehr langsam ist. bei Tabellen mit mehr als mehreren Millionen Zeilen zu verhindern, müssen Entwickler mindestens ein indiziertes Filterfeld in Find/Browse-Formularen erzwingen. Das Setzen der Eigenschaft "Filter Criteria" auf "Equal" bei einer indizierten Spalte wie SDKCOO oder SDDOCO zwingt den Datenbank-Optimizer, einen Index-SeekEine effiziente Suchmethode der Datenbank, die gezielt über einen Index auf Daten zugreift. anstelle eines kostspieligen Table-Scans durchzuführen. Wenn der Benutzer diese Pflichtfelder leer lässt, sollte die Anwendung die Abfrage programmatisch im "Button Clicked"-Event des Find-Buttons blockieren, bevor die Datenbank erreicht wird.
Wenn statische Filter nicht ausreichen, schränkt die dynamische Verwendung der Systemfunktion Set Selection in der Event-Sequenz "Clear Select" und "Set Selection" die WHERE-KlauselEin Teil eines SQL-Befehls, der bestimmt, welche Datensätze basierend auf bestimmten Kriterien ausgewählt werden sollen. ein, bevor das Grid seinen primären Fetch ausführt. Entscheidend ist, dass die Grid-Eigenschaften auf "Page-at-a-Time"-Verarbeitung konfiguriert sind, anstatt alle Datensätze auf einmal in den Speicher zu laden. Dies begrenzt den anfänglichen Datenbank-Fetch auf die Grid-Seitengröße – typischerweise 10 bis 50 Zeilen – und verhindert Speichererschöpfung bei gleichzeitiger Beibehaltung von Antwortzeiten im Sub-Sekunden-Bereich.
Die Kosten repetitiver BSFN- und Datenbankaufrufe
Eine einzelne BSFN-Ausführung, die scheinbar vernachlässigbare 10 Millisekunden dauert, summiert sich zu zehn Sekunden reiner Latenz, wenn sie sequenziell über ein Grid mit 1.000 Zeilen ausgeführt wird. Diese Latenz-Kumulierung tritt häufig im Event Grid Record is Fetched auf, wo Entwickler routinemäßig Standard- oder benutzerdefinierte BSFNs platzieren, um Hilfsbeschreibungen abzurufen oder Codes pro Zeile zu validieren. Die Performance-Verschlechterung eskaliert, wenn diese BSFNs innerhalb der Schleife wiederholt Tabellen-Handles öffnen und schließen, wie z. B. beim Aufruf von 'F0005 Get UDCUser Defined Codes; anpassbare Nachschlagetabellen in JD Edwards für vordefinierte Werte wie Statuscodes.', um UDC-Beschreibungen für jede einzelne Zeile abzurufen.
Um tausende redundante Datenbank-Select-Operationen zu eliminieren, sollten Entwickler statische oder semi-statische Validierungsdaten mithilfe von JDE Cache-APIsProgrammierschnittstellen zur temporären Speicherung von Daten im schnellen Arbeitsspeicher, um langsame Datenbankzugriffe zu vermeiden. wie jdeCacheInit während des Events Dialog is Initialized im Speicher zwischenspeichern, bevor das Grid geladen wird. Anstatt die Datenbank zu belasten oder F0005-Tabellenlesevorgänge tausende Male für einen großen Grid-Load auszuführen, kann eine benutzerdefinierte C-BSFN die erforderlichen UDC-Werte oder Cross-Reference-Datensätze einmalig in einen speicherresistenten Cache laden. Speicher-Lookups im Sub-Millisekunden-Bereich ersetzen dann Festplatten-I/O und Netzwerk-Hops, wodurch die Verarbeitungszeit pro Zeile von 12 Millisekunden auf unter eine Millisekunde sinkt.
Wenn komplexe Berechnungen unvermeidbar sind, wechseln Sie von der Zeile-für-Zeile-Ausführung zur Batch-Verarbeitung. Übergeben Sie vorab abgerufene Arrays oder Datenstrukturen, die alle Schlüsselfelder enthalten, in einem einzigen Memory-Mapped-Aufruf an eine benutzerdefinierte C-Business-Function, anstatt die BSFN einmal pro Grid-Zeile aufzurufen. Diese strukturelle Änderung ermöglicht es der BSFN, eine einzige Datenbank-Open-Operation durchzuführen, Bulk-Fetches auszuführen, die Logik im RAM zu verarbeiten und den Datensatz an die Anwendungsschicht zurückzugeben. Die Implementierung dieses Musters auf einem hochvolumigen Bildschirm für die Bestandsverfügbarkeit kann Transaktionszeiten um 80 % bis 85 % senken und die Ladezeiten von fünfzehn Sekunden auf unter drei Sekunden reduzieren.
Grid-Buffer-Manipulation und Speicher-Footprints
Wir analysieren häufig Produktionsumgebungen, in denen die JVM des HTML-Servers während Spitzenzeiten im Versand oder in der Fakturierung mit OutOfMemoryError-Exceptions abstürzt. Der Übeltäter ist typischerweise ein benutzerdefiniertes Power Form oder eine stark modifizierte P42101 mit Grids, die über 100 Spalten enthalten. Jede einzelne Zeile, die in diese breiten Grids geladen wird, instanziiert einen massiven Satz von Grid-BufferEin temporärer Speicherbereich für die Daten einer Tabellenzeile während der Verarbeitung in JD Edwards.-Variablen im JAS-Memory-Heap. Dies multipliziert den Speicherbedarf, wenn fünfzig oder mehr gleichzeitige Benutzer große Datensätze abfragen.
Entwickler verschärfen diesen Druck auf den Speicher, indem sie Systemfunktionen wie 'Copy Grid Row To Grid Buffer' innerhalb der Events Grid Record Is Fetched oder Write Grid Line-Before verwenden. Diese Systemfunktion referenziert nicht lediglich vorhandenen Speicher; sie dupliziert die gesamte 100-spaltige Datenstruktur innerhalb des JAS-Memory-Heaps. Wenn dies sequenziell über einen Fetch von 1.000 Zeilen ausgeführt wird, löst diese redundante Allokation aggressive JVM-Garbage-CollectionEin automatischer Prozess in Java, der nicht mehr benötigten Arbeitsspeicher identifiziert und wieder freigibt.-Pausen aus, die den Web-Client einfrieren.
Ein häufiger Fehler ist das Ausblenden ungenutzter Spalten über Event Rules mit der Systemfunktion Set Grid Column Attribute. Das visuelle Verstecken einer Spalte verhindert nicht, dass der JAS-Server diese Daten abruft, verarbeitet und serialisiert. Das vollständige Löschen dieser toten Spalten aus dem Grid-Layout, anstatt sie per ER zu verstecken, reduziert die Größe der Serialisierungs-PayloadDie eigentlichen Nutzdaten, die bei einer Netzwerkübertragung zwischen Client und Server gesendet werden. um mehr als die Hälfte und stabilisiert das Speicherprofil des Webservers. Beispielsweise senkt die Reduzierung eines 120-spaltigen Grids auf die 20 tatsächlich benötigten Felder den Speicher-Overhead pro Zeile um etwa 80 %.
Umgang mit großen Datensätzen durch asynchrone Verarbeitung
Eine hängende Web-Sitzung während des Speicherns eines Grids mit 500 Zeilen wird typischerweise durch die synchrone Ausführung schwerer Validierungslogik verursacht. Wenn eine benutzerdefinierte Validierungs-BSFN in die Grid-Events Row Exit & Changed - Asynchronous oder Row Is Selected platziert wird, müssen Entwickler diese BSFN in den Event-Rule-Eigenschaften explizit als asynchron kennzeichnen. Diese Konfigurationsoption weist den HTML-Server an, die Kontrolle sofort an die Präsentationsschicht zurückzugeben, was verhindert, dass die Benutzeroberfläche blockiert, während der Enterprise-Server die Geschäftslogik in einem parallelen Thread verarbeitet.
Um schwere Berechnungen in einem großen Grid zu verarbeiten, ohne die Benutzererfahrung zu beeinträchtigen, verlagern Sie die Ausführung in das Event Post Button Clicked einer versteckten Schaltfläche. Bei der Bestandsallokations-APPL eines Distributionskunden haben wir Inline-Grid-Berechnungen durch ein System ersetzt, bei dem der "OK"-Button modifizierte Zeilen in einen Memory-Cache schreibt und dann programmatisch einen versteckten "Process"-Button klickt. Die Ausführung der Bulk-Berechnungslogik im Event "Post Button Clicked" dieses versteckten Steuerelements stellt sicher, dass der primäre Grid-Thread reaktionsschnell bleibt und die synchronen Verarbeitungsfallen vermieden werden, die Browser-Latenzen auslösen.
Wenn ein Benutzer versucht, mehr als 200 Grid-Zeilen gleichzeitig zu aktualisieren, ist die Verarbeitung dieser Änderungen innerhalb des interaktiven APPL-Threads ein architektonisches Anti-Pattern. Ein effizienterer Ansatz besteht darin, die modifizierten Grid-Daten in eine benutzerdefinierte Staging-Tabelle zu schreiben und sofort ein Subsystem-UBEEin Hintergrundprozess in JD Edwards, der dauerhaft läuft und Aufgaben sofort nach deren Übermittlung verarbeitet. (wie einen benutzerdefinierten Treiber der R55-Serie) auszulösen oder eine AISApplication Interface Services; eine Schnittstelle, die JDE-Logik als REST-Services für externe Apps bereitstellt.-basierte OrchestrationEin automatisierter Workflow in JD Edwards, der mehrere Schritte, Dienste und Datenquellen miteinander verbindet. aufzurufen, um den Batch im Hintergrund zu verarbeiten. Dieser Wechsel hält den interaktiven Runtime-Thread sauber und eliminiert die HTTP 504 Gateway-Timeout-Fehler, die typischerweise auftreten, wenn WebLogic oder ein F5-Load-BalancerEin Gerät oder Dienst, der eingehenden Netzwerkverkehr auf mehrere Server verteilt, um die Last zu optimieren. eine Verbindung nach dem Standard-Schwellenwert von 120 Sekunden beendet.
Diagnose-Tools zur Identifizierung von Grid-Engpässen
Datenbankadministratoren präsentieren häufig einen SQL-AusführungsplanDie Strategie, die das Datenbankmanagementsystem wählt, um eine Abfrage am effizientesten auszuführen. im Sub-Millisekunden-Bereich, um den Zustand der Datenbank zu beweisen, doch ein Standard-Grid wie P42101 oder P4312 kann immer noch über zehn Sekunden benötigen, um 200 Zeilen zu rendern. Diese Diskrepanz tritt auf, weil Metriken auf Datenbankebene die Latenz auf Anwendungsebene übersehen, die durch die Ausführung von Event Rules (ER) eingeführt wird. Wenn ER bei Events wie Grid Record Is Fetched ausgeführt wird, findet die Zeit für Variablenzuweisungen und Tabellen-I/O vollständig außerhalb der Sichtweite der Datenbank-Engine statt.
Isolieren Sie diese Latenz, indem Sie das jas.log mit einer gezielten Call-StackEine Liste, die die Reihenfolge der aufgerufenen Funktionen oder Programmschritte während der Ausführung anzeigt.-Analyse im jdedebug.log auf dem Enterprise-Server korrelieren. Das jas.log erfasst den genauen Zeitstempel, zu dem der HTML-Server die Grid-Daten anfordert, während das jdedebug.log die exakten Millisekunden-Kosten jeder durch die ER ausgelösten BSFN-Ausführung verfolgt. Das Parsen dieser Logs offenbart den kumulativen Overhead von hunderten sequenziellen F4101-Abrufen, die pro Grid-Zeile auftreten.
Verwenden Sie den Performance Monitor innerhalb des Server Managers, um JAS-zu-Enterprise-Server-Roundtrips zu verfolgen. Dieses Tool macht das Volumen der Netzwerk-Hops sichtbar, die durch übermäßige BSFN-Aufrufe aus der Präsentationsschicht generiert werden. Wenn ein einzelner Grid-Load von 100 Zeilen in hunderten von Roundtrips resultiert, haben Sie einen klaren Indikator dafür, dass die Logik in eine konsolidierte C-Business-Function gehört und nicht in einzelne ER-Zeilen.
Verwenden Sie schließlich den Event Rules Debugger, um die Grid-Schleifen schrittweise zu durchlaufen und Variablenzustände in Echtzeit zu beobachten. Dies ermöglicht es Ihnen, bedingte Logikfehler zu finden, die Endlosschleifen oder redundante Abrufe derselben Stammdaten-Datensätze verursachen. Dieses praktische Tracing ist der direkteste Weg, um zu verifizieren, warum ein Grid dutzende unnötige Datenbank-Lesevorgänge für eine einzige Zeile ausführt.
Die Optimierung der Grid-Performance in einer 9.2.x-Umgebung ist nur eine Ebene des Stacks; Engpässe liegen oft in ineffizientem BSFN-Cache-Management oder nicht optimierten SQL-Ausführungsplänen. Wenn Ihre benutzerdefinierten Anwendungen langsam sind, ist die Isolierung dieser Ineffizienzen auf Anwendungsebene der erste Schritt zur Wiederherstellung der Systemstabilität und Benutzerproduktivität.
Für Unterstützung bei der Prüfung Ihrer benutzerdefinierten EnterpriseOne-Anwendungen oder der Optimierung Ihrer JAS-Server-Performance kontaktieren Sie unser Enterprise-ERP-Consulting-Team, um eine technische Überprüfung zu vereinbaren.
