Bei der Prüfung kundenspezifischer Anpassungen in JDE 9.2JD Edwards EnterpriseOne Version 9.2.-Umgebungen finde ich regelmäßig einen häufigen Architekturfehler: Standardspaltenwerte für benutzerdefinierte Tabellen (wie eine kundenspezifische F550101) sind über mehrere interaktive Anwendungen (APPLInteraktive Anwendung in JD Edwards.) hinweg fest codiert. Sich auf Standard-Constraints auf Datenbankebene zu verlassen, schlägt fehl, da die JDB-MiddlewareDatenbank-Abstraktionsschicht von JD Edwards.-Schicht explizit Leerzeichen oder Nullen einfügt und so die Datenbank-Vorgaben überschreibt. Die Implementierung von JDE NERNamed Event Rule; wiederverwendbare Logik in JDE-Skriptsprache.-Beispielen für Standardwerte in benutzerdefinierten Tabellen ermöglicht es Teams, die Validierung und Zuweisung vor dem Aufruf des Table I/ODatenbank-Lese- und Schreibvorgänge in JD Edwards.-Inserts zu zentralisieren und so die Datenintegrität über alle Einstiegspunkte hinweg sicherzustellen.
Dieser Leitfaden bietet konkrete Implementierungsmuster zur Zentralisierung von Validierung und Zuweisung vor dem Aufruf des Table I/O-Inserts. Die Verlagerung dieser Logik aus den FDAForm Design Aid; Tool zum Erstellen von JDE-Anwendungsoberflächen. Event RulesSkriptsprache zur Steuerung von Logik in JDE-Objekten. in eine einzige, wiederverwendbare Business FunctionZentrales Programmmodul für Geschäftslogik. reduziert den Umfang des benutzerdefinierten Codes in interaktiven Anwendungen nach unserer Erfahrung um etwa ein Drittel bis zur Hälfte. Diese Umstellung vereinfacht zukünftige Tools ReleaseTechnisches Plattform-Update für JD Edwards. Upgrades und garantiert eine konsistente Datenformatierung, unabhängig davon, ob Datensätze aus einer APPL, einem UBEUniversal Batch Engine; Hintergrundprozess oder Bericht in JDE. oder einer AISApplication Interface Services; REST-API-Schnittstelle für JDE.-basierten OrchestrierungAutomatisierter Prozessablauf im JDE Orchestrator. stammen.
Die Kosten verstreuter APPL-Logik für Standardwerte
Ich habe kürzlich ein kundenspezifisches Versandsystem geprüft, bei dem Entwickler die Logik für Standardwerte über die Ereignisse Write Grid Line-Before und OK-Post Button Clicked mehrerer APPLs verteilt hatten. Dieses Designmuster erzeugt sofortige technische SchuldenZukünftiger Mehraufwand durch schnelle, unsaubere Lösungen., da Event Rules (ER) interaktiver Anwendungen bekanntermaßen schwierig zu testen und außerhalb ihres spezifischen Laufzeitkontexts zu warten sind. Wenn sich Geschäftsanforderungen ändern – wie die Aktualisierung eines Standard-Branch/PlantGeschäftseinheit oder Lagerort in JD Edwards. oder eines Statuscodes – sind Sie gezwungen, mehrere interaktive Anwendungen auszuchecken, zu ändern und Packages zu erstellen, anstatt eine einzige, wiederverwendbare Komponente zu bearbeiten.
Betrachten Sie eine benutzerdefinierte Stammdatentabelle wie F550101, die Standardwerte für ein Dutzend oder mehr verschiedene Felder erfordert, einschließlich Standard-Audit-SpaltenDatenbankfelder, die Benutzer und Zeitstempel von Änderungen speichern., Suchtypen und Währungscodes. Wenn diese Tabelle von mehreren APPLs (einem mobilen Erfassungsbildschirm, einem Desktop-Stammdatenmanager und einer Portalanwendung) sowie mehreren Batch-UBEs für nächtliche Integrationen aktualisiert wird, garantiert die Duplizierung dieser Logik über alle Einstiegspunkte hinweg Datenkorruption. Ein Entwickler, der die Desktop-APPL modifiziert, wird unweigerlich eine Zuweisung in einem der Hintergrund-UBEs übersehen, was zu verwaisten Datensätzen oder Nullwerten in kritischen Spalten wie GL-Klasse oder Steuererklärungscode führt.
Die Kapselung dieser Logik in einer dedizierten Named Event Rule (NER) reduziert den Code-Umfang der APPL bei Standard-Datenerfassungsformularen um mehr als die Hälfte. Anstatt dutzende Zeilen ER-Mapping für Standardwerte in jedem Formular zu pflegen, ruft die interaktive Anwendung einfach eine einzige BSFNBusiness Function; zentrales Programmmodul für Geschäftslogik. auf und übergibt die F550101-Datenstruktur vor dem Insert. Dieser architektonische Wandel gewährleistet eine konsistente Datenintegrität über alle Kanäle und stellt sicher, dass künftige Anpassungen von Standardwerten nur eine einzige Änderung in einer zentralen BSFN erfordern.

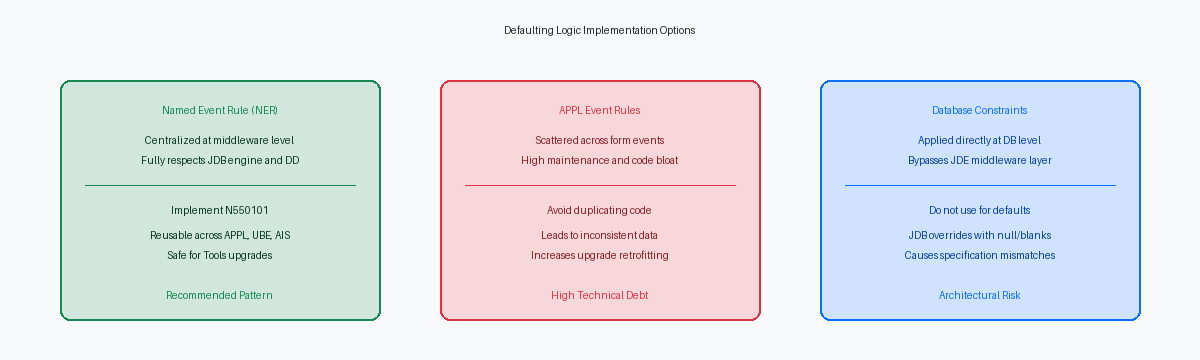
Warum Datenbank-Default-Constraints in JDE fehlschlagen
Datenbankadministratoren versuchen oft, die JDE-Entwicklung zu umgehen, indem sie ein ALTER TABLE-Statement ausführen, um einen DEFAULT 'Y'-Constraint auf eine benutzerdefinierte Tabelle wie F550101 anzuwenden. Dieser Ansatz scheitert sofort aufgrund des Designs der JDB-Middleware-Engine. Wenn eine Anwendung oder ein Batch-Prozess einen Insert auslöst, lässt die JDB-Schicht nicht zugeordnete Felder im SQL-Statement nicht einfach weg. Stattdessen konstruiert sie explizit ein INSERT-Statement, das jede in den Table Specifications definierte Spalte enthält. Da die JDB-Engine explizit ein Leerzeichen, eine Null oder einen Null-Pointer für nicht initialisierte Variablen übergibt, behandelt die Datenbank-Engine dies als expliziten Wert und überschreibt den Default-Constraint der Datenbank vollständig.
Sich auf Datenbank-Constraints zu verlassen, um Standardwerte zu erzwingen, führt zu stillen Fehlern und Konfigurationsabweichungen zwischen Ihren Umgebungen. Wenn Sie die F550101 mittels OMWObject Management Workbench; Tool zur Verwaltung von JDE-Objekten. von DV920 nach PY920 befördern und die Tabelle neu generieren, löscht das Standard-Generierungstool die physische Tabelle und erstellt sie neu. Dieser Prozess löscht alle benutzerdefinierten SQL Server- oder Oracle DB-Constraints. Entwickler wundern sich dann, warum ein Prozess, der in der Entwicklungsdatenbank funktionierte, in der Test- oder Produktionsumgebung keine Standardwerte mehr liefert.
Das korrekte Architekturmuster besteht darin, Standardwerte auf der Application-Middleware-Ebene mithilfe einer Named Event Rule zu erzwingen. Da eine NER innerhalb des Standard-EnterpriseOne-Call-Stacks ausgeführt wird – entweder auf dem HTML-Server oder über den OCMObject Configuration Manager; steuert den Ausführungsort von Objekten. auf einen Enterprise-Server gemappt – respektiert sie die nativen Data DictionaryZentrales Verzeichnis für Felddefinitionen und Regeln.-Regeln und Table Specs von JDE. Durch das Abfangen der Daten, bevor sie die JDB-Schicht erreichen, stellt die NER sicher, dass die Runtime-Engine die korrekten Standardwerte konsistent schreibt, unabhängig davon, ob die Transaktion von einer interaktiven Anwendung, einem Batch-UBE oder einer AIS-Orchestrierung stammt.
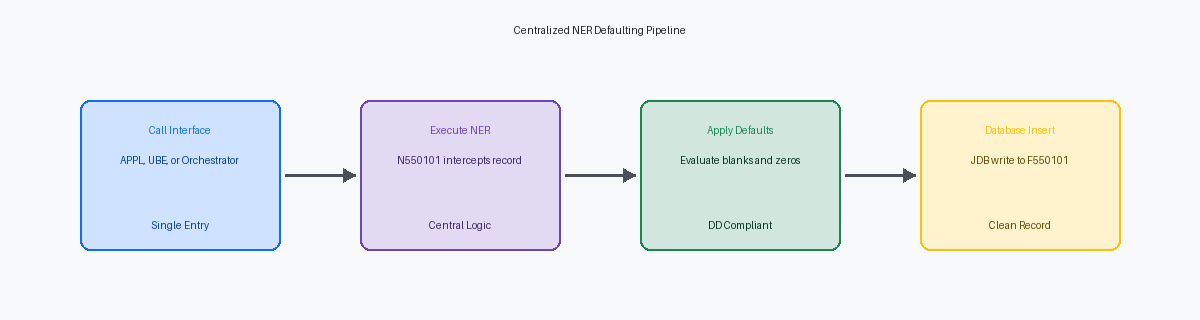
Design der zentralisierten Table Insert NER
Die Verlagerung der Logik für Standardwerte aus interaktiven Ereignissen wie "Grid Record is Fetched" in eine zentrale Named Event Rule, wie N550101, ist der einzige Weg, um Datenkorruption zu verhindern, wenn externe Integrationen die GUI umgehen. Wenn Sie N550101 als dedizierte Engine für Validierung und Standardwerte vor dem Insert aufbauen, stellen Sie sicher, dass jeder Schreibpfad dieselben Geschäftsregeln einhält. Dieser Wandel eliminiert das Risiko fehlender Header-Felder, wenn Integrationen direkt in die Schnittstellentabellen schreiben.
Die Grundlage dieses Musters liegt in der zugehörigen Datenstruktur D550101, die die Spalten der benutzerdefinierten Tabelle widerspiegeln muss. Durch die Übergabe des gesamten Datensatzes als IN/OUT-Struktur kann die NER den Status jedes Feldes prüfen und leere Werte direkt ändern. Wenn Sie nur eine Teilmenge der Schlüssel übergeben, müssen Sie redundante Fetch-Logik innerhalb der BSFN schreiben, was die Performance bei der Verarbeitung von Batches mit tausenden von Datensätzen verschlechtert.
Innerhalb der NER führt die Logik eine strikte bedingte Auswertung durch: Sie wendet Standardwerte wie das Systemdatum (SL DateToday) oder Next Numbers nur an, wenn der eingehende Parameter leer oder Null ist. Wenn der Aufrufer beispielsweise ein explizites Transaktionsdatum übergibt, respektiert N550101 dieses; ist es leer, füllt die NER es aus. Dies verhindert, dass beabsichtigte Benutzereingaben bei Bulk-UBE-Importen durch fest codierte System-Defaults überschrieben werden.
Dieses Designmuster macht die NER zu einem zentralen Dienst, der im gesamten EnterpriseOne-Ökosystem zugänglich ist. Unabhängig davon, ob eine Transaktion von einer interaktiven P550101-Anwendung, einem R550101-Batch-UBE oder einem über den AIS Orchestrator gerouteten REST-Aufruf stammt, gelten exakt dieselben Regeln für Standardwerte. Dieser einheitliche Einstiegspunkt reduziert Ihren Aufwand für Anpassungen bei Tools Release Upgrades erheblich, da Sie nur ein einziges Objekt validieren müssen.
Code-Walkthrough der Logik für Standardwerte
In den Event Rules unserer benutzerdefinierten NER besteht die erste Verteidigungslinie in der Validierung der eingehenden Datenstruktur. Wenn ein alphanumerisches Feld wie Company (CO) gleich <Blank> ist oder ein numerisches Feld wie Address Number (AN8) gleich <Zero> ist, muss die NER dies abfangen und den Standardwert anwenden. Wir implementieren dies mit expliziten If-Anweisungen, die CO und AN8 prüfen, bevor ein Table I/O erfolgt, um zu verhindern, dass die Datenbank unvollständige Datensätze erhält.
Wenn der Primärschlüssel unserer benutzerdefinierten Tabelle vom aufrufenden Prozess leer gelassen wird, ruft die NER dynamisch eine eindeutige Kennung ab. Wir rufen die Business Function F0002 Get Next Number innerhalb der NER auf und übergeben den Ziel-Systemcode sowie den Next-Number-Index, um das Schlüsselfeld zu füllen. Dies stellt sicher, dass die NER die Datenbankintegrität garantiert, indem sie automatisch die Next NumbersAutomatische Nummernvergabe für Datensätze in JDE. generiert, selbst wenn ein Entwickler vergisst, in einer APPL oder einem UBE einen Schlüssel zuzuweisen.
Die konsistente Befüllung von Audit-Feldern ist der Punkt, an dem manuelle Codierung in APPLs oft scheitert. Innerhalb dieser zentralisierten NER ordnen wir explizit die JDE-Systemwerte SL UserID dem Feld USER, SL DateToday dem Feld UPMJ und die Systemzeit dem Feld TDAY zu. Dieses Design stellt sicher, dass jeder Insert, egal ob von einer interaktiven Anwendung, einem Batch-UBE oder einer externen AIS-Orchestrierung initiiert, einen identischen, manipulationssicheren Audit-Trail trägt.
Um zu verhindern, dass die aufrufende Anwendung mit einer fehlerhaften Transaktion fortfährt, stellt die NER ein Return-Flag bereit, typischerweise cErrorFlag (EV01). Wenn eine kritische Validierung fehlschlägt – wie ein ungültiger Company-Code oder ein Fehler in der Next-Numbers-Routine – setzt die NER dieses Flag auf '1' und umgeht den Table Insert. Die aufrufende APPL oder Business Function wertet diesen Rückgabecode sofort nach der Ausführung aus, was es ermöglicht, die Verarbeitung zu stoppen und die Transaktion zurückzurollen, bevor ungültige Daten in die Datenbank gelangen.
APPL-Vereinfachung und Aufrufmuster
In einer typischen interaktiven P550101-Anwendung zur Erweiterung des Kundenstamms überladen Entwickler oft die Ereignisse "OK-Post Button Clicked" oder "Grid Record is Fetched" mit dutzenden Zeilen repetitiver Validierung und fest codierter Zuweisungen. Das Ersetzen dieser verstreuten Logik durch einen einzigen Aufruf der Named Event Rule (NER) N550101 reduziert den ER-Umfang des Formulars erheblich. Bei Headerless-Detail-Formularen stellt die Platzierung dieses Aufrufs im Ereignis Write Grid Line-Before sicher, dass jede Zeile sauber verarbeitet wird, bevor sie in die Datenbank gelangt. Bei Fix-Inspect-Formularen dient das Ereignis "Add Record to DB - Before" als optimaler Gatekeeper, um den Puffer abzufangen und die Standardwerte anzuwenden.
Die Entkopplung dieser Logik von der Präsentationsschicht beschleunigt künftige Upgrade-Zyklen direkt. Wenn Sie von 9.1 auf 9.2 upgraden, dauert der Vergleich und die Anpassung einer vereinfachten APPL mit minimalen ER-Modifikationen Minuten statt Stunden. Die Benutzeroberfläche wird zu einem reinen Dateneingabe-Vehikel, während die Kern-Geschäftsregeln sicher in der zentralisierten NER liegen. Diese Isolierung verhindert die üblichen Upgrade-Probleme, bei denen benutzerdefinierte Formularänderungen überschrieben werden oder mühsame manuelle Merges während eines Tools Release oder Anwendungs-Updates erfordern.
Dieses Architekturmuster liefert sofortige Verbesserungen bei der Integration von Batch-Prozessen wie dem R550101-Kunden-Upload-UBE. Anstatt die Regeln für Standardwerte und Validierung im "Do Section"-Ereignis des UBE zu duplizieren, ruft der Batch-Report exakt dieselbe Business Function N550101 auf. Unabhängig davon, ob ein Datensatz manuell von einem Benutzer in P550101 erstellt oder per Bulk-Import über R550101 aus einer externen Flatfile importiert wird, werden konsistent dieselben Datenbank-Defaults angewendet. Dieser zentrale Wartungspunkt eliminiert Diskrepanzen in der Datenintegrität zwischen interaktiven Eingaben und Batch-Schnittstellen.
Performance- und Cache-Überlegungen für NER-Defaults
Die Ausführung einer benutzerdefinierten NER bei jedem einzelnen Zeilen-Insert kann die Batch-Performance erheblich beeinträchtigen, wenn der zugrunde liegende Code nicht-gepufferte Datenbankabfragen durchführt. Bei einem UBE mit hohem Volumen, das zehntausende Datensätze verarbeitet, wird eine schlecht konzipierte Funktion einen kurzen Lauf in einen langwierigen Verarbeitungsengpass verwandeln. Um dies zu verhindern, muss Ihr Design einen Ausführungs-Overhead von weniger als einigen Millisekunden pro Datensatz-Insert bei der Massenverarbeitung anstreben. Dieser enge Performance-Rahmen ist absolut erreichbar, wenn Sie den Umfang der NER einschränken und den Datenabruf intelligent handhaben.
Die Minimierung von Datenbank-Roundtrips innerhalb der NER ist der effektivste Weg, um die Systemleistung zu schützen. Anstatt für jede Zeile direkte Select- oder Fetch-Single-Statements gegen Steuerungstabellen auszuführen, nutzen Sie den JDE Service Cache oder rufen Sie Standard-Business-Functions auf, die internes Caching verwenden. Wenn Sie beispielsweise Werte basierend auf der Business Unit validieren oder vorbelegen, leiten Sie die Prüfung über den Standard-F0006-Branch/Plant-Validierungscache, anstatt die physische Datenbanktabelle wiederholt abzufragen. Dies hält die Abfragen im lokalen Speicher des Enterprise-Servers und reduziert den Overhead jeder Prüfung auf Mikrosekunden.
Halten Sie die NER-Architektur einfach, indem Sie sich strikt auf die Vorbelegung von Daten und grundlegende Validierungen konzentrieren; überlassen Sie komplexe Geschäftslogik nachgelagerten Verarbeitungsfunktionen. Der Versuch, mehrstufige Bestandsallokationen oder Kreditprüfungen innerhalb einer Routine für Tabellen-Standardwerte auszuführen, ist ein Designmuster, das Datenbank-Deadlocks und einen aufgeblähten Call-Stack provoziert. Wenn ein Feld komplexe bedingte Berechnungen erfordert, weisen Sie in der NER einen sicheren Fallback-Standardwert zu und lassen Sie die anschließende Master Business FunctionKomplexe Logik-Einheit zur Verarbeitung von Kerndaten. die Hauptarbeit erledigen.
Die Zentralisierung der Logik für Standardwerte in einer NER ist ein Standardschritt zur Reduzierung eines benutzerdefinierten Code-Bestands, der oft 5.000 bis 15.000 Objekte überschreitet. Wenn Ihre 9.2.x.x-Roadmap Tabellen mit hoher Parallelität vorsieht, bieten die verwandten Artikel über C BSFN-Speichermanagement und benutzerdefinierte Cache-Muster die notwendige technische Tiefe, um Kernel-Fehler zu vermeiden. Für diejenigen, die komplexe Retrofits verwalten, enthält mein technisches Projektportfolio spezifische Beispiele für Bereinigungen von Anpassungen auf Unternehmensebene und Datenbankoptimierungsstrategien, die Upgrade-Dauern erfolgreich von mehreren Monaten auf 6-9 Wochen reduziert haben.
