
In einer typischen JDEJD Edwards ist eine umfassende Enterprise Resource Planning (ERP) Softwarelösung von Oracle für Unternehmen.-Unternehmensumgebung ist die Logik für Select, Fetch, Insert und UpdateStandard-Datenbankoperationen zum Suchen, Abrufen, Einfügen und Ändern von Datensätzen. einer einzelnen benutzerdefinierten Tabelle wie F55101 oft über 15 bis 20 verschiedene APPLsInteraktive Anwendungen in JD Edwards, mit denen Benutzer über Formulare direkt im Web-Client arbeiten. und UBEsUniversal Batch Engine; Programme zur Stapelverarbeitung, die Berichte erstellen oder Massendaten im Hintergrund verarbeiten. hinweg dupliziert. Dieser Copy-Paste-Ansatz für Event Rules (ER)Die proprietäre Programmiersprache von JD Edwards, mit der Geschäftslogik visuell erstellt wird. schafft einen massiven Wartungsaufwand; eine einfache Änderung des Datenbankschemas – wie das Hinzufügen eines 10-stelligen Kategoriecode-Feldes – zwingt Entwickler dazu, Dutzende einzelner Objekte manuell zu refactoren und zu testen. Die Einführung eines einheitlichen JDE NERNamed Event Rule; eine wiederverwendbare Geschäftsfunktion, die mit Event Rules erstellt wurde. Table IODatenbank-Ein- und Ausgabevorgänge, die direkt auf Tabellen zugreifen. Patterns zur Vermeidung wiederholter ER-Blöcke konsolidiert diese Datenbankoperationen in einer einzigen, aktionsgesteuerten Named Event Rule.
Durch die Kapselung aller Datenbankinteraktionen für eine Tabelle innerhalb einer einzigen NER reduzieren Sie das Volumen benutzerdefinierter ER um bis zu 30 % bis 50 % und etablieren eine saubere, modulare Datenzugriffsschicht direkt im JDE-Toolset. Anstatt rohe Table I/O-Anweisungen über Object Management Workbench (OMW)Das zentrale Werkzeug in JD Edwards zur Verwaltung, Entwicklung und Verteilung von Softwareobjekten. Projekte zu verstreuen, rufen Entwickler eine zentralisierte BSFNBusiness Function; ein gekapseltes Programmstück (in C oder NER), das spezifische Logik zentral ausführt. mit einem einfachen Action-Code-Parameter auf (z. B. 'A' für Add, 'U' for Update, 'F' for Fetch). Diese Umstellung verkürzt die Zeit für das Retrofitting bei Tools ReleaseEin Update der zugrunde liegenden Systemsoftware und Laufzeitumgebung von JD Edwards. Upgrades drastisch und gewährleistet absolute Datenintegrität über alle Einstiegspunkte hinweg, von interaktiven Anwendungen bis hin zu eingehenden AISApplication Interface Services; eine Schnittstelle, die JDE-Funktionen für externe Web-Services und mobile Apps bereitstellt. OrchestrationEin Werkzeug zur Automatisierung von Prozessen und zur Integration von JDE mit Drittsystemen. PayloadsDie eigentlichen Nutzdaten, die bei einem API-Aufruf übertragen werden..
Die Kosten verstreuter Table IO in Event Rules
Wenn wir eine benutzerdefinierte Tabelle wie F55101 ändern – etwa durch Hinzufügen eines 10-stelligen Kostenstellenfeldes (MCU) oder eines Audit-Datums –, ist das unmittelbare Problem nicht die Tabellenregeneration selbst. Der eigentliche Schmerz besteht darin, die 10 bis 15 verschiedenen interaktiven Anwendungen (APPLs) und Batch-Berichte (UBEs) aufzuspüren, in denen ein Entwickler die Fetch-, Select- und Update-Event-Rules-Blöcke manuell per Drag-and-Drop eingefügt hat. Die Duplizierung von Table I/O über diese Objekte hinweg erzeugt einen exponentiellen Wartungsaufwand und verwandelt ein einfaches zweistündiges Schema-Update in eine mehrtägige Suchen-und-Ersetzen-Aktion in Ihren Object Management Workbench (OMW) Projekten.
In einer Standard-9.2-Umgebung werden die CRUD-OperationenAbkürzung für Create, Read, Update, Delete – die vier grundlegenden Funktionen der Datenbankverwaltung. einer benutzerdefinierten Tabelle wie F55101 häufig über 10 bis 15 verschiedene Einstiegspunkte kopiert, vom primären Wartungsbildschirm bis hin zu benutzerdefinierten EDIElectronic Data Interchange; der elektronische Austausch von Geschäftsdokumenten in einem Standardformat.-UBEs. Jeder dieser wiederholten Event Rules-Blöcke stellt eine kritische Fehlerquelle dar. Ein Entwickler, der eine Select- oder Update-Anweisung in einem benutzerdefinierten Batch-Bericht bearbeitet, könnte leicht ein wichtiges Indexfeld wie UKID oder LNID übersehen, was zu Table ScansEin ineffizienter Suchvorgang, bei dem die Datenbank jede Zeile einer Tabelle lesen muss. führt, die die Datenbankleistung auf Ihrer Oracle- oder SQL Server-Datenbank beeinträchtigen.
Diese verstreute Architektur lähmt auch Ihre Fähigkeit, globale Datenintegrität oder konsistente Audit-Protokollierung durchzusetzen. Wenn Ihr Unternehmen beschließt, jede Änderung an F55101-Statusfeldern in einer benutzerdefinierten Audit-Tabelle zu protokollieren, müssen Sie diese Protokollierungslogik manuell in jedes aufrufende Objekt einzeln injizieren. Wenn Sie nur einen interaktiven Bildschirm vergessen, ist Ihr Compliance-Audit-Trail unterbrochen. Um dies zu verhindern, empfehle ich dringend, alle Datenbankinteraktionen für F55101 vor Ihrem nächsten Tools Release Upgrade in einer einzigen, dedizierten Business Function zu isolieren.

Entwurf einer fokussierten NER für Tabellenoperationen
Bei der Sanierung des benutzerdefinierten Auftragserfassungssystems eines globalen Vertriebskunden haben wir über hundert einzelne Table IO-Anweisungen, die über ein Dutzend verschiedene Anwendungen verstreut waren, durch eine einzige, dedizierte Named Event Rule (NER) ersetzt. Die Grundlage dieses Patterns ist eine einheitliche DatenstrukturEine Definition von Parametern und Feldern, die zum Datenaustausch an eine Funktion übergeben werden., D55101A, die jede Spalte der Zieltabelle zusammen mit kritischen Steuerungsparametern kapselt. Anstatt einzelne Variablen über mehrere Ebenen zu übergeben, bündelt diese Struktur die funktionalen Tabellenfelder mit Steuerflags wie Action Code (szActionCode) und Return Status (cReturnStatus).
Innerhalb der NER wertet eine bedingte Struktur den Action Code aus, um die Datenbankoperation zu bestimmen. Wir setzen einen strengen Standard durch: 'A' führt ein Insert aus, um einen Datensatz hinzuzufügen, 'C' führt ein Update aus, um ihn zu ändern, 'D' führt ein Delete aus und 'G' löst ein Fetch Single aus, um die Daten abzurufen. Dieses Design verhindert, dass Entwickler ad-hoc unvollständige Select/Fetch-Schleifen in den Anwendungs-Event-Rules schreiben, und zwingt alle Datenbankinteraktionen durch einen vorhersehbaren, getesteten Codepfad.
Die Konsolidierung dieser Operationen in einer einzigen NER stellt sicher, dass Datenbanktransaktionen als eine einzige, vorhersehbare Arbeitseinheit verwaltet werden, was bei der Zuordnung zu EnterpriseOne-TransaktionsverarbeitungEin Verfahren, das sicherstellt, dass eine Gruppe von Datenbankänderungen entweder komplett erfolgreich ist oder vollständig rückgängig gemacht wird.sgrenzen entscheidend ist. Wenn ein Insert während eines Multi-Tabellen-Updates fehlschlägt, kann die NER die Transaktion sofort zurückrollen und einen Fehlerstatus von '1' an den Aufrufer zurückgeben, wodurch verwaiste Datensätze in benutzerdefinierten Tabellen wie F55101 verhindert werden. Diese Abstraktionsschicht isoliert das physische Tabellenlayout vollständig von den aufrufenden Anwendungen. Wenn Sie der Tabelle eine neue Spalte hinzufügen oder einen Index ändern, aktualisieren Sie den internen Code der NER und die Datenstruktur, während die aufrufenden Event Rules unberührt bleiben und die Notwendigkeit entfällt, Dutzende von APPL- oder UBE-Objekten neu zu erstellen.
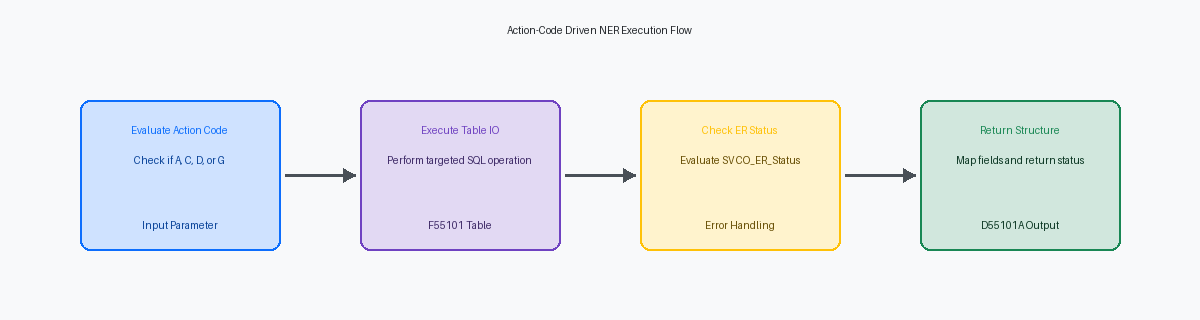
Umgang mit komplexen Table IO und Fehlerzuständen
In mehr als einem Dutzend Upgrade-Audits habe ich erlebt, dass benutzerdefinierte NERs geräuschlos fehlschlagen, weil Entwickler davon ausgingen, dass eine Select-Anweisung immer erfolgreich war. Ihre ER-Status-Evaluierungslogik muss SV CO_ER_Status unmittelbar nach jeder einzelnen Fetch Single-, Update- oder Delete-Anweisung prüfen. Selbst ein einziger Zuweisungs- oder Utility-BSFN-Aufruf zwischen dem Table IO und der Statusprüfung birgt das Risiko, die Systemvariable zu überschreiben, was zu falsch-positiven Ergebnissen führt, die Tabellen wie die F41021 mit korrupten Daten verunreinigen.
Anstatt Glossartexte fest zu codieren oder Set ER Error innerhalb der NER aufzurufen, ordnen Sie Datenbankzustände einem standardisierten Ausgabeparameter wie cReturnCode zu ('0' für Erfolg, '1' für Datensatz nicht gefunden, '2' für doppelten Schlüssel). Dies ermöglicht es der aufrufenden APPL oder UBE, den Fehler kontrolliert zu behandeln. Eine Einzelhandels-APPL könnte die Transaktion stoppen, während eine nächtliche Batch-UBE lediglich die Warnung protokolliert und fortfährt. Die Übergabe des rohen Codes nach oben hält die NER über verschiedene Umgebungen hinweg wiederverwendbar.
Beim Umgang mit Teil-Schlüssel-Abfragen mit einer Select- und Fetch Next-Schleife ist das Versäumnis, den Rückgabestatus des initialen Select zu validieren, eine gefährliche Falle. Wenn das Select fehlschlägt und Ihr Code in eine While-Schleife eintritt, die durch SV CO_ER_Status is equal to CO SUCCESS gesteuert wird, können Sie eine Endlosschleife auslösen, die die CPU des Enterprise-Servers maximal auslastet. Initialisieren Sie Schleifensteuerungsvariablen immer und prüfen Sie explizit den Status des ersten Fetch Next, bevor Sie den Block betreten.
Schritt-für-Schritt-Implementierung der Custom Table IO NER
Die Standardisierung des Datenbankzugriffs in einer benutzerdefinierten Named Event Rule (NER) beginnt mit einem starren Datenstruktur-Design. Wir ordnen die Primärschlüssel, die Payload-Felder und einen 1-stelligen Action Code (cActionCode) zu, um die Ausführung zu steuern. Innerhalb der NER muss die erste Zeile der Event Rules ein bedingter Verzweigungsblock sein – typischerweise eine Select-Struktur –, die diesen Action Code auswertet. Dieses zentralisierte Routing stellt sicher, dass kein Datenbankaufruf erfolgt, ohne vorher den Operationstyp zu validieren, wodurch das Risiko versehentlicher Tabellen-Updates eliminiert wird.
Wenn der Action Code 'G' (Get) lautet, wertet die NER die eingehenden Schlüsselparameter aus. Wenn der Aufrufer einen vollqualifizierten eindeutigen Schlüssel übergibt, führt der Code ein direktes Fetch Single gegen die Tabelle F55101 aus; andernfalls initiiert er eine Open-, Fetch- und Close-Cursor-Sequenz, je nachdem, ob ein eindeutiger Schlüssel bereitgestellt wurde. Wenn der Action Code 'A' (Add) lautet, fängt die NER den Schreibvorgang ab, um die Standard-Audit-Felder zentral zu füllen. Anstatt sich darauf zu verlassen, dass der Aufrufer diese übergibt, weist die NER programmgesteuert die Benutzer-ID (USER), Programm-ID (PID), das Aktualisierungsdatum (UPMJ) und die Uhrzeit (TDAY) zu, bevor sie die Insert-Anweisung ausführt.
Für eine 'C' (Change)-Operation führt die NER ein Fetch for Update oder eine direkte Update-Anweisung basierend auf den in der Datenstruktur übergebenen Primärschlüsseln aus. Wenn optimistisches SperrenEine Methode, die verhindert, dass zwei Benutzer gleichzeitig denselben Datensatz überschreiben, ohne die Datenbank dauerhaft zu blockieren. erforderlich ist, sperrt das Fetch for Update die Zeile in der F55101-Datenbank, bevor der Datensatz geändert wird. Andernfalls wird ein direktes Update ausgeführt, das strikt auf die Primärschlüssel gemappt ist. Dies kapselt die Dauer von Datenbank-Sperren auf Millisekunden und verhindert die lang anhaltenden Sperren, die auftreten, wenn Entwickler manuelle Table IO direkt in Form Event Rules schreiben.
Beispiele für Aufrufer: Refactoring von APPL- und UBE-Event-Rules
Betrachten Sie das Grid Record Is Validated Event in einem Standard-P4210-Custom-Klon. In einer typischen Legacy-Implementierung enthält dieses Event Dutzende Zeilen manueller Table I/O, verstreut mit Fetch Single-Anweisungen zur Validierung von Item Branch-Datensätzen. Durch das Refactoring dieser Logik komprimieren wir diese Zeilen redundanter Event Rules auf einen einzigen, sauberen BSFN-Aufruf, der die Schlüsselparameter übergibt. Diese Umstellung reduziert die Größe der lokalen Spezifikationen der APPL und eliminiert das Risiko nicht geschlossener Tabellen-Handles bei schnellem Scrollen im Grid.
Dieser Refactoring-Ansatz isoliert die Präsentationsschicht der interaktiven Anwendung von der Datenbankzugriffsschicht und ahmt eine moderne Model-View-ControllerEin Software-Architekturmuster, das Daten (Model), Benutzeroberfläche (View) und Logik (Controller) strikt trennt.-Architektur innerhalb von JD Edwards nach. Wenn Sie die SQL-Ausführung aus dem Form Design Aid (FDA) entfernen und in einer NER kapseln, erhalten Sie einen einzigen Wartungspunkt. Wenn eine benutzerdefinierte Tabelle wie F554101 einen neuen Index oder eine neue Validierung erfordert, ändern Sie die zentrale NER einmal, anstatt Dutzende von APPL-Eingabeformularen zu durchsuchen.
Für die Stapelverarbeitung profitiert eine volumenstarke UBE wie eine angepasste R42565, die Zehntausende von Datensätzen verarbeitet, erheblich von diesem Design. Anstatt komplexe Fetch Single-Blöcke im Do Section Event des Hauptdetailbereichs zu wiederholen, ruft die UBE die benutzerdefinierte NER mit einem Action Code 'G' auf, um Preisüberschreibungen abzurufen. Die UBE verarbeitet die zurückgegebene Datenstruktur sauber und wertet das Erfolgsflag aus, bevor sie die Ausgabezeile formatiert.
Wenn die Tabellenoperation nicht-blockierende Schreibvorgänge beinhaltet, wie das Aktualisieren einer benutzerdefinierten Audit-Log-Tabelle wie F559801, können Entwickler sicher das Flag für asynchrone Ausführung in den BSFN-Aufrufeigenschaften aktivieren. Dies ermöglicht es dem primären interaktiven Thread, die Verarbeitung fortzusetzen, ohne auf die Bestätigung des Schreibvorgangs in der Datenbank zu warten. Die asynchrone Ausführung der NER verhindert Verzögerungen in der Benutzeroberfläche während Spitzenzeiten und hält die Datenbankinteraktion standardisiert.
Performance- und Wartungsgewinne in der Praxis
Bei einem kürzlichen Refactoring eines benutzerdefinierten Bestandszuteilungssystems für einen großen Metallhändler haben wir verstreute F41021- und F4111-Table-I/O-Anweisungen in mehreren verschiedenen Eingabeanwendungen durch eine einzige konsolidierte NER ersetzt. Diese architektonische Umstellung reduzierte die Zeilenanzahl der benutzerdefinierten Event Rules bei den betroffenen Objekten um fast die Hälfte. Durch das Entfernen redundanter Select-, Fetch- und Update-Blöcke aus einzelnen Form Events eliminierten wir den Spaghetti-Code, der zuvor die eigentliche Geschäftslogik verschleierte.
Die Konsolidierung von Table I/O in eine kompilierte NER reduziert direkt die Größe der generierten SpecsSpezifikationen; die Metadaten, die das Aussehen und Verhalten von JD Edwards Objekten definieren. für die aufrufenden Anwendungen und UBEs. Wenn eine APPL oder UBE weniger eingebettete ER-Table-I/O-Anweisungen hat, verbringt die Runtime-Engine weniger Zeit damit, Specs bei der Ausführung zu parsen und in den Speicher zu laden. Dies führt zu messbaren Verbesserungen bei den Startzeiten von Anwendungen und Batch-Initialisierungsphasen, insbesondere über WANWide Area Network; ein Netzwerk, das große geografische Distanzen abdeckt und Standorte miteinander verbindet.-Verbindungen mit hoher Latenz oder in dichten HTML-Serverumgebungen.
Datenbankadministratoren profitieren sofort von diesem Design, da es Tabellenzugriffsmuster standardisiert. Anstatt sich mit Dutzenden von leicht unterschiedlichen Ad-hoc-SQL-Abfragen auseinanderzusetzen, die von verschiedenen APPLs generiert werden, verarbeitet die Datenbank-Engine hochgradig vorhersehbare, wiederverwendbare SQL-Ausführungspläne, die über ein einziges, zentralisiertes Objekt generiert werden. Diese Konsistenz ermöglicht es dem Datenbank-Optimizer, Ausführungspläne effektiver zwischenzuspeichern, was den CPU-Overhead auf dem Datenbankserver während Spitzen-Transaktionsvolumina reduziert.
Aus Wartungssicht ist die Fehlersuche bei Datenbankproblemen oder Datenkorruption keine mehrtägige Jagd durch verschachtelte Event Rules mehr. Entwickler können den JDEDebugger öffnen, einen einzigen Breakpoint innerhalb der vorgesehenen Table IO NER setzen und jeden Lese- oder Schreibversuch erfassen, der an die Zieltabelle gerichtet ist. Diese Isolationsfähigkeit reduziert die durchschnittliche Zeit bis zur Fehlerbehebung (MTTRMean Time To Repair; die durchschnittliche Zeit, die benötigt wird, um ein System nach einem Ausfall wiederherzustellen.) für Produktionsfehler von Stunden der Log-Verfolgung auf wenige Minuten aktiven Debuggings.
Für Unternehmen, die eine JD Edwards 9.2-Umgebung stabilisieren, stellt die Konsolidierung redundanter Datenbanklogik in einer einzigen Named Event Rule eine hocheffektive Methode dar, um den Footprint des benutzerdefinierten Codes um ein Fünftel oder mehr zu reduzieren, zukünftige Upgrade-Pfade zu vereinfachen und die langfristige Systemstabilität zu gewährleisten.
