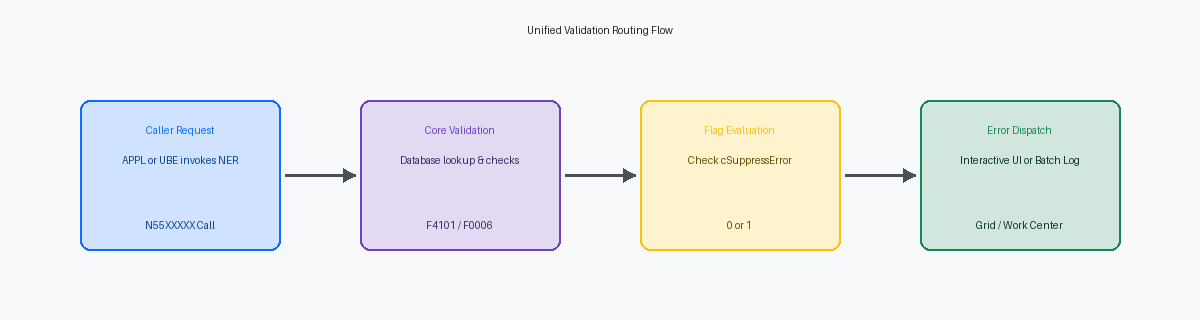
In ausgereiften JD Edwards 9.2Eine umfassende Enterprise Resource Planning (ERP) Software von Oracle für mittlere und große Unternehmen. Umgebungen finde ich routinemäßig genau dieselbe Validierungslogik vor, die über ein Dutzend oder mehr verschiedene Einstiegspunkte dupliziert wurde – von benutzerdefinierten P42101Eine spezifische interaktive Anwendung in JD Edwards zur Verwaltung von Verkaufsaufträgen. Power Forms bis hin zu automatisierten EDI-Inbound-UBEsUniversal Batch Engine; Programme in JD Edwards, die Berichte erstellen oder Daten im Hintergrund verarbeiten.. Diese Fragmentierung entsteht, weil Entwickler standardmäßig die Validierung direkt in den Event RulesEine proprietäre Skriptsprache in JD Edwards, mit der Geschäftslogik ohne C-Programmierung definiert wird. "Control Exited/Changed" einer interaktiven Anwendung (APPLAbkürzung für eine interaktive Anwendung (Application) innerhalb der JD Edwards-Umgebung.) platzieren, wodurch sie für Batch-Prozesse unzugänglich wird. Um diese technischen Schulden zu eliminieren, müssen Sie die Ausführung der Validierung sowohl von der Benutzeroberfläche als auch von den Batch-Runtimes entkoppeln, indem Sie ein wiederverwendbares JDE NERNamed Event Rule; eine wiederverwendbare Geschäftsfunktion, die mit Event Rules erstellt wird. Validierungsmuster für APPL- und UBE-Aufrufer implementieren.
Die Implementierung dieses zentralisierten Ansatzes ermöglicht es Ihnen, die Logik innerhalb einer einzigen Named Event Rule (NER) unter Verwendung von Standard-DD-Error-Glossaren zu konsolidieren. Durch die Übergabe einer einheitlichen DatenstrukturDefiniert die Eingabe- und Ausgabeparameter für eine Business Function oder ein Formular., die Action Codes enthält, passt sich diese einzelne BSFNBusiness Function; ein kapselbarer Programmbaustein, der spezifische Logik ausführt. dynamisch an: Sie gibt strukturierte Fehler an ein APPL-Grid zurück oder schreibt saubere Protokolle in das PDF eines UBEs, ohne eine einzige Zeile redundanten Codes.
Die Kosten duplizierter Validierungslogik
Das Hardcodieren identischer Validierungslogik sowohl in der Verkaufsauftragserfassung P4210 als auch im R47011 EDI-Inbound-Auftragsprozessor ist ein Architekturmuster, das IT-Budgets belastet. Bei einem Upgrade von 9.1 auf 9.2 führt diese Realität der doppelten Wartung zu einem erheblichen Anstieg der Kosten für das Code-Retrofitting, oft um bis zu 50 %. Entwickler müssen genau dieselben Regeln in zwei völlig unterschiedlichen Objekttypen lokalisieren, modifizieren und Unit-Tests unterziehen, was die Fehleranfälligkeit während des Upgrade-Zyklus verdoppelt.
Über die Upgrade-Mechanik hinaus bedroht dieser architektonische Split aktiv die Integrität der Transaktionstabellen in kritischen Dateien wie der F4211Die Datenbanktabelle in JD Edwards, in der die Details von Verkaufsaufträgen gespeichert werden. Sales Order Detail und der F4111Die Artikel-Ledger-Tabelle, die alle Lagerbewegungen und Transaktionen aufzeichnet. Item Ledger. Batch-Uploads, die über UBEs oder Inbound-Business-Functions laufen, umgehen häufig die Event Rules auf UI-Ebene interaktiver Masken. Das Ergebnis ist stille Datenkorruption: verwaiste Datensätze, ungültige Branch/Plant-Kombinationen und nicht übereinstimmende Einheitskosten, die die APPL-Validierung umgehen und direkt in die Datenbank gelangen.
Die Konsolidierung dieser fragmentierten Regeln in einer einzigen, zentralisierten Named Event Rule (NER) reduziert den Footprint für benutzerdefinierte Objekte sofort um etwa ein Viertel bis ein Drittel des gesamten Modifikationsbestands. Anstatt Dutzende von getrennten Form Extension Regeln, Table Triggern oder UBE Event Rules zu verwalten, leiten Sie die gesamte Validierung über eine einzige wiederverwendbare Engine. Diese strukturelle Verschiebung vereinfacht Retrofits auf einen einzigen Validierungspunkt und stellt sicher, dass jede zukünftige regulatorische oder betriebliche Änderung einmal codiert und überall übernommen wird.
Eine typische Enterprise-Installation, die JDE seit einem Jahrzehnt oder länger nutzt, sammelt Dutzende von benutzerdefinierten Validierungsroutinen an, die über die Namensräume 55 bis 59 verteilt sind. Diese Routinen – von einfachen Losstatusprüfungen bis hin zu komplexen Margenberechnungen – sind prädestiniert für dieses einheitliche Architekturmuster. Die Prüfung Ihres Repositorys zur Identifizierung dieser redundanten Routinen ist der erste Schritt zur Stabilisierung Ihrer Transaktionsdaten vor Ihrem nächsten Tools Release Update.
Design der wiederverwendbaren NER-Parameterschnittstelle
Das Design einer Datenstruktur, die APPL (interaktiv) und UBE (Batch) verbindet, erfordert eine explizite Kontrolle darüber, wie Fehler ausgegeben werden. Wenn Ihre NER SetUserBehaviorError direkt aufruft, unterbrechen Sie die Headless-Batch-Verarbeitung in UBEs oder AIS OrchestrationsEin Werkzeug zur Automatisierung von Geschäftsprozessen und Integrationen über REST-Dienste., was zu stillen Fehlern führt. Stattdessen muss die benutzerdefinierte Datenstruktur (DSTR) Kontroll-Flags wie cSuppressErrorMessage und cErrorOccurred (beide EV01) zusammen mit einem 10-stelligen Fehlercode-Parameter szErrorMessageID (DTAI) an den Aufrufer zurückgeben. Diese Entkopplung ermöglicht es einer APPL, einen visuellen Fehler unter Verwendung der zurückgegebenen ID anzuzeigen, während ein UBE die Nachricht elegant in ein PDF oder das Work CenterEin internes JDE-System zur Zustellung von Systemnachrichten und Fehlermeldungen an Benutzer. schreiben kann.
Um sicherzustellen, dass die Validierungs-Engine verschiedene operative Kontexte über Module wie Procurement (G43) hinweg verarbeiten kann, muss die DSTR einen standardisierten Satz von Kontextfeldern enthalten. Ordnen Sie Company (szCompany, CO), Business Unit (szBusinessUnit, MCUBusiness Unit; ein Feld in JDE, das eine organisatorische Einheit oder einen Standort identifiziert.) und Item Number (mnShortItemNo, ITMShort Item Number; eine interne, systemgenerierte numerische Kennung für einen Artikel.) als optionale Eingaben zu. In einer realen Multi-Währungs-Implementierung ermöglicht die Übergabe dieser drei Variablen derselben NER, Branch-Plant-Konstanten oder Item-Branch-Verfügbarkeit zu validieren. Wenn ein Aufrufer nur einen Artikel validieren muss, lässt er das Feld Company leer; die NER verarbeitet die bedingte Logik intern, was den Bedarf an mehreren speziellen Validierungsfunktionen reduziert.
Ein häufiger Fehler, der zeitweise Speicherfehler auf 64-Bit Enterprise ServernDer zentrale Server in einer JDE-Architektur, auf dem die Geschäftslogik und Batch-Prozesse ausgeführt werden. verursacht, ist die Verwendung von UI-spezifischen Data Dictionary Items in der DSTR. Datenelemente, die für interaktive Grids entwickelt wurden, enthalten oft Formatierungs-Trigger, die während einer Headless-Ausführung im Speicher nicht korrekt ausgerichtet sind. Halten Sie sich an saubere, primitive Datentypen wie MATH_NUMERIC für Mengen und CHAR für Flags. Dies garantiert, dass die Datenstruktur sauber an 8-Byte-Grenzen ausgerichtet ist, wenn ein UBE die NER in einer Multi-Threaded-Queue aufruft, was Speicherkorruption verhindert und eine konsistente Ausführung sowohl auf lokalen Clients als auch auf dem Enterprise Server gewährleistet.

Aufbau der Core NER Validierungs-Engine
Das Schreiben eines stabilen Validators bedeutet, der Versuchung zu widerstehen, auf benutzerdefinierte C-Code-Hacks oder direkte Datenbank-API-Aufrufe innerhalb des Toolsets zurückzugreifen. Beim Aufbau der Kern-Validierungs-Engine innerhalb von N55XXXXX beschränken wir uns strikt auf Standard-Event Rules (ER). Dieser Ansatz garantiert, dass die OMWObject Management Workbench; das zentrale Werkzeug in JD Edwards zur Verwaltung und Entwicklung von Objekten. bei einem Update des Tools Release von 9.2.7 auf 9.2.8 den zugrunde liegenden C-Code fehlerfrei generiert, ohne bei Compiler-Änderungen zu scheitern.
Innerhalb der ER führen wir gezielte Datenbankabfragen gegen Stammdatentabellen wie F4101 und F0006 durch, wobei wir ausschließlich deren Primärschlüssel verwenden – speziell Short Item Number (ITM) und Business Unit (MCU). Das Umgehen von Sekundärindizes oder Teil-Schlüsselsuchen hält den Overhead für Datenbankabfragen nahe Null, was kritisch ist, wenn ein Batch-UBE Zehntausende von Datensätzen verarbeitet. Wenn eine Suche fehlschlägt, markieren wir den Datensatz sofort als ungültig, bevor CPU-Zyklen für nachfolgende Validierungsschritte verschwendet werden.
Die Engine wertet eingehende Kontroll-Flags aus, um zu bestimmen, wie mit Validierungsfehlern umgegangen werden soll. Wenn die aufrufende Anwendung sofortiges UI-Feedback benötigt, wertet die ER diese Flags aus, um entweder 'Set Action Code' oder 'Set User Error' Systemfunktionen direkt im Ausführungspfad auszulösen. Bei Batch-Läufen umgeht die NER diese interaktiven Systemfunktionen und füllt stattdessen die Output-Fehlerstruktur, was Laufzeitabstürze in Headless-Umgebungen verhindert.
Um eine saubere Schnittstelle zu wahren, gibt die NER ein binäres Erfolgs-Flag, cErrorOccurred, zurück, das bei einem Fehler auf '1' oder bei Erfolg auf '0' gesetzt wird. Zusammen mit diesem Flag gibt die Funktion den spezifischen vierstelligen JDE-Fehlercode aus, der im F9203 Data Dictionary registriert ist. Dieser duale Rückgabemechanismus lässt die aufrufende APPL oder den UBE entscheiden, ob die Verarbeitung vollständig gestoppt oder die Fehlerdetails für eine asynchrone Überprüfung in eine Work Center Tabelle geschrieben werden sollen.
Aufruf der NER aus einer interaktiven Anwendung
Das Auslösen der Validierung zum falschen Zeitpunkt im interaktiven Lebenszyklus ist eine Hauptquelle für Geisterfehler und Performance-Verzögerungen in angepassten Anwendungen wie P554101. Um dies zu verhindern, platzieren Sie den benutzerdefinierten NER-Aufruf direkt im Event Grid Cell Exited - Changed Inline der Zielspalte, anstatt sich auf lose Post-Commit-Prüfungen zu verlassen. Wenn Sie ein Header-Level-Control anstelle einer Grid-Spalte validieren, verwenden Sie das Event Control Exited. Diese gezielte Platzierung stellt sicher, dass die Validierung nur ausgeführt wird, wenn ein Benutzer tatsächlich einen Wert ändert, was unnötige Database-RoundtripsDie Kommunikation zwischen Anwendung und Datenbank, um Daten abzurufen oder zu speichern. bei sauberen Datensätzen spart.
Beim Mapping der Parameterliste für den NER-Aufruf innerhalb der Event Rules übergeben Sie die Ziel-Grid-Row-Pointer und setzen das Flag cSuppressErrorMessage auf '0'. Die Übergabe von '0' weist die NER an, die interaktive Engine den Bildschirmstatus nativ verwalten zu lassen, anstatt den Fehler im Hintergrund zu vergraben oder einen harten Absturz zu erzwingen. Sobald die NER zurückkehrt, werten Sie den Parameter szErrorMessageID aus. Wenn diese Variable nicht leer ist, rufen Sie sofort die Systemfunktion Set Grid Cell Error in P554101 auf und übergeben das aktive Grid Control, die aktuelle Zeile und die spezifische Fehler-ID, die von der Business Function zurückgegeben wurde.
Eine häufige Schwachstelle im benutzerdefinierten APPL-Design ist der "Fast-Typing-Bypass", bei dem ein Benutzer auf die Schaltfläche OK klickt, bevor das Validierungs-Event auf Zellenebene die Verarbeitung abgeschlossen hat. Um diese Lücke zu schließen, müssen Sie den Validierungsaufruf innerhalb des Button Clicked Events der OK-Schaltfläche replizieren und das Grid in einer Schleife durchlaufen, um alle Zeilen neu zu bewerten. Diese zweistufige Prüfung dauert weniger als zehn Millisekunden pro Zeile, garantiert aber, dass während der kritischen Tabellenschreibphase niemals ungültige Daten in die Standard Inventory Master Business Function, B4100140, gelangen.
Aufruf der NER aus einer Batch-Engine
Die Ausführung der Validierungslogik innerhalb eines Batch-UBEs requiriert eine strukturelle Verschiebung gegenüber interaktiven Anwendungen, um stille Fehler oder unkontrollierte Jobs zu verhindern. In einem Inbound-Item-Staging-Tabellen-Prozessor wie dem R554101, der routinemäßig eine große Anzahl von Staging-Datensätzen pro Lauf verarbeitet (typischerweise 10.000 bis 50.000), müssen Sie die Validierungs-NER direkt im Do Section des primären Driver-Sections platzieren. Für jeden abgerufenen Staging-Datensatz ordnet der UBE die Roh-Eingabefelder – wie MCU, LITM und UOM – direkt der Datenstruktur der NER zu, um sicherzustellen, dass jeder Datensatz genau dieselbe Validierungsroutine durchläuft wie eine interaktive Maske.
Beim Aufruf der Validierungs-NER aus einem Batch-Kontext ist die Übergabe einer '1' an den Eingabeparameter cSuppressErrorMessage zwingend erforderlich. Dieses Unterdrückungs-Flag verhindert, dass die Engine versucht, interaktive Fehlerdialoge auszulösen oder den Thread anzuhalten, was andernfalls das Laufzeitverhalten des Batches korrumpieren würde. Wenn die NER einen cErrorOccurred-Wert von '1' zurückgibt, müssen die Event Rules den Datenbank-Insert-Schritt umgehen, indem sie die Systemfunktion 'Write Section' überspringen. So wird sichergestellt, dass nur einwandfreie, validierte Daten Ihre Produktions-Tabellen F4101 oder F4102 erreichen.
Anstatt den Benutzer raten zu lassen, warum ein Datensatz fehlgeschlagen ist, muss der UBE das spezifische DD-Error-Item erfassen, das von der NER zurückgegeben wurde. Sie können diesen Fehlercode direkt an die Standard-Business-Function B0100025 übergeben, um eine detaillierte Nachricht in das JDE Work Center zu schreiben und sie mit der spezifischen EDI-Belegnummer oder Transaktions-ID zu verknüpfen. Für Kunden, die sauberere operative Dashboards bevorzugen, bietet das Einfügen dieser Validierungsfehler in eine benutzerdefinierte Fehlerprotokolltabelle wie F55ERR eine direkte Quelle für benutzerdefinierte Monitoring-Tools, was einen erheblichen Teil der Analysezeit einspart – oft bis zur Hälfte dessen, was normalerweise für die Suche in rohen PDF-Ausgaben aufgewendet wird.
Performance- und Cache-Überlegungen
Eine Validierungs routine, die in weniger als zwanzig Millisekunden ausgeführt wird, mag während interaktiver APPL-Tests vernachlässigbar erscheinen, wird aber einen hochvolumigen UBE, der Hunderttausende von Datensätzen verarbeitet, lahmlegen. Wenn Ihre benutzerdefinierte Validierungs-NER bei jeder einzelnen Iteration redundante Tabellen-I/O ausführt, wird sich ein nächtlicher Batch-Lauf, der in wenigen Minuten abgeschlossen sein sollte, leicht auf fast eine Stunde ausdehnen. Diese Verschlechterung tritt auf, weil Datenbank-Roundtrips schnell Netzwerk- und Disk-Overhead ansammeln, insbesondere wenn SQL-AusführungspläneDer vom Datenbank-Optimierer gewählte Weg, um eine Abfrage effizient auszuführen. Cursor bei sich wiederholenden Aufrufen nicht wiederverwenden.
Um diese Latenz zu verhindern, müssen Sie den JDE Service Cache oder das Standard-Umgebungstabellen-Caching für statische Setup-Tabellen wie die F41001 nutzen. Die Sicherstellung, dass die Inventory Constants Tabelle im Speicher zwischengespeichert wird, senkt die Suchzeiten auf unter zehn Millisekunden pro Aufruf und eliminiert effektiv physische Datenbank-Lesevorgänge. Bei dynamischen Transaktionsabfragen sollten Sie komplexe Unterabfragen innerhalb der NER vollständig vermeiden. Übergeben Sie stattdessen vorab abgerufene Parent-Keys direkt aus dem primären Driver-Section des aufrufenden UBEs über die Business-Function-Datenstruktur, um den internen Ausführungspfad der NER so flach und schnell wie möglich zu halten.
Sie müssen sich auch gegen Transaktionsisolationsprobleme schützen, die auftreten, wenn interaktive APPLs und Batch-UBEs dieselbe Logik teilen. Öffnen Sie einen lokalen Fat Client, führen Sie Ihren Validierungsprozess aus und analysieren Sie sofort den Call-Stack des Enterprise Servers mithilfe von JDEDEBUG-Protokollen. Achten Sie genau auf die Abschnitte zur Transaktionsverfolgung, um zu bestätigen, dass die NER keine verschachtelten Transaktionen initiiert oder Sperren auf Tabellen wie F4101 oder F0101 hält. Wenn Sie SELECT FOR UPDATE-Anweisungen oder unerwartete Commit Transaction-Aufrufe innerhalb der Validierungsschleife entdecken, entkoppeln Sie diese Operationen, um Datenbank-DeadlocksEin Zustand, bei dem sich zwei Prozesse gegenseitig blockieren, da jeder auf eine Ressource wartet, die der andere hält. während paralleler Batch-Läufe auf Ihrem Enterprise Server zu verhindern. Eine einzige nicht indizierte Abfrage in Ihrer Validierungslogik kann unter Last zu Sperren auf Tabellenebene führen.
Die Zentralisierung der Validierungslogik in wiederverwendbaren NERs ist eine Grundvoraussetzung, um einen Bestand von über 500 benutzerdefinierten Objekten zu verwalten, ohne den Zeitplan für Ihr 9.2.8 Upgrade aufzublähen. Die Auslagerung dieser Logik aus einzelnen UI- und Batch-Engines in eine einheitliche Business Function gewährleistet eine konsistente Datenvalidierung, reduziert den Retrofitting-Overhead und rationalisiert die langfristige Systemwartung.
