
Von der Roh-Liste zur Schätzung: Wie man ein JD Edwards Upgrade belastbar macht
Ein JD Edwards Upgrade sollte nicht mit einer Schätzung beginnen. Es sollte mit einer deutlich unbequemeren Frage beginnen: Was ist eigentlich der Umfang, der geschätzt werden muss? In der Theorie scheint die Antwort einfach. Man extrahiert die Custom Objects, vergleicht sie mit dem Standard, prüft, was geändert wurde, und berechnet den Aufwand, der nötig ist, um sie von der Ausgangsrelease auf die Zielrelease zu bringen. In der Praxis existiert diese lineare Abfolge nur selten. Reale Umgebungen enthalten Jahre von Eingriffen, Kopien von Standardobjekten, Reports, die nie mehr ausgeführt wurden, technische Objekte, geänderte Versionen, Objekte, die für längst vergessene Notfälle erstellt wurden, Drittanbieterkomponenten, weiterhin kritische Customizations und Anpassungen, die niemand mehr verwendet. Deshalb kann die Schätzung nicht der erste Schritt sein: Sie muss das Ergebnis eines Qualifizierungsprozesses sein.
Der zentrale Punkt besteht darin, eine Roh-ListeAnfängliche, breite und bewusst vorsichtige Liste von Objekten, die potenziell für das Upgrade relevant sind. in eine Suggested Object ListBegründete Liste von Objekten, die nach Filtern und Prüfungen im Analyse- oder Schätzumfang bleiben sollten. zu transformieren. Diese Transformation ist keine Übung zur numerischen Reduktion. Man beginnt nicht mit Tausenden von Objekten, um auf wenige Hundert zu kommen, weil „weniger besser ist“. Man beginnt mit einer breiten Momentaufnahme, weil es in einem seriösen Assessment gefährlicher ist, ein wichtiges Objekt zu verlieren, als ein zusätzliches Objekt zu analysieren. Die Sichtung dient daher dazu, den Umfang zu qualifizieren: Jedes Objekt muss aus einem technisch dokumentierbaren Grund ausgeschlossen, behalten, klassifiziert oder wieder aufgenommen werden.
Diese Unterscheidung verändert die Art, den Prozess zu verstehen, vollständig. Eine anfängliche Liste ist noch keine Arbeitsliste. Sie ist eine Sammlung von Kandidaten. Einige Kandidaten werden bestätigt, andere neu klassifiziert, wieder andere können aus dem operativen Umfang des Upgrades herausgenommen werden. Aber keine Entscheidung sollte unsichtbar sein. Ein Objekt verschwindet nicht, weil jemand die finale Zahl senken möchte. Es verlässt den Umfang nur, wenn es ein überprüfbares Kriterium gibt: zum Beispiel, weil es Standard ist, weil es zu einer Kategorie gehört, die kein Application Retrofit erfordert, weil es nicht mehr genutzt wird, weil es separat behandelt wird oder weil der Kunde bewusst entscheidet, es nicht einzubeziehen.
Warum die Anfangsliste breit sein muss
Der erste Fehler, den man vermeiden sollte, ist die zu frühe Suche nach einer „sauberen“ Liste. In einer reifen JD Edwards Umgebung kann etwas, das einfach erscheint, komplexe Abhängigkeiten verbergen. Ein Report kann custom wirken, aber fast identisch mit dem Standard sein. Eine Kopie kann harmlos aussehen, aber von einem Standardobjekt abstammen, das Oracle in der Zielrelease geändert hat. Eine Batch-Version kann nebensächlich erscheinen, aber beim Monatsabschluss verwendet werden. Ein technisches Objekt kann außerhalb des Umfangs wirken, aber notwendig sein, damit eine Prozesskette funktioniert. Deshalb muss die Anfangsphase eine gewisse Informationsredundanz akzeptieren: Es ist besser, breit zu starten und danach zu qualifizieren, als eng zu starten und zu spät festzustellen, dass relevante Elemente fehlen.
Die vom Kunden erhaltenen ExtrakteDateien aus der Kundenumgebung, die Objekte, Versionen, Metadaten, Nutzung, Differenzen und weitere für das Assessment nützliche Elemente beschreiben. dienen genau dazu, diese erste Momentaufnahme aufzubauen. Sie sind kein bloßer administrativer Anhang: Sie sind das Rohmaterial des gesamten Prozesses. Sie müssen empfangen, aufbewahrt, organisiert und in bearbeitbare Daten transformiert werden, ohne die Verbindung zur ursprünglichen Quelle zu verlieren. Diese Trennung zwischen empfangenen Daten, verarbeiteten Daten und Endergebnissen ist für die Nachvollziehbarkeit entscheidend. Wenn eine Zahl angefochten, ein Objekt wieder aufgenommen oder eine Schätzung überarbeitet wird, muss es möglich sein, den Grund und die Quelle zurückzuverfolgen.
Die Roh-Liste ist daher kein Fehler, der korrigiert werden muss. Sie ist eine notwendige Phase. Sie enthält Rauschen, aber auch wichtige Signale. Die Arbeit des Assessments besteht darin, beides zu unterscheiden. Der Wert liegt nicht darin, sofort eine scheinbar elegante Liste zu produzieren, sondern darin, einen Weg aufzubauen, der klar macht, warum einige Elemente bleiben und andere nicht.
Sichtung ist kein Schnitt: Sie ist Klassifikation
Das Wort „Sichtung“ kann irreführend sein. Es kann den Eindruck eines mechanischen, fast buchhalterischen Schnitts vermitteln: Man nimmt eine Liste, löscht Zeilen und erhält eine kleinere Zahl. In einem seriösen JD Edwards Upgrade ist Sichtung dagegen eine progressive Klassifikation. Jedes Objekt wird innerhalb einer technischen Kategorie gelesen. Ist es ein Standardobjekt? Ist es reines Custom? Ist es eine direkte Änderung an einem Standardobjekt? Ist es eine Kopie eines Standardobjekts? Ist es eine Version? Ist es ein Batch Report? Ist es ein Objekt, das nicht mehr ausgeführt wird? Ist es eine technische Komponente, die nicht als Anwendungsentwicklung geschätzt werden sollte? Ist es eine Anomalie, die dem Kunden vorgelegt werden muss?
Diese Klassifikation macht das Assessment belastbar. Es reicht nicht zu sagen, dass ein Objekt ausgeschlossen wurde. Man muss sagen können, warum. Es reicht nicht zu sagen, dass ein Objekt behalten wurde. Man muss erklären können, welches Risiko es darstellt. Es reicht nicht zu sagen, dass eine Kopie identifiziert wurde. Man muss verstehen, von welchem Standard sie abstammt, ob dieser Standard geändert wurde, wie weit sich die Kopie vom Referenzobjekt entfernt hat und welche Arbeit nötig sein wird, um sie auf die neue Release zu bringen.
In diesem Sinn ähnelt die Sichtung eher einer redaktionellen Überarbeitung als einer automatischen Bereinigung. Eine redaktionelle Überarbeitung löscht keine Sätze zufällig: Sie unterscheidet, was notwendig ist, was redundant ist, was mehrdeutig ist und was neu geschrieben werden muss. Genauso unterscheidet die technische Sichtung Objekte, die Retrofit benötigen, Objekte, die Prüfung benötigen, Objekte, die eine Entscheidung benötigen, Objekte, die nicht auf die Schätzung drücken dürfen, und Objekte, die nicht ignoriert werden können.
Standardobjekte, Änderungen und reines Custom
Eine der ersten Unterscheidungen betrifft die Natur des Objekts. Ein reines Standardobjekt darf nicht wie ein Custom Object behandelt werden. Wenn es keine Kundenanpassung enthält, sollte es nicht als Custom-Retrofit-Aufwand zählen. Das bedeutet nicht, dass der Standard irrelevant ist: Der Standard ist die Referenz, gegen die der Upgrade-Impact gemessen wird. Aber die Schätzung des Custom-Aufwands muss sich auf das konzentrieren, was der Kunde tatsächlich geändert, kopiert, erweitert oder erstellt hat.
Anders ist der Fall direkter Änderungen an Standardobjekten. Hier ist das Problem unmittelbar: Wenn sich der Oracle-Standard in der Zielrelease ändert, muss die Kundenanpassung im neuen Kontext neu interpretiert werden. Es geht nicht nur darum, Code oder Konfiguration von einer Umgebung in eine andere zu verschieben. Es geht darum zu verstehen, ob die Kundenänderung noch gültig ist, ob sie mit dem neuen Standard kollidiert, ob sie entfernt werden kann, weil sie von der Zielrelease absorbiert wurde, oder ob sie neu geschrieben werden muss, um mit dem neuen Verhalten zu koexistieren.
Reines CustomObjekt, das vom Kunden oder für den Kunden erstellt wurde und nicht zwingend von einem Oracle-Standardobjekt abgeleitet ist. stellt ein anderes Problem dar. Wenn es wirklich unabhängig vom Standard ist, benötigt es möglicherweise keinen direkten Vergleich mit einem Oracle-Ausgangsobjekt. Aber dadurch wird es nicht automatisch einfach. Es kann von Tabellen, Funktionen, Business Views, Data Structures, Processing Options oder Logiken abhängen, die sich zwischen Releases ändern. Es kann ohne Fehler kompilieren, aber andere Ergebnisse liefern. Es kann technisch gültig, aber funktional obsolet sein. Deshalb muss auch reines Custom qualifiziert und nicht nur gezählt werden.
Der heikelste Fall: Kopien von Standardobjekten
Kopien von Standardobjekten gehören in einem JD Edwards Upgrade oft zu den kritischsten Objekten. Eine Kopie ist kein Duplikat und kein Objekt, das man verwerfen sollte: Sie ist ein Custom Object, das eine technische Beziehung zu einem Oracle-Standardobjekt bewahrt, dem sogenannten based-onDas Oracle-Standardobjekt, von dem eine Custom-Kopie abstammt oder gegen das sie verglichen werden sollte.. Diese Beziehung ist der Kern des Problems. Wenn eine Kopie von einem Standardobjekt abstammt, hängt ihr Schicksal nicht nur davon ab, was der Kunde an der Kopie getan hat, sondern auch davon, was Oracle in der neuen Release am Standard getan hat.
Wenn Oracle das Standardobjekt in der Zielrelease ändert, kann die Kopie nicht so behandelt werden, als würde sie isoliert existieren. Wenn die Kundenkopie im Wesentlichen identisch mit dem Ausgangsstandard ist, kann die Arbeit relativ einfach sein: Es kann nötig sein, sie ausgehend vom neuen Standard neu zu erstellen oder neu auszurichten. Aber auch in diesem Fall wird sie nicht verworfen. Sie wird als Kopie mit geringer Abweichung klassifiziert, also als Objekt, das möglicherweise einfach zu behandeln ist, aber dennoch dem korrekten Pfad folgen muss.
Das eigentliche Problem entsteht, wenn sich beide Entwicklungslinien bewegt haben. Auf der einen Seite hat Oracle das based-on in der Zielrelease geändert; auf der anderen Seite hat der Kunde die Kopie in seiner eigenen Umgebung geändert. Dann wird das Upgrade zu einer Übung in der Versöhnung zweier unterschiedlicher Geschichten desselben Objekts. Man muss verstehen, welche Oracle-Änderungen wichtig sind, welche Kundenanpassungen erhalten bleiben müssen, welche Teile obsolet sind, welche Teile kollidieren und welcher Weg der sicherste ist, um das finale Objekt wieder aufzubauen. Genau hier kann eine Kopie deutlich schwieriger werden als reines Custom.
Deshalb sollten Kopien von Standardobjekten niemals wie Duplikate behandelt werden. Eine Kopie ist keine Zeile, die man löscht, um die Liste zu erleichtern. Sie ist eine Analysekategorie. In manchen Fällen ist sie einfach, in anderen komplex, in wieder anderen benötigt sie einen sehr detaillierten Vergleich. Aber das Kriterium lautet niemals: „Es ist eine Kopie, also wird sie verworfen.“ Das korrekte Kriterium lautet: Es ist eine Kopie, also muss das based-on identifiziert, die Abweichung gemessen, die Änderung des Standards geprüft und der Rekonstruktionsaufwand geschätzt werden.
Dieses Thema verdient eine eigene Vertiefung, weil es Vergleichstechniken, Ähnlichkeit, Struktur, Namensgebung und funktionales Wissen umfasst. Für eine spezifische Erklärung zur Erkennung von Standardkopien in JD Edwards siehe den Artikel Copies of JD Edwards Standards: how I identify them.
Last Run Date: Wenn reale Nutzung in das Assessment eintritt
Ein weiteres entscheidendes Kriterium ist die Last Run DateDatum der letzten bekannten Ausführung eines Reports oder einer Batch-Version. Es wird als Indikator realer Nutzung verwendet, nicht als absolute Wahrheit., häufig als LRD abgekürzt. Dieser Wert führt eine Dimension ein, die der rein technische Vergleich nicht liefern kann: reale Nutzung. Ein Objekt kann custom, technisch gültig und historisch wichtig sein, aber wenn es lange nicht ausgeführt wurde, ist es vernünftig zu fragen, ob es noch in den operativen Upgrade-Umfang gehört.
Bei Batch Reports und Versionen ist die Last Run Date ein besonders nützlicher Indikator. In JD Edwards ist das letzte Ausführungsdatum einer Batch-Version normalerweise mit der Versions List verbunden, also mit der Tabelle F983051JD Edwards Versionstabelle. Das Feld VRVED wird häufig als Date - Last Executed für Batch-Versionen verwendet., insbesondere mit dem Feld VRVEDFeld, das als Date - Last Executed angegeben wird; es repräsentiert das letzte Ausführungsdatum der Version.. Auch die Historie der submitted jobs kann nützliche Informationen liefern, zum Beispiel über die Logik der submitted jobs und die Tabelle F986110Job Control Status Master: Tabelle, die Statusdatensätze zu Jobs enthält, die an Queues übermittelt wurden.. Diese Daten müssen jedoch vorsichtig gelesen werden: Die Historie kann durch Bereinigungen, Retention, Konfigurationen und unterschiedliche Verhaltensweisen zwischen Umgebungen beeinflusst werden.
Im Assessment-Prozess kann eine praktische Schwelle bei 18 Monaten liegen. Wenn ein Report seit mehr als 18 Monaten nicht ausgeführt wurde, kann er Kandidat für den Ausschluss aus dem operativen Upgrade-Umfang werden. Das wichtige Wort ist „Kandidat“. Es bedeutet nicht, dass der Report automatisch gelöscht, ignoriert oder für nutzlos erklärt wird. Es bedeutet, dass die Nutzungsdaten eine Frage öffnen: Wird dieser Report noch gebraucht? Wurde er ersetzt? Wird er manuell, selten, aber kritisch ausgeführt? Wird er nur beim Jahresabschluss genutzt? Wird er von einem anderen Prozess gestartet, der das erwartete Datum nicht korrekt aktualisiert? Ist er ein Notfallobjekt, das das Business behalten möchte?
Diese Vorsicht ist entscheidend. Ein LRD-basiertes Kriterium darf keine Guillotine werden. Es muss zu einem technischen und funktionalen Gespräch führen. Wenn ein Report seit zwei Jahren nicht gelaufen ist und niemand mehr weiß, wozu er dient, ist es vernünftig, ihn nicht als voll operatives Objekt zu gewichten. Wenn er dagegen seit zwei Jahren nicht gelaufen ist, weil er nur in außergewöhnlichen, aber regulatorisch wichtigen Szenarien verwendet wird, ändert sich die Diskussion. Die Last Run Date trifft die Entscheidung nicht anstelle des Analysten: Sie macht eine Frage sichtbar, die sonst verborgen bliebe.
Die 18-Monats-Schwelle ist keine mathematische Wahrheit
Die 18-Monats-Schwelle ist nützlich, weil sie dazu zwingt, zwischen noch lebenden und wahrscheinlich ruhenden Objekten zu unterscheiden. Sie darf aber nicht als mathematische Wahrheit präsentiert werden. In manchen Kontexten kann ein seit 18 Monaten nicht ausgeführter Report irrelevant sein. In anderen kann er selten, aber unverzichtbar sein. Ein jährlicher Prozess, eine steuerliche Pflicht, eine Audit-Prüfung oder eine Notfallfunktion können geringe Frequenz und hohe Bedeutung haben. Deshalb muss das Zeitkriterium mit Business-Wissen kombiniert werden.
Die korrekte Nutzung der LRD besteht darin, sie in eine Entscheidungsmatrix einzufügen. Ein aktueller Custom Report gehört klar in den Umfang. Ein alter, nicht ausgeführter und vom Business nicht erkannter Report kann Ausschlusskandidat sein. Ein alter, aber vom Kunden bestätigter Report bleibt. Ein Report ohne verlässliche Last Run Date benötigt weitere Prüfung. In allen Fällen muss die Entscheidung nachvollziehbar bleiben.
Das ist auch in der Kundenbeziehung wichtig. Zu sagen: „Diesen Report schätzen wir nicht, weil er seit 18 Monaten nicht gelaufen ist“, ist zu schwach. Zu sagen: „Dieser Report ist Ausschlusskandidat, weil die Last Run Date auf keine aktuelle Nutzung hinweist; wir bitten um funktionale Bestätigung, bevor er aus dem operativen Umfang entfernt wird“, ist deutlich belastbarer. Im ersten Fall wird ein Schnitt auferlegt. Im zweiten wird eine gemeinsame Entscheidung aufgebaut.
Technische Objekte, administrative Objekte und Anomalien
Nicht alle Objekte, die in der Anfangsliste auftauchen, sollten wie Anwendungsentwicklung für Retrofit behandelt werden. Einige gehören zu technischen oder administrativen Kategorien, die eine andere Behandlung erfordern. Es kann Elemente geben, die mit Konfigurationen, Versionen, Metadaten, Supportstrukturen oder Komponenten verbunden sind und keine Anwendungsänderung im klassischen Sinn darstellen. Sie ohne Unterscheidung in die Schätzung aufzunehmen, riskiert, den Umfang aufzublähen und die tatsächlich nötige Arbeit zu verunklaren.
Das bedeutet nicht, dass solche Objekte irrelevant sind. Es bedeutet, dass sie getrennt werden müssen. Ein technisches Objekt benötigt möglicherweise kein Retrofit, aber eine Prüfung. Eine Version ist vielleicht kein Programm, kann aber relevante Processing Options, Data Selection oder operative Einstellungen enthalten. Eine Anomalie wird vielleicht nicht sofort zu Entwicklungsaufwand, kann aber auf ein Risiko hinweisen, das vor dem weiteren Vorgehen geklärt werden muss. Die Qualität des Assessments liegt genau in der Fähigkeit, Entwicklungsarbeit von Prüf-, Konfigurations-, Entscheidungs- oder Bereinigungsarbeit zu unterscheiden.
Anomalien verdienen eine eigene Betrachtung. In einem reifen Prozess dürfen sie nicht versteckt werden. Ein Objekt ohne klare Entsprechung, eine Kopie mit unsicherem based-on, eine Version, die mit einem unklaren Report verbunden ist, ein inkonsistenter Datensatz, ein mehrdeutiger Name oder eine fehlende Information sollten nicht in eine Kategorie gezwungen werden, nur um die Liste zu schließen. Sie müssen hervorgehoben werden. Manchmal löst sich die Anomalie durch eine technische Prüfung. Manchmal erfordert sie die Einbindung des Kunden. Manchmal wird sie zu einer Anmerkung in der Schätzung. In jedem Fall ist eine Liste mit expliziten Warnungen besser als eine scheinbar saubere Liste, die auf undokumentierten Entscheidungen basiert.
Manuelle Wiederaufnahmen: Wenn technisches Urteil den Filter überstimmt
Ein guter Sichtungsprozess darf nicht blind sein. Filter sind notwendig, aber sie dürfen technisches Urteil nicht ersetzen. Es gibt Fälle, in denen ein Objekt nach einem automatischen Kriterium ausschließbar erscheint, aber wieder aufgenommen werden muss, weil der Analyst ein Risiko, eine Abhängigkeit oder eine Besonderheit erkennt. Das gilt besonders für JD Edwards Systeme mit vielen Jahren Historie, in denen lokale Konventionen, nicht standardisierte Namensgebung und projektspezifische Lösungen jede automatische Regel unvollkommen machen können.
Manuelle Wiederaufnahme ist kein Scheitern der Methode. Sie ist ein notwendiger Bestandteil der Methode. Ein vollständig automatisches Assessment kann schnell sein, aber fragil werden. Ein seriöses technisches Assessment kombiniert Regeln, Daten und Urteil. Ziel ist nicht, menschliches Eingreifen zu eliminieren, sondern es nachvollziehbar zu machen. Wenn ein Objekt wieder aufgenommen wird, muss der Grund klar sein. Wenn es trotz Warnung ausgeschlossen wird, muss klar sein, wer die Entscheidung getroffen hat und auf welcher Grundlage.
Dieses Gleichgewicht zwischen Automatisierung und Verantwortung ist einer der Unterschiede zwischen einer von einem Tool erzeugten Liste und einem echten Upgrade-Assessment-Prozess. Das Tool kann beschleunigen, vergleichen, hervorheben, aggregieren und messen. Der finale Wert entsteht jedoch erst, wenn die Ergebnisse im Kontext des Kunden und der Zielrelease interpretiert werden.
Was die historischen Daten zeigen
Um die Methode konkret zu machen, ist der Blick auf eine anonymisierte historische Stichprobe von 54 Assessment-Runs hilfreich. Die Stichprobe enthält 358,046 Objekte in der anfänglichen Roh-Liste. Nach der Qualifizierungsphase enthält die Suggested Object ListListe der Objekte, die nach Ausschlüssen, Prüfungen und Klassifikationen im vorgeschlagenen technischen Umfang bleiben. 145,773 Objekte, während 212,269 Objekte ausgeschlossen oder aus dem operativen Upgrade-Umfang herausgenommen wurden.
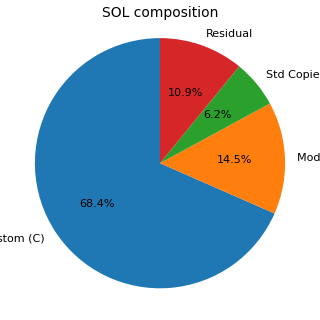
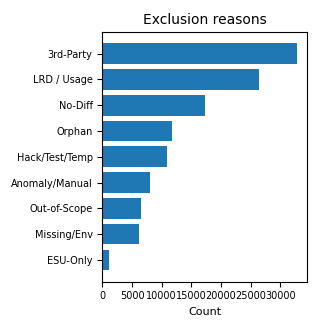
Im ersten Diagramm bezeichnet Residual den Teil der Suggested Object List, der nicht von den drei Kategorien C, M und Y des aggregierten Überblicks abgedeckt wird. Im zweiten Diagramm werden die Ausschlussgründe als Balkendiagramm dargestellt, weil die Kategorien nicht exklusiv sind und daher nicht korrekt als Anteile eines einzelnen Kreisdiagramms dargestellt werden können.
| Indikator | Aggregierter Wert | Interpretation des Werts |
|---|---|---|
| Analysierte Runs | 54 | Assessments mit verfügbarem Detail, das mit der Zusammenfassung verbunden werden kann. |
| Objekte in der Roh-Liste | 358,046 | Bewusst breiter Anfangsumfang. |
| Objekte in der Suggested Object List | 145,773 (40.7%) | Objekte, die im vorgeschlagenen technischen Umfang bleiben. |
| Ausgeschlossene Objekte | 212,269 (59.3%) | Objekte, die nach Anwendung der Sichtungskriterien aus dem operativen Umfang entfernt wurden. |
| Reine Custom Objects in der SOL | 99,733 | Als Custom klassifizierte Objekte. |
| Geänderte Standardobjekte in der SOL | 21,145 | Vom Kunden geänderte Standardobjekte, die im Umfang bleiben. |
| Kopien von Standardobjekten in der SOL | 8,989 (6.2% der SOL) | Standardkopie-Objekte, die als kritische Kategorie und nicht als Duplikate zu behandeln sind. |
| Vor Klassifikation ausgeschlossene Objekte | 212,188 | Objekte, die den Umfang verließen, bevor der Modifikationstyp bestimmt werden musste. |
| Als no-diff ausgeschlossene geänderte Standardobjekte | 17,036 | Objekte, die zunächst als geändert klassifiziert wurden, später aber als am Standard ausgerichtet erkannt wurden. |
| UBE/UBEVER in der Roh-Liste | 69,567 | Reports und Batch-Versionen im anfänglichen Umfang. |
| UBE/UBEVER in der SOL | 30,337 | Reports und Batch-Versionen, die im vorgeschlagenen Umfang bleiben. |
| Ausgeschlossene UBE/UBEVER | 39,229 (56.4% der Raw UBE/UBEVER) | Reports und Batch-Versionen, die nach der Qualifizierung ausgeschlossen wurden oder Ausschlusskandidaten sind. |
| LRD- / nicht aktuelle Nutzungsausschlüsse | 26,328 | Objekte, deren Ausschluss mit Last Run Date oder fehlender aktueller Nutzung begründet ist. |
| No-diff-Ausschlüsse | 17,297 | Objekte, die ausgeschlossen wurden, weil sie keine relevanten Unterschiede zum Standard zeigen. |
| Drittanbieter-Ausschlüsse | 32,896 | Objekte, die auf Komponenten außerhalb des Custom-Umfangs des Kunden zurückzuführen sind. |
| Hack-, Test- oder temporäre Objekte | 10,852 | Objekte, die wegen Tests, temporärer Workarounds oder nicht struktureller Elemente ausgeschlossen wurden. |
| Verwaiste Objekte | 11,676 | Objekte, die keinem klaren operativen Gebrauch mehr zugeordnet werden konnten. |
| ESU-only | 1,162 | Objekte, die ausgeschlossen wurden, weil sie auf Standard-Update-Logiken zurückzuführen sind, die bereits durch den Release-Pfad abgedeckt sind. |
| Missing / Environment | 6,098 | Objekte, deren Ausschluss von Umgebungsbedingungen oder fehlenden Daten abhängt. |
| Außerhalb des Projektumfangs | 6,482 | Objekte, die für den operativen Umfang des Assessments nicht relevant sind. |
| Anomalien / manuelle Prüfung | 8,079 | Fälle, die Aufmerksamkeit, Bestätigung oder technisches Urteil erfordern. |
| Ohne expliziten Grund ausgeschlossen | 89,300 | Datenqualitätsprüfung: ausgeschlossene Zeilen ohne lesbaren Grund im Kommentarfeld. |
Methodische Anmerkung. Ausschlusskategorien sind nicht gegenseitig ausschließende Flags: Dasselbe Objekt kann mehrere dokumentierte Gründe haben, zum Beispiel Testobjekt, Drittanbieter und LRD-Hinweis. Deshalb dürfen die Zeilen zu Ausschlussgründen nicht addiert werden. Der aggregierte Wert zeigt das Gewicht der Kriterien, nicht eine exklusive Aufteilung.
Diese Zahlen machen den Wert der Sichtung sichtbar. In der historischen Stichprobe erreichen etwa 59.3% der Anfangsobjekte die Suggested Object List nicht. Dieser Wert darf nicht als einfache „Reduktion“ gelesen werden, sondern als Ergebnis einer technischen Klassifikation. Die Roh-Liste erfasst alles, was relevant sein könnte; die vorgeschlagene Liste bewahrt, was diskutiert, analysiert oder geschätzt werden sollte. Darunter bleiben fast 8,989 Kopien von Standardobjekten, was einen wesentlichen Punkt bestätigt: Kopien werden nicht als Ausschuss behandelt, sondern als kritische Retrofit-Kategorie.
Die Daten zu UBE und Batch-Versionen sind ebenso bedeutend. Von 69,567 Reports oder Versionen im anfänglichen Umfang bleiben 30,337 in der vorgeschlagenen Liste, und 39,229 verlassen den operativen Umfang. Ein relevanter Teil dieser Ausschlüsse ist mit LRD oder Kriterien nicht aktueller Nutzung verbunden. Auch hier ersetzt die Zahl nicht das Urteil: Ein selten genutzter Report kann kritisch sein, aber ein seit Jahren nicht ausgeführter Report muss zumindest hinterfragt werden, bevor er in der Schätzung Gewicht erhält.
Schließlich zeigt der no-diff-Wert, warum man der Anfangsklassifikation nicht einfach vertrauen darf. In der Stichprobe gibt es 17,036 Objekte, die zunächst der Kategorie geänderter Standardobjekte zugeordnet wurden, später aber ausgeschlossen wurden, weil sie keine relevanten Unterschiede zeigten. Dieser Schritt verhindert, dass die Schätzung künstlich aufgebläht wird: Ein Objekt, das geändert wirkt, darf nicht als Retrofit zählen, wenn der Vergleich zeigt, dass es tatsächlich mit dem Standard übereinstimmt.
Von der Suggested Object List zur Schätzung
Erst nach der Qualifizierungsphase ist eine Schätzung sinnvoll. Die Suggested Object List ist nicht der Endpunkt: Sie ist der Punkt, an dem die Schätzung seriös beginnen kann. Zu diesem Zeitpunkt sind die Objekte keine bloßen Namen mehr. Sie sind klassifizierte Elemente: reines Custom, Änderung am Standard, Kopie eines Standards, Batch Report mit aktueller Nutzung, Batch Report als Ausschlusskandidat, Version mit Override, technisches Objekt, Anomalie, zu prüfende Komponente, Element zur Diskussion mit dem Kunden.
Die Schätzung muss von dieser Klassifikation ausgehen. Reines Custom, direkte Standardänderung und Standardkopie haben nicht dasselbe Risikoprofil. Eine Kopie, die fast identisch mit dem based-on ist, und eine stark abweichende Kopie benötigen nicht denselben Aufwand. Ein gestern verwendeter Report und ein seit Jahren nicht ausgeführter Report haben nicht dasselbe operative Gewicht. Ein Objekt mit Anomalien kann nicht geschätzt werden, als wäre es vollständig klar. Die Schätzung darf kein generischer Durchschnitt über eine Liste sein: Sie muss eine Bewertung sein, die aus der Natur des Objekts abgeleitet ist.
In dieser zweiten Phase wird jedes Objekt in potenzielle Arbeit übersetzt. Die Frage lautet nicht mehr nur „Was ist es?“, sondern „Was muss getan werden, um es korrekt auf die Zielrelease zu bringen?“. Die Antwort kann Rekompilierung, Vergleich, Retrofit, Neuaufbau aus dem neuen Standard, funktionale Prüfung, Test, Anpassung von Processing Options, Kontrolle von Data Selection, Abhängigkeitsanalyse oder einfache Bestätigung des Ausschlusses umfassen. So wird die Schätzung zum Ergebnis einer Kette: Anfangsdaten, Filter, Klassifikation, Entscheidungen, Aufwand.
Warum eine Schätzung ohne Sichtung gefährlich ist
Die Roh-Liste direkt zu schätzen, ist aus zwei gegensätzlichen Gründen gefährlich. Der erste ist Überschätzung. Wenn Standardobjekte, ungenutzte Objekte, nicht anwendungsbezogene technische Elemente oder ruhende Reports in der Liste bleiben, erhält der Kunde eine Schätzung, die durch möglicherweise unnötige Arbeit belastet ist. Das kann das Projekt teurer, schwerer genehmigbar und weniger transparent machen.
Der zweite Grund ist Unterschätzung. Wenn Kopien von Standardobjekten als einfache Duplikate gelesen werden, direkte Standardänderungen wie gewöhnliches Custom behandelt werden oder Anomalien ignoriert werden, kann die Schätzung leichter erscheinen, aber fragil werden. Das Risiko zeigt sich später, wenn das Projekt bereits läuft und die komplexeren Objekte ungeplante Zeit beanspruchen.
Die Sichtung dient dazu, beide Fehler zu vermeiden. Sie ist kein Mechanismus, um die Schätzung zu senken. Sie ist ein Mechanismus, um sie proportional zu machen. Sie nimmt Gewicht heraus, wo keine Arbeit existiert, und fügt Aufmerksamkeit hinzu, wo echtes Risiko besteht. Das ist der wichtigste Punkt gegenüber dem Kunden: Die Reduktion des Umfangs ist keine Abkürzung, sondern eine Form von Präzision.
Nachvollziehbarkeit als Wert der Methode
Ein Upgrade Assessment produziert nicht nur Zahlen. Es produziert Entscheidungen. Jeder Ausschluss, jede Aufnahme, jede Wiederaufnahme und jede Klassifikation ist eine Entscheidung. Wenn diese Entscheidungen nicht nachvollzogen werden können, wird die finale Schätzung schwer verteidigbar. Wenn sie dokumentiert sind, kann der Kunde nicht nur verstehen, wie viel Arbeit erwartet wird, sondern auch warum.
Nachvollziehbarkeit ist auch für das Projektteam wichtig. Wenn das Upgrade in die Ausführungsphase eintritt, müssen die Personen, die an den Objekten arbeiten, wissen, woher die Klassifikation kommt. Sie müssen verstehen, ob ein Objekt als Kopie betrachtet wurde, ob das based-on sicher oder wahrscheinlich ist, ob die Last Run Date die Entscheidung beeinflusst hat, ob ein Report auf Kundenbestätigung ausgeschlossen wurde, ob eine Warnung offen geblieben ist. Ohne diese Erinnerung droht das Assessment zu einem statischen Dokument zu werden. Mit dieser Erinnerung wird es zu einem operativen Werkzeug.
Nachvollziehbarkeit hilft auch, Revisionen zu verwalten. Eine Schätzung kann sich ändern. Ein Kunde kann einen Report wieder aufnehmen. Ein zunächst einfach wirkendes Objekt kann sich als komplex erweisen. Eine Kopie kann eine größere Abweichung zeigen als erwartet. Wenn der Prozess nachvollziehbar ist, ist die Revision verständlich. Wenn nicht, wirkt jede Änderung willkürlich.
Die Rolle des Kunden bei der Validierung des Umfangs
Der Kunde sollte die Suggested Object List nicht als Urteil erhalten. Er sollte sie als technischen Umfang erhalten, der zu validieren ist. Das technische Team kann sagen, dass ein Report seit mehr als 18 Monaten nicht ausgeführt wurde, aber nur der Kunde kann bestätigen, ob dieser Report wirklich aufgegeben wurde. Das technische Team kann eine Kopie identifizieren und ihre Abweichung messen, aber oft ist funktionales Wissen nötig, um zu verstehen, welche Änderungen noch relevant sind. Das technische Team kann eine Anomalie melden, aber der Kunde weiß möglicherweise, dass diese Anomalie einer alten Prozedur, einem Workaround oder einer kritischen Customization entspricht.
Die Qualität des Upgrades hängt daher auch davon ab, wie der Umfang diskutiert wird. Ein Assessment sollte keine isoliert geschlossene Liste produzieren. Es sollte eine begründete Liste erzeugen, begleitet von Kriterien, Notizen, Warnungen und Fragen. So muss der Kunde nicht einfach einer Zahl vertrauen: Er kann den Weg sehen, der diese Zahl hervorgebracht hat.
Das ist besonders wichtig in Projekten mit starkem wirtschaftlichem Druck. Eine zu große Liste schreckt ab. Eine zu kleine Liste erzeugt Risiko. Eine belastbare Liste ermöglicht eine rationale Diskussion: Welche Objekte sind sicher im Umfang, welche sind Ausschlusskandidaten, welche benötigen Bestätigung, welche sind technisch kritisch, welche funktional sensibel.
Von technischen Daten zur Projektentscheidung
Der finale Wert des Verfahrens ist nicht nur technisch. Er ist entscheidungsbezogen. Ein JD Edwards Upgrade ist ein Projekt, in dem Risiko oft aus Unsicherheit entsteht: nicht zu wissen, wie viele Objekte wirklich betroffen sind, nicht zu wissen, welche Kopien kritisch sind, nicht zu wissen, welche Reports noch genutzt werden, nicht zu wissen, ob eine Schätzung nutzlose Objekte enthält oder wichtige ausschließt. Das Verfahren reduziert diese Unsicherheit, indem es verstreute Informationen in sichtbare Entscheidungen transformiert.
Das bedeutet nicht, jeden Zweifel zu beseitigen. In einem komplexen System verschwindet Zweifel nicht. Er wird gesteuert. Einige Objekte bleiben mit Notizen. Einige Entscheidungen benötigen Bestätigung. Einige Schätzungen haben Margen. Einige Kopien benötigen tiefere Analyse. Aber eine deklarierte Marge ist etwas ganz anderes als eine versteckte. Die erste kann diskutiert werden. Die zweite explodiert während des Projekts.
In diesem Sinn ist das Upgrade-Assessment-Verfahren nicht einfach ein Weg, eine Schätzung zu produzieren. Es ist ein Weg, Vertrauen aufzubauen. Vertrauen, dass der Umfang nicht willkürlich ist. Vertrauen, dass kritische Objekte nicht vereinfacht wurden. Vertrauen, dass ungenutzte Reports mit Kriterien behandelt wurden. Vertrauen, dass Kopien von Standardobjekten als das verstanden wurden, was sie sind: oft der heikelste Punkt des Retrofits.
Fazit: Das Upgrade als Reduktion von Unsicherheit
Ein JD Edwards Upgrade ist nicht nur ein technischer Übergang von einer Release zur anderen. Es ist eine Übung in der Reduktion von Unsicherheit. Am Anfang steht eine Masse potenziell relevanter Objekte. Am Ende müssen ein erklärbarer Umfang, eine vorgeschlagene Liste, eine proportionale Schätzung und eine Reihe nachvollziehbarer Entscheidungen stehen. Die wichtigste Arbeit geschieht genau in der Mitte, in der Phase, in der die Roh-Liste in Wissen transformiert wird.
Die Sichtung ist der Kern dieses Prozesses, aber nur, wenn sie richtig verstanden wird. Sie dient nicht dazu, Zeilen zu löschen. Sie dient dazu, zu unterscheiden. Standardobjekte dürfen nicht mit Custom verwechselt werden. Reports, die seit mehr als 18 Monaten nicht genutzt wurden, können Ausschlusskandidaten sein, aber nicht ohne Urteil gelöscht werden. Anomalien müssen hervorgehoben, nicht versteckt werden. Manuelle Wiederaufnahmen sind Teil der Methode, keine peinlichen Ausnahmen. Und Kopien von Standardobjekten sind keine Duplikate: Sie sind oft die heikelsten Objekte, weil sie den Vergleich zwischen der Entwicklung des Kunden und der Entwicklung des Oracle-Standards erzwingen.
Erst wenn diese Arbeit erledigt ist, wird die Schätzung glaubwürdig. Nicht weil sie perfekt ist, sondern weil sie erklärbar ist. Und in einem komplexen Upgrade ist eine erklärbare Schätzung viel mehr wert als eine scheinbar präzise Schätzung ohne technische Erinnerung.
