Sprache auswählen
- Details
- By Vincenzo Caserta
- Kategorie: Database CNC Architecture
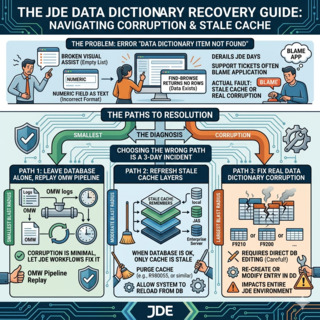
"Data Dictionary Item Not Found" ist der Fehler, der einen JD-Edwards-Tag am schnellsten aus der Bahn wirft. Benutzer sehen einen defekten Visual Assist, ein numerisches Feld, das als Text dargestellt wird, oder einen Find-Browse, der nichts zurückgibt, obwohl er gestern noch Zeilen geliefert hat — und der erste Reflex in der Hälfte aller Support-Tickets, die ich gesehen habe, ist, die Anwendung verantwortlich zu machen. Der eigentliche Fehler liegt jedoch fast immer eine Ebene tiefer: ein Data DictionaryDie JDE-Metadatenschicht, die jedes Data Item definiert (Alias, Länge, Dezimalstellen, Glossar, Edit Rules). Sie steuert, wie jedes Formular, jede BSFN und jedes UBE die zugrunde liegenden Spalten interpretiert.-Eintrag, der nicht mehr zu dem passt, was eine der vier Cache-Schichten darüber gespeichert hat.
Dieser Leitfaden beschreibt das Verfahren, das ich verwende, um JD Edwards Data-Dictionary-Fehler zu beheben: wenn die Korruption echt ist, wenn es nur veralteter Cache ist und wenn der sicherste Weg darin besteht, die Datenbank in Ruhe zu lassen und die OMWObject Management Workbench: die JDE-Konsole, die Check-out, Check-in, Promotion und Audit-Historie jeder Objektänderung verfolgt, einschließlich Data-Dictionary-Items.-Pipeline die Änderung erneut ausführen zu lassen. Die drei Pfade haben sehr unterschiedliche Auswirkungen, und die falsche Wahl macht aus einer 10-Minuten-Korrektur einen 3-Tage-Incident.

- Details
- By Vincenzo Caserta
- Kategorie: Database CNC Architecture
JD Edwards adressiert die entscheidende Herausforderung der Datenintegrität in globalen Lieferketten, in denen disparate Systeme oft zu kostspieligen Synchronisationsfehlern führen. Durch die Bereitstellung eines einheitlichen ERPEnterprise Resource Planning ist eine Software zur Verwaltung zentraler Geschäftsprozesse wie Buchhaltung, Lieferkette und HR in einem einzigen System.-Frameworks ermöglicht es Unternehmen, die Lücke zwischen operativer Ausführung und Finanzberichterstattung zu schließen. Im Jahr 2026 hat sich die Plattform über die traditionelle Datenerfassung hinaus zu einer prädiktiven Engine entwickelt, die Machine LearningEin Teilbereich der künstlichen Intelligenz, der sich auf die Entwicklung von Systemen konzentriert, die aus Daten lernen und darauf basierend Entscheidungen treffen. nutzt, um Routineentscheidungen zu automatisieren. Dieser Wandel von reaktivem zu proaktivem Management stellt sicher, dass Unternehmen ihre Ressourcenzuweisung in Echtzeit optimieren können, was Verschwendung erheblich reduziert und den operativen Durchsatz verbessert.