"Data Dictionary Item Not Found" ist der Fehler, der einen JD-Edwards-Tag am schnellsten aus der Bahn wirft. Benutzer sehen einen defekten Visual Assist, ein numerisches Feld, das als Text dargestellt wird, oder einen Find-Browse, der nichts zurückgibt, obwohl er gestern noch Zeilen geliefert hat — und der erste Reflex in der Hälfte aller Support-Tickets, die ich gesehen habe, ist, die Anwendung verantwortlich zu machen. Der eigentliche Fehler liegt jedoch fast immer eine Ebene tiefer: ein Data DictionaryDie JDE-Metadatenschicht, die jedes Data Item definiert (Alias, Länge, Dezimalstellen, Glossar, Edit Rules). Sie steuert, wie jedes Formular, jede BSFN und jedes UBE die zugrunde liegenden Spalten interpretiert.-Eintrag, der nicht mehr zu dem passt, was eine der vier Cache-Schichten darüber gespeichert hat.
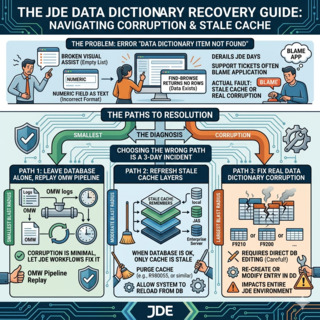
Dieser Leitfaden beschreibt das Verfahren, das ich verwende, um JD Edwards Data-Dictionary-Fehler zu beheben: wenn die Korruption echt ist, wenn es nur veralteter Cache ist und wenn der sicherste Weg darin besteht, die Datenbank in Ruhe zu lassen und die OMWObject Management Workbench: die JDE-Konsole, die Check-out, Check-in, Promotion und Audit-Historie jeder Objektänderung verfolgt, einschließlich Data-Dictionary-Items.-Pipeline die Änderung erneut ausführen zu lassen. Die drei Pfade haben sehr unterschiedliche Auswirkungen, und die falsche Wahl macht aus einer 10-Minuten-Korrektur einen 3-Tage-Incident.
Warum die Cache-Hierarchie fast immer der eigentliche Verursacher ist
Bevor Sie auch nur eine einzige Zeile in F9200 oder F9210 anfassen, verinnerlichen Sie dies: JDE sucht ein Data Item nacheinander über vier bis fünf Cache-Schichten, und jede einzelne davon kann eine veraltete Kopie der Definition enthalten, während alle anderen Schichten korrekt sind. Der Fehler, den der Benutzer sieht, ist identisch, egal ob die Korruption in der Datenbank liegt oder nur in einem Cache, der geleert werden muss.

Der Fat Client, wo er noch existiert, speichert DD-Einträge lokal in den Workstation-Spec-Dateien. Der HTML ServerDer Java-basierte Webserver, der die JDE EnterpriseOne-Weboberfläche bereitstellt. Er hält speicherinterne Caches pro Benutzer und Umgebung für häufig genutzte Metadaten, einschließlich Data-Dictionary-Items. hält einen speicherinternen JVM-Cache, der träge aktualisiert wird. Der Enterprise ServerDas C-basierte Backend, das Call-Object-Kernels, UBE-Kernels und andere Serverprozesse ausführt. Sein DD-Cache liegt im Prozessspeicher jedes Kernels und ist unabhängig vom HTML-Server-Cache. hält seinen eigenen Cache in jedem Call-Object-Kernel — und ja, jeder Kernel hat seine eigene Kopie, weshalb zwei Benutzer, die dasselbe Formular ausführen, unterschiedliches Verhalten sehen können. Darunter liegen die Spec-Tabellen pro Path Code, und darunter die zentralen Master-Tabellen F9200 (Data Item Master), F9202 (Alpha Description), F9203 (Übersetzungen) und F9210 (Data Item Specifications).
Die praktische Regel: In ungefähr 70–80 % der Tickets zu „Data-Dictionary-Korruption“, an denen ich gearbeitet habe, war nichts beschädigt. Eine DD-Änderung war promoted worden, aber eine der darüberliegenden Cacheschichten war nicht aktualisiert, und die Anwendung las einfach eine alte Definition. Das Leeren der Caches in der richtigen Reihenfolge behebt das Problem in weniger als 10 Minuten und berührt die Datenbank nicht.
Die verbleibenden 20–30 % sind echte Korruption: eine Zeile fehlt in F9210, obwohl sie in F9200 existiert, eine veraltete Übersetzung in F9203 für einen nicht mehr aktiven Sprachcode, oder eine Primärschlüssel-Kollision nach einer fehlgeschlagenen Wiederherstellung. Diese Fälle brauchen chirurgische Korrekturen, und genau dort sind die nächsten Abschnitte entscheidend.
Die drei Reparaturpfade und wann welcher zu wählen ist
Sobald Sie bestätigen, dass das Problem über Benutzer und Umgebungen hinweg reproduzierbar ist — also nicht nur ein einzelner veralteter Cache — haben Sie drei Optionen. Die Versuchung ist immer, direkt zu SQL zu springen, und genau das ist fast immer die falsche Entscheidung.

Cache clear über Server Manager ist immer das Erste, was Sie versuchen. Öffnen Sie Server Manager, wählen Sie die betroffene HTML-Server-Instanz, gehen Sie zu Runtime Metrics und leeren Sie den Data-Dictionary-Cache. Danach tun Sie dasselbe auf jedem Enterprise-Server-Logic-Kernel, der die betroffenen Benutzer bedient. Der gesamte Vorgang dauert 5–10 Minuten und ändert keine einzige Zeile in der Datenbank. Wenn das Symptom verschwindet, war die Korruption nie echt — es war ein Cache-Mismatch — und Sie sind fertig.
P92001 (Data Dictionary Design) ist die Standard-JDE-Anwendung zur Verwaltung von DD-Items. Wenn das Leeren des Caches nicht geholfen hat, öffnen Sie P92001 für den betroffenen Alias, prüfen Sie, ob die Definition dem entspricht, was die Anwendung erwartet, und speichern Sie das Item bei Bedarf erneut. P92001 schreibt nach F9200/F9210, propagiert in die Spec-Tabellen, und die Änderung wird Teil des OMW-Audit-Trails. Dies ist der einzige Reparaturpfad, der ein Upgrade oder ein ESU-Retrofit sauber übersteht, weil er eine nachverfolgbare Aufzeichnung hinterlässt, wer was wann geändert hat.
Direct SQL gegen F9200/F9210/F9202/F9203 ist der letzte Ausweg. Sie verwenden ihn nur, wenn P92001 auf der Zeile nicht arbeiten kann — typischerweise wegen eines verwaisten Datensatzes, eines Duplikats, das nicht existieren sollte, oder einer Primärschlüsselverletzung. SQL-Chirurgie erfordert ein vollständiges Backup der vier Tabellen vor Beginn, die Freigabe durch DBA und CNC-Team und unmittelbar danach einen Integrity Report. Aus JDE-Sicht ist sie nicht auditierbar: Die Änderung hinterlässt keine OMW-Spur, keine Versionshistorie, keinen Rollback-Button.
Die Diagnoseabfragen, die zeigen, was wirklich falsch ist
Bevor Sie entscheiden, welchen Pfad Sie nehmen, führen Sie die vier Abfragen aus, die die Korruption lokalisieren. Sie dauern Sekunden und sparen Stunden des Ratens.
Prüfen Sie zuerst, ob das Data Item in F9200 (Master) und F9210 (Specifications) existiert:
SELECT FRDTAI, FRDSCR, FRSY FROM F9200 WHERE FRDTAI = 'YOUR_ALIAS';
SELECT FROMDTAI, FROOWTP, FROODA FROM F9210 WHERE FROMDTAI = 'YOUR_ALIAS';Wenn F9200 eine Zeile zurückgibt, F9210 aber null, haben Sie einen klassischen Orphan: Der Master existiert, die Spezifikationen nicht, und jedes Formular, das den Alias referenziert, wird fehlschlagen. Das Gegenteil — F9210 ohne F9200 — ist seltener, aber schlimmer, weil der Spec Compiler etwas zum Kompilieren hat, die Anwendung den Master aber nie finden kann.
Prüfen Sie als Zweites die Alpha Descriptions in F9202 und die Übersetzungen in F9203 für die am Standort verwendeten Sprachen:
SELECT FRLNGP, FRALPH FROM F9202 WHERE FRDTAI = 'YOUR_ALIAS';
SELECT FRLNGP, FRALPH FROM F9203 WHERE FRDTAI = 'YOUR_ALIAS';Eine fehlende F9203-Zeile für die aktive Sprache eines Benutzers ist die häufigste Ursache für Beschwerden über „leere Labels“ — das Feld hat eine Beschreibung auf Englisch, aber nicht auf Italienisch, und italienische Benutzer sehen eine leere Überschrift. Das ist fast nie „Korruption“; es ist eine Übersetzung, die nie angelegt wurde.
Drittens vergleichen Sie den Master mit den zentralen Spec-Tabellen für den aktiven Path Code. Die Spec-Tabellen liegen in der path-code-spezifischen Data Source (DD910, DV920, PY920, PD920 je nach Release und Path Code) und werden vom Package-Build-Prozess befüllt. Wenn F9210 sagt decimals = 2 und die Spec-Tabelle sagt decimals = 0, liest die Anwendung die Spec-Tabelle — der Datenbank-Master ist korrekt, die kompilierten Specs sind falsch, und Sie brauchen einen Partial Package Build des betroffenen DD-Items, keine Datenbankkorrektur.
Viertens führen Sie R9202 (Data Dictionary Repair) als Select gegen den Alias aus, um einen von JDE erzeugten Bericht über die Integrität der vier Tabellen zu erhalten. R9202 meldet Orphans, fehlende Übersetzungen und inkonsistente Definitionen in einer Ausgabe, formatiert so, wie Oracle Support sie erwartet, falls Sie eskalieren.
Cache-Clear-Reihenfolge: Die falsche Reihenfolge verschwendet den Vorgang
Wenn Sie entscheiden, dass das Problem Cache ist, ist die Reihenfolge entscheidend. Wenn Sie den Enterprise-Server-Cache vor dem HTML-Server-Cache leeren, kann der HTML Server den Enterprise-Server-Cache bei der nächsten Benutzeranfrage mit seinen eigenen veralteten Daten wieder befüllen. Die richtige Reihenfolge ist top-down: zuerst Fat Clients, falls beteiligt, dann HTML Server, dann Enterprise-Server-Kernels, dann prüfen, ob die Spec-Tabellen aktuell sind.
Auf dem HTML Server stellt Server Manager „Clear Data Dictionary Cache“ unter den Runtime Metrics der JAS-Instanz bereit. Das leert den speicherinternen JVM-Cache ohne Neustart der JVM, sodass Benutzer in aktiven Sessions nicht unterbrochen werden. Der nächste DD-Lookup eines beliebigen Benutzers zieht eine frische Kopie von unten.
Auf dem Enterprise Server liegt der Cache im Prozessspeicher jedes Call-Object-Kernels. Ihn zu leeren erfordert entweder einen Neustart des Kernels (unterbricht laufende Calls) oder die Runtime Command Interface des Kernels über Server Manager. In der Praxis ist in einer stark genutzten Umgebung ein Rolling Restart der Call-Object-Kernels der sauberste Ansatz — einen Teil herunterfahren, den Load Balancer umleiten lassen, wiederholen. Der gesamte Vorgang auf einem 16-Kernel-Setup dauert etwa 8–12 Minuten und ist für Benutzer unsichtbar.
Die Spec-Tabellen (DD3xxxnn-style central spec store) werden während Package Builds aktualisiert. Wenn eine DD-Änderung promoted wurde, aber kein Package Build gelaufen ist, sind die Spec-Tabellen veraltet und kein Cache-Clearing hilft — die Kernels lesen korrekten Cache aus falschen Specs. Ein Partial Package Build des betroffenen DD-Items, typischerweise 5–15 Minuten je nach Umgebungsgröße, ist die Korrektur.
Wenn SQL unvermeidbar ist, das sichere Verfahren
SQL-Chirurgie an den F92xx-Tabellen ist nur gerechtfertigt, wenn P92001 die Zeile nicht korrigieren kann und der Integrity Report einen echten Orphan oder ein echtes Duplikat bestätigt. Das Verfahren ist:
Schritt eins: vollständiges Tabellenbackup von F9200, F9202, F9203, F9210 in der betroffenen Data Source, mit Datum im Backup-Namen. Kein logischer Export — eine CREATE TABLE AS SELECT-Kopie, mit der Sie später Vergleiche auf Zeilenebene durchführen können. Diesen Schritt zu überspringen ist der Weg, wie aus einer 20-Minuten-Korrektur eine Restore-from-Tape-Situation wird.
Schritt zwei: jede Zeile identifizieren, die von der anstehenden Änderung betroffen ist. Wenn Sie einen Orphan aus F9210 entfernen, suchen Sie nach zugehörigen Zeilen in F9202, F9203 und den Spec-Tabellen, die denselben Alias referenzieren. Eine saubere Korrektur entfernt zugehörige Zeilen in einer einzigen Transaktion; verbleibende Fragmente in F9203 bedeuten, dass die nächste Benutzerabfrage für diesen Alias einen anderen Fehler trifft.
Schritt drei: DML innerhalb einer Transaktion mit explizitem Rollback bei Fehler. Für eine verwaiste F9210-Zeile ohne F9200-Master ist die sichere Form:
BEGIN;
DELETE FROM F9210 WHERE FROMDTAI = 'ORPHAN_ALIAS'
AND NOT EXISTS (SELECT 1 FROM F9200 WHERE FRDTAI = 'ORPHAN_ALIAS');
-- verify row count matches expectation before commit
COMMIT;Schritt vier: R9202 erneut ausführen. Der Bericht sollte für den betroffenen Alias nun sauber zurückkommen. Wenn er weiterhin ein Problem meldet, stellen Sie aus dem Backup wieder her und eskalieren — Sie sind auf etwas gestoßen, das die einfache Löschung nicht behebt.
Schritt fünf: Caches top-down leeren (HTML, Enterprise, wiederholen) und das betroffene DD-Item über einen Partial Package Build erneut in die Spec-Tabellen bauen. Ohne das ist die Datenbank nun korrekt, aber die Kernels lesen weiterhin den alten defekten Zustand aus ihrem eigenen Cache.
Schritt sechs: Die Korrektur im CNC Change Log dokumentieren, mit Alias, ausgeführtem SQL, Row Counts vorher und nachher und Ausgabe des Integrity Reports. SQL-Chirurgie ist aus OMW-Sicht nicht auditierbar, daher ist der einzige Audit Trail der, den Sie selbst schreiben.
Die Fehler, die aus einer 10-Minuten-Korrektur einen 3-Tage-Incident machen
Der erste Fehler ist, das Cache-Clearing zu überspringen und direkt zu SQL zu gehen. In ungefähr 75 % der Fälle war der für Benutzer sichtbare Fehler nie Datenbankkorruption — es war ein Kernel, der veralteten Cache gelesen hat. SQL-Chirurgie hilft in dieser Situation nicht, hinterlässt eine nicht auditierbare Änderung, die später untersucht werden muss, und riskiert echte Korruption zusätzlich zu einem Nichtproblem.
Der zweite ist, Caches in der falschen Reihenfolge zu leeren. Zuerst den Enterprise-Server-Cache zu leeren und dann den HTML Server mit seiner eigenen veralteten Kopie dagegen aktualisieren zu lassen, ist der klassische Weg, eine Stunde damit zu verbringen, sich zu fragen, warum sich nichts geändert hat. Top-down ist jedes Mal die Regel.
Der dritte ist, die Änderung in PD vorzunehmen, ohne sie zuerst durch DV und PY zu spielen. Selbst eine Notfallkorrektur sollte in DV angewendet, verifiziert und dann über PY nach PD mit einem nachverfolgten OMW-Projekt promoted werden — oder zumindest sollte das SQL-Replay-Skript nach stabiler PD-Situation erneut gegen PY und DV ausgeführt werden. Umgebungen nicht synchron zu halten macht das nächste Upgrade oder Refresh zu einer Diskrepanzsuche.
Der vierte ist zu vergessen, dass DD-Items in kompiliertem C-Code innerhalb von BSFNs über Aliase referenziert werden. Wenn Sie die Größe oder Dezimalstellen eines DD-Items ändern, ohne jede BSFN neu zu bauen, die es verwendet, sieht die Runtime ein Mismatch zwischen der C-Struktur und der neuen DD-Definition. Dieses Mismatch kann harte Runtime-Fehler im Call-Object-Kernel verursachen — nicht so dramatisch, wie ältere Artikel gern behaupten, aber real und nur durch einen vollständigen BSFN-Rebuild der betroffenen B-Objects zu beheben.
Der fünfte ist, F9203-Korruption als Datenbankproblem zu behandeln. Die meisten Tickets zu „fehlender Übersetzung“ sind überhaupt keine Korruption — es sind Übersetzungszeilen, die für den Sprachcode des Benutzers schlicht nie angelegt wurden. Die Korrektur ist ein P92001-Update mit der fehlenden Übersetzung, keine SQL-Reparatur gegen F9203.
Wenn diese Art operativer Details das ist, was Sie für Ihre tägliche JD Edwards CNC- und Datenbankarbeit brauchen, behandeln die verwandten Artikel auf dieser Website OMW-Projektmuster, Package-Build-Interna und SQL-seitige Optimierungen auf Standard-JDE-Tabellen. Das Projektportfolio zeigt, wo diese Techniken in realer Produktionsunterstützung angewendet wurden.
