
Den Index einer BSVWBusiness View: ein JD-Edwards-Objekt, das eine oder mehrere Tabellen verbindet und Anwendungen sowie Reports einen festen Satz von Spalten und einen ausgewählten Index bereitstellt. zu ändern, sieht nach einem Fünf-Minuten-Klick in BVDABusiness View Design Aid: das JD-Edwards-Werkzeug, mit dem festgelegt wird, welche Tabellenspalten und welchen Schlüssel die Business View den Anwendungen bereitstellt. aus, und genau deshalb beschädigt diese Änderung mehr Reports als jede andere einzelne Änderung in JD Edwards EnterpriseOne. Eine BSVW kann potenziell von Dutzenden UBEs, APPLs und form interconnects gelesen werden; wenn ihre Schlüsseldefinition in OMWObject Management Workbench: die JD-Edwards-Konsole, die check-out, check-in, Projektverfolgung und die Promotion von Objekten zwischen path codes steuert. von Index 2 auf Index 4 umgestellt wird, ändert sich die Zeilenreihenfolge, die jeder Consumer sieht. Wenn auch nur einer von ihnen auf die vorherige Sortierung angewiesen war, haben Sie gerade einen stillen Datenfehler in die Produktion eingeführt.
Dies ist das Verfahren, das ich für eine JD-Edwards-BSVW-Indexänderung mit OMW und BVDA verwende — die genaue Reihenfolge, die Abhängigkeitsprüfung, die ich vor jeder Änderung am Objekt durchführe, und der Rebuild-Pfad, der die Änderung sauber durch DVEntwicklungsumgebung in JD Edwards: der path code, in dem Entwickler Objekte auschecken, ändern, bauen und Unit-Tests ausführen, bevor sie promotet werden., PYPrototype-Umgebung in JD Edwards: der path code, der für Integrationstests und User Acceptance verwendet wird, bevor Objekte in die Produktion promotet werden. und PDProduktions-path code in JD Edwards EnterpriseOne. Die Live-Umgebung, in der Business-User Transaktionen durchführen; Änderungen werden hier per OMW-Promotion aus PY ausgerollt. hält.
Warum eine BSVW-Indexänderung nie nur eine BSVW-Änderung ist
Eine BSVW speichert keine Daten. Sie ist eine gespeicherte SQLStructured Query Language: die Standardsprache zum Abfragen und Manipulieren relationaler Datenbanken. JDE generiert SQL hinter jeder BSVW, jedem Fetch und jedem UBE.-Definition über einer oder mehreren zugrunde liegenden Tabellen, mit einem ausgewählten Index, der zwei Dinge bestimmt: die Form der WHERE-Klausel und das standardmäßige ORDER BY. Wenn Sie den Index ändern, zum Beispiel vom datumsbasierten Schlüssel zum dokumentnummernbasierten Schlüssel, ändern die vom Runtime erzeugten WHERE-Klauseln ihre Form, und die Reihenfolge, in der Zeilen zurückkommen, ändert sich mit ihnen. Jeder Consumer, der Ergebnisse in der Annahme einer Datumssortierung durchlief, durchläuft sie nun in Dokumentnummernreihenfolge, und Aggregationen, Breaks sowie Logiken vom Typ "first record wins" kippen ohne Vorwarnung.
Das zweite Problem ist die Anzahl der Consumer. Eine einzelne BSVW, die in einer typischen Betriebsumgebung verwendet wird, kann 10–30 UBEs und 5–15 application forms versorgen. Die 30-Sekunden-Aufgabe, den Schlüssel in BVDA zu ändern, wird zu einer 3–4-Stunden-Aufgabe: jeden Consumer finden, öffnen und bestätigen, dass keiner von ihnen von der vorherigen Sortierung abhängt. Diesen Schritt zu überspringen, verwandelt eine saubere Indexoptimierung zwei Wochen später in einen Produktionsvorfall, wenn Monatsabschluss-Aggregationsreports beginnen, Zeilen in die falsche Gruppe zu legen.
Das dritte Problem ist, dass der Index tatsächlich auf der zugrunde liegenden Tabelle existieren muss. Der Dialog "Select Key" von BVDA listet jeden Index auf, der auf der Primärtabelle auf Ebene des data dictionaryJD Edwards Data Dictionary: das zentrale Repository für Data-Item-Definitionen (Fxxxx-Tabellen, GTxxxx-Arbeitsfelder), das Validierung, Anzeige und Spaltenmetadaten steuert. definiert ist. Wenn Sie einen Schlüssel benötigen, der noch nicht existiert, führen Sie keine BSVW-Änderung durch — Sie führen eine Tabellenänderung durch, die um eine Größenordnung invasiver ist und die Beteiligung des CNCConfigurable Network Computing: die JD-Edwards-Administrationsdisziplin, die Umgebungen, path codes, server packages und Datenbank-Deployments verantwortet.-Teams erfordert.
Die Abhängigkeitsprüfung, die ich vor jeder Änderung am Objekt durchführe
Führen Sie vor jedem check-out die Cross-Reference-Suche in P980011Cross Application Reference Repository-Anwendung in JD Edwards: ermöglicht das Auflisten jedes Objekts (UBE, APPL, NER, BSFN), das auf eine bestimmte BSVW, BSFN oder Tabelle verweist. gegen den BSVW-Namen aus. Die Ausgabe ist die vollständige Liste der UBEs, APPLs und NERs, die darauf verweisen. Für jeden Consumer gibt es zwei Fragen: iteriert er das Result Set, und enthält er Logik, die von der Reihenfolge abhängt? Wenn beides zutrifft, muss dieser Consumer vor Freigabe der Änderung auf die Regressionsliste.
Eine nützliche Abkürzung: Lesen Sie die Tabellen F9860 (Object Librarian Master) und F980011 (XREF) direkt mit einem SQL-Client. Eine einfache Abfrage — SELECT FOOBNM, FOMODNAME FROM F980011 WHERE FOPONM = 'V55XXXXA' — gibt Ihnen dieselbe Antwort in einer Sekunde, statt sich durch OMW-Suchergebnisse zu klicken. Der XREF-Index muss in JDE regelmäßig neu aufgebaut werden; wenn Ihr letzter Rebuild Monate zurückliegt, ist die Liste veraltet und Sie übersehen kürzlich hinzugefügte Consumer. Führen Sie zuerst den XREF-Refresh aus.
Erfassen Sie für jeden Consumer, der von der Reihenfolge abhängt, einen "before"-Snapshot. Führen Sie den UBE in DV gegen einen eingefrorenen Datensatz aus und speichern Sie die Ausgabe. Derselbe Datensatz und derselbe UBE werden nach der Änderung erneut ausgeführt; der Diff zwischen den beiden Ausgaben ist Ihr Akzeptanzkriterium. Ohne diesen Snapshot diskutieren Teams am Ende mit Benutzern darüber, ob der Report "anders aussieht" — es gibt keine Messung, nur Meinungen.
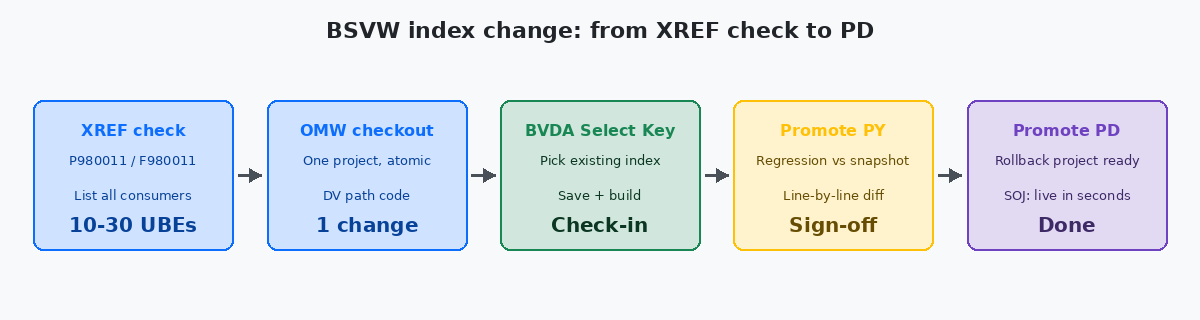
Die OMW- und BVDA-Sequenz, Schritt für Schritt

Die eigentliche Mechanik besteht aus acht Schritten, alle in DV, alle über OMW:
- Öffnen Sie OMW (P98220W) und suchen Sie die BSVW nach Namen (z. B.
V55XXXXA). - Fügen Sie das Objekt einem aktiven OMW-Projekt hinzu. Wenn Ihnen kein Projekt gehört, erstellen Sie eines; checken Sie das Objekt nicht in das Projekt einer anderen Person aus.
- Checken Sie die BSVW aus. OMW warnt, wenn sie bereits von einem anderen Entwickler ausgecheckt ist — brechen Sie diese Sperre niemals, ohne dies mit ihm zu bestätigen.
- Öffnen Sie sie in Business View Design Aid (BVDA).
- Aus dem Menü: View → Select Table Columns. Bestätigen Sie, dass die Primärtabelle und die Spaltenliste genau Ihren Erwartungen entsprechen. Ändern Sie die Spaltenauswahl nicht im selben Checkout wie eine Indexänderung — halten Sie Änderungen atomar.
- View → Select Key. Der Dialog listet jeden Index auf, der auf der Primärtabelle definiert ist. Wählen Sie das neue key item. Notieren Sie die Schlüsselnummer, die Sie verlassen, und die, zu der Sie wechseln; Sie benötigen beide für das OMW-Änderungsprotokoll.
- Speichern und bauen Sie die BSVW. Ein BSVW-Build ist schnell (Sekunden), muss aber lokal erfolgreich sein, bevor Sie einchecken können.
- Checken Sie ein. Dokumentieren Sie im OMW-Kommentar den alten Schlüssel, den neuen Schlüssel und die Consumer-Anzahl aus der XREF-Suche. Das ist die Audit-Spur, die Sie rettet, wenn jemand sechs Monate später fragt, warum sich die Sortierreihenfolge geändert hat.
Wenn der Build fehlschlägt, liegt die Ursache fast immer darin, dass die Spaltenliste noch auf eine Spalte verweist, die in der Tabelle des neuen Schlüssels nicht existiert — typisch, wenn die Primärtabelle in einem früheren Checkout geändert und nicht sauber committet wurde. Die Lösung ist Revert, nicht Erzwingen.
Wenn der benötigte Index noch nicht existiert
Wenn "Select Key" den benötigten Index nicht anzeigt, haben Sie zwei Optionen, und sie haben sehr unterschiedliche blast radii. Option eins: den nächstliegenden vorhandenen Index wählen und den Kompromiss akzeptieren. Option zwei: einen neuen Index auf der Tabelle selbst erstellen. Die zweite Option bedeutet eine Tabellenänderung, und eine JDE-Tabellenänderung ist grundlegend anders als eine BSVW-Änderung.
Eine Tabellenänderung berührt TDATable Design Aid: das JD-Edwards-Werkzeug zum Definieren von Tabellenspalten, Indizes und Primärschlüsseln sowie zum Generieren des DDL, das die physische Datenbanktabelle erstellt oder ändert. (Table Design Aid), generiert neues DDL und erfordert, dass die Datenbank in jeder Umgebung physisch neu aufgebaut oder geändert wird. Der neue Index muss in DV, PY und PD existieren, bevor eine BSVW oder ein UBE, der darauf zeigt, funktioniert. Das Deployment gehört CNC, nicht dem Entwickler, der den Index benötigt. Planen Sie für Server-Package-Erzeugung und Deployment typischerweise einen Zyklus von 1–3 Tagen ein, abhängig vom Release-Kalender der Umgebung.
Das andere Risiko besteht darin, dass das Hinzufügen eines Index zu einer standardmäßigen JDE-Tabelle (z. B. F4211, F0911, F4101) etwas ist, das Oracle Support mit Ihnen diskutieren wird, wenn ein künftiger ESU dieselbe Tabelle berührt. Sie ändern keine Schema-Spalten — Sie fügen einen Index hinzu —, aber die Auswirkung auf den Insert/Update-Durchsatz einer Hochvolumentabelle ist real und messbar. Einen Index zu F4211 in einem Distributionsbetrieb hinzuzufügen, der täglich 100.000 Verkaufsauftragszeilen verarbeitet, ist ein CNC-Gespräch, keine reine Entwicklerentscheidung.
Wenn Sie diesen Weg gehen: checken Sie die Tabelle in OMW aus, öffnen Sie TDA, fügen Sie den Index mit den Spalten in exakt der Reihenfolge hinzu, die von der gewünschten Form der WHERE-Klausel benötigt wird, speichern und bauen Sie, und promoten Sie dann durch die Standard-path codes. Erst danach kann die BSVW geändert werden, um ihn zu verwenden. Zwei separate OMW-Projekte, zwei separate check-ins, zwei separate Deployment-Fenster.
Build und Deployment der Änderung über DV, PY, PD
Sobald die BSVW in DV eingecheckt ist, ist die Änderung für niemanden sichtbar außer für einen Entwickler, der in DV testet. Damit sie Endbenutzer erreicht, muss das OMW-Projekt promotet werden: DV → PY → PD. Jede Promotion benötigt einen CNC-gesteuerten Server-Package-Build für den Ziel-path code. Eine BSVW allein erfordert keinen vollständigen Package-Build, wenn Sie specs over JavaSOJ (Specs Over Java): der JDE-Deployment-Modus, bei dem Objektspezifikationen vom Deployment-Server bereitgestellt werden, statt in ein vollständiges Client-Package eingebettet zu sein, wodurch ein vollständiger Package-Build bei jeder Änderung entfällt. (SOJ) verwenden — das ist einer der Hauptvorteile von SOJ und auf jeder modernen Tools Release der Standard.
In SOJ-aktivierten Umgebungen wird die BSVW-Spec aus dem zentralen Spec-Store übernommen, sobald die OMW-Promotion ankommt. Die Änderung ist für den Ziel-path code sofort live. Bei einem Nicht-SOJ-Deployment (selten auf aktuellen Tools Releases, aber an manchen Standorten noch vorhanden) sind ein vollständiger Client-Package-Build und ein Deployment erforderlich, bevor die Änderung sichtbar wird — ein Build-Fenster von 30–60 Minuten, abhängig von der Größe der Umgebung.
Der Regressionstest findet in PY statt, nicht in DV. PY hat produktionsähnliche Datenvolumen und die tatsächlichen Consumer-UBEs sind so geplant, wie Benutzer sie ausführen. Führen Sie jeden Consumer auf der Regressionsliste gegen den eingefrorenen Snapshot aus, der vor der Änderung erstellt wurde. Vergleichen Sie Zeile für Zeile. Erst wenn jeder Consumer den Erwartungen entspricht, erhält die Änderung grünes Licht für PD.
In PD ist das Deployment-Fenster das, was Ihre Change-Management-Richtlinie vorgibt. Die BSVW-Änderung selbst landet in Sekunden. Das Risiko ist nicht das Deployment — es ist der erste UBE, der nach dem Deployment läuft und ein Ergebnis zeigt, das niemand erwartet hat. Halten Sie das Rollback-OMW-Projekt bereit: ein zweites Projekt, das die vorherige BSVW-Spec enthält, eingecheckt, aber noch nicht promotet, damit ein CNC-Engineer in Minuten demoten kann, falls ein Benutzer in der ersten Stunde eine Regression meldet.
Die Fehler, die dieses Verfahren in der Praxis brechen
Der häufigste Fehlermodus ist das Überspringen des XREF-Schritts. Ein Entwickler ändert den Schlüssel in BVDA, baut, promotet und erfährt erst zwei Wochen später, dass ein Monatsabschluss-UBE von der alten Sortierung abhängig war. Zu diesem Zeitpunkt wurde ein ganzer Monat von Reports mit falscher Zeilenreihenfolge ausgegeben, und sie neu auszugeben ist ein Finance-Gespräch, kein Development-Gespräch.
Der zweite Fehler ist, eine Schlüsseländerung mit einer Spaltenänderung im selben Checkout zu bündeln. Wenn etwas bricht, können Sie nicht erkennen, welche Änderung es verursacht hat. Atomare Checkouts sind keine Bürokratie — sie halten die Rollback-Story einfach. Eine Änderung pro Checkout, ein OMW-Projekt pro Änderung.
Der dritte Fehler ist, den neuen Index auf einer standardmäßigen JDE-Tabelle zu erstellen, ohne CNC zu konsultieren. Eine kundenspezifische Tabelle mit B55-Präfix ist Ihr Entwicklerbereich; F4211 ist es nicht. Einen Index ohne CNC-Sign-off zu einer Standardtabelle hinzuzufügen, kann dazu führen, dass dieser Index bei der nächsten ESU-Anwendung stillschweigend entfernt wird — oder schlimmer, zu einem Performanceproblem in Produktion auf einem Codepfad, den Sie nicht gemessen haben.
Der vierte Fehler ist, BSVW-Promotion als reine Entwickleraufgabe zu behandeln. In SOJ-Umgebungen ist der Klick klein, aber die Änderung erreicht jeden UBE-Consumer in dem Moment, in dem die Spec landet. Es gibt keinen Soft-Launch. Die Disziplin, die dies sicher macht, ist die Regressionsliste und der eingefrorene Dataset-Snapshot, nicht die OMW-UI selbst.
Wenn diese Art von Verfahrensdetail das ist, was Sie für die tägliche JD-Edwards-Betriebsarbeit benötigen, behandeln die verwandten Artikel auf dieser Website SQL-Datenanalyse auf Standard- und Custom-Tabellen, BSFN-Performance-Messung mit Logs und Timings sowie OMW-Projektmuster, die Multi-Developer-Umgebungen sicher machen. Das Projektportfolio zeigt, wo diese Techniken in echten Upgrade- und Retrofit-Arbeiten angewendet wurden.
