Sprache auswählen
Mein Blog

- Details
- By Vincenzo Caserta
- Kategorie: Mein Blog
Aktuelle Telemetriedaten aus dem Jahr 2026 deuten darauf hin, dass ein durchschnittlicher Enterprise-Webserver inzwischen mehr als 1,2 Terabyte Logdaten pro Monat erzeugt — ein Volumen, das manuelle Prüfung nicht nur ineffizient, sondern für menschliche Operatoren mathematisch unmöglich macht. In einer Zeit, in der MicroservicesEin Architekturstil, der eine Anwendung als Sammlung kleiner, autonomer Services strukturiert, die an einer Geschäftsdomäne ausgerichtet sind. die Infrastruktur prägen, hat sich das einfache Nginx-Log von einer Textdatei zu einem kritischen Hochgeschwindigkeits-Datenstrom entwickelt. Dennoch bleiben viele Administratoren an veraltete manuelle Arbeitsweisen gebunden, die den tatsächlichen Zustand ihrer Infrastruktur nicht erfassen. Zu verstehen, wie man Nginx-Logmanagement automatisiert, ist kein Luxus mehr, sondern eine Grundvoraussetzung für Systemintegrität und Performance in einer hypervernetzten Welt.
- Details
- By Vincenzo Caserta
- Kategorie: Mein Blog
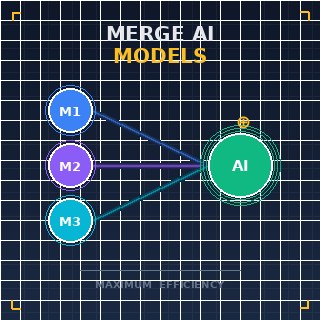
In einem Hightech-Labor in Zürich starrt ein Data Scientist auf einen Terminal-Bildschirm, auf dem zwei verschiedene neuronale Geister im Begriff sind, eins zu werden. Ein Modell ist ein Meister der Molekularbiologie, während das andere ein Experte für Strömungsmechanik ist; einzeln sind sie brillant, aber zusammen könnten sie Systeme zur Medikamentenverabreichung revolutionieren. Dies ist die Realität des Jahres 2026, in der die primäre Herausforderung nicht mehr nur darin besteht, größere Systeme zu bauen, sondern herauszufinden, wie man mehrere spezialisierte Large Language Models (LLMs)KI-Systeme, die auf riesigen Textmengen trainiert wurden, um menschenähnliche Sprache zu verstehen und zu generieren. zu einer einzigen, kohärenten Intelligenz verschmilzt. Dieser Prozess, bekannt als Model Merging, hat sich von einer experimentellen Kuriosität zu einem kritischen Engineering-Standard entwickelt, der es Entwicklern ermöglicht, die Stärken verschiedener Architekturen zu synthetisieren, ohne die prohibitiven Kosten eines erneuten Trainings von Grund auf.

- Details
- By Vincenzo Caserta
- Kategorie: Mein Blog
Stellen Sie sich einen Genomforscher im Jahr 2026 vor, der versucht, eine einzelne Proteinvariante aus einer Bibliothek von fünfzigtausend Einträgen mit einem Standard-HTML-Select-Element zu isolieren. Der Browser friert ein, die Bildlaufleiste wird mikroskopisch klein, und die Benutzererfahrung bricht unter der Last übermäßiger DOMDas Document Object Model ist eine Programmierschnittstelle für Webdokumente, die die Seite so darstellt, dass Programme Struktur und Inhalt ändern können.-Knoten zusammen. Um dies zu lösen, müssen wir über statische Elemente hinausgehen und programmierbare Komponenten einsetzen. Zu lernen, wie man ein dynamisches durchsuchbares Dropdown erstellt, ist nicht mehr nur eine UI/UXUser Interface und User Experience Design konzentrieren sich auf die ästhetischen und funktionalen Aspekte der Interaktion zwischen Mensch und Software.-Präferenz; es ist eine technische Notwendigkeit für leistungsstarke Datenmanagement- und wissenschaftliche Visualisierungsplattformen.

- Details
- By Vincenzo Caserta
- Kategorie: Mein Blog
Warum scheitern unsere fortschrittlichsten Vorhersagemodelle, obwohl sie auf der teuersten Hardware des Jahres 2026 trainiert wurden, immer noch an geringfügigen Änderungen des Umgebungskontexts? Dieser Fehler ist kein Software-Bug, sondern eine mathematische Unausweichlichkeit: die Unfähigkeit aktueller Architekturen, JD (Joint Distributions) erfolgreich von einer Quelldomäne in eine Zieldomäne zu migrieren. Während wir die Grenzen autonomer Systeme und wissenschaftlicher Echtzeitmodellierung erweitern, hat die Industrie endlich erkannt, dass Daten keine statische Ressource sind. Um die Genauigkeit aufrechtzuerhalten, müssen wir Daten als fluide Entität betrachten, die anspruchsvolle Translokationsstrategien erfordert. Zu verstehen, wie man JD migriert, ist keine akademische Übung mehr; es ist der Grundstein für robuste Künstliche Intelligenz.
Weitere Beiträge …
Seite 1 von 18