
In meinen über zwei Jahrzehnten JDE-EntwicklungEntwicklung von Software für JD Edwards, ein ERP-System von Oracle. habe ich Hunderte von benutzerdefinierten Tabellen korrumpiert gesehen, weil Entwickler das Data DictionaryEin zentrales Repository in JD Edwards, das Definitionen und Regeln für alle Datenfelder speichert, wie Datentypen, Längen und Validierungen. als ein reines UI-Feature behandelten. Wenn Sie Logik in eine BSFNEine Business Function ist ein wiederverwendbares Stück Code in JD Edwards, das Geschäftslogik kapselt. Es kann in C oder NER (Named Event Rule) geschrieben sein. verschieben, verschwindet das Sicherheitsnetz der Anwendung (APPL)Eine interaktive Anwendung in JD Edwards, die Benutzern die Eingabe und Anzeige von Daten ermöglicht.. Wenn Ihre Logik die JD Edwards BSFN-Validierung benutzerdefinierter Tabellen mit Data Dictionary-Elementen nicht explizit aufruft, sind Sie nur einen UBEUniversal Batch Engine. Ein JD Edwards-Prozess, der Aufgaben im Hintergrund ausführt, oft für Berichte oder Massendatenverarbeitung.- oder AIS-AufrufEin Aufruf an die Application Interface Services, eine REST-API-Schicht in JD Edwards, die externe Systeme mit JDE-Anwendungen und -Daten verbindet. von einer Datenbank voller ungültiger UDCsBenutzerdefinierte Codes. Vordefinierte Listen von Werten in JD Edwards, die zur Standardisierung von Daten und zur Validierung verwendet werden. und verwaister Datensätze entfernt. Sich auf „Check“-Eigenschaften im Formular-Designer zu verlassen, ist ein Anfängerfehler, der alle Ihre Nicht-UI-Dateneingabepunkte für fehlerhafte Daten anfällig macht.
Das Erstellen einer Validierungsgrenze auf Datenebene erfordert das Umgehen der Bequemlichkeit der Formular-EngineDie Softwarekomponente in JD Edwards, die interaktive Formulare rendert und deren Logik verarbeitet. und die direkte Interaktion mit der JDE-LaufzeitumgebungDie Umgebung, in der JD Edwards-Anwendungen und -Prozesse ausgeführt werden, einschließlich der Server und der zugrunde liegenden Infrastruktur.. In einer typischen EnterpriseOne 9.2Eine spezifische Version des JD Edwards EnterpriseOne ERP-Systems von Oracle.-Umgebung kann eine einzige OrchestrierungEin Werkzeug in JD Edwards (Teil von Orchestrator), das komplexe Geschäftsprozesse automatisiert, indem es mehrere Schritte und Interaktionen mit JDE-Komponenten koordiniert. jede UI-Ebene-Einschränkung umgehen, was zu Datenintegritätsproblemen führt, die oft eine ganze Arbeitswoche manueller SQL-Bereinigung erfordern, um sie zu beheben. Die Verlagerung dieser Regeln in C-APIsApplication Programming Interfaces, die in der Programmiersprache C geschrieben sind und es Entwicklern ermöglichen, direkt mit den Kernfunktionen von JD Edwards zu interagieren. stellt sicher, dass die Tabelle, unabhängig davon, ob Daten von einer mobilen App oder einem Legacy-Flatfile-Import stammen, durch dieselben harten Einschränkungen geschützt bleibt, die im DDData Dictionary. Ein zentrales Repository in JD Edwards, das Definitionen und Regeln für alle Datenfelder speichert. definiert sind.
Definieren der Validierungsgrenze für benutzerdefinierte Tabellen
In älteren 9.1-UmgebungenÄltere Versionen der JD Edwards EnterpriseOne-Software, die vor 9.2 veröffentlicht wurden. finde ich oft kritische Validierungslogik, die in den Control Exited/Changed-Inline-EreignissenEreignisse im JD Edwards Formular-Designer, die ausgelöst werden, wenn ein Benutzer ein Steuerelement verlässt oder dessen Wert ändert. einer P55-AnwendungEine benutzerdefinierte Anwendung in JD Edwards. Die "55" im Namen kennzeichnet oft kundenspezifische Entwicklungen. gefangen ist. Diese architektonische SchuldTechnische Schulden, die durch die Wahl einer suboptimalen Architektur oder Implementierung entstehen, die zukünftige Änderungen erschwert. wird zu einer Belastung, wenn Sie Daten über einen R55-BatchprozessEin benutzerdefinierter Batch-Prozess oder Bericht in JD Edwards. Die "55" kennzeichnet oft kundenspezifische Entwicklungen. oder einen externen AIS-AufrufEin Aufruf an die Application Interface Services, eine REST-API-Schicht in JD Edwards, die externe Systeme mit JDE-Anwendungen und -Daten verbindet. laden müssen. Sich auf die Anwendungsebene zu verlassen, um die Integrität durchzusetzen, geht davon aus, dass jeder Eingabepunkt ein Mensch vor einem Bildschirm ist. Ein direkter Tabellen-I/O-AufrufEin direkter Aufruf zum Lesen, Schreiben, Aktualisieren oder Löschen von Daten in einer Datenbanktabelle. in einem UBEUniversal Batch Engine. Ein JD Edwards-Prozess, der Aufgaben im Hintergrund ausführt, oft für Berichte oder Massendatenverarbeitung. umgeht jede Zeile des ER-CodesEvent Rule-Codes. Die Skriptsprache in JD Edwards, die zur Implementierung von Geschäftslogik in Anwendungen und Berichten verwendet wird. in Ihrer APPLEine interaktive Anwendung in JD Edwards, die Benutzern die Eingabe und Anzeige von Daten ermöglicht. und macht Ihre benutzerdefinierte Tabelle anfällig für verwaiste Datensätze oder ungültige Statuscodes.
Die Verlagerung der Validierungsgrenze auf eine Master Business Function (MBF)Eine zentrale Business Function, die als primärer Einstiegspunkt für die Interaktion mit einer bestimmten Datenentität dient und alle Validierungen kapselt. stellt sicher, dass die DatenschichtDie Schicht einer Softwarearchitektur, die für den Zugriff und die Verwaltung von Daten zuständig ist, oft direkt mit der Datenbank interagierend. niemals „dünn“ ist. Wenn Sie die Validierung innerhalb einer C-basierten BSFNEine Business Function, die in der Programmiersprache C geschrieben ist, was eine hohe Leistung und direkten Zugriff auf Systemressourcen ermöglicht. oder einer strukturierten NEREine Named Event Rule, die als Business Function strukturiert ist, um wiederverwendbare Geschäftslogik zu kapseln, ohne C-Code zu verwenden. kapseln, schaffen Sie einen einheitlichen GatekeeperEine Komponente oder ein Prozess, der den Zugriff auf eine Ressource oder die Ausführung einer Aktion kontrolliert und validiert., der sowohl Data Dictionary-Regeln als auch komplexe relationale Logik vor einem CommitDer Vorgang, bei dem Änderungen an einer Datenbank dauerhaft gespeichert werden, nachdem alle Transaktionen erfolgreich abgeschlossen wurden. berücksichtigt.
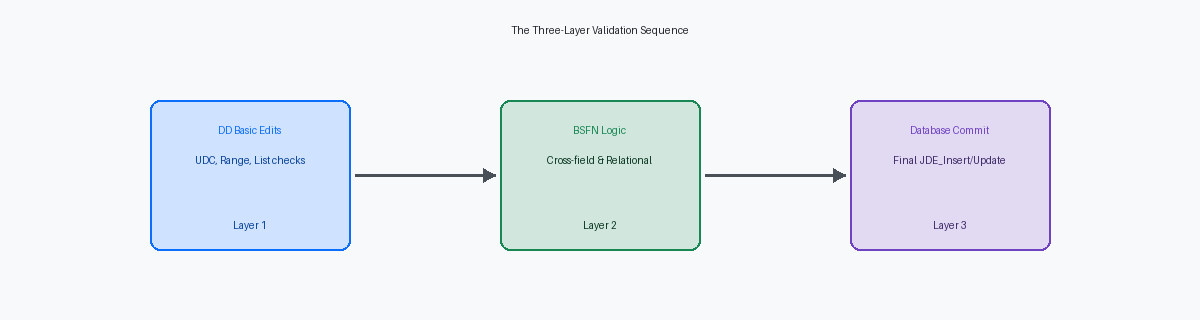
Anwendung des Data Dictionary für harte Einschränkungen
Ein benutzerdefiniertes TabellenschemaDie Struktur einer Datenbanktabelle, einschließlich der Namen, Datentypen und Eigenschaften ihrer Spalten. ist nur so zuverlässig wie die Data Dictionary (DD)Ein zentrales Repository in JD Edwards, das Definitionen und Regeln für alle Datenfelder speichert, wie Datentypen, Längen und Validierungen.-Elemente, die seine Spalten untermauern. Sich auf die BSFN-LogikDie Geschäftslogik, die in einer Business Function (BSFN) in JD Edwards implementiert ist. zu verlassen, um eine fehlerhafte Zeichenfolge oder eine Ganzzahl außerhalb des Bereichs abzufangen, ist ein Architekturfehler, wenn das DD native Bereichs-, Listen- und UDC-ValidierungDer Prozess der Überprüfung, ob ein eingegebener Wert in einer der vordefinierten Listen von Benutzerdefinierten Codes (UDCs) in JD Edwards existiert. bietet. Zum Beispiel erfordert die Definition eines „Status“-Feldes mit einer fest codierten Prüfung im C-Code einen vollständigen Paket-BuildDer Prozess des Kompilierens und Bereitstellens von JD Edwards-Objekten (wie Anwendungen, Berichte, Business Functions) in einer ausführbaren Form. für eine einzelne Wertänderung. Ein UDC-gestütztes DD-Element ermöglicht es einem Business Analysten, die Tabelle F0005Eine Standardtabelle in JD Edwards, die alle Benutzerdefinierten Codes (UDCs) speichert. über P0004AEine Standardanwendung in JD Edwards, die zur Verwaltung und Konfiguration von Benutzerdefinierten Codes (UDCs) verwendet wird. in Sekundenschnelle zu aktualisieren, ohne eine einzige Codezeile zu berühren.
Beim Schreiben einer C BSFNEine Business Function, die in der Programmiersprache C geschrieben ist. zur Validierung eines benutzerdefinierten Tabellendatensatzes sollte der erste Schritt der Aufruf des Standard-Validierungsstacks über die C-API jdeCallObjectEine C-API-Funktion in JD Edwards, die verwendet wird, um andere Business Functions aufzurufen. sein. Insbesondere stellt der Aufruf von B0000016 (VerifyUDC)Eine Standard-Business Function in JD Edwards, die speziell für die Validierung von Benutzerdefinierten Codes (UDCs) entwickelt wurde. sicher, dass Ihre benutzerdefinierte Logik dieselben F0005-IntegritätsprüfungenValidierungsprüfungen, die sicherstellen, dass Daten den Regeln entsprechen, die in der F0005-Tabelle für UDCs definiert sind. respektiert, die von Standardanwendungen wie P4210Eine Standardanwendung in JD Edwards für die Erfassung von Verkaufsaufträgen. oder P4310Eine Standardanwendung in JD Edwards für die Erfassung von Bestellungen. verwendet werden. Dieser Ansatz pflegt eine einzige Quelle der Wahrheit für gültige Codes und verhindert die „GeisterdatenDaten, die in einem System vorhanden sind, aber aufgrund von Inkonsistenzen oder fehlender Validierung nicht korrekt verwendet oder angezeigt werden können.“-Probleme, die auftreten, wenn benutzerdefinierte BSFNs und Standardanwendungen sich nicht einig sind, was einen gültigen Wert darstellt.
Benutzerdefinierte DD-ElementeData Dictionary-Elemente. Einzelne Definitionen von Datenfeldern im Data Dictionary von JD Edwards. sollten mit spezifischen Bearbeitungsregeln in P92001Eine Standardanwendung in JD Edwards, die zur Konfiguration und Verwaltung von Data Dictionary-Elementen verwendet wird. konfiguriert werden, um die grundlegende Datenintegrität zu automatisieren, noch bevor die BSFN ihre Ausführung beginnt. Wenn ein Feld einen bestimmten numerischen Bereich oder einen Wert aus einer vordefinierten Liste erfordert, verlagert das Festlegen dieser Einschränkungen auf DD-Ebene die Validierungslast von der Anwendungsebene auf die JDE-EngineDer Kernmotor von JD Edwards, der die Ausführung von Anwendungen, Business Functions und Batch-Prozessen steuert.. In einer Hochleistungsumgebung, die Zehntausende von Datensätzen pro Stunde über ein benutzerdefiniertes UBEUniversal Batch Engine. Ein JD Edwards-Prozess, der Aufgaben im Hintergrund ausführt, oft für Berichte oder Massendatenverarbeitung. verarbeitet, reduziert diese Entlastung den Overhead des AufrufstacksDer zusätzliche Rechenaufwand, der durch das Verwalten von Funktionsaufrufen und deren Rückgabeadressen im Speicher entsteht., indem ungültige Datensätze am frühestmöglichen Eintrittspunkt abgefangen werden.
Das Festcodieren von Validierungswerten innerhalb einer BSFN ist eine Wartungsfalle, die ich bei zahlreichen 9.2-Upgrade-Projekten zum Scheitern gebracht habe. Jedes Mal, wenn sich eine Geschäftsregel ändert, steht eine Code-Revision, eine OWM-PromotionDer Prozess des Verschiebens von JD Edwards-Objekten (z.B. Business Functions) von einer Entwicklungsumgebung in eine Test- oder Produktionsumgebung mithilfe des Object Workbench. und eine PaketbereitstellungDer Vorgang des Verteilens und Installierens eines kompilierten JD Edwards-Pakets auf Client-Workstations oder Servern. über den PfadcodeEine logische Umgebung in JD Edwards (z.B. DV für Entwicklung, PY für Test, PD für Produktion), die eine bestimmte Version von Objekten und Daten repräsentiert. an. Die Nutzung DD-gesteuerter Einschränkungen verlagert diese Logik in die MetadatenschichtEine Schicht in der Softwarearchitektur, die Informationen über Daten (Metadaten) speichert und verwaltet, anstatt die Daten selbst., wo sie hingehört. Die Verwaltung dieser Einschränkungen über P92001Eine Standardanwendung in JD Edwards, die zur Konfiguration und Verwaltung von Data Dictionary-Elementen verwendet wird. stellt sicher, dass Ihre Validierungslogik für das gesamte IT-Team sichtbar bleibt, anstatt in einer Quelldatei vergraben zu sein, die nur ein Entwickler entschlüsseln kann.

Implementierung der BSFN-Logik für die feldübergreifende Validierung
Data Dictionary-BearbeitungenÄnderungen an den Definitionen und Regeln von Datenfeldern im Data Dictionary von JD Edwards. wie Bereichsprüfungen oder Wertelisten versagen in dem Moment, in dem Ihre Logik einen relationalen Vergleich zwischen zwei verschiedenen Feldern erfordert. Zum Beispiel erfordert die Sicherstellung, dass ein „Ship Date“ (SDTJEin internes Feld in JD Edwards, das das Versanddatum (Ship Date) darstellt.) in einer benutzerdefinierten Tabelle nicht vor einem „Order Date“ (TRDJEin internes Feld in JD Edwards, das das Bestelldatum (Order Date) darstellt.) liegt, eine C BSFNEine Business Function, die in der Programmiersprache C geschrieben ist., da das DD den Wert eines anderen Feldes nicht in Echtzeit referenzieren kann. In einer Hochleistungsumgebung, die täglich Tausende von benutzerdefinierten Datensätzen verarbeitet, stellt die Verlagerung dieser Logik auf eine BSFN sicher, dass komplexe Geschäftsregeln sowohl in interaktiven Anwendungen als auch bei Batch-Uploads konsistent durchgesetzt werden.
Im C-QuellcodeDer in der Programmiersprache C geschriebene Code einer Business Function. ist der lpBhvrCom->hToolkitEin Zeiger in JD Edwards C-Code, der Zugriff auf das Toolkit-Handle der Behavior Common-Struktur bietet, um mit der Laufzeitumgebung zu interagieren.-Zeiger Ihre primäre Schnittstelle für die Interaktion mit dem internen Zustand der JDE-EngineDer Kernmotor von JD Edwards, der die Ausführung von Anwendungen, Business Functions und Batch-Prozessen steuert.. Sie müssen dieses Handle an die jdeErrorSet-APIEine C-API-Funktion in JD Edwards, die verwendet wird, um Fehler zu protokollieren und sie der Benutzeroberfläche oder dem Fehlerstack zuzuordnen. übergeben, um sicherzustellen, dass Fehler korrekt dem spezifischen Datenstrukturmitglied zugeordnet und der Benutzeroberfläche angezeigt werden. Ohne ordnungsgemäße Initialisierung und Nutzung des Toolkit-Handles könnten Ihre Validierungsfehler im jdedebug.logEine Protokolldatei in JD Edwards, die detaillierte Debugging-Informationen über die Ausführung von Anwendungen und Business Functions enthält. protokolliert werden, aber die Transaktion nicht stoppen oder das fehlerhafte Feld in einem Power FormEin moderner Typ von interaktiven Formularen in JD Edwards, der erweiterte Layout- und Interaktionsmöglichkeiten bietet. oder Standard-GridEine Standardtabelle oder Rasteranzeige in JD Edwards-Anwendungen, die Daten in Zeilen und Spalten darstellt. rot hervorheben.
Ein professioneller Validierungsstack wird in einer bestimmten Hierarchie ausgeführt: Zuerst lässt man das DD Nullen und grundlegende Formatierungen behandeln; zweitens verwendet man die BSFN, um relationale Prüfungen gegen MastertabellenZentrale Datenbanktabellen in JD Edwards, die grundlegende Stammdaten wie Unternehmen, Adressen oder Artikel speichern. wie die Company Constants (F0010)Eine Standardtabelle in JD Edwards, die unternehmensspezifische Konstanten und Einstellungen speichert. oder das Address Book (F0101)Eine Standardtabelle in JD Edwards, die alle Adressbuchdatensätze (Personen, Unternehmen) speichert. durchzuführen. Wenn Sie ein benutzerdefiniertes Feld gegen eine bestimmte Business Unit (MCU)Eine Organisationseinheit in JD Edwards, die für die Kostenrechnung und Berichterstattung verwendet wird. validieren, sollte die BSFN zuerst überprüfen, ob die MCU in F0006Eine Standardtabelle in JD Edwards, die alle definierten Geschäftseinheiten (Business Units) speichert. existiert, bevor sie mit der feldübergreifenden Logik fortfährt. Dies verhindert, dass der Code teure Select-AnweisungenSQL-Befehle, die zum Abrufen von Daten aus einer oder mehreren Datenbanktabellen verwendet werden. auf fehlerhaften Daten ausführt, die von den grundlegenden Bearbeitungsregeln des DD hätten abgefangen werden sollen.
Der letzte Schritt in der BSFN ist die explizite Rückgabe des JDEBFRTN-WertesDer Rückgabewert einer JD Edwards Business Function, der den Erfolg oder Misserfolg der Ausführung anzeigt., typischerweise ER_SUCCESSEin Rückgabewert in JD Edwards Business Functions, der anzeigt, dass die Funktion erfolgreich ausgeführt wurde. oder ER_ERROREin Rückgabewert in JD Edwards Business Functions, der anzeigt, dass bei der Ausführung der Funktion ein Fehler aufgetreten ist.. Wenn Ihre feldübergreifende Logik einen ungültigen Datumsbereich oder einen fehlenden Datensatz in F0101 erkennt, ist die Rückgabe von ER_ERROR der einzige Mechanismus, der der JDE-Laufzeit-EngineDer Kernprozess, der JD Edwards-Anwendungen und -Business Functions ausführt. mitteilt, den Commit-ProzessDer Vorgang, bei dem alle Änderungen einer Transaktion dauerhaft in der Datenbank gespeichert werden. anzuhalten. In einem Standardszenario für die Dateneingabe bedeutet das Versäumnis, den korrekten Code zurückzugeben, dass das System möglicherweise mit einem Tabellen-I/O Insert oder UpdateDatenbankoperationen zum Einfügen neuer Datensätze oder Aktualisieren bestehender Datensätze in einer Tabelle. fortfährt, selbst wenn jdeErrorSetEine C-API-Funktion in JD Edwards, die verwendet wird, um Fehler zu protokollieren und sie der Benutzeroberfläche oder dem Fehlerstack zuzuordnen. aufgerufen wurde, was zu Datenintegritätsproblemen führt, die in Produktions-SQL-Tabellen notorisch schwer zu beheben sind.
Fehlerbehandlung und Nachrichten-Mapping
Ein häufiger Fehler in benutzerdefinierten C BSFNsBusiness Functions, die in der Programmiersprache C geschrieben sind. ist das Festcodieren von Fehlerzeichenfolgen oder das Versäumnis, Rückgabecodes dem JDE-Fehlerstack zuzuordnen. Wenn eine Validierung gegen eine benutzerdefinierte Tabelle fehlschlägt, ist die Rückgabe einer einfachen '1' an die aufrufende APPLEine interaktive Anwendung in JD Edwards, die Benutzern die Eingabe und Anzeige von Daten ermöglicht. oder UBEUniversal Batch Engine. Ein JD Edwards-Prozess, der Aufgaben im Hintergrund ausführt, oft für Berichte oder Massendatenverarbeitung. für die Fehlerbehebung unzureichend. Sie müssen jeden Fehler einer spezifischen Data Dictionary-Fehler-IDEine eindeutige Kennung im Data Dictionary von JD Edwards, die einer spezifischen Fehlermeldung zugeordnet ist. zuordnen, z. B. 0001 für eine „Ungültige Adressbuchnummer“ oder 0002 für „Datensatz ungültig“. Durch die Verwendung der jdeErrorSet-APIEine C-API-Funktion in JD Edwards, die verwendet wird, um Fehler zu protokollieren und sie der Benutzeroberfläche oder dem Fehlerstack zuzuordnen. injizieren Sie Laufzeitvariablen in den GlossartextDer beschreibende Text, der im Data Dictionary für jedes Datenfeld hinterlegt ist und oft für Fehlermeldungen verwendet wird.. Das Übergeben der spezifischen mnAddressNumberEin internes Feld in JD Edwards, das die Adressbuchnummer darstellt. in die Fehlerstruktur ermöglicht es dem Benutzer, genau zu sehen, welcher Datensatz den Fehler ausgelöst hat, anstatt aus einer generischen Nachricht zu raten. Dies stellt sicher, dass der lpBhvrCom-ZeigerEin Zeiger auf die Behavior Common-Struktur, die Kontextinformationen für eine Business Function enthält. den korrekten Zustand an das interaktive Formular oder die Batch-Engine zurückgibt.
In Hochleistungs-, Multi-Thread-UBE-UmgebungenJD Edwards Universal Batch Engine-Umgebungen, die mehrere Threads gleichzeitig nutzen, um Aufgaben parallel zu verarbeiten. führt unsachgemäßes Fehlerstack-Management zu Phantomfehlern oder Speicherlecks innerhalb der JDE-EngineDer Kernmotor von JD Edwards, der die Ausführung von Anwendungen, Business Functions und Batch-Prozessen steuert.. Wenn Ihre BSFN innerhalb einer Schleife aufgerufen wird, die Tausende von Datensätzen verarbeitet, kann das Versäumnis, den Fehlerstack zu löschen oder die idControlEine eindeutige Kennung für ein Steuerelement (z.B. ein Feld oder eine Schaltfläche) in einer JD Edwards-Anwendung. falsch zuzuweisen, dazu führen, dass eine Nachricht von Datensatz 5 bei Datensatz 500 erscheint. Ich habe gesehen, wie Produktions-KernelDer Kernprozess des JD Edwards-Servers, der in einer Live-Produktionsumgebung läuft und für die Verarbeitung von Anfragen zuständig ist. abgestürzt sind, weil ein Entwickler Speicher für eine benutzerdefinierte Fehlerzeichenfolge zugewiesen, diesen aber nach dem jdeErrorSet-AufrufEin Aufruf der C-API-Funktion jdeErrorSet in JD Edwards, um Fehler zu protokollieren und zuzuordnen. nicht freigegeben hat. Halten Sie sich an Standard-DD-Elemente und lassen Sie die Middleware den Speicherlebenszyklus des Fehlerstacks verwalten. Dies ist besonders kritisch bei der Ausführung auf 64-Bit Tools ReleasesSpezifische Versionen der JD Edwards Tools Release-Software, die auf 64-Bit-Architekturen laufen und größere Speicherkapazitäten nutzen können., wo der Speicheradressraum größer, aber immer noch endlich ist.
Sich auf den Glossartext des Data DictionaryDer beschreibende Text, der im Data Dictionary für jedes Datenfeld hinterlegt ist und oft für Fehlermeldungen verwendet wird. zu verlassen, bietet eine lokalisierte Erfahrung, ohne Codeänderungen für internationale Bereitstellungen zu erfordern. Wenn Sie einen Fehler im DD definieren, ruft die JDE-Laufzeit automatisch die übersetzte Version basierend auf der Profilsprache des Benutzers ab. Für komplexe Validierungen, bei denen eine kurze Nachricht nicht ausreicht, können Sie die Fehler-ID mit F00165 Media ObjectsEine Standardtabelle in JD Edwards, die binäre Objekte (wie Dokumente, Bilder, Videos) speichert, die mit JDE-Datensätzen verknüpft sind. verknüpfen, um detaillierte Lösungsschritte bereitzustellen. Dies verwandelt eine kryptische Systemmeldung in eine funktionale SOPStandard Operating Procedure. Eine detaillierte, schrittweise Anleitung zur Durchführung einer Routineaufgabe. für den Endbenutzer. Es ist der Unterschied zwischen einem Helpdesk-Ticket mit hoher Priorität und einem selbstkorrigierten Dateneingabefehler, der die Abteilung nie verlässt.
Die Leistungskosten redundanter Validierung
Ein häufiger Fehler bei der Batch-Verarbeitung großer Mengen ist es, das Data Dictionary als eine kostenlose Ressource zu behandeln. Wenn ein UBEUniversal Batch Engine. Ein JD Edwards-Prozess, der Aufgaben im Hintergrund ausführt, oft für Berichte oder Massendatenverarbeitung. sechsstellige Datensatzmengen verarbeitet und die C BSFNEine Business Function, die in der Programmiersprache C geschrieben ist. JDECM_GetDictColInfoEine C-API-Funktion in JD Edwards, die Informationen über eine Spalte aus dem Data Dictionary abruft. für jede Zeile aufruft, um Dezimal-Trigger zu prüfen, führen Sie einen massiven I/O-EngpassEine Situation, in der die Leistung eines Systems durch langsame Eingabe-/Ausgabeoperationen (z.B. Datenbankzugriffe) begrenzt wird. ein. In einer Vertriebsumgebung haben wir die Laufzeit eines benutzerdefinierten Verkaufs-Uploads von mehreren Stunden auf unter dreißig Minuten reduziert, indem wir diese Metadaten-Abrufe aus der primären Zeilenverarbeitungsschleife herausgenommen haben.
Effektive Entwickler nutzen den lpBhvrComEin Zeiger auf die Behavior Common-Struktur, die Kontextinformationen für eine Business Function enthält.-Zeiger oder eine benutzerdefinierte Datenstruktur, um DD-MetadatenMetadaten (Daten über Daten) aus dem Data Dictionary, die die Struktur und Eigenschaften von JD Edwards-Datenfeldern beschreiben. einmalig zu speichern. Das Abrufen von Spalteninformationen über JDECM_GetDictColInfoEine C-API-Funktion in JD Edwards, die Informationen über eine Spalte aus dem Data Dictionary abruft. sollte während der Initialisierungsphase oder der ersten Iteration erfolgen und dann im Speicherbereich der BSFN gespeichert werden. Dies stellt sicher, dass die Laufzeit nicht wiederholt auf die Tabellen F9210Eine Standardtabelle in JD Edwards, die die Definitionen der Data Dictionary-Elemente speichert. und F9211Eine Standardtabelle in JD Edwards, die die Spalteninformationen für Data Dictionary-Elemente speichert. zugreift, um Informationen abzurufen, die während der gesamten Ausführung statisch bleiben.
Das Aufrufen von VerifyUDCEine Standard-Business Function in JD Edwards, die speziell für die Validierung von Benutzerdefinierten Codes (UDCs) entwickelt wurde. (X0005) innerhalb einer Schleife für einen Wert, der sich nicht ändert – wie z. B. einen konstanten Firmen-Code – ist eine Verschwendung von CPU-ZyklenDie grundlegenden Operationseinheiten, die ein Prozessor pro Sekunde ausführen kann.. Ein effizienteres Muster besteht darin, den konstanten Wert einmal zu Beginn des Prozesses zu validieren und ein boolesches FlagEine Variable, die nur zwei Zustände annehmen kann (wahr/falsch, ja/nein), oft zur Steuerung von Logikflüssen verwendet. in der internen Datenstruktur zu setzen. Wenn das Flag wahr ist, wird die Logik fortgesetzt; anderenfalls wird der Prozess beendet, bevor der erste Datensatz aus der benutzerdefinierten Tabelle gelesen wird.
Wenn Ihre BSFN relationale Validierungen gegen Standard-JDE-Master wie F0101Eine Standardtabelle in JD Edwards, die alle Adressbuchdatensätze (Personen, Unternehmen) speichert. oder F4101Eine Standardtabelle in JD Edwards, die die Stammdaten für Artikel (Item Master) speichert. durchführt, sind fehlende IndizesDatenstrukturen, die die Geschwindigkeit von Datenabfragen in einer Datenbanktabelle verbessern, ähnlich einem Buchindex. auf benutzerdefinierten Tabellen fatal. Eine Tabelle mit 500.000 Datensätzen, der ein Index auf der kurzen Artikelnummer (ITMEin internes Feld in JD Edwards, das die kurze Artikelnummer (Item Number) darstellt.) fehlt, erzwingt einen vollständigen TabellenscanEine Datenbankoperation, bei der jede Zeile einer Tabelle gelesen wird, um die gewünschten Daten zu finden, was bei großen Tabellen ineffizient ist. für jede Validierungsprüfung. Stellen Sie sicher, dass Ihre benutzerdefinierte Tabelle einen PrimärindexEin spezieller Index in einer Datenbanktabelle, der eine oder mehrere Spalten enthält, die jeden Datensatz eindeutig identifizieren. hat, der mit den Fetch-AnweisungenDatenbankbefehle, die verwendet werden, um Datensätze aus einer Abfrageergebnismenge abzurufen. der BSFN übereinstimmt, um Antwortzeiten im Sub-Sekundenbereich aufrechtzuerhalten.
Testen des Validierungsstacks in OWM
Das Testen einer BSFNEine Business Function ist ein wiederverwendbares Stück Code in JD Edwards, das Geschäftslogik kapselt. Es kann in C oder NER (Named Event Rule) geschrieben sein. isoliert ist Zeitverschwendung ohne ein kontrolliertes TestgerüstEine Umgebung oder ein Framework, das zum Testen von Softwarekomponenten entwickelt wurde, oft mit vordefinierten Eingaben und erwarteten Ausgaben.. Ich sehe, wie Entwickler Stunden damit verbringen, eine Funktion manuell aus einer Standardanwendung aufzurufen, was ineffizient und anfällig für menschliche Fehler ist. Erstellen Sie ein Treiber-UBEUniversal Batch Engine. Ein JD Edwards-Prozess, der Aufgaben im Hintergrund ausführt, oft für Berichte oder Massendatenverarbeitung. oder eine einfache Test-APPLEine einfache JD Edwards-Anwendung, die speziell für Testzwecke erstellt wurde, um Business Functions oder andere Logik zu isolieren und zu überprüfen. mit spezifischen Eingabefeldern, um 10–15 ungültige Datenszenarien zu durchlaufen. Dies umfasst das Testen von Grenzwerten, Nullzeigern und nicht übereinstimmenden Datentypen. Ein dediziertes Testobjekt ermöglicht es Ihnen, die Ausführung nach jedem C-Code-RebuildDer Prozess des Neukompilierens von C-Quellcode, nachdem Änderungen vorgenommen wurden, um eine neue ausführbare Version zu erstellen. in OWMObject Workbench. Ein Entwicklungstool in JD Edwards, das Entwicklern die Verwaltung, Änderung und Bereitstellung von JDE-Objekten ermöglicht. in weniger als einer Minute zu wiederholen und so sicherzustellen, dass die Logik auch bei Randfällen wie negativen Mengen oder ungültigen Julianischen DatenEin Datumsformat, das die Anzahl der Tage seit dem 1. Januar eines bestimmten Jahres angibt, oft in JD Edwards verwendet. standhält.
Effektives Validierungstesten erfordert mehr als nur die Suche nach einem roten Fehler auf dem Bildschirm. Starten Sie den JDE DebuggerEin Tool in JD Edwards, das Entwicklern ermöglicht, den Code Schritt für Schritt auszuführen, Variablen zu inspizieren und Fehler zu finden. und setzen Sie HaltepunktePunkte im Code, an denen die Ausführung während des Debuggings angehalten wird, um den Zustand des Programms zu überprüfen. bei jeder Return-AnweisungEine Anweisung in einer Funktion, die den Wert angibt, der an den aufrufenden Code zurückgegeben werden soll. im Quellcode. Sie müssen die Rückgabewerte der jdeErrorSetEine C-API-Funktion in JD Edwards, die verwendet wird, um Fehler zu protokollieren und sie der Benutzeroberfläche oder dem Fehlerstack zuzuordnen.-Aufrufe überprüfen und sicherstellen, dass die lpBhvrCom-DatenstrukturEine Datenstruktur in JD Edwards C-Code, die Kontextinformationen und Status für eine Business Function enthält. korrekt gefüllt ist, bevor die Funktion beendet wird, um stille Fehler in der Produktion zu verhindern.
Wenn Sie mit hartnäckigen Datenintegritätsproblemen in benutzerdefinierten JDE-ModulenEinzelne, in sich geschlossene Softwarekomponenten innerhalb des JD Edwards ERP-Systems, die spezifische Geschäftsfunktionen abdecken. kämpfen oder neue Integrationen entwerfen, die von benutzerdefinierten Tabellen abhängen, sollten wir uns unterhalten. Ich kann Ihnen helfen, Ihre BSFN-basierte ValidierungsarchitekturEine Softwarearchitektur, bei der die Datenvalidierung hauptsächlich durch Business Functions (BSFNs) in JD Edwards implementiert wird. zu bewerten und eine widerstandsfähigere DatenschichtDie Schicht einer Softwarearchitektur, die für den Zugriff und die Verwaltung von Daten zuständig ist, oft direkt mit der Datenbank interagierend. zu implementieren.