Die schwierigste Frage in jeder ausgereiften JDE-Installation ist eine der einfachsten: "Wenn ich diese Tabelle ändere, welche Custom-Anwendung bricht dann?" Das Mapping von Business-View-Abhängigkeiten in JD Edwards EnterpriseOne Custom-Anwendungen ist die Disziplin, die diese Frage von einer mehrtägigen forensischen Analyse in eine Abfrage verwandelt, die in Sekunden zurückkommt. Die meisten Installationen haben zwischen 80 und 400 Custom Business Views, die über Standard- und Custom-Tabellen liegen und von einer unbekannten Anzahl von Anwendungen, UBEs und Forms aufgerufen werden — und niemand hat ein aktuelles Bild davon, was wovon abhängt.
Der Preis des Nichtwissens wird jedes Mal bezahlt, wenn sich etwas ändert. Eine Spalte, die zu F4211 hinzugefügt wird. Ein neuer Index auf F0911. Eine Custom-Tabelle, die im Rahmen einer Bereinigung umbenannt wird. Jede Änderung breitet sich über alle Business Views aus, die das betroffene Objekt referenzieren, und jede BV betrifft jede Anwendung, die darauf aufsetzt. Ohne Map wird der Impact entdeckt, wenn etwas in PY bricht, oder schlimmer, in PD.
Warum Business Views der richtige Anker für die Map sind
Eine Business View in JDE ist keine Datenbank-View. Sie ist ein Metadatenobjekt, das Spalten aus einer oder mehreren Tabellen auswählt, Joins zwischen ihnen definiert und das Ergebnis als einen einzelnen rechteckigen Datensatz bereitstellt, an den Forms, Anwendungen und UBEs gebunden werden. Die BV sitzt zwischen den Tabellen und dem Code, und genau deshalb ist sie der richtige Knoten als Anker jeder Dependency Map.
Nur auf Tabellen zu ankern erzeugt Rauschen — jede Anwendung liest Tabellen, direkt oder indirekt, und der resultierende Graph ist zu dicht, um nützlich zu sein. Auf Anwendungen zu ankern erzeugt Lücken — Anwendungen rufen BVs auf, die über mehrere Tabellen joinen, und eine Tabellenfrage, die durch eine reine Anwendungs-Map geleitet wird, verliert Genauigkeit. Die BV ist der natürliche Join-Punkt: Sie weiß, welche Tabellen sie berührt, und sie ist jedem darüberliegenden Caller bekannt.
Auf der Upstream-Seite deklariert jede BV ihre Quelltabellen in der Spec, gespeichert in der Repository-Tabelle F98711Business-View-Spalten-Metadatentabelle — die JDE-Repository-Tabelle, die aufzeichnet, welche Spalten welcher Tabellen jede Business View bereitstellt, einschließlich Join-Definitionen.. Auf der Downstream-Seite speichert jede Form, Anwendung und UBE, die eine BV verwendet, die Beziehung in F9860 mit einem Source Type, der den Consumer identifiziert. Zwei korrekt verknüpfte SQL-Abfragen erzeugen den vollständigen Graphen für die gesamte Installation.
Der andere Grund, auf BVs zu ankern, ist, dass sie sich weniger häufig ändern als der Code, der sie nutzt. Eine BV mit zwanzig Consumern wird vielleicht einmal pro Jahr geändert; die zwanzig Anwendungen darüber werden im selben Zeitraum vielleicht zwanzigmal berührt. Eine Map, die auf der stabilen Schicht basiert, bleibt zwischen Regenerationszyklen länger korrekt.
Die Repository-Tabellen, die die Wahrheit enthalten
Das JDE-Repository — die Metadaten über jedes Objekt in der Installation — liegt in einer kleinen Gruppe von Systemtabellen, die aus Entwicklersicht read-only sind und für Analysen konsequent zu wenig genutzt werden. Die vier relevanten Tabellen für Dependency Mapping sind F9860, F98711, F98712 und F98750.
F9860 ist der Object Librarian Master. Jede BSFN, Anwendung, UBE, Business View und Tabelle hat hier eine Zeile, mit OBNM (Object Name), FUNO (Function Use, zur Identifikation des Typs) und SRCTYPE (Source Type, zur Unterscheidung von BV, APPL, UBE und TBL). Eine einfache Abfrage auf F9860, gefiltert nach FUNO-Werten für Business Views, liefert die vollständige Liste der BVs in der Installation; gefiltert nach Anwendungen, die vollständige Liste der Forms darüber. Die Filterwerte sind in den Standardtabellendefinitionen dokumentiert und ändern sich zwischen Tools Releases nicht.
F98711 ist die spaltenbezogene Join-Tabelle für Business Views. Jede Spalte, die eine BV bereitstellt, ist eine Zeile, mit Quelltabelle und Quellfeld. Die Aggregation von F98711 nach BV-Name liefert den vollständigen Tabellen-Footprint jeder View — genau das, was die Upstream-Seite der Dependency Map benötigt.
F98712 speichert Form- und Report-Sections, die an eine BV gebunden sind. Eine Custom-Anwendung, die über ihre Forms drei verschiedene BVs aufruft, erzeugt drei Zeilen in F98712, geschlüsselt nach Anwendungsname und BV-Name. Das ist die Downstream-Seite: welche Caller welche Views verwenden.
F98750 ist der Spec-Datenspeicher in modernen Tools Releases — der binäre Spec-Inhalt wird hier, nach Objekt indexiert, gespeichert. Für Dependency Mapping ist F98750 normalerweise nicht die primäre Quelle, weil die lesbaren Metadaten bereits in den anderen drei Tabellen liegen; F98750 wird nur relevant, wenn man Spec-Level-Details verfolgt, die die Metadatentabellen verflachen.
Den Graphen bauen: vom SQL-Extract zur navigierbaren Struktur
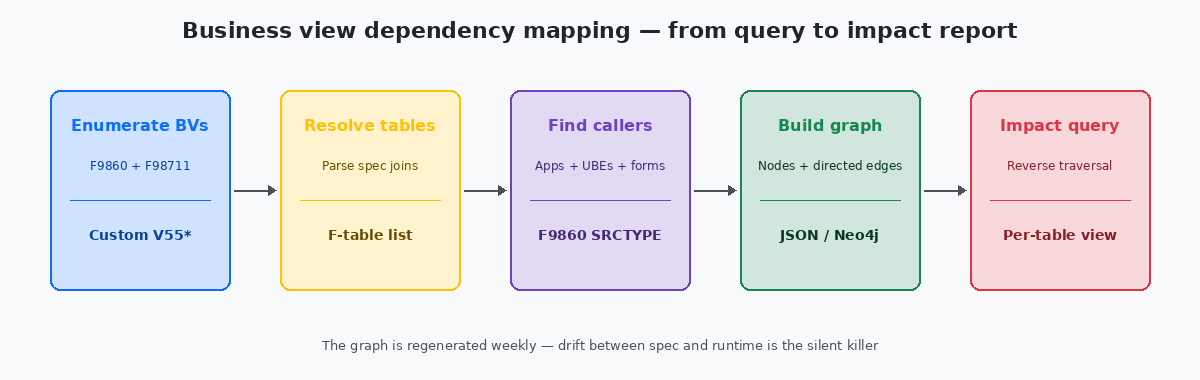
Der mechanische Teil des Mappings ist einfach und wird regelmäßig unnötig verkompliziert. Drei SQL-Abfragen gegen das Repository, nacheinander ausgeführt, liefern alles, was für einen vollständigen Dependency Graph einer Installation jeder Größe benötigt wird.
Die erste Abfrage listet jede Custom Business View auf — gefiltert nach Namenspräfix, typischerweise V55 bis V59 in Installationen, die Oracles reservierte Namespace-Konvention befolgen. Das Ergebnis ist eine flache Liste mit BV-Name, BV-Beschreibung und Zeitstempel der letzten Änderung. In einer typischen mittelgroßen Installation liefert das 80 bis 300 Zeilen in weniger als einer Sekunde.
Die zweite Abfrage löst jede BV auf ihre Quelltabellen auf. Ein Join von F9860 zu F98711 über OBNM und Gruppierung nach BV plus Quelltabellenname erzeugt eine Many-to-One-Liste — eine Zeile pro BV-zu-Tabelle-Beziehung. Eine BV, die F4211 und F4101 joint, erzeugt zwei Zeilen. Eine BV, die acht Tabellen berührt, erzeugt acht. Das Gesamtvolumen liegt in einer realen Installation typischerweise bei 200 bis 1.500 Zeilen.
Die dritte Abfrage findet jeden Caller für jede BV, indem sie F98712 liest und zurück auf F9860 joint, um den Caller mit Typ und Beschreibung anzureichern. Das ist das größte der drei Ergebnisse, weil eine beliebte BV zwanzig oder dreißig Caller haben kann; die Gesamtzeilenanzahl geht bei größeren Installationen in die Tausende, bleibt aber für jede moderne Datenbank trivial.
Die drei Ergebnissets werden zu den Kanten eines gerichteten Graphen: Tabellen zeigen nach oben auf BVs, BVs zeigen nach oben auf Caller. Als JSON gespeichert passt der Graph in wenige hundert Kilobyte und kann in jedes Visualisierungstool geladen werden, von Neo4jEine Graphdatenbank, die häufig für Abhängigkeits-, Netzwerk- und Beziehungsanalysen verwendet wird. Speichert Knoten und gerichtete Kanten nativ und beantwortet Erreichbarkeitsabfragen mit einzelnen Cypher-Statements. bis hin zu einer statischen HTML-Seite mit einer Force-Directed-Layout-Bibliothek. Die Visualisierung ist weniger wichtig als die zugrunde liegende Struktur — dasselbe JSON beantwortet programmatische Abfragen genauso gut wie visuelle.
Die Impact Queries, die den Aufwand rechtfertigen
Ein Dependency Graph, der nie abgefragt wird, ist Dokumentationstheater. Die Abfragen, die seinen Aufbau rechtfertigen, sind diejenigen, die echte Fragen beantworten, die Entwickler und CNC-Teams unter Druck stellen.
Die erste Impact Query ist eine Rückwärtsnavigation von einer Tabelle: Wenn F4211 im nächsten Sprint eine Spalte erhält, liste jede Custom BV auf, die daraus selektiert, und für jede BV jeden Caller. Die Antwort steuert den Regressionstestplan. Auf einem Graphen mit 200 BVs und 2.000 Callern läuft diese Abfrage in wenigen Dutzend Millisekunden und erzeugt eine Liste, die vollständig ist wie keine Tabelle es je war.
Die zweite Impact Query ist eine Vorwärtsnavigation von einer Anwendung: Wenn die Custom P55020A deprecated werden soll, liste jede BV auf, die sie verwendet, und prüfe für jede BV, ob noch ein anderer Caller davon abhängt. Views ohne weiteren Consumer werden selbst zu Deprecation-Kandidaten, und die Kette setzt sich bis zu Tabellen fort, die sonst niemand liest. Das ist die Abfrage, die Technical-Debt-Cleanup antreibt — die Kandidaten tauchen von selbst auf, sobald der Graph existiert.
Die dritte Abfrage ist Orphan Detection. Custom BVs in F9860, die null Zeilen in F98712 haben, sind Orphans — sie existieren im Repository, aber nichts ruft sie auf. Custom-Tabellen, aus denen keine BV selektiert, sind tiefere Orphans. In einer 20 Jahre alten Installation liegen Orphan-Anteile typischerweise zwischen 5% und 15% des Custom-Bestands, und jeder Orphan ist toter Code, der trotzdem durch jedes Upgrade mitgetragen werden muss. Sie sichtbar zu machen, ist in den meisten Installationen der erste praktische Nutzen des Graphen.

Die Map ehrlich halten: Regenerationsrhythmus und Drift
Der einzelne Fehlermodus jeder Dependency Map ist Veralten. Ein Graph, der einmal zu Projektbeginn erzeugt und nie aktualisiert wird, ist innerhalb weniger Wochen falsch — jeder Check-in in OMW, der eine BV hinzufügt oder ändert, erzeugt ein Delta, das der statische Graph nicht kennt. Die Disziplin, die die Map ehrlich hält, ist automatische Regeneration nach einem Zeitplan, den das Team tatsächlich befolgt.
Der Rhythmus, der in den meisten Installationen funktioniert, ist wöchentlich. Ein geplanter Job — ein Shell-Skript, eine kleine UBE oder ein Python-Skript mit Verbindung zur JDE-Datenbank — führt die drei Repository-Abfragen aus, baut das JSON, archiviert die vorherige Version und veröffentlicht den neuen Graphen an dem Ort, den das Team nutzt. Wöchentlich ist häufig genug, damit die Map nie mehr als ein paar Tage hinter der Realität liegt, und selten genug, damit der Job kein Rauschen erzeugt.
Der Diff zwischen aufeinanderfolgenden Snapshots ist nützlicher als jeder einzelne Snapshot. Neue BVs, die diese Woche erschienen sind, BVs, deren Quelltabellen sich geändert haben, BVs, die Caller gewonnen oder verloren haben — das sind die Elemente, die in der wöchentlichen Team Review sichtbar gemacht werden sollten. Eine BV, die plötzlich eine fünfte Tabelle in ihrem Join hat, ist eine Code-Review-Gelegenheit; eine BV, die ihren letzten verbleibenden Caller verloren hat, ist ein Löschkandidat. Der Diff besteht aus zwanzig Zeilen Skript und verwandelt den Graphen von einem Referenzdokument in einen Feedback-Loop darüber, was das Team tatsächlich baut.
Mehr zum Umfeld finden Sie in den verwandten Artikeln zum Retrofitting von Kopien des Standards, zum Scoping von Tools-Release-Upgrades und zu F-Table-Archivierungsstrategien, die die operative Ebene abdecken, auf der diese Map sitzt. Das technische Projektportfolio auf dieser Website dokumentiert zwei produktive Dependency-Tools, aus denen die hier beschriebenen Muster entstanden sind.