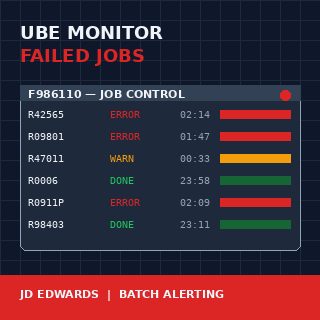
Ein JD Edwards EnterpriseOne-Batch-Job-Monitor für fehlgeschlagene UBE-Reports gehört zu den Entwicklungen, die sich bereits im ersten Monat bezahlt machen und sich danach bei jedem Quartalsabschluss weiter auszahlen. Die Server-Manager-Konsole zeigt an, dass ein Job mit Fehler beendet wurde, aber sie weckt niemanden deswegen auf, und sie sagt auch nicht, dass der Bestätigungslauf R42565 zum dritten Mal in Folge nachts um 02:14 fehlgeschlagen ist. Wenn der Lagerleiter um 7 Uhr morgens anruft und fragt, warum keine Pick Slips gedruckt wurden, sind die Daten bereits vier Stunden veraltet und der Morgen ist schon verloren.
Jede ausgereifte JDE-Installation, mit der ich gearbeitet habe, baut früher oder später einen solchen Monitor. Die funktionierenden Lösungen haben drei gemeinsame Eigenschaften: Sie pollen F986110Job Control Master — die JDE-Tabelle, die jede UBE-Übermittlung, ihren Statuscode, Start- und Endzeiten sowie den Server, auf dem sie lief, protokolliert. in engen Abständen, sie klassifizieren Fehler nach Auswirkung, und sie leiten Alerts an Kanäle weiter, die zur jeweiligen Kritikalität passen. Die Lösungen, die scheitern, sind meist reine E-Mail-Lösungen, schlagen bei allem Alarm und werden vom Betriebsteam innerhalb von sechs Wochen stummgeschaltet.
Was "fehlgeschlagen" in F986110 tatsächlich bedeutet
Der Job Control Master ist die zentrale Wahrheit für die Batch-Ausführung in JDE E1. Jede UBE-Übermittlung schreibt dort eine Zeile, identifiziert durch JOBNBR, mit einer JOBSTS-Spalte, die eine kleine Menge einstelliger Werte durchläuft: W (wartend), P (in Verarbeitung), D (erledigt), E (Fehler), CE (mit Fehler abgebrochen), S (vom Benutzer abgebrochen), H (gehalten). Ein naiver Monitor prüft auf JOBSTS = E und sendet einen Alert. Ein nützlicher Monitor kennt den Unterschied zwischen E und CE, behandelt H-Jobs, die älter als 30 Minuten sind, als eigenes Problem und erkennt, dass ein P-Job, der seit sechs Stunden läuft, obwohl er normalerweise in zwölf Minuten fertig ist, ebenfalls ein Fehler ist — nur ein leiserer.
Die Spalten SBMDATE und SBMTIME liefern den Übermittlungszeitpunkt; ENDDATE und ENDTIME liefern den Abschlusszeitpunkt. Die Differenz zwischen Übermittlung und aktueller Systemzeit ermöglicht es, hängende Jobs zu erkennen. Die Spalte PID zeigt, um welche UBE es sich handelte. Das ist wichtig, weil ein Fehlschlag von R0006 (EDI inbound) andere nachgelagerte Folgen hat als ein Fehlschlag von R09801 (Post General Ledger), und der Monitor wissen muss, was was ist.
Die Spalte SRVRNM zeigt, welcher Enterprise Server den Job ausgeführt hat. In einer Multi-Server-Installation ist das keine kosmetische Information — ein wiederkehrender Fehler auf einem Server, während die anderen sauber laufen, ist ein Infrastrukturproblem, kein UBE-Problem, und der Monitor sollte dieses Muster sichtbar machen.
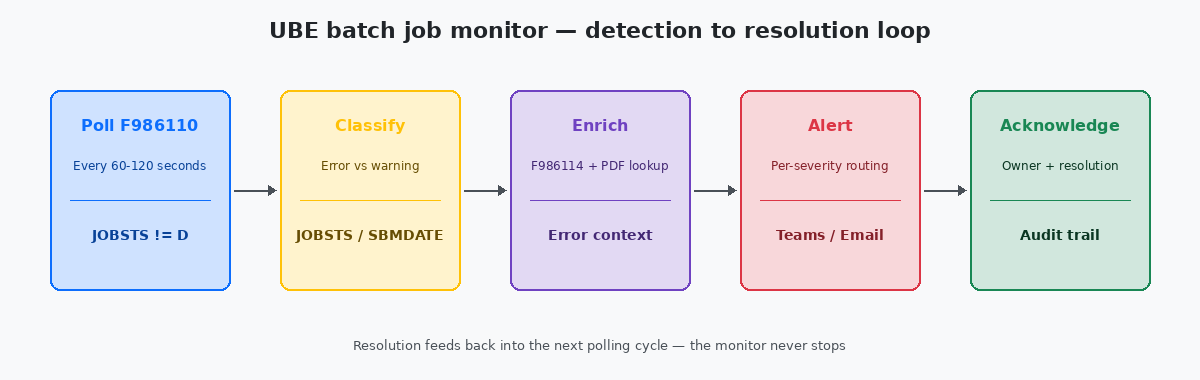
Die Polling-Schleife und warum Timing wichtiger ist als Logik
Der einfachste funktionierende Monitor ist eine SQL-Abfrage gegen F986110, die alle 60 bis 120 Sekunden durch einen geplanten Job ausgeführt wird. Läuft sie häufiger, belastet sie die Datenbank ohne menschlichen Nutzen — niemand wird ohnehin in weniger als einer Minute auf einen Alert reagieren. Läuft sie seltener, verliert man die Fähigkeit, kurzzyklische Fehler zu erkennen, bevor der nächste abhängige Job zu starten versucht.
Die Abfrage selbst ist einfach: Ziehe jede Zeile, bei der JOBSTS in ('E','CE') liegt und ENDDATE größer oder gleich dem High-Water-Mark des vorherigen Polling-Zyklus ist. Speichere den High-Water-Mark in einer kleinen Custom-Tabelle, damit ein Neustart des Monitors nicht jeden Fehler der letzten sechs Monate erneut abspielt. Das Muster ist dasselbe Idempotenzprinzip, das für jeden Datenladeprozess gilt — den Monitor zweimal auszuführen sollte einen Satz Alerts erzeugen, nicht zwei.
Der Punkt, den die meisten Builds übersehen, ist die Zeitzonenbehandlung. F986110 speichert Datumswerte im JDE-Julianformat und Zeiten als ganzzahlige HHMMSS-Werte, beide in der Zeitzone des Enterprise Servers. Wenn der Monitor auf einem anderen Host in einer anderen Zeitzone läuft, muss die Vergleichslogik explizit konvertieren. Ich habe einen Monitor debuggt, der jeden Fehler zwischen 23:00 und Mitternacht stillschweigend verpasst hat, weil der Vergleich auf der falschen Seite eine Datumsgrenze überschritten hat.
Kritikalität klassifizieren, ohne tausend Regeln zu schreiben
Der erste Impuls beim ersten Build ist, eine Regel pro UBE zu schreiben. Wenn man 40 Regeln hat, ist daraus bereits ein unwartbares Durcheinander geworden, und bei 200 weiß niemand mehr, welche Regeln noch gelten. Das skalierende Muster ist Kritikalität nach Kategorie, nicht nach Job.
Drei Kategorien decken ungefähr 95% realer Installationen ab. Kritisch bedeutet umsatzrelevant oder compliance-relevant: EDI inbound und outbound (R47*), Versandbestätigung für Kundenaufträge (R42565), Fakturierung (R42565, R03B11Z1I), Periodenabschluss (R09801, R0911P, R09866), Payroll-Erzeugung. Standard bedeutet geschäftsrelevant, aber nicht am selben Tag kritisch: Integritätsreports für Stammdaten, Reorganisationsjobs, Replikationsmonitore. Noisy bedeutet Fehler, die vorhersehbar wiederkehren und meist Datenprobleme sind: Integritätsreports, die bekannte verwaiste Datensätze melden, Custom-UBEs, die häufig bei fehlerhafter Eingabe scheitern.
Die Klassifizierung liegt in einer kleinen Lookup-Tabelle, die über PID geschlüsselt ist, mit Standard als Default für alles, was nicht gemappt ist. Neue UBEs werden im Rahmen der Development-Promotion-Checkliste in den Lookup aufgenommen, nicht danach. Der Monitor liest den Lookup einmal pro Polling-Zyklus und cached ihn für den Rest des Zyklus.

Alerts an Kanäle routen, die tatsächlich gelesen werden
E-Mail ist der Ort, an dem Alerts sterben. Die erste Version jedes Monitors, den ich geerbt habe, sendet an eine Verteilerliste mit zwölf Personen; im dritten Monat haben zehn davon eine Outlook-Regel, die die Nachrichten in einen Ordner verschiebt, den niemand öffnet. Das funktionierende Muster ist Routing nach Kritikalität: Kritische Alerts gehen an ein Paging-System mit On-Call-Rotation, Standard-Alerts gehen an einen dedizierten Teams- oder Slack-Kanal mit dem Betriebsteam, Noisy-Alerts gehen in eine tägliche Digest-E-Mail, die zusammenfasst statt zu spammen.
Das Teams-Kanal-Muster ist das Arbeitspferd für Standard-Alerts. Ein Webhook empfängt eine JSON-Payload mit JOBNBR, PID, Server, Fehlerzeitpunkt und einem direkten Link zur PDFDie UBE-Ausgabedatei, die für jeden Batch-Job erzeugt und im PrintQueue-Verzeichnis auf dem Enterprise Server gespeichert wird. Der Fehlerkontext befindet sich meist auf den letzten Seiten.-Ausgabe und zum Job Log in der Server-Manager-Webkonsole. Der Link ist entscheidend — ohne ihn kostet jeder Alert fünf Minuten Navigation, bevor der Engineer mit der Diagnose beginnen kann. Mit ihm erfolgt die Diagnose häufig direkt aus dem Alert heraus.
Das Paging-System, ob PagerDutyEine weit verbreitete Incident-Response-Plattform, die Bereitschaftspläne, Telefonalarme, SMS und automatische Eskalationen abwickelt, wenn Alerts nicht innerhalb eines definierten Zeitfensters bestätigt werden., Opsgenie oder eine der Open-Source-Alternativen, sollte insgesamt nur bei etwa fünf bis zehn PIDs auslösen, nicht bei jeder roten Zeile in F986110. Je weniger Jobs Menschen um 3 Uhr morgens wecken, desto mehr Glaubwürdigkeit behält der Monitor. Die Liste der paging-berechtigten UBEs sollte jedes Quartal überprüft werden, weil manche Jobs kritisch werden und andere es nicht mehr sind.
Alert-Deduplizierung ist das Detail, das jedes Team beim ersten Build falsch macht. Wenn der Periodenabschluss fehlschlägt, passiert das nicht isoliert — ein Fehler in R09801 bedeutet meistens, dass R0911P und R09866 in den nächsten zehn Minuten ebenfalls fehlschlagen werden, weil sie vom selben Datenzustand abhängen. Ohne Deduplizierung erhält der On-Call-Engineer vier Alerts für eine Root Cause und muss sie gedanklich zusammenführen. Das funktionierende Muster ist ein Fünf-Minuten-Alert-Fenster, geschlüsselt nach Kategorie und Server, in dem der Monitor einen zusammengefassten Alert mit allen zusammenhängenden Fehlern ausgibt, statt viermal zu feuern. Zwanzig Zeilen Gruppierungslogik, messbare Verbesserung der mittleren Zeit bis zur Bestätigung.
Alerts mit Kontext anreichern, den der On-Call-Engineer wirklich braucht
Der Unterschied zwischen einem nützlichen Alert und einer Steuer auf Aufmerksamkeit ist der angehängte Kontext. Ein bloßes "R42565 failed on server JDE_ENT01" zwingt den Engineer, sich im Server Manager anzumelden, den Job zu finden, das PDF herunterzuladen, es zu öffnen, nach unten zu scrollen und den Error Stack zu lesen. Multipliziert mit jedem Alert wird der Monitor zu einem Produktivitätsverlust.
Die Anreicherung, die sich bezahlt macht, entsteht durch den Join von F986110 mit F986114 (Job Step Detail) und das direkte Ziehen der letzten Zeilen des Job Logs in die Alert-Payload. Die Fehlermeldung — "Invalid Branch/Plant for Item 30000" oder "Mandatory Processing Option PR1 not set" — sagt dem On-Call-Engineer in fünf Sekunden, ob es sich um ein Datenproblem handelt (Analyst anrufen) oder um ein Codeproblem (Developer anrufen). Ohne diese Zeile ist jeder Alert ein Münzwurf.
Das zweite skalierende Anreicherungselement ist die Wiederholungserkennung. Wenn dieselbe PID drei Nächte hintereinander ungefähr zur selben Zeit fehlgeschlagen ist, sollte die Alert-Payload das sagen. Die Lösung ist selten dieselbe wie bei einem einmaligen Fehler, und der Responder muss wissen, worauf er schaut, bevor er beginnt. Eine kleine Recurrence-Tabelle, geschlüsselt nach PID und wöchentlich rollierend, besteht aus fünfzig Zeilen SQL und spart Stunden pro Monat.
Das letzte Element, das oft übersprungen wird, ist die Bestätigungsschleife. Wenn der On-Call-Engineer einen Job repariert, sollte er den Alert mit einem kurzen Kommentar als gelöst markieren können — "PO bad data, fixed in F4311 batch 1207" — und dieser Kommentar sollte in einer kleinen Monitor-Historientabelle landen. Drei Monate später, wenn dieselbe UBE am selben Tag des Monats fehlschlägt, sieht der nächste Responder die frühere Lösung und erkennt das Muster in dreißig Sekunden, statt wieder bei null anzufangen. Der Audit Trail gibt dem Operations Manager außerdem konkrete Daten für den vierteljährlichen Stabilitätsbericht: nicht "der Monitor hat 247 Fehler erkannt", sondern "247 Fehler, mittlere Zeit bis zur Bestätigung 11 Minuten, Top-3-Verursacher R47011, R42565, R09801, alle innerhalb der SLA behoben". Das sind die Daten, die den Build rechtfertigen.
Wenn Batch-Monitoring die Art operativer Disziplin ist, von der Sie mehr möchten, behandeln die verwandten Artikel zur JDE-Server-Manager-Konfiguration, zum UBE-Checkpoint- und Restart-Design sowie zu F986110-Archivierungsstrategien den operativen Stack von der anderen Seite. Das technische Projektportfolio auf dieser Website dokumentiert zwei der Produktionsmonitore, aus denen die hier beschriebenen Muster entstanden sind.