
Was ein Retrofit-Risiko-Dashboard wirklich ist
Im Kern ist es ein objektbezogener Risiko-Score, der vor Beginn der Retrofit-Arbeit berechnet und so dargestellt wird, dass das Team danach priorisieren kann. Die Inputs stammen aus drei Quellen: dem Ergebnis der Custom Code AnalyzerDas technische Konzept, das die objektbezogene Entscheidung liefert — behalten, retrofiten, verwerfen, neu schreiben. Sein Output ist der wichtigste Input des Dashboards.-Phase, der Runtime-Telemetrie der Quellumgebung und dem Abhängigkeitsgraphen der betroffenen JDE-Objekte. Der Output ist ein einzelner Wert pro Objekt — 1 bis 10, grün/gelb/rot oder eine andere Skala — plus die Aufschlüsselung der Faktoren, die den Wert verursacht haben.
Ein einzelner Wert ist wichtig, weil ein Entwicklungsfenster von 9 Wochen ungefähr 70 Arbeitstage für das Dev-Team bietet. Bei 350 betroffenen Objekten sind das im Durchschnitt rund fünf Stunden pro Objekt, inklusive Test. Ein solches Dashboard zeigt, welche Objekte einen Tag verdienen und welche fünfzehn Minuten. Ohne diese Sicht bekommt jedes Objekt dieselbe Zuteilung; die gefährlichen werden zu wenig getestet, die trivialen werden überentwickelt.
Auch der Dashboard-Teil des Namens ist wichtig. Es ist keine Liste, kein Urteil — es ist eine Sicht, die Projektmanager und Lead Developer jeden Montagmorgen anschauen, um zu entscheiden, wohin die nächsten zwei Wochen Aufwand fließen. Anfangs statisch, später laufend aktualisiert, wenn das Retrofit fortschreitet und Annahmen validiert werden.
Warum diese Disziplin überhaupt entstanden ist
Weil die Alternative — Retrofit-Arbeit als flache Liste von 350 gleich gewichteten Einträgen zu behandeln — ein vorhersehbares Fehlermuster hat. Das Team beginnt alphabetisch oben, verbrennt die ersten sechs Wochen mit einfachen Custom-UBEsUniversal Batch Engine — der Batch-Report-Runner von JDE. Custom-UBEs sind meist die zahlreichsten und risikoärmsten Objekte in einer Retrofit-Landschaft. in den Präfixen A und B und entdeckt in Woche sieben, dass die drei Custom-BSFNsBusiness Functions — kompilierter C-Code in der JDE-Runtime. Sie sitzen am unteren Ende des Abhängigkeitsgraphen und brechen alles, wenn sie fehlschlagen. im Kern des Order-Entry-Flows in ihrer aktuellen Form nicht tragfähig sind. Dann ist das Budget bereits aufgebraucht.
Das Risiko-Dashboard kehrt diese Reihenfolge um. Die gefährlichsten Objekte werden zuerst bearbeitet, wenn das Team frisch ist und noch Zeit zur Eskalation bleibt. Die trivialen Objekte wandern an das Ende des Plans, wo ein Junior Developer zehn davon an einem Tag erledigen kann. Gleiche Gesamtarbeit, völlig anderes Ergebnis in Woche neun.
Deshalb greifen Teams mit starken Projektmanagern auch dann zu dieser Disziplin, wenn kein formales Artefakt existiert. Sie rekonstruieren das Dashboard im Kopf, auf einem Whiteboard oder in einer halb defekten Tabelle — weil ohne diese Sicht das Upgrade verspätet oder fehlerhaft live geht, und sie beides schon gesehen haben.
Die drei Eingabedimensionen eines echten Risiko-Scores
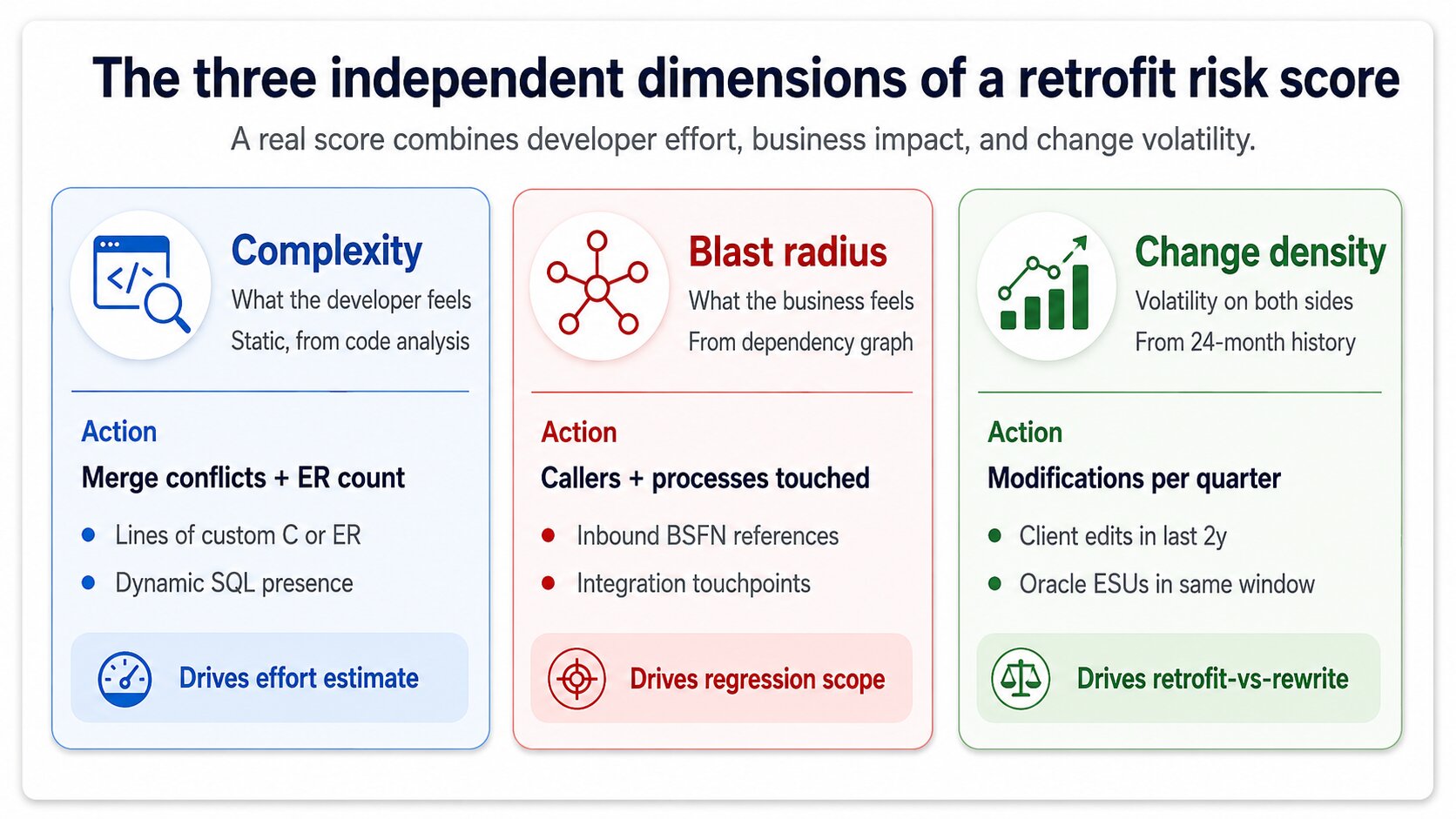
Ein Score mit nur einer Dimension ist eine Vermutung. Ein Score mit drei Dimensionen ist eine vertretbare technische Bewertung. Die drei wirklich relevanten Dimensionen sind Komplexität, Blast Radius und Change Density, und ein ernsthaftes Risiko-Dashboard berechnet alle drei unabhängig, bevor es sie kombiniert.
Komplexität ist das, was der Entwickler spürt. Anzahl der vom Fingerprint-Schritt vorhergesagten Merge-Konflikte, Zeilen Custom Code im Objekt, Vorhandensein von Event RulesDie visuelle Skripting-Schicht von JDE, die an Forms und Anwendungen hängt. Event-Rules-Retrofit ist schwieriger als C-Code-Retrofit, weil der Diff visuell und nicht textuell ist. statt reinem C, Vorhandensein von dynamischem SQL. Eine Custom-BSFN mit 40 Zeilen unverändertem C und einer umbenannten Variable ist Komplexität 1. Eine Custom-Anwendung mit 200 Event Rules und widersprüchlichen Oracle-Änderungen in drei Subforms ist Komplexität 9.
Blast Radius ist das, was das Business spürt. Wie viele andere Objekte von diesem Objekt abhängen, wie viele Geschäftsprozesse es durchlaufen, wie viele Integrationen es aufrufen. Eine Custom-UBE, die niemand ausführt, hat Blast Radius 1, selbst wenn ihr Code schwierig ist. Eine Custom-BSFN, die von 47 Anwendungen in Order Entry, Fertigung und Finance aufgerufen wird, hat Blast Radius 9, selbst wenn ihr Code trivial zu mergen ist. Beide Dimensionen sind unabhängig, und ein gutes Dashboard vermischt sie nicht zu früh.
Change Density ist das Volatilitätssignal. Wie oft das Objekt in der Quellumgebung in den letzten 24 Monaten geändert wurde und wie viele ESUs Oracle im selben Zeitraum für das entsprechende Standardobjekt geliefert hat. Hohe Change Density auf beiden Seiten bedeutet, dass künftige Retrofits schwieriger werden, nicht nur dieses eine — der Score sollte die strategischen Kosten von Retrofit gegenüber Neuentwicklung auf aktueller Oracle-Basis widerspiegeln.
Wie Runtime-Telemetrie den Score schärft
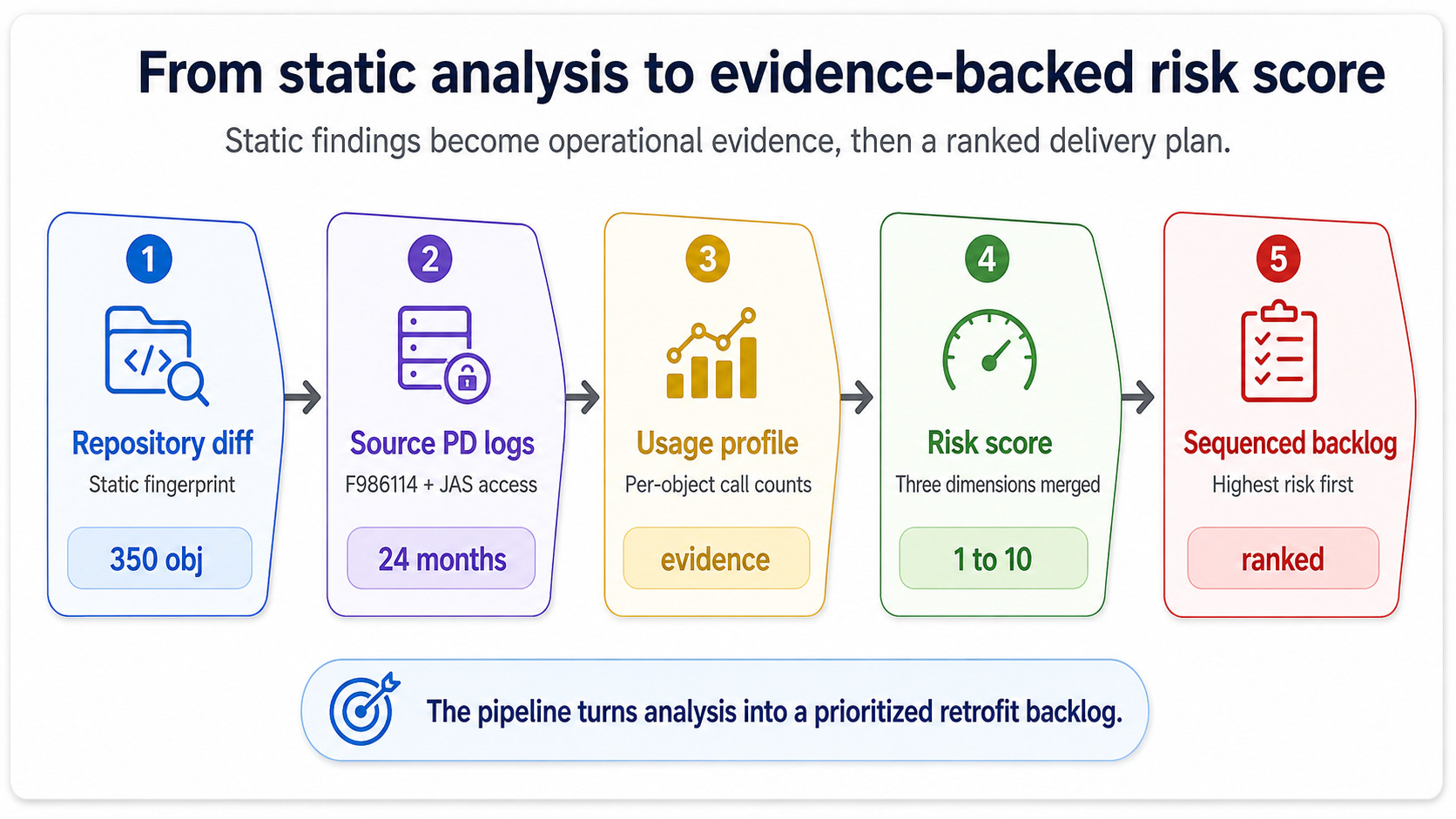
Die genannten Dimensionen können statisch aus Repository und Änderungshistorie berechnet werden. Das Risiko-Dashboard wird nützlich — und nicht nur eine akademische Übung — wenn Runtime-Daten aus der Quellumgebung einbezogen werden.
Die Quell-PDProduktionsumgebung in JDE — die Live-Umgebung. PD-Ausführungslogs sind die belastbare Quelle dafür, welche Objekte tatsächlich verwendet werden und wie oft.-Umgebung weiß Dinge, die statische Analyse nicht kennt. Sie weiß, welche Custom-UBEs im letzten Quartal null Mal liefen, welche Custom-BSFNs 11 Millionen Mal aufgerufen wurden und bei welchen Custom-Anwendungen sich Fehlerlogs in den Wochen vor der Go-live-Planung häuften. Ziehe die Ausführungszahlen für Batch aus F986114Die Job-Control-Tabelle von JDE. Sie protokolliert jede UBE-Übermittlung und ist die kanonische Quelle für Batch-Ausführungstelemetrie in der Quellumgebung. und für interaktive Nutzung aus den JAS Access Logs, und du erhältst ein Nutzungsprofil, das „Blast Radius“ von einer Schätzung in Evidenz verwandelt.
Genau dieser Schritt macht aus dem Dashboard mehr als eine statische Tabelle. Ein grüner Score, gestützt durch null Ausführungen, ist ehrlich. Ein grüner Score, der 11 Millionen Aufrufe ignoriert, ist ein Projekt, das beim Cutover scheitern kann.
Wie das Dashboard auf Artefaktebene aussieht
Die physische Form variiert — einige Teams verwenden eine Confluence-Seite, andere einen Power-BI-Report auf Basis eines SQL-Exports, die disziplinierten verwenden eine flache CSV, die jeder durchsuchen kann. Die Form ist unwichtig. Entscheidend ist, dass du für jedes der 350 betroffenen Objekte vier Fragen in weniger als einer Minute beantworten kannst.
Wie lautet der Score, und wodurch wurde er verursacht. Wer ist während des Retrofits für dieses Objekt verantwortlich. Welcher Aufwand und welcher Regression Scope sind geplant. In welchem Status ist es aktuell — nicht begonnen, in Entwicklung, im Test, freigegeben. Wenn das Dashboard diese vier Fragen für ein beliebiges Objekt nicht auf Abruf beantworten kann, ist es kein Risiko-Dashboard, sondern eine Liste. Der Unterschied ist nicht pedantisch: Listen ändern kein Verhalten, Dashboards schon.
Eine weitere Anforderung auf Artefaktebene ist, dass das Dashboard aktualisiert wird. Eine Retrofit-Schätzung aus Woche null wird in Woche drei falsch sein — einige Objekte erweisen sich als schwieriger, andere als trivial — und das Dashboard muss diese Korrekturen ohne Aufwand aufnehmen. Teams, die das initiale Scoring als Evangelium behandeln, liefern spät. Teams, die es als Hypothese unter laufender Revision behandeln, liefern pünktlich.
Wo das Dashboard in den restlichen Upgrade-Prozess passt
Es bedient zwei nachgelagerte Verbraucher. Das Entwicklungsteam nutzt es zur Arbeitsreihenfolge, nimmt in Woche eins die Objekte mit dem höchsten Score und spart die trivialen für das Ende des Plans auf. Das Testteam nutzt es zur Regression Scope Definition: Objekte mit hohem Blast Radius ziehen mehr Geschäftsprozesse in die Regression, Objekte mit niedrigem Blast Radius können oft allein durch automatisierte Smoke Tests abgedeckt werden.
Der dritte Verbraucher ist das Steering Committee, und hier unterschätzen die meisten Teams den Wert des Artefakts. Als aggregiertes Verteilungsdiagramm sagt das Dashboard dem CIO lange vor normalem Statusreporting, ob das Retrofit im Scope landen wird oder nicht. Ein rot verschobenes Dashboard ist ein Budgetgespräch in Woche zwei, kein Feuerwehreinsatz in Woche acht. Dieses frühe Signal ist nach der täglichen Priorisierung der zweitwertvollste Output der Disziplin.
Upstream hängt das Dashboard vollständig davon ab, dass Smart-Filter- und Fingerprint-Phasen sauberen Output geliefert haben. Garbage in, nutzloses Dashboard out. Deshalb lebt diese Disziplin nie isoliert — sie ist die dritte Stufe einer vierstufigen Pipeline, und wer die Vorarbeit überspringt, um direkt Scores zu vergeben, erzeugt Zahlen, denen niemand vertraut.
Was das für deinen Upgrade Scope bedeutet
Wenn der Partner, der dein Retrofit durchführt, dir in Woche eins der Entwicklung keinen risikobewerteten Backlog oder ein belastbares Äquivalent zeigen kann, hast du ein Problem, das du noch nicht kennst. Das Artefakt muss nicht genau so heißen — Synonyme wie Retrofit Triage Matrix, impact-weighted backlog oder risk-scored work order beschreiben dieselbe Disziplin — aber die drei Eingabedimensionen und die vier Fragen auf Artefaktebene sind nicht verhandelbar.
Fordere es an. Frage, welche Objekte am höchsten bewertet wurden und warum. Frage, wie Runtime-Telemetrie aus deiner Quellumgebung berücksichtigt wurde. Wenn die Antworten vage sind, wird das Team die gefährlichen Objekte auf die langsame Art entdecken, auf deine Zeit. Die Kosten dieser Entdeckung liegen in einer typischen 9.1-zu-9.2-Landschaft irgendwo zwischen drei und sechs zusätzlichen Entwicklungswochen plus einem spürbaren Rückschlag im Regressionstest.
Wenn du eine zweite Einschätzung möchtest, ob dein aktueller Retrofit-Plan die nötige Scoring- und Priorisierungsstruktur hat, buche eine kostenlose Beratung. Wir gehen die Dimensionen anhand deiner konkreten Landschaft durch, prüfen, wo die Runtime-Telemetrie in deiner Quellumgebung liegt, und sagen dir ehrlich, ob die Arbeit vor dir korrekt gewichtet ist — oder ob das Projekt eine schlechte Woche von einem Budgetgespräch entfernt ist.