

In a mature JDE 9.2 environment, a notable portion of data integrity issues in custom tables stem from "ghost records"—entries where PID is "JDE" or UPMJ is null because audit logic was lost during a migration from APPL events to C Business Functions. While a standard Power Form handles these fields automatically via the runtime engine, a BSFN requires manual population of the USER, PID, UPMJ, and TDAY fields. This guide provides a JDE BSFN audit fields example for updating user, date, and program ID data, focusing on how to correctly populate the record buffer to ensure database integrity.
The Five Pillars of JDE Audit Telemetry
Every standard table in the JDE schema, from the F0101 Address Book to the F4211 Sales Order Detail, relies on a five-field cluster to maintain record provenance: USER (User ID), PID (Program ID), JOBN (Workstation ID), UPMJ (Date Updated), and TDAY (Time of Day). In large-scale environments with thousands of custom objects, maintaining this telemetry is the difference between a brief data forensic task and a multi-day investigation through the logs. When these fields are neglected in custom C BSFNs, the database driver often defaults to the system user 'OVR' or leaves them null, effectively blinding the audit trail.
A common mistake in custom development is hardcoding the BSFN name into the PID field during a table update. If C code updates a record in the F0101, the PID should reflect the calling application—such as P01012—rather than the business function itself. This ensures that when a developer or auditor queries the audit columns, they see the actual entry point of the transaction. Without this distinction, every update appears to originate from a generic utility function, rendering the PID column useless for tracking the business process flow.
The JOBN field presents a specific challenge in modern 9.2 web-based architectures. In legacy fat client environments, this was a simple machine name, but in current HTML server environments, JOBN is frequently truncated to 10 characters or misrepresented as the logic server name unless explicitly retrieved via the environment's session information. Developers must ensure BSFN logic pulls the actual client workstation ID from the JDEUserSession structure. Failing to do so results in a database full of identical JOBN values, masking the physical origin of the change across the entire user base.
Unlike an APPL or UBE where the toolset handles these fields automatically during a standard Table I/O update, a C BSFN requires manual assignment for every JDB_InsertTable or JDB_UpdateTable call. You are responsible for populating the data structure passed to the API. If you omit these assignments, you risk corrupting the audit integrity of core tables like the F0101 or F03B11. I recommend creating a standard internal DSTR for audit fields to ensure consistency across all custom development projects, preventing the 'OVR' system user from becoming the most active "user" in the production environment.
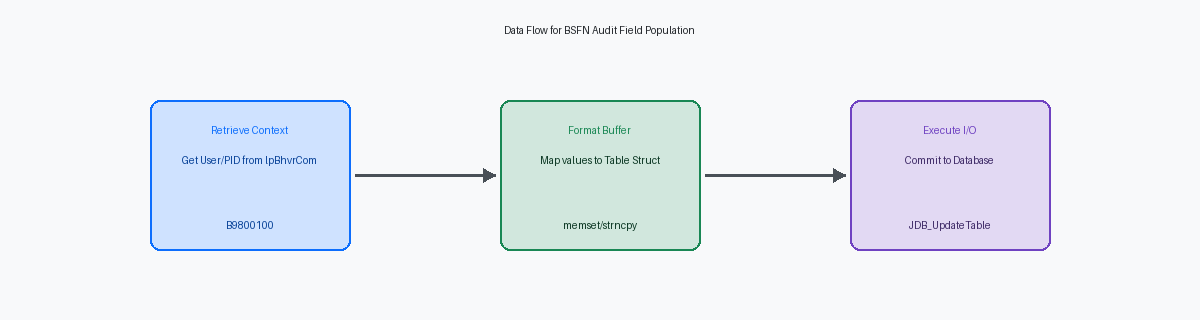
Retrieving System Values via B9800100 and B0000160
In the vast majority of custom C BSFNs, B9800100 (Get Audit Information) remains the standard for populating the primary audit fields: USER, UPOT, TDAY, and PID. A frequent failure in complex call stacks is passing a null or improperly initialized lpBhvrCom structure, which causes the PID to default to the BSFN name rather than the calling Application ID, such as P4210 or P4310. This breaks the audit trail for administrators trying to trace an erroneous record back to a specific entry point in the 9.2 web client. To maintain data integrity, developers must ensure the internal lpBhvrCom->szApplication is correctly mapped to the szProgramId parameter within the business function's main entry point before any table I/O occurs.
When requirements move beyond standard six-digit HHMMSS time stamps—common in high-frequency integrations via AIS or heavy batch processing in R47011—B0000160 (Get Local System Time) is the necessary alternative. This function provides the millisecond precision required to prevent primary key collisions on custom log tables when multi-threaded kernels in OCI or Azure environments attempt to write to the same table simultaneously. It is also the correct tool for handling specific time-zone adjustments when the enterprise server is in UTC but the transaction must reflect a localized warehouse time. Using B0000160 allows for alignment of JDE timestamps with the 13-digit Unix epoch values often required by modern 3PL providers.
For developers writing deep-stack C logic where performance is a constraint, such as within the nested loops of a custom Inventory Allocation engine, calling an external BSFN like B9800100 adds unnecessary overhead to the call stack. In these scenarios, use the JDB_GetInternalDate API directly. This API retrieves the system date into a JDEDATE structure without the context-switching cost of the JDE Object Dispatcher. In a UBE processing large volumes, switching from an external BSFN call to the direct API for audit date retrieval can shave several seconds off the total execution time. This prevents the cumulative latency that often turns a 30-minute batch job into a significantly longer bottleneck in mature 9.1 or 9.2 environments.
Handling JDEUTIME and Date/Time Mismatch
Modern 9.2 schema evolution creates a bifurcation in how we handle temporal metadata. While legacy master tables like F0101 and F4101 persist with the JDEDATE (UPMJ) and MathNumeric (TDAY) split, newer tables and custom objects often use the UTIME data type to provide a single, UTC-based source of truth. This shift requires a specific conversion step: you cannot directly map a standard date and time into a UTIME field. You must utilize the DeformatDateToUTime API, passing the date, time, and the user’s time zone context to populate the structure correctly.
In complex BSFNs where logic updates both legacy and modern tables, a slight temporal drift occurs if the system clock rolls over between sequential assignments. To maintain integrity across the transaction, capture the system date and time into local variables at the entry point of the function. Use these static values for both the legacy numeric assignments and the UTIME deformatting. This ensures that a record in F4211 and its corresponding entry in a modern custom audit table reflect the exact same millisecond of execution, preventing reconciliation errors during forensic debugging.
Performance at scale requires populating these audit values within the JDB buffer immediately prior to the JDB_InsertTable or JDB_UpdateTable call. Avoid the trap of issuing secondary I/O or using JDB_ExecuteSqlDirect to patch audit fields after the primary update has finished. In high-volume datasets, that extra I/O adds marginal latency per record, extending a 15-minute batch window significantly. Setting the buffer fields once ensures the database engine handles the write in a single atomic operation, preserving both performance and the transaction boundary.

Implementing Table I/O in C BSFNs
Most developers assume the JDB layer handles audit columns automatically during a C BSFN update. This is false. When calling JDB_UpdateTable, you must explicitly include the audit columns—typically USER, PID, JOBN, UPMT, and UPMJ—within the 'List of Columns to Update' array passed to the API to prevent the kernel from skipping them. If these columns are omitted from the update list, the JDB kernel ignores the values in your data structure, leaving the database records with stale telemetry. In a high-concurrency environment like a P4210 sales order session, missing these updates renders the audit trail useless for troubleshooting data integrity issues.
Memory corruption in the Program ID (PID) field frequently stems from a failure to initialize the record buffer. Before populating audit fields, you must execute a memset on the entire table structure to ensure no residual data exists in the memory block. Forgetting this step often results in the PID string containing invalid characters from previous operations being committed to the database. Because the PID field is used for filtering in OMW or custom UBEs, these corrupted strings break standard reporting and make it impossible to trace which BSFN actually triggered the database update.
The USER field requires strict adherence to its 10-character limit. Passing a string longer than 10 characters without a proper null terminator into the JDB layer will trigger a memory violation, often crashing the CallObject Kernel. You must ensure the source string is safely copied using strncpy to prevent overrunning the buffer. A single off-by-one error in a custom BSFN can bring down an entire enterprise server instance if the memory violation occurs in a high-frequency processing loop.
Efficiency matters when processing thousands of records in a single transaction. Instead of recalculating the system date and time inside a main loop, retrieve the audit values once and store them in a local structure. Assigning these pre-fetched values to the table buffer in each iteration reduces CPU cycles compared to repeatedly calling system APIs. This approach maintains responsive performance for the end user while ensuring every record in a large batch contains identical, accurate audit timestamps.
Transaction Processing and Audit Consistency
In a standard F4211 sales order update involving fifty lines and a single F4201 header, referential integrity depends on audit field uniformity. If the header shows a UPMJ of 124200 and a TDAY of 101530, but the lines drift across several seconds due to processing overhead, you lose the ability to group that transaction during a forensic SQL audit. To maintain this consistency, developers must capture the system time at the initial entry point of the business function and propagate that exact value across every JDE_UpdateTable or JDE_InsertTable call within the logic.
Managing manual commit boundaries requires the developer to pass the same hRequest handle across all table I/O operations within the transaction scope. Failing to link these calls to the same request handle often results in the middleware treating each update as an autonomous event. When the I/O is decoupled from the transaction handle, the database might commit the F4201 update while the F4211 lines hang or fail, leading to orphaned header records that appear updated even when the detail lines reverted to their previous state.
A common misconception involves the "Include in Transaction" flag within OWM. Checking this box for a custom BSFN does not automatically wrap its internal C code in a global transaction if the developer ignores the lpBhvrCom->hUser or fails to initialize the transaction ID properly. Without explicitly passing the transaction handle to the JDEBASE APIs, the BSFN executes in auto-commit mode regardless of the OWM setting. This oversight is why many transactional custom updates fail to roll back correctly during a kernel error or a timeout.
Accepting gaps in the audit sequence is a necessary trade-off for data reliability. When a complex transaction spanning multiple tables hits a rollback condition, the resulting missing timestamps in the database confirm that the system prioritized atomicity over continuous sequencing. These gaps are far more desirable than phantom updates where a header reflects a successful change but the lines remain out of sync due to a failed commit. Control the boundary at the C level to ensure that if the UPMJ is written once, it is written everywhere or nowhere at all.
Common Pitfalls: PID Truncation and USER Length
The 10-character hard limit on the PID and USER fields in the JDE data dictionary remains a primary source of truncated telemetry in custom development. While a standard business function name like B5500010 fits, developers frequently attempt to pass long-form application names or descriptive strings into the PID field, leading to silent truncation at the database level. If calling a BSFN from a deep sub-form or a nested power communication, the PID should reflect the originating object. This ensures that when a record is locked or corrupted, the DBA can trace the change back to the specific entry point rather than a generic utility function.
Hardcoding "JDE" as the USER value in custom C code is a legacy practice that effectively blinds the audit trail for automated interfaces. This implementation obscures whether a record was modified by a scheduled batch job, an AIS-driven orchestration, or a manual correction. You must retrieve the actual session user through B9800100 or the internal lpBhvrCom structure. Even within batch UBEs, the audit logic should capture the user who submitted the job to the server map, rather than defaulting to the system account under which the JDE services are running.
Discrepancies between the logic server and the database server clocks can result in UPMJ values that appear to be future-dated relative to the transaction timestamp. In a multi-foundation or geographically distributed environment, a slight offset between the web and logic tiers can cause integrity reports to flag legitimate records as errors. Always validate the UPMJ field against the system date during the initialization of the data structure. If the logic server's time is ahead of the database, you risk breaking sequential dependency checks in modules like Sales Order Management where the date-time stamp dictates the availability of the next status.
Ensuring proper audit field population in BSFNs, like the USER and PID fields, is essential for data integrity and traceability. If this analysis of BSFN table I/O provided value, you will find similar technical insights in my documentation on JDE cache management.
