

Custom tables in JD Edwards EnterpriseOne — the F55, F56, F57, F58 and F59 namespace — accumulate fast on any installation that takes its business processes seriously. Custom interface tables for partner integrations, staging tables for legacy loads, audit tables, configuration tables, lookup tables that the standard model does not provide. By the third year of a JDE installation a typical shop has 30 to 80 custom tables, and the question of how to keep their contents clean stops being theoretical. JD Edwards BSFN custom table validation with data dictionary items is the discipline that answers it — and the discipline most installations skip, because the standard tooling makes it look optional.
The shortcut that everyone reaches for first is to write validation rules inside the application or UBE that loads the table. It works on the first caller. It survives the second. By the fourth entry path — a form, two UBEs, and an orchestration — the rules are out of sync and the table is accumulating rows that violate constraints nobody documented. The fix is to anchor every validation rule to a data dictionary item, expose the rules through a single BSFN, and call that BSFN from every write path.
Why the data dictionary is the right anchor
The data dictionaryThe JDE metadata layer that defines every column used in the system: alias, data type, length, decimals, default UDC binding, edit rules, and display attributes. Stored in F9200 and related tables. in JDE is not a passive metadata layer. It is the single declaration of what each column means — its data type, its length, its default UDC binding, its allowed range, whether it is required — and the entire JDE runtime already respects it for standard tables. The standard form for P4210 reads the DD definition of UORG and enforces the length, type and UDC validation automatically before the user can save the row.
The mistake most custom development makes is to ignore this layer for custom tables and re-implement the same rules in hardcoded code. The result is two definitions of "what valid means" for the same column — the one in F9200 that the system enforces in some paths, and the one in the BSFN or Event Rules that enforces it in other paths. They drift within months. The drift only surfaces when a Tools Release upgrade changes how the DD layer is evaluated, or when an orchestration starts writing rows that the form would have rejected.
The discipline that solves this is straightforward: every column in every custom table is bound to a data dictionary item, and every validation rule expressed about that column is expressed in the DD definition, not in code. The BSFN that validates the row reads the DD at runtime and applies the rules it finds there. Add a new allowed value to a UDC, change a length, mark a previously optional column as required — the change goes in F9200 once, and every caller of the BSFN respects it immediately.
The non-obvious benefit is that the same metadata feeds reporting, AIS service definitions, and any custom UDO that surfaces the column. The DD becomes what it was designed to be — the source of truth for the column — instead of one of several competing definitions.
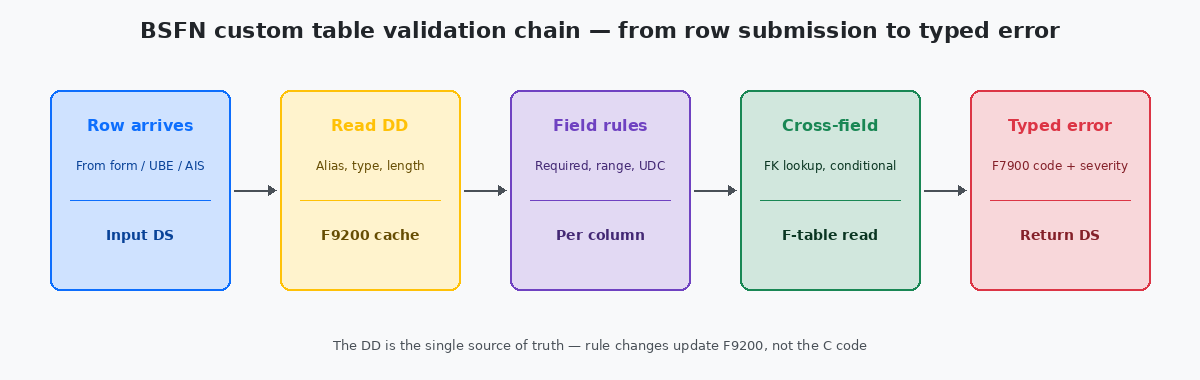
Designing the validation BSFN around the DD
The validation BSFN follows a consistent structure regardless of which custom table it serves. It takes the input row as a data structure, reads the DD definition for each column in the row, applies the syntactic checks the DD defines, then runs the cross-field and cross-table checks that the DD cannot express, and returns a structured error result.
The first half — the DD-driven syntactic pass — is mechanical. For each column, read the F9200 row through the standard B9200500Get Data Dictionary Information — the standard JDE BSFN that returns the DD definition for a given column alias. Cached internally by the JDE runtime, so repeated calls are cheap. business function (the JDE runtime caches the result, so the per-column cost is negligible after warmup). Check that the value matches the declared data type. Check that the length does not exceed the declared maximum. Check that, if the column has a UDC binding, the value exists in F0005 for that UDC product code and type. Check that, if the column is declared required, the value is not blank.
The second half — the cross-field and cross-table pass — is what the DD cannot express and what the BSFN exists to centralise. A custom F55 staging table may require that AN8 exists in F0101 before a row referencing it can be inserted. The DD says AN8 is an 8-digit numeric; the BSFN says AN8 must be present in the address book master. These two layers are complementary: the DD covers what can be said about the column in isolation, the BSFN covers what can only be said in context.
The output is the same structured error pattern that any well-designed validation BSFN uses: severity (E or W), an error code that maps to a row in F7900, an optional substitution parameter for the message. Every caller — form, UBE, orchestration — reads the same fields back and reacts in its own way. The semantics are identical across paths; only the user experience changes.
Practical patterns for F55 staging table validation
The most common case where this discipline pays off immediately is staging tables for inbound data — partner integrations, legacy migrations, EDI feeds. These tables receive rows from sources that have no understanding of JDE rules, and they are the boundary at which JDE rules have to be applied. A single validation BSFN sitting on the staging table is the cheapest enforcement point in the entire data flow.
The pattern that scales is to give every staging table a paired BSFN named by convention — staging table F5511Z1, validation BSFN B5511Z1V, with the V suffix marking it as a validation function. The UBE that loads from the staging table to the production table calls the BSFN once per row, before any insert. Rows that fail validation are marked with the returned error code in a status column on the staging table itself, and the UBE writes a structured error report alongside its main output.
The discipline that holds the pattern together is that the staging table includes audit columns the validation depends on: ERRC (error code), ERRT (error timestamp), VLDT (validation timestamp), VLDU (validation user / process). These columns are populated by the BSFN, not by the caller, which keeps the contract explicit: the caller submits a row and reads back its validation state, full stop. No hidden assumptions about who writes which column when.
One thing that surprises teams the first time they implement this: the validation BSFN should be re-runnable against rows that have already been validated. Idempotency on the validation side is just as important as idempotency on the load side. A row that previously failed validation but has been corrected by a manual update needs to be re-validated cleanly, not skipped because it already has an error code from the previous run. The pattern is to clear ERRC at the start of each validation pass and rewrite it based on the current row state.
Where pure DD edits stop being enough
The data dictionary handles a defined set of rules: type, length, default value, UDC membership, required flag, default edit rules through the visual edit rule designer. Everything beyond that has to live somewhere, and the question is where. The wrong answer is to keep stretching the DD with workarounds; the right answer is to recognise the boundary and put the rest in the BSFN.
Cross-field rules are the first thing that exceeds the DD. A custom table that requires DOCO to be present when OPSTS is "I" but not when OPSTS is "P" cannot be expressed in the DD definitions of either column. The dependency between the two is the rule, and the BSFN is the only sensible place for it. The same applies to conditional required-ness, mutual exclusion, and rules that depend on the value of a column in another table.
Foreign-key lookups are the second. The DD cannot say "AN8 must exist in F0101"; that statement is about the row's relationship to another table. The BSFN reads F0101 by AN8 and either finds a match or returns an error. The lookup is cheap if the index supports it, expensive if it does not — and the BSFN is the right place to make the engineering trade-off, which is rarely visible to a DD configurator.
Domain rules that depend on configuration are the third. A custom rule that says "the credit limit check applies only for customers in business unit 100 through 199" mixes a hardcoded range with a configurable threshold, and the right place to express it is in the BSFN reading from a small configuration table — never in the DD edit rule designer, which has neither the expressiveness nor the maintainability for it.

Testing and maintaining DD-bound validation BSFNs
Validation BSFNs that read from the DD have a unique testing challenge: their behaviour depends on the DD state, not only on the input row. A test that passes today may fail tomorrow because someone added a UDC value or changed a column's required flag. The testing discipline has to account for this by treating the DD definitions as part of the test fixture, not as an environmental constant.
The pattern that works is a unit-test UBE that, for each test case, asserts both the BSFN's response and the DD state it relied on. A case like "AN8 = 7777777, valid customer, returns clean" includes a pre-check that AN8 in F9200 has length 8 and that 7777777 exists in F0101. If either pre-check fails, the test reports infrastructure drift rather than logic regression — and the developer knows where to look. Twenty to thirty test cases per BSFN, with paired pre-checks, covers the typical custom table validation surface.
Maintenance over time is the second challenge. A DD change made years after the BSFN was written can subtly alter its behaviour — adding a UDC value broadens what the BSFN accepts; tightening a required flag breaks rows that previously passed. The discipline is to treat the DD as code: every change to a DD item used by a validation BSFN goes through the same review and promotion path as the BSFN itself, with the impacted BSFNs listed in the OMW project notes.
For more on this side of JDE development, the related articles on BSFN testing harnesses, on F-table archival strategies, and on custom order entry validation cover the surrounding territory. The technical project portfolio on this site documents two production validation suites built around the DD-driven pattern described here.
