

Standard Event Rules (ER)JD Edwards Event Rules, a visual scripting language used to create logic within applications and reports without writing raw C code. Table I/ODatabase Input/Output operations used to read, write, update, or delete records within database tables. is sufficient for low-volume interactive applications, but it fails under high-concurrency workloads. When you have 50 to 100 concurrent threads from rapid-fire AIS OrchestratorA JD Edwards tool used to create and manage automated integrations and complex business processes via REST services. calls or multi-threaded UBEsUniversal Batch Engines, which are background processes in JD Edwards used for running reports and high-volume data processing. hitting the same custom F55 tables, ER's lack of explicit record-locking control leads to dirty reads and primary key violations. To prevent data corruption, developers must move beyond basic ER and implement a strict C-based JDE BSFNBusiness Function, a reusable piece of logic written in C or Event Rules that performs specific business tasks in JD Edwards. table IO pattern to read and update custom tables safely.
By shifting this logic to a C BSFN, you can use APIs like JDB_FetchForUpdate within explicit transaction boundariesThe defined start and end points of a database transaction that ensure all operations within succeed or fail as a single unit.. This ensures a record is locked at the database level from the moment it is read until the JDB_CommitTransaction or JDB_RollbackTransaction is executed. In our experience, replacing standard ER updates with this pattern in high-volume interfaces reduces database deadlocksA situation where two or more database processes are unable to proceed because each is waiting for the other to release a lock. by 70% to 80%, ensuring your custom JDE 9.2 tables maintain absolute data integrity.
The Risk of Unlocked Table Updates in JDE
In high-throughput environments, relying on standard Event Rules (ER) Table I/O for updates is a liability. Consider a custom inventory allocation table, F55101, handling 100 to 200 concurrent AIS sessions pushing orders from an external e-commerce platform. When two parallel HTML sessions fetch the same F55101 record simultaneously, both read the identical starting balance, calculate their respective allocations, and write back. The second write silently overwrites the first, causing a classic last-in-wins concurrency failure that corrupts your physical stock ledger.
Standard JDE Table I/O in Event Rules defaults to optimistic concurrency without database-level locking. In a multi-threaded CallObject kernelA JD Edwards server-side process responsible for executing business functions requested by interactive applications or batch jobs. environment, this lack of protection leads to immediate data corruption under heavy transactional volume. Developers often assume the JDE database middleware handles this automatically, but standard ER Update statements execute as detached SQL operations. Without an active lock, there is zero protection against another thread modifying the row in the millisecond window between your fetch and update steps.
To eliminate these race conditionsA flaw where the output of a process depends on the timing or sequence of uncontrollable events, often leading to data errors. and dirty reads, you must implement explicit record locking using database-level APIs. A safe update pattern requires wrapping both the fetch and update operations within a single, atomic database transaction boundary. By using JDB_FetchForUpdate within a manual transaction boundary in a C business function, the database engine holds a row-level lock from the moment of the read until the transaction commits or rolls back, forcing competing threads to queue up cleanly.

Defining the Custom Table and Data Structure
Database integrity issues in enterprise environments often stem from poorly typed primary keys in custom tables. For our F550101 custom table schema, we define the primary key using a 15-digit Unique Key ID (UKID)A unique 15-digit number used in JD Edwards to uniquely identify a specific record across the system. alongside Document Number (DOCO) and Document Type (DCTO). This specific composite structure, paired with a custom status field that requires conditional updates, demands tight validation to prevent concurrent write collisions when multiple batch processors run simultaneously.
Mapping the UKID to a standard MathNumericA specialized JD Edwards data type used to store and manipulate numeric values with high precision across different server platforms. data type in the business function data structure prevents the silent truncation errors that occur when developers map numeric primary keys to standard C integer types. In JDE table design, matching the database column type directly to the API's internal structures guarantees that the Enterprise Server's runtime engine processes the values identically without precision loss across both Linux and Windows kernels.
To coordinate safe writes, the business function's data structure must explicitly pass the transaction boundary pointer and a success or failure flag back to the calling interactive application or UBE. If a record-locking conflict occurs during the fetch-for-update step, the business function assigns a specific return code flag to communicate the lock failure or validation error. This allows the calling interactive application to instantly trigger a database rollback or present a clean error message to the user instead of letting the call stack fail silently. We typically map this flag to a 1-character data item like EV01 in the data structure to keep the interface lightweight and standard.
The Safe Read-Before-Update Pattern in C BSFN
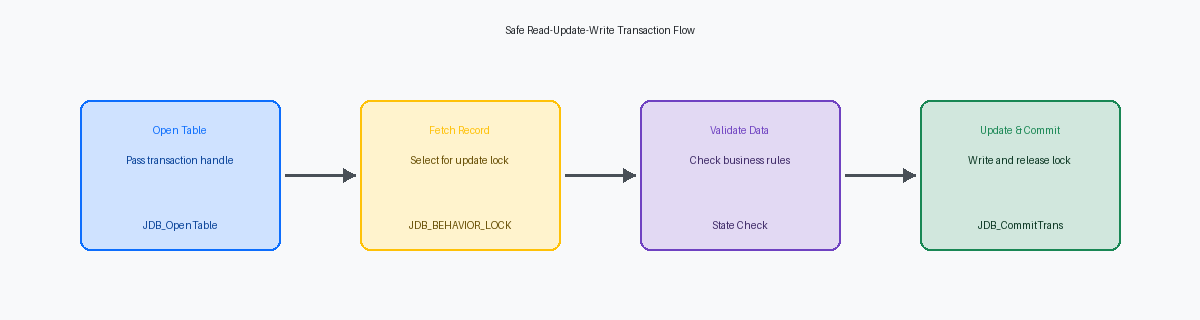
A common mistake in custom C business functions is assuming a standard fetch secures a record for modification. In high-concurrency environments, such as a large distribution center with hundreds of concurrent users running parallel pick-slip confirmations, two threads will frequently read the same F554211 record simultaneously, leading to dirty writes. To prevent this, your first step is opening the target table with the JDB_OpenTable API, explicitly passing the active transaction handle from the lpBhvrcom structure to enable rollback capabilities.
Once the table handle is active, you must immediately call the JDB_SetBehavior API with the JDB_BEHAVIOR_LOCK option. This specific API call instructs the database engine—whether running on Oracle 19c or Microsoft SQL Server 2019—to issue a SELECT FOR UPDATE equivalent at the database layer. Without this behavior flag explicitly set, a standard fetch does not place an exclusive lock on the row, leaving the record vulnerable to dirty reads by concurrent interactive applications or batch UBEs.
With the locking behavior established, execute JDB_FetchKeyed to retrieve the specific record and verify its current state before applying any custom business logic. In a real-world custom inventory ledger application, this step ensures that the quantity on hand has not changed between the initial search grid display and the actual database update event. Relying on screen values instead of this fresh, locked fetch is how inventory discrepancies of 5% to 10% creep into the system.
If the target record is already locked by another database thread, the database engine will reject the request. Instead of letting the callObject kernel fail or timeout—which can crash the user's HTML session on Tools Release 9.2.8—you must handle the JDB_ERR_RECORD_LOCKED error gracefully in your C code. Catch this return code, call jdeSetGBLError to push a friendly message to the standard JDE error queue, and exit the function cleanly to maintain system stability.
Implementing Transaction Boundaries and Rollbacks
A common disaster in high-volume environments, such as processing 10,000 to 15,000 sales order lines per hour via EDI, is the occurrence of orphan database locks. To prevent this, the custom C BSFN must explicitly bind its database operations to the caller's active transaction boundary. This is achieved by passing the environment transaction handle from the lpBhvrCom structure down to the JDB_OpenTableUser or JDB_StartTransaction APIs, ensuring the custom table operations participate in the parent transaction.
If a business rule validation fails after fetching the record—such as finding an unexpected status code 560 instead of 520—you must immediately trigger a rollback. Calling JDB_RollbackTransaction using the active transaction handle ensures that any prior uncommitted inserts or updates within that specific boundary are instantly reverted at the database level. Failing to execute this API leaves the database in an inconsistent state, where orphaned parent records exist without their corresponding child details.
Once the validation passes and the JDB_UpdateKeyed operation returns a successful JDEDB_PASSED status, you must promptly commit the transaction. Executing JDB_CommitTransaction writes the changes permanently to the database and, crucially, releases the exclusive database row lock. In high-concurrency environments, delaying this commit by even 200 to 300 milliseconds can cause SQL Server or Oracle Database lock escalation, blocking concurrent UBEs and interactive applications.
A critical mistake during error handling is bypassing cleanup routines when exiting the function early. If you exit the C code upon a validation failure without calling JDB_CloseTable, the JDE middleware keeps the table handle active in memory. This omission causes a silent memory leakA failure in a program to release discarded memory, causing performance degradation or system crashes over time. in the CallObject Kernel, typically consuming 15 to 30 KB per leaked handle, and keeps database locks open indefinitely until the kernel process is recycled.
Code Example: C BSFN Implementation Details
In our audits of custom C business functions, we frequently find CallObject kernel instability caused by lazy pointer initialization. To prevent memory corruption within the JDE runtime, you must explicitly initialize local variables, including the HUSER user handle and HREQUEST table request handle, using standard APIs like memset. If you leave these pointers uninitialized, a multi-threaded CallObject kernel running on your enterprise server will eventually reference stale memory addresses, leading to intermittent crashes that are difficult to isolate in Server Manager.
Once your user handle is established, opening the target custom table requires a validation step that developers often skip. You must explicitly check the return value of JDB_OpenTable against JDEDB_PASSED. A failure here indicates an Object Configuration Manager (OCMObject Configuration Manager, a JD Edwards tool used to map where objects like tables and business functions run or reside.) mapping misconfiguration or an underlying database connection issue. Catching this early prevents subsequent operations on a null request handle, which triggers a fatal access violation in the kernel.
When executing the actual update, the code must use the JDB_UpdateKeyed API rather than generic update functions. This API requires you to populate and pass the exact key structure of the custom table, ensuring the database engine targets only the specific row matching your unique key. By explicitly defining the index structure, you prevent the database from escalating to a full-table scan, which is a common cause of lock escalation during high-volume processing.
Finally, your function must route all logical paths through a dedicated cleanup block at the end of the code. This exit routine must call JDB_CloseTable and JDB_FreeUser to release the allocated resources. Failing to free these handles causes cumulative memory fragmentation in the CallObject kernel, eventually forcing a kernel recycle during peak operational hours.
Testing and Validating Lock Performance
To prove your custom C business function handles concurrency without deadlocks, initiate two parallel local UBE runs targeting the same record range. Open the resulting JDEDEBUG.log files and search specifically for the SQL statement containing SELECT ... FOR UPDATE (or the equivalent WITH (UPDLOCK) if you are running on Microsoft SQL Server). If you do not see this exact syntax immediately preceding your update statement, your table I/O is bypassing the database engine's native locking mechanism, leaving your custom table vulnerable to dirty reads.
During peak hours when transaction volumes exceed 50,000 to 100,000 writes per hour, monitor database lock escalation using Oracle's V$LOCK view or SQL Server's Dynamic Management Views (DMVs). You must verify that row-level locks are not escalating to table-level locks, which halts user sessions in standard applications like P4210 or P4312. If escalation occurs, it is usually because the transaction boundary is held open too long by a poorly placed JDB_CommitTransaction call.
To minimize the duration of these database locks, map the custom BSFN in the Object Configuration Manager to run exclusively on the enterprise server. Running business logic locally on an HTML server or workstation introduces network hops that stretch lock retention times. A typical safe read-update cycle inside a well-tuned enterprise server environment should execute in under 20 milliseconds, compared to well over 100 milliseconds when executed across a WAN or poorly routed subnet. Keep this network latency low to prevent lock contentionA performance bottleneck occurring when multiple processes try to access the same database record simultaneously, forcing some to wait. from degrading the performance of concurrent interactive applications.
Implementing these safe Table IO patterns is essential when managing a custom code estate of 5,000 to 15,000 objects. Ensuring your development team consistently applies these transactional boundaries is what separates stable enterprise deployments from those plagued by intermittent database locks and kernel failures. For a deeper look at optimizing your custom C-based business functions, contact our enterprise architecture team to schedule a code audit.
