

From Raw List to Estimate: How to Make a JD Edwards Upgrade Defensible
A JD Edwards upgrade should not begin with an estimate. It should begin with a much more uncomfortable question: what is the real scope to be estimated? In theory, the answer seems simple. You extract the custom objects, compare them with the standard, look at what has been modified and calculate the work required to move them from the source release to the target release. In practice, this linear sequence rarely exists. Real environments contain years of interventions, copies of standard objects, reports that are no longer run, technical objects, modified versions, objects created for emergencies long forgotten, third-party components, still-critical customizations and customizations nobody uses anymore. For this reason, the estimate cannot be the first step: it must be the consequence of a qualification process.
The central point is to transform a raw listInitial, broad and deliberately conservative list of objects potentially relevant to the upgrade. into a Suggested Object ListReasoned list of objects that, after filters and checks, deserve to remain within the analysis or estimation scope.. This transformation is not a numerical reduction exercise. You do not start from thousands of objects with the goal of reaching a few hundred because “less is better”. You start from a broad snapshot because, in a serious assessment, missing an important object is more dangerous than analysing one extra object. The screening phase is therefore used to qualify the scope: every object must be excluded, kept, classified or re-included for a technically documentable reason.
This distinction completely changes how the process should be read. An initial list is not yet a working list. It is a collection of candidates. Some candidates will be confirmed, others will be reclassified, and others may be moved outside the operational scope of the upgrade. But no decision should be invisible. An object does not disappear because someone wants to lower the final number. It leaves the scope only if there is a verifiable criterion: for example because it is standard, because it belongs to a category that does not require application retrofit, because it is no longer used, because it is handled separately, or because the customer consciously decides not to include it.
Why the initial list must be broad
The first mistake to avoid is looking for a “clean” list too early. In a mature JD Edwards environment, what appears simple can hide complex dependencies. A report may look custom but be almost identical to the standard. A copy may seem harmless but derive from a standard object that Oracle modified in the target release. A batch version may look secondary but be used during month-end close. A technical object may appear out of scope but be required to make a process chain work. This is why the initial phase must accept a certain level of informational redundancy: it is better to start wide and then qualify, rather than start narrow and discover too late that relevant elements were missed.
The extractsFiles produced from the customer environment that describe objects, versions, metadata, usage, differences and other elements useful to the assessment. received from the customer are used precisely to build this initial snapshot. They are not a simple administrative attachment: they are the raw material of the entire process. They must be received, preserved, organized and transformed into workable data without losing the connection to the original source. This separation between received data, processed data and final results is essential for traceability. If a number is challenged, if an object is re-included, if an estimate is revised, it must be possible to trace the reason and the source.
The raw list, therefore, is not an error to correct. It is a necessary phase. It contains noise, but it also contains important signals. The assessment work consists in separating the two. The value is not in immediately producing an apparently elegant list, but in building a path that makes clear why some elements are kept and others are not.
Screening is not a cut: it is a classification
The word “screening” can be misleading. It can suggest a mechanical, almost accounting-style cut: take a list, delete rows, obtain a smaller number. In a serious JD Edwards upgrade, screening is instead a progressive classification. Every object is read within a technical category. Is it a standard object? Is it pure custom? Is it a direct modification to a standard object? Is it a copy of a standard object? Is it a version? Is it a batch report? Is it an object no longer executed? Is it a technical component that should not be estimated as application development? Is it an anomaly to bring to the customer’s attention?
This classification is what makes the assessment defensible. It is not enough to say that an object was excluded. You must be able to say why. It is not enough to say that an object was kept. You must be able to explain what risk it represents. It is not enough to say that a copy was identified. You must understand which standard it derives from, whether that standard has changed, how far the copy has diverged from the reference and what work will be required to bring it onto the new release.
In this sense, screening is closer to editorial review than to automatic cleanup. Editorial review does not delete sentences at random: it distinguishes what is necessary, what is redundant, what is ambiguous and what requires rewriting. In the same way, technical screening distinguishes the objects that require retrofit, those that require verification, those that require a decision, those that should not weigh on the estimate and those that cannot be ignored.
Standard objects, modifications and pure custom
One of the first distinctions concerns the nature of the object. A pure standard object should not be treated as a custom object. If it does not contain a customer customization, it should not weigh as custom retrofit work. This does not mean the standard is irrelevant: the standard is the reference against which the upgrade impact is measured. But the estimate of custom work must focus on what the customer has actually changed, copied, extended or created.
Direct modifications to standard objects are different. Here the problem is immediate: if the Oracle standard changes in the target release, the customer customization must be reinterpreted in the new context. It is not just a matter of moving code or configuration from one environment to another. It is about understanding whether the customer change is still valid, whether it conflicts with the new standard, whether it can be removed because it has been absorbed by the target release, or whether it must be rewritten to coexist with the new behaviour.
Pure customObject created by or for the customer, not necessarily derived from an Oracle standard object. raises a different kind of problem. If it is truly independent from the standard, it may not require a direct comparison with an Oracle source object. But that does not automatically make it simple. It may depend on tables, functions, business views, data structures, processing options or logic that change between releases. It may compile without errors but produce different results. It may be technically valid but functionally obsolete. For this reason, pure custom must also be qualified, not just counted.
The most delicate case: copies of standard objects
Copies of standard objects are often among the most critical objects in a JD Edwards upgrade. A copy is not a duplicate and it is not an object to discard: it is a custom object that preserves a technical relationship with an Oracle standard object, the so-called based-onThe Oracle standard object from which a custom copy derives or against which it should be compared.. This relationship is the heart of the problem. If a copy derives from a standard object, its fate depends not only on what the customer did to the copy, but also on what Oracle did to the standard in the new release.
When Oracle modifies the standard object in the target release, the copy cannot be treated as if it lived in isolation. If the customer copy is substantially identical to the source standard, the work may be relatively simple: it may be necessary to recreate it or realign it from the new standard. But even in this case it is not discarded. It is classified as a low-divergence copy, that is, as an object that may be simple to handle but still needs to follow the correct path.
The real problem emerges when both evolutionary lines have moved. On one side, Oracle has modified the based-on in the target release; on the other, the customer has modified the copy in its own environment. At that point, the upgrade becomes an exercise in reconciling two different histories of the same object. You need to understand which Oracle changes are important, which customer customizations must be preserved, which parts are obsolete, which parts conflict and what is the safest way to rebuild the final object. This is where a copy can become much more difficult than pure custom.
This is why copies of standard objects should never be treated as duplicates. A copy is not a row to delete in order to lighten the list. It is an analysis category. In some cases it will be simple, in others complex, and in others it will require a very detailed comparison. But the criterion is never “it is a copy, therefore discard it”. The correct criterion is: it is a copy, therefore identify the based-on, measure the divergence, verify the change in the standard and estimate the recomposition work.
This topic deserves its own deeper explanation, because it involves comparison techniques, similarity, structure, naming and functional knowledge. For a specific explanation of how to identify standard copies in JD Edwards, refer to the article Copies of JD Edwards Standards: how I identify them.
Last Run Date: when real usage enters the assessment
Another crucial criterion is the Last Run DateDate of the last known execution of a report or batch version. It is used as an indicator of real usage, not as an absolute truth., often abbreviated as LRD. This data point introduces a dimension that technical comparison alone cannot provide: real usage. An object may be custom, technically valid and historically important, but if it has not been run for a long time, it is reasonable to ask whether it should still enter the operational scope of the upgrade.
For batch reports and versions, the Last Run Date is a particularly useful indicator. In JD Edwards terms, the last execution data of a batch version is normally associated with the Versions List, that is, table F983051JD Edwards versions table. The VRVED field is commonly used as Date - Last Executed for batch versions., specifically the field VRVEDField indicated as Date - Last Executed; it represents the version’s last execution date.. Submitted job history may also provide useful information, for example through the logic of submitted jobs and table F986110Job Control Status Master: table that keeps records on the status of jobs submitted to queues.. However, these data points must be read with caution: history may be affected by purges, retention, configurations and different behaviours across environments.
In the assessment process, a practical threshold may be 18 months. If a report has not been executed for more than 18 months, it may become a candidate for exclusion from the operational scope of the upgrade. The important word is “candidate”. It does not mean the report is automatically deleted, ignored or declared useless. It means the usage data opens a question: is this report still needed? Has it been replaced? Is it run manually, rarely but critically? Is it used only at year-end close? Is it launched by another process that does not correctly update the expected date? Is it an emergency object the business wants to keep?
This caution is essential. An LRD-based criterion must not become a guillotine. It must become a technical and functional conversation. If a report has not run for two years and nobody knows what it is for anymore, it is reasonable not to weigh it as a fully operational object. If, however, it has not run for two years because it is used only in exceptional but regulatory-critical scenarios, the discussion changes. The Last Run Date does not make the decision instead of the analyst: it makes visible a question that would otherwise remain hidden.
The 18-month threshold is not a mathematical truth
The 18-month threshold is useful because it forces a distinction between objects that are still alive and objects that are probably dormant. But it should not be presented as a mathematical truth. In some contexts, a report not executed for 18 months may be irrelevant. In others, it may be rare but indispensable. An annual process, a tax requirement, an audit check or an emergency function may have low frequency and high importance. This is why the time criterion must be combined with business knowledge.
The correct way to use LRD is to place it within a decision matrix. A recent custom report strongly enters the scope. An old, unexecuted report not recognized by the business may be a candidate for exclusion. An old report confirmed by the customer remains. A report without reliable Last Run Date requires further verification. In all cases, the decision must remain traceable.
This is also important in the customer relationship. Saying “we are not estimating this report because it has not run for 18 months” is too weak. Saying “this report is a candidate for exclusion because the Last Run Date indicates no recent usage; we request functional confirmation before removing it from the operational scope” is much stronger. In the first case, a cut is imposed. In the second, a shared decision is built.
Technical objects, administrative objects and anomalies
Not all objects that appear in the initial list should be treated as application development to retrofit. Some belong to technical or administrative categories that require a different treatment. There may be elements linked to configurations, versions, metadata, support structures or components that do not represent an application modification in the traditional sense. Including them without distinction in the estimate risks inflating the scope and confusing the work that is actually required.
This does not mean these objects are irrelevant. It means they must be separated. A technical object may not require retrofit, but may require control. A version may not be a program, but it may contain relevant processing options, data selection or operational settings. An anomaly may not immediately become development effort, but may indicate a risk to clarify before proceeding. The quality of the assessment lies precisely in the ability to distinguish development work from verification, configuration, decision or cleanup work.
Anomalies deserve a separate discussion. In a mature process, they should not be hidden. An object without a clear match, a copy with uncertain based-on, a version associated with an unclear report, an inconsistent record, an ambiguous name or missing information should not be forced into a category just to close the list. They must be highlighted. Sometimes the anomaly is resolved with a technical check. Sometimes it requires customer involvement. Sometimes it becomes a note in the estimate. In every case, a list with explicit warnings is better than a list that looks clean but is built on undocumented decisions.
Manual re-inclusions: when technical judgement prevails over the filter
A good screening process must not be blind. Filters are necessary, but they must not replace technical judgement. There are cases where an object may appear excludable according to an automatic criterion, but must be re-included because the analyst recognizes a risk, a dependency or a special condition. This is especially true in JD Edwards systems with many years of history, where local conventions, non-standard naming and project-specific solutions can make any automatic rule imperfect.
Manual re-inclusion is not a failure of the method. It is a necessary component of it. A fully automatic assessment can be fast, but it risks being fragile. A serious technical assessment combines rules, data and judgement. The point is not to eliminate human intervention; it is to make it traceable. If an object is re-included, the reason must be clear. If it is excluded despite a warning, it must be clear who made the decision and on what basis.
This balance between automation and responsibility is one of the differences between a list produced by a tool and a real upgrade assessment process. The tool can accelerate, compare, highlight, aggregate and measure. But the final value emerges when the results are interpreted within the context of the customer and the target release.
What the historical data show
To make the method concrete, it is useful to look at an anonymized historical sample of 54 assessment runs. The sample contains 358,046 objects in the initial raw list. After the qualification phase, the Suggested Object ListList of objects that remain within the suggested technical scope after exclusions, checks and classifications. contains 145,773 objects, while 212,269 objects are excluded or moved outside the operational scope of the upgrade.
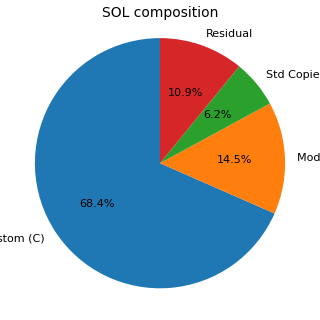
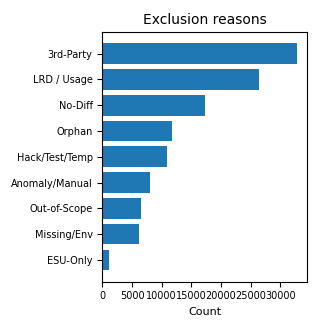
In the first chart, Residual indicates the portion of the Suggested Object List not covered by the three C, M and Y categories shown in the aggregate summary. In the second chart, exclusion reasons are shown with a bar chart because the categories are not exclusive and therefore cannot be correctly represented as shares of a single pie.
| Indicator | Aggregated value | How to read the data |
|---|---|---|
| Runs analysed | 54 | Assessments with available detail that can be linked to the summary. |
| Objects in the raw list | 358,046 | Deliberately broad initial scope. |
| Objects in the Suggested Object List | 145,773 (40.7%) | Objects remaining in the suggested technical scope. |
| Excluded objects | 212,269 (59.3%) | Objects removed from the operational scope after applying screening criteria. |
| Pure custom objects in the SOL | 99,733 | Objects classified as custom. |
| Modified standard objects in the SOL | 21,145 | Standard objects modified by the customer and kept in scope. |
| Copies of standard objects in the SOL | 8,989 (6.2% of the SOL) | Standard-copy objects, to be treated as a critical category and not as duplicates. |
| Objects excluded before classification | 212,188 | Objects that left the scope before it was necessary to determine the modification type. |
| Modified standard objects excluded as no-diff | 17,036 | Objects initially classified as modified, but later found to be aligned with the standard. |
| UBE/UBEVER in the raw list | 69,567 | Reports and batch versions present in the initial scope. |
| UBE/UBEVER in the SOL | 30,337 | Reports and batch versions kept in the suggested scope. |
| Excluded UBE/UBEVER | 39,229 (56.4% of raw UBE/UBEVER) | Reports and batch versions excluded or candidates for exclusion after qualification. |
| LRD / non-recent usage exclusions | 26,328 | Objects excluded with a reason linked to Last Run Date or lack of recent usage. |
| No-diff exclusions | 17,297 | Objects excluded because they show no relevant differences from the standard. |
| Third-party exclusions | 32,896 | Objects traceable to components outside the customer custom scope. |
| Hack, test or temporary objects | 10,852 | Objects excluded because they relate to tests, temporary workarounds or non-structural elements. |
| Orphans | 11,676 | Objects identified as no longer connected to a clear operational use. |
| ESU-only | 1,162 | Objects excluded because they are traceable to standard update logic already covered by the release path. |
| Missing / environment | 6,098 | Objects whose exclusion depends on environment conditions or missing data. |
| Out of project scope | 6,482 | Objects not relevant to the operational scope of the assessment. |
| Anomalies / manual review | 8,079 | Cases requiring attention, confirmation or technical judgement. |
| Excluded without explicit reason | 89,300 | Data quality check: excluded rows without a readable reason in the comments field. |
Methodological note. Exclusion categories are non-mutually exclusive flags: the same object may have multiple documented reasons, for example being a test object, third-party and marked with LRD. For this reason, the rows related to exclusion reasons must not be summed together. The aggregated data shows the weight of the criteria, not an exclusive breakdown.
These numbers make the value of screening visible. In the historical sample, about 59.3% of the initial objects do not reach the Suggested Object List. This should not be read as a simple “reduction”: it should be read as the result of a technical classification. The raw list captures everything that might be relevant; the suggested list preserves what deserves to be discussed, analysed or estimated. Among these objects, almost 8,989 copies of standard objects remain, confirming an essential point: copies are not treated as waste, but as a critical retrofit category.
The data on UBEs and batch versions is equally significant. From 69,567 reports or versions in the initial scope, 30,337 remain in the suggested list and 39,229 leave the operational scope. A relevant portion of these exclusions is linked to LRD or non-recent usage criteria. Here again, the number does not replace judgement: a rare report may be critical, but a report not executed for years must at least be questioned before it weighs on the estimate.
Finally, the data on no-diff objects shows why it is not enough to trust the initial classification. In the sample there are 17,036 objects initially traceable to the modified-standard category but later excluded because they show no relevant differences. This is one of the steps that prevents the estimate from being artificially inflated: an object that appears modified should not weigh as retrofit if the comparison proves that it is actually aligned with the standard.
From the Suggested Object List to the estimate
Only after the qualification phase does it make sense to estimate. The Suggested Object List is not the endpoint: it is the point where the estimate can begin seriously. At that stage, objects are no longer just names. They are classified elements: pure custom, modification to standard, copy of standard, batch report with recent usage, batch report candidate for exclusion, version with override, technical object, anomaly, component to verify, element to discuss with the customer.
The estimate must start from this classification. Pure custom, a direct modification to standard and a copy of standard do not have the same risk profile. A copy almost identical to the based-on and a strongly divergent copy do not require the same effort. A report used yesterday and a report not executed for years do not carry the same operational weight. An object with anomalies cannot be estimated as if it were completely clear. The estimate must not be a generic average applied to a list: it must be an evaluation derived from the nature of the object.
In this second phase, every object is translated into potential work. The question is no longer only “what is it?”, but “what must be done to bring it correctly onto the target release?”. The answer may include recompilation, comparison, retrofit, rebuilding from the new standard, functional verification, testing, processing option adjustment, data selection control, dependency analysis or simple confirmation of exclusion. The estimate thus becomes the result of a chain: initial data, filters, classification, decisions, effort.
Why an estimate without screening is dangerous
Estimating the raw list directly is dangerous for two opposite reasons. The first is overestimation. If standard objects, unused objects, non-application technical elements or dormant reports remain in the list, the customer receives an estimate weighed down by work that may not be necessary. This can make the project more expensive, harder to approve and less transparent.
The second reason is underestimation. If copies of standard objects are read as simple duplicates, if direct modifications to standard are treated as ordinary custom, if anomalies are ignored, the estimate may appear lighter but become fragile. The risk emerges later, when the project has already started and the more complex objects begin to require unplanned time.
Screening serves to avoid both errors. It is not a mechanism to lower the estimate. It is a mechanism to make it proportionate. It removes weight where the work is not there, but adds attention where the risk is real. This is the most important point to communicate to the customer: scope reduction is not a shortcut, it is a form of precision.
Traceability as the value of the method
An upgrade assessment does not produce only numbers. It produces decisions. Every exclusion, inclusion, re-inclusion or classification is a decision. If these decisions are not traced, the final estimate becomes difficult to defend. If they are documented, the customer can understand not only how much work is expected, but also why.
Traceability is also important for the project team. When the upgrade enters execution, the people working on the objects need to know where the classification came from. They need to understand whether an object was considered a copy, whether the based-on is certain or probable, whether the Last Run Date affected the decision, whether a report was excluded on customer confirmation, whether a warning remained open. Without this memory, the assessment risks becoming a static document. With this memory, it becomes an operational tool.
Traceability also helps manage revisions. An estimate can change. A customer may re-include a report. An object initially considered simple may prove complex. A copy may show greater divergence than expected. If the process is traced, the revision is understandable. If it is not, every change looks arbitrary.
The customer’s role in scope validation
The customer should not receive the Suggested Object List as a verdict. They should receive it as a technical scope to validate. The technical team can say that a report has not been executed for more than 18 months, but only the customer can confirm whether that report is truly abandoned. The technical team can identify a copy and measure its divergence, but functional knowledge is often needed to understand which changes are still relevant. The technical team can flag an anomaly, but the customer may know that the anomaly corresponds to an old procedure, a workaround or a critical customization.
The quality of the upgrade therefore also depends on how the scope is discussed. An assessment should not produce a list closed in isolation. It should produce a reasoned list, accompanied by criteria, notes, warnings and questions. In this way, the customer is not forced to trust a number: they can see the path that produced that number.
This is especially important in projects where economic pressure is strong. A list that is too large is frightening. A list that is too small creates risk. A defensible list enables a rational discussion: which objects are certainly in scope, which are candidates for exclusion, which require confirmation, which are technically critical and which are functionally sensitive.
From technical data to project decision
The final value of the procedure is not only technical. It is decisional. A JD Edwards upgrade is a project in which risk often comes from uncertainty: not knowing how many objects are truly involved, not knowing which copies are critical, not knowing which reports are still used, not knowing whether an estimate includes useless objects or excludes important ones. The procedure reduces this uncertainty by transforming dispersed information into visible decisions.
This does not mean eliminating every margin of doubt. In a complex system, doubt does not disappear. It is managed. Some objects will remain with notes. Some decisions will require confirmation. Some estimates will have margins. Some copies will require deeper analysis. But a declared margin is very different from a hidden one. The first can be discussed. The second explodes during the project.
In this sense, the upgrade assessment procedure is not simply a way to produce an estimate. It is a way to build trust. Trust that the scope is not arbitrary. Trust that critical objects have not been oversimplified. Trust that unused reports have been treated with criteria. Trust that copies of standard objects have been understood for what they are: often the most delicate point of the retrofit.
Conclusion: the upgrade as uncertainty reduction
A JD Edwards upgrade is not only a technical move from one release to another. It is an exercise in reducing uncertainty. At the beginning there is a mass of potentially relevant objects. At the end there must be an explainable scope, a suggested list, a proportionate estimate and a set of traceable decisions. The most important work happens precisely in the middle, in the phase where the raw list is transformed into knowledge.
Screening is the heart of this process, but only if it is understood correctly. It is not used to delete rows. It is used to distinguish. Standard objects must not be confused with custom. Reports not used for more than 18 months can be candidates for exclusion, but not deleted without judgement. Anomalies must be highlighted, not hidden. Manual re-inclusions are part of the method, not embarrassing exceptions. And copies of standard objects are not duplicates: they are often the most delicate objects, because they force the comparison between the customer’s evolution and the evolution of the Oracle standard.
Only when this work has been done does the estimate become credible. Not because it is perfect, but because it is explainable. And in a complex upgrade, an explainable estimate is worth much more than an apparently precise estimate without technical memory.
