Lorsqu'une grille personnalisée dans une application comme P554210 met plus de dix secondes à charger 500 enregistrements, les équipes techniques blâment immédiatement les index de la base de donnéesStructure de données améliorant la vitesse de récupération des informations dans une table. ou la taille du heap JVMMémoire vive allouée à la machine virtuelle Java pour stocker les objets et données d'application. de WebLogicServeur d'applications Java d'Oracle qui héberge les composants web de JD Edwards.. Dans la grande majorité des audits de performance menés sur EnterpriseOne 9.2, l'infrastructure est parfaitement saine ; le goulot d'étranglement réside dans les Event Rules (ER)Langage de programmation spécifique à JD Edwards pour créer la logique métier des applications. synchrones s'exécutant sur le serveur JASServeur Java (Java Application Server) qui gère l'interface web et les interactions utilisateur. pour chaque ligne. Obtenir des temps de réponse inférieurs à la seconde nécessite d'arrêter de pointer du doigt l'infrastructure pour se concentrer sur l'optimisation des performances de la grille APPL JD Edwards pour les grands jeux de données au sein même du moteur d'exécution JDE.
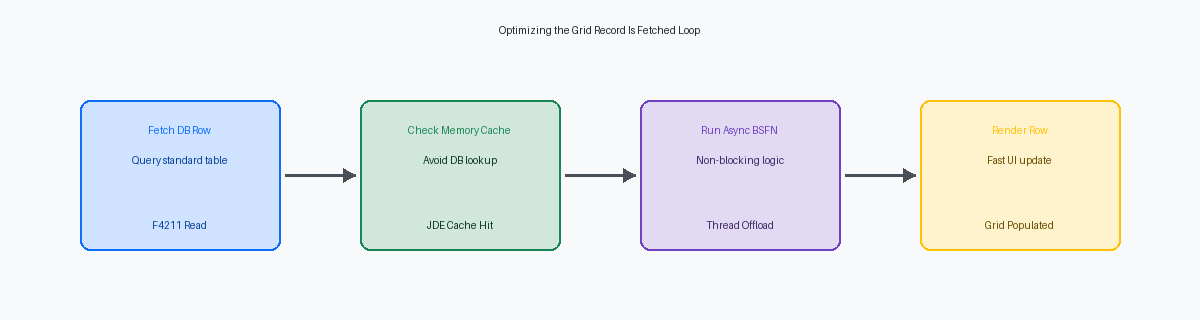
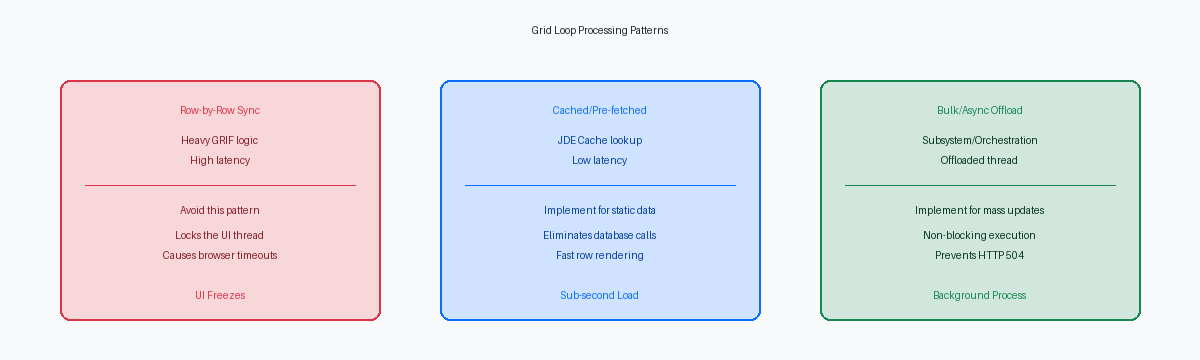
Une optimisation efficace de la grille repose sur l'élimination de la surcharge liée aux allers-retours itératifs vers la base de données et à l'exécution synchrone des Business Function (BSFN)Composant logiciel encapsulant une logique métier spécifique, exécutable sur le serveur.. En déplaçant la logique de validation lourde de l'événement Grid Record Is FetchedÉvénement déclenché lors de la récupération de chaque ligne de données vers l'écran. vers des E/S de tableOpérations de lecture ou d'écriture (Entrées/Sorties) effectuées sur les tables de données. asynchrones ou un traitement en arrière-plan, les développeurs peuvent réduire les appels à la base de données de 70 % à 80 %. Si votre équipe de développement écrit encore des boucles ER procédurales qui récupèrent la même table de constantes pour chaque ligne de la grille, elle dégrade gravement l'expérience utilisateur.
Le piège de la boucle de grille et l'exécution ligne par ligne
Les audits techniques des APPL personnalisées révèlent fréquemment des centaines de lignes d'Event Rules placées directement dans l'événement Grid Record Is Fetched (GRIF). Cet événement se déclenche de manière synchrone pour chaque ligne de base de données récupérée avant qu'elle ne soit affichée à l'écran. Si un utilisateur interroge 500 lignes de commande client dans une version personnalisée de P4210, le moteur JAS est contraint d'exécuter ce bloc entier d'ER 500 fois consécutives avant de présenter les données au navigateur.
La pénalité de performance s'aggrave lorsque les développeurs placent des Master Business FunctionsFonctions complexes gérant des processus transactionnels complets, comme la création de commandes. lourdes ou des BSFN C personnalisées comme GetAuditInfo (B9800100) à l'intérieur de cette boucle. Ce qui devrait être une simple récupération SQL de deux secondes se transforme rapidement en un gel du navigateur durant près d'une minute. Cette latence est causée par les allers-retours réseau constants entre le serveur HTML et le serveur logique Enterprise, car chaque ligne individuelle nécessite sa propre sérialisationConversion de données complexes en un format linéaire pour le transfert entre serveurs. pour exécuter la logique métier.
Pour résoudre ce goulot d'étranglement, déplacez toute la logique de validation non essentielle hors du GRIF. Le déplacement du formatage visuel vers l'événement Write Grid Line-Before garantit que JDE ne traite que les 10 à 20 lignes réellement visibles dans la page active de la grille. Pour les calculs lourds, les exécuter de manière asynchrone ou les différer jusqu'à ce qu'une ligne soit sélectionnée peut réduire les temps de chargement initiaux de 75 % à 80 %.
Si vous devez impérativement calculer des valeurs lors de la récupération, configurez les propriétés de la grille pour un traitement page par page plutôt que de charger l'ensemble des enregistrements. Ce changement limite l'exécution synchrone du GRIF à la taille de la page active de la grille, empêchant le client web de saturer sur des tables contenant des dizaines de milliers d'enregistrements.

Optimisation de la sélection de données avec des lectures sélectives
Permettre à un utilisateur d'exécuter une recherche non filtrée sur un formulaire Find/Browse portant sur une table F4211 ou F0911 de plusieurs millions de lignes introduit des risques opérationnels graves. La requête SQL ouverte qui en résulte force le serveur JAS à allouer de la mémoire heap pour des centaines de milliers de lignes de grille, déclenchant une erreur Java OutOfMemoryErrorErreur critique indiquant que la mémoire vive allouée à l'application Java est totalement épuisée. et faisant planter la session HTML active. Lors d'un récent audit technique, nous avons résolu un problème où quelques requêtes ouvertes simultanées sur F4211 épuisaient la mémoire JVM et faisaient tomber une instance HTML entière, perturbant des dizaines d'utilisateurs actifs.
Pour éviter les scans complets sur des tables dépassant plusieurs millions de lignes, les développeurs doivent imposer au moins un champ de filtre indexé sur les formulaires Find/Browse. Définir la propriété "Filter Criteria" sur "Equal" pour une colonne indexée comme SDKCOO ou SDDOCO force l'optimiseur de base de données à exécuter une recherche par index plutôt qu'un scan de table coûteux. Si l'utilisateur laisse ces champs obligatoires vides, l'application doit bloquer programmatiquement la requête dans l'événement "Button Clicked" du bouton Find avant d'interroger la base de données.
Lorsque les filtres statiques sont insuffisants, l'utilisation de la fonction système Set Selection dynamiquement dans la séquence d'événements "Clear Select" et "Set Selection" restreint la clause SQL WHERE avant que la grille n'exécute sa récupération principale. Crucialement, les propriétés de la grille doivent être configurées pour un traitement "Page-at-a-Time" plutôt que de charger tous les enregistrements en mémoire à la fois. Cela limite la récupération initiale de la base de données à la taille de la page de la grille — généralement 10 à 50 lignes — évitant l'épuisement de la mémoire tout en maintenant des temps de réponse inférieurs à la seconde.
Le coût des appels BSFN et base de données répétitifs
L'exécution d'un seul appel de Business Function (BSFN) qui prend 10 millisecondes (ce qui semble négligeable) ajoute dix secondes de latence pure lorsqu'elle est exécutée séquentiellement sur une grille de 1 000 lignes. Ce cumul de latence se produit fréquemment dans l'événement Grid Record is Fetched, où les développeurs placent couramment des BSFN standards ou personnalisées pour récupérer des descriptions auxiliaires ou valider des codes par ligne. La dégradation des performances s'accentue lorsque ces BSFN en boucle ouvrent et ferment répétitivement des handles de table, comme l'appel à 'F0005 Get UDC' pour récupérer les descriptions de codes UDCUser Defined Codes, des listes de valeurs prédéfinies utilisées pour normaliser les données dans JD Edwards. pour chaque ligne.
Pour éliminer des milliers d'opérations de sélection redondantes, les développeurs devraient mettre en cache les données de validation statiques ou semi-statiques en mémoire à l'aide des API JDE Cache comme jdeCacheInitFonction API permettant d'initialiser un espace de stockage temporaire en mémoire vive pour un accès ultra-rapide aux données. lors de l'événement Dialog is Initialized avant le chargement de la grille. Au lieu d'interroger la base de données ou d'exécuter des lectures de table F0005 des milliers de fois, une BSFN C personnalisée peut charger une seule fois les valeurs UDC ou les enregistrements de correspondance requis dans un cache résidant en mémoire. Les recherches en mémoire de l'ordre de la milliseconde remplacent alors les E/S disque et les sauts réseau, réduisant le temps de traitement par ligne de 12 millisecondes à moins d'une milliseconde.
Lorsque les calculs complexes sont inévitables, passez d'une exécution ligne par ligne à un traitement par lots (bulk processing). Transmettez des tableaux pré-récupérés ou des structures de données contenant tous les champs clés à une Business Function C personnalisée en un seul appel mappé en mémoire, plutôt que d'appeler la BSFN une fois par ligne de grille. Ce changement structurel permet à la BSFN d'effectuer une seule opération d'ouverture de base de données, d'exécuter des récupérations groupées, de traiter la logique en RAM et de renvoyer le jeu de données à la couche applicative. L'implémentation de ce modèle sur un écran de disponibilité des stocks à gros volume peut réduire les temps de transaction de 80 % à 85 %, faisant passer le temps de chargement de l'écran de quinze secondes à moins de trois secondes.
Manipulation du buffer de grille et empreinte mémoire
Nous analysons fréquemment des environnements de production où la JVM du serveur HTML plante avec des exceptions OutOfMemoryError lors des pics d'expédition ou de facturation. Le coupable est généralement un Power Form personnalisé ou un P42101 lourdement modifié contenant des grilles de plus de 100 colonnes. Chaque ligne chargée dans ces grilles larges instancie un ensemble massif de variables de buffer de grilleZone de mémoire temporaire stockant les données d'une ligne de la grille avant son affichage ou traitement. dans le heap mémoire JAS. Cela multiplie l'empreinte mémoire lorsque cinquante utilisateurs ou plus interrogent simultanément de grands jeux de données.
Les développeurs aggravent cette pression mémoire en utilisant des fonctions système comme 'Copy Grid Row To Grid Buffer' à l'intérieur des événements Grid Record Is Fetched ou Write Grid Line-Before. Cette fonction système ne se contente pas de référencer la mémoire existante ; elle duplique l'intégralité de la structure de données de 100 colonnes dans le heap JAS. Lorsqu'elle est exécutée séquentiellement sur une récupération de 1 000 lignes, cette allocation redondante déclenche des pauses agressives du garbage collectorSystème automatique de nettoyage de la mémoire vive inutilisée par le serveur. JVM qui gèlent le client web.
Une erreur courante consiste à masquer les colonnes inutilisées via les Event Rules en utilisant la fonction système Set Grid Column Attribute. Masquer visuellement une colonne n'empêche en rien le serveur JAS de récupérer, traiter et sérialiser ces données. Supprimer entièrement ces colonnes mortes de la mise en page de la grille, plutôt que de les masquer via ER, réduit la taille de la charge utile de sérialisation de plus de moitié et stabilise le profil mémoire du serveur web. Par exemple, réduire une grille de 120 colonnes aux 20 champs réellement requis diminue la surcharge mémoire par ligne d'environ 80 %.
Gestion des grands jeux de données avec le traitement asynchrone
Une session web qui se fige lors de l'enregistrement d'une grille de 500 lignes est généralement causée par l'exécution synchrone d'une logique de validation lourde. Lors du placement d'une BSFN de validation personnalisée dans les événements de grille "Row Exit & Changed - Asynchronous" ou "Row Is Selected", les développeurs doivent explicitement marquer cette BSFN comme asynchrone dans les propriétés des Event Rules. Cette option de configuration indique au serveur HTML de rendre immédiatement le contrôle à la couche de présentation, empêchant l'interface utilisateur de se bloquer pendant que le serveur Enterprise traite la logique métier dans un thread parallèle.
Pour traiter des calculs lourds sur une grande grille sans dégrader l'expérience utilisateur, déportez l'exécution vers l'événement "Post Button Clicked" d'un bouton caché. Chez un client de distribution, pour une APPL d'allocation d'inventaire, nous avons remplacé les calculs de grille en ligne par un système où le bouton "OK" écrit les lignes modifiées dans un cache mémoire, puis clique programmatiquement sur un bouton "Process" caché. L'exécution de la logique de calcul en masse dans l'événement "Post Button Clicked" de ce contrôle caché garantit que le thread principal de la grille reste réactif, évitant les pièges du traitement synchrone qui déclenchent la latence du navigateur.
Lorsqu'un utilisateur tente de mettre à jour massivement plus de 200 lignes de grille simultanément, traiter ces changements dans le thread interactif de l'APPL est un anti-pattern architectural. Une approche plus efficace consiste à écrire les données de grille modifiées dans une table de staging personnalisée et à déclencher immédiatement un UBEProgramme de traitement par lots ou rapport s'exécutant en arrière-plan sur le serveur. de sous-système (comme un driver de série R55 personnalisé) ou à appeler une OrchestrationFlux de travail automatisé combinant plusieurs étapes métier sans intervention humaine. basée sur AISServeur permettant de connecter JD Edwards à des applications mobiles ou externes via des API. pour traiter le lot en arrière-plan. Ce changement maintient la propreté du thread d'exécution interactif et élimine les erreurs de timeout HTTP 504 qui surviennent généralement lorsque WebLogic ou un équilibreur de charge F5 interrompt une connexion après son seuil par défaut de 120 secondes.
Outils de diagnostic pour identifier les goulots d'étranglement de la grille
Les administrateurs de base de données présentent fréquemment un plan d'exécution SQL inférieur à la milliseconde pour prouver la santé de la base de données, pourtant une grille standard comme P42101 ou P4312 peut encore mettre plus de dix secondes à afficher 200 lignes. Ce décalage se produit parce que les métriques au niveau de la base de données ignorent la latence de la couche applicative introduite par l'exécution des Event Rules (ER)Langage de programmation propriétaire de JD Edwards utilisé pour définir la logique métier des applications.. Lorsque l'ER s'exécute sur des événements comme Grid Record Is Fetched, le temps passé à traiter les affectations de variables et les E/S de table se produit entièrement en dehors de la vue du moteur de base de données.
Isolez cette latence en corrélant le fichier jas.logFichier journal enregistrant les activités et erreurs du serveur web JD Edwards. avec une analyse ciblée de la pile d'appels dans le jdedebug.logFichier de diagnostic détaillé traçant chaque étape de l'exécution du code serveur. sur le serveur Enterprise. Le jas.log capture l'horodatage précis du moment où le serveur HTML demande les données de la grille, tandis que le jdedebug.log suit le coût exact en millisecondes de chaque exécution de BSFN déclenchée par l'ER. L'analyse de ces journaux révèle la surcharge cumulative de centaines de récupérations F4101 séquentielles se produisant par ligne de grille.
Utilisez le Performance Monitor au sein de Server ManagerConsole d'administration centralisée pour gérer et surveiller les environnements JD Edwards. pour suivre les allers-retours entre le JAS et le serveur Enterprise. Cet outil expose le volume de sauts réseau générés par des appels BSFN excessifs depuis le niveau présentation. Si un seul chargement de grille de 100 lignes entraîne des centaines d'allers-retours, vous avez un indicateur clair que la logique doit être consolidée dans une Business Function C plutôt que dans des lignes ER individuelles.
Enfin, utilisez l'Event Rules Debugger pour parcourir les boucles de la grille et observer l'état des variables en temps réel. Cela vous permet de détecter les erreurs de logique conditionnelle qui provoquent des boucles infinies ou des récupérations redondantes des mêmes enregistrements de données de base. Ce traçage direct est le moyen le plus efficace de vérifier pourquoi une grille exécute des dizaines de lectures de base de données inutiles pour une seule ligne.
L'optimisation des performances de la grille dans un environnement 9.2.x n'est qu'une couche de la pile ; les goulots d'étranglement résident souvent dans une gestion inefficace du cache BSFN ou des plans d'exécution SQL non optimisés. Si vos applications personnalisées sont lentes, isoler ces inefficacités au niveau applicatif est la première étape pour restaurer la stabilité du système et la productivité des utilisateurs.
Pour obtenir de l'aide dans l'audit de vos applications EnterpriseOne personnalisées ou l'optimisation des performances de votre serveur JAS, contactez notre équipe de conseil ERP pour planifier une revue technique.
