
Lorsqu'une application Find/Browse personnalisée interrogeant la F4211Table JD Edwards contenant les détails des commandes de vente. ou la F0911Table JD Edwards contenant les écritures comptables du grand livre. prend plus de quelques secondes pour retourner les lignes de la grille, les développeurs blâment immédiatement l'indexation de la base de données ou la latence du réseau. Dans la grande majorité des audits de performance que je réalise, le goulot d'étranglement est auto-infligé au sein de JDE. La corrélation entre la performance des formulaires de recherche personnalisés JDE APPL et la conception de la Business ViewObjet JDE définissant les tables et colonnes de données utilisées par une application. est directe : joindre des dizaines de colonnes inutiles dans une BSVW personnalisée force la base de données à effectuer des table scansOpération lente où la base de données lit chaque ligne d'une table pour trouver les résultats. coûteux au lieu de index seeksRecherche efficace utilisant un index pour localiser directement les données souhaitées. propres.
Pour corriger un écran de recherche lent, ne demandez pas simplement à votre DBAAdministrateur de base de données, responsable de la gestion et de l'optimisation des serveurs de données. de créer un autre index composite personnalisé. Refactorisez plutôt l'application pour aligner les mappages Grid Line-to-Business View avec les clés primaires existantes, et auditez l'événement Grid Record is FetchedÉvénement JDE qui s'exécute à chaque fois qu'une ligne de données est chargée dans la grille. pour détecter les boucles d'E/S de table F4101 ou F0101 cachées. Restreindre votre BSVW personnalisée aux seuls champs essentiels (généralement moins d'une douzaine) requis pour les critères de recherche et l'affichage initial de la grille peut réduire les temps d'exécution SQL sur une table de plusieurs dizaines de millions de lignes à moins d'un quart de seconde.
Le coût des Business Views surchargées sur les grandes tables
Voyons ce qui se passe dans la base de données lorsqu'un développeur crée un formulaire Find/Browse personnalisé en utilisant une Business View standard comme V4211A, ou une vue personnalisée qui extrait tous les champs de la table F4211 Sales Order Detail. Le middleware de base de données JDE (JDBCouche logicielle JDE gérant les communications entre l'application et la base de données.) génère une instruction SELECT contenant chaque colonne définie dans cette Business View, que ces champs soient placés sur le formulaire ou dans la grille. Pour la F4211, qui contient plus d'une centaine de colonnes, ce modèle de conception paresseux force la base de données à extraire et à transmettre des centaines d'octets de données inutiles par ligne, gonflant la charge utile du réseau et gaspillant la mémoire du pool de mémoire tampon de la base de données pour des données qui ne seront jamais affichées à l'utilisateur.
Pour éviter cette surcharge sur les formulaires de recherche à gros volume, les développeurs doivent construire une Business View dédiée et allégée contenant uniquement l'essentiel. Cela signifie sélectionner uniquement les clés primaires (SDKCOO, SDDOCO, SDDCTO, SDLNID), les champs spécifiques utilisés comme filtres de recherche dans l'en-tête, et la poignée de colonnes réellement rendues dans la grille. Réduire une Business View de plus de cent colonnes à une ou deux douzaines peut réduire considérablement les temps d'exécution SQL et la consommation de mémoire du serveur d'applications, souvent jusqu'à deux tiers, lors de sessions utilisateur intensives.
Un autre tueur de performance courant est la jointure de tables à l'intérieur de la Business View pour afficher des champs de description, comme la jointure de la F4211 à la F4101 sur le numéro d'article court (SDITM). Si ces clés de jointure ne sont pas correctement alignées avec les index de base de données existants, l'optimiseur de la base de données contournera entièrement l'index primaire de la F4211. Au lieu d'un index range scanParcours d'une partie d'un index pour récupérer une plage de valeurs spécifiques. rapide, la base de données exécute une boucle imbriquée (nested loop) ou une jointure de hachage coûteuse qui déclenche un balayage complet de la table sur des millions de lignes de commandes de vente, transformant une recherche de moins d'une seconde en un gel du système de plusieurs minutes.
Comment le mappage des critères de recherche dicte la sélection de l'index
Lorsqu'un utilisateur clique sur "Find" dans un formulaire Find/Browse, le serveur HTML EnterpriseOne traduit les champs Form Control (FC) mappés comme champs de filtre en une clause SQL WHERE dynamique. Si votre application personnalisée interroge une table à gros volume comme la F4211, qui dépasse fréquemment plusieurs millions de lignes, l'optimiseur de la base de données s'appuie sur la correspondance de ces champs de filtre avec les structures d'index. Mapper un champ de filtre à une colonne non indexée force la base de données à évaluer chaque ligne, transformant une requête de quelques millisecondes en un drainage du système de plusieurs secondes.
Les recherches par caractères génériques (wildcards) non restreintes utilisant le signe de pourcentage sur des colonnes dépourvues d'indexation appropriée entraînent une dégradation sévère des performances. Lorsqu'un utilisateur saisit une valeur partielle dans un champ de description non indexé, le moteur de base de données abandonne les index range scans et recourt à un balayage complet de la table. Pour éviter cela, les développeurs doivent configurer les propriétés du formulaire pour restreindre l'utilisation des caractères génériques sur les champs de recherche à gros volume ou imposer une saisie obligatoire sur les champs indexés.
Les développeurs doivent faire correspondre les contrôles des critères de recherche directement aux colonnes de tête des index primaires ou secondaires de la table. Par exemple, si vous avez un index secondaire personnalisé sur la table F4211 défini avec Business Unit (MCU), Order Type (DCTO) et Line Number (LNID), les champs FC du formulaire de recherche doivent être présentés dans cet ordre hiérarchique exact. L'omission de la colonne de tête MCU et le filtrage uniquement par DCTO rendent l'index secondaire inutile, car l'optimiseur ne peut pas effectuer de recherche d'index sans la colonne de clé la plus à gauche.
La configuration de l'opérateur de comparaison dans Form Design Aid est tout aussi critique. Sélectionner un opérateur de comparaison "Like" au lieu de "Equal To" sur des champs numériques, tels que le Short Item Number (ITM), empêche l'optimiseur de la base de données d'exécuter des recherches d'index précises. La base de données est forcée de traiter le champ numérique comme une chaîne de caractères pour évaluer le modèle, ce qui peut augmenter l'utilisation du processeur sur le serveur de base de données de près de moitié pendant les heures de pointe.
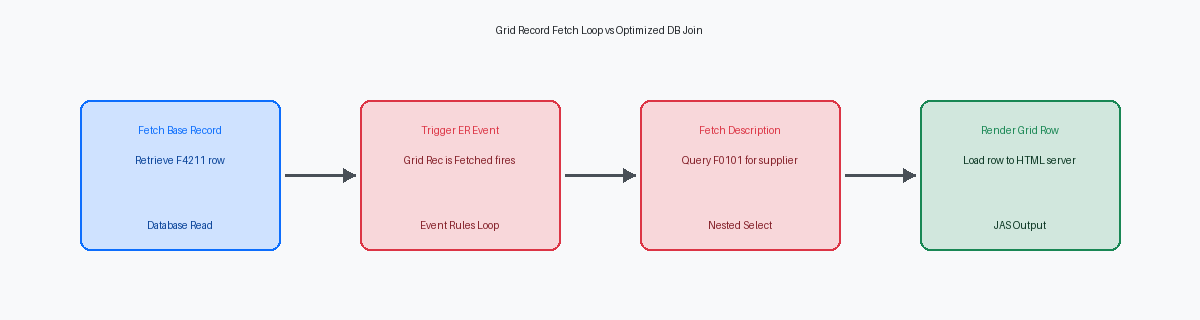
Le piège du Grid Rec is Fetched et les boucles d'exécution ER
Placer des extractions de base de données ou des fonctions métier C complexes à l'intérieur de l'événement Grid Record is Fetched est l'erreur architecturale la plus courante que je vois dans les applications Find/Browse personnalisées. Les développeurs utilisent souvent cet événement pour récupérer des données supplémentaires, comme l'extraction d'un nom alpha à partir de la table Address Book Master (F0101) pour chaque ligne. Si une requête utilisateur retourne plusieurs centaines d'enregistrements de grille, une seule fonction métier d'extraction F0101 à l'intérieur de cet événement s'exécute des centaines de fois. Ce qui ressemble à un appel de base de données négligeable au niveau de la milliseconde pendant le développement local s'aggrave en un retard cumulé de plusieurs secondes en production lorsqu'il est multiplié par ces centaines de lignes.
Pour éliminer cette boucle d'exécution, vous devez déplacer la charge de récupération des données vers le moteur de base de données ou la mémoire. Au lieu d'exécuter des appels JDB_Fetch ou BSFNBusiness Function, un programme C ou Java encapsulant une logique métier réutilisable dans JDE. en série par ligne, modifiez la Business View sous-jacente pour joindre directement les tables de description, comme lier la F4211 à la F4101 pour les descriptions d'articles. Si une jointure de table directe est impossible en raison d'une logique métier complexe, remplacez les accès à la base de données ligne par ligne par un modèle de cache en mémoire. L'utilisation des fonctions de l'API de cache JDE telles que JDEDB_CreateCache et JDB_FindKey dans vos Event RulesLangage de programmation visuel utilisé dans JD Edwards pour définir la logique applicative. vous permet de récupérer les données de référence une seule fois et d'effectuer des recherches en mémoire à haute vitesse.
Pour les formulaires de recherche à gros volume traitant des milliers de lignes, la stratégie la plus efficace consiste à désactiver entièrement l'événement Grid Record is Fetched. Vous pouvez pré-charger des données de base statiques, comme les conditions de paiement ou les centres de coûts, dans un cache d'exécution personnalisé lors de l'événement Post Dialog is Initialized. En interrogeant ces tables statiques une seule fois au démarrage du formulaire, vous pouvez remplir les colonnes de la grille à l'aide de recherches mémoire rapides plutôt que de déclencher des instructions SQL répétitives. La mise en œuvre de ce changement sur un formulaire de recherche d'ordres de travail très utilisé réduit généralement les temps de chargement de l'écran de plusieurs secondes à des fractions de seconde.
Configuration du chargement de la grille : Page-at-a-Time vs. Load-All
Les grilles JDE standard fonctionnent en mode Page-at-a-Time, n'extrayant que 10 à 50 enregistrements pour satisfaire aux exigences d'affichage initiales. Ce comportement par défaut minimise l'empreinte mémoire sur le serveur HTML et maintient le temps d'exécution SQL initial sous un quart de seconde. Des problèmes surviennent lorsque les développeurs activent la propriété Load All Grid Records pour prendre en charge le tri côté client ou les exigences d'exportation sans tenir compte du volume de la table sous-jacente. Dans un environnement de production où la F4211 contient des dizaines de millions de lignes, une configuration Load All sans filtres obligatoires est un risque pour la stabilité du middleware.
Lorsqu'un utilisateur exécute une recherche sans restriction sur une grille Load All, le serveur JASJava Application Server, le composant qui gère l'interface web de JD Edwards. tente de construire l'intégralité de l'objet grille en mémoire avant de rendre la réponse. Nous constatons systématiquement un épuisement de la heap JVMMémoire allouée à la machine virtuelle Java pour exécuter les applications. du JAS à environ 10 000 ou 15 000 enregistrements, selon la largeur de la Business View et le nombre de colonnes cachées. Cette pression sur la mémoire déclenche des cycles de Garbage Collection agressifs, faisant grimper l'utilisation du processeur sur le serveur Web et entraînant finalement un timeout 504 Gateway ou une Web Client Exception pour l'utilisateur final.
Les développeurs doivent atténuer ce risque en utilisant la fonction système Set Max Rows Spoken dans les événements Dialog is Initialized ou Find Button Clicked. Limiter le retour à 500 ou 1 000 enregistrements fournit suffisamment de données pour une utilisation fonctionnelle tout en garantissant que la heap du JAS reste stable. Si la requête dépasse cette limite, le système arrête l'extraction, empêchant la charge utile XML de gonfler à une taille que le navigateur ou la heap Java ne peuvent pas gérer.
La logique de validation dans l'événement Button Clicked doit explicitement bloquer les recherches où les champs d'index critiques comme DCTO, KCO ou AN8 sont laissés nuls. En vérifiant l'état de ces champs de filtre et en utilisant la fonction Set Control Error, vous forcez les utilisateurs à fournir des critères sélectifs que la base de données peut réellement optimiser. Ce garde-fou architectural est plus efficace que n'importe quel gouverneur de requête au niveau de la base de données, car il arrête le drainage des ressources au niveau de la couche applicative, réduisant la fréquence des erreurs JAS "Out of Memory" de 80 % à 90 % dans les environnements de distribution à gros volume.

Analyse de l'exécution SQL via les journaux CallObject et JAS
Un formulaire de recherche qui reste bloqué pendant dix secondes ou plus est rarement une erreur de logique applicative ; il s'agit presque toujours d'une instruction SQL non optimisée frappant une table de plusieurs millions de lignes comme la F4211 ou la F0911. Vous ne pouvez pas diagnostiquer ces goulots d'étranglement à partir du seul Form Design Aid (FDA) car le middleware JDB fait abstraction de la couche physique de la base de données. Vous devez capturer le SQL brut en activant la journalisation CallObject (jdedebug.log) sur le client lourd ou via Server Manager pour une session Web spécifique afin de voir exactement ce qu'on demande à la base de données.
Dans le jdedebug.log, recherchez la chaîne "SELECT ... FROM" suivie de la ligne "OCI Execute" ou "SQL Execute". Cela fournit le temps d'exécution de l'instruction SQL du jdedebug.log en microsecondes, vous permettant d'identifier précisément quelle extraction bloque l'interface utilisateur. Simultanément, les journaux de débogage JAS vous permettent de corréler l'action de l'utilisateur JDE à un ID de thread spécifique, garantissant que vous ne poursuivez pas une instruction fantôme provenant d'un UBEUniversal Batch Engine, programme JDE traitant des données en lot ou générant des rapports. en arrière-plan ou d'une session utilisateur différente.
Copiez l'instruction SQL littérale du journal — y compris les marqueurs de paramètres — et exécutez un EXPLAIN PLANOutil d'analyse montrant comment la base de données prévoit d'exécuter une requête SQL. dans votre studio de gestion de base de données. C'est une idée fausse courante que JDE utilise toujours l'index défini dans la Business View (BSVW). Si l'utilisateur filtre sur une colonne non indexée dans un en-tête de grille, l'optimiseur de la base de données peut par défaut effectuer un balayage complet de la table, indépendamment de la façon dont vous aviez prévu que la recherche se comporte pendant la phase de développement.
La dégradation des performances provient également d'instructions SQL à haute fréquence et de courte durée qui indiquent des boucles imbriquées. Si le journal montre des centaines d'instructions SELECT identiques frappant la F0101 dans une brève fenêtre de quelques secondes, vous avez probablement une logique dans l'événement Grid Rec is Fetched effectuant une extraction manuelle pour les données de base. Ce traitement ligne par ligne ajoute une surcharge massive à la communication entre le serveur JAS et le serveur Enterprise. Déplacer ces extractions dans la jointure BSVW initiale ou utiliser une BSFN C avec un handle mis en cache peut réduire ces centaines de trajets vers la base de données à une seule exécution.
L'optimisation d'une Business View APPL personnalisée implique plus que la simple sélection de colonnes ; elle nécessite une plongée profonde dans le plan d'exécution SQL sous-jacent et la sélection d'index. Lorsque votre environnement EnterpriseOne 9.2 est réglé pour aligner la conception applicative avec les réalités de la base de données, vous éliminez la latence que les utilisateurs finaux confondent avec une instabilité du système.
