
De nombreuses fonctions métier (BSFNRoutine logicielle réutilisable dans JD Edwards pour exécuter des tâches métier spécifiques.) en C personnalisées dans les installations JDESystème de gestion intégré (ERP) d'Oracle utilisé pour piloter les activités de l'entreprise. héritées sont des monolithes de plusieurs milliers de lignes impossibles à maintenir, où la logique de validation, les recherches en cache mémoire et les entrées/sorties (I/O) directes sur les tables sont désespérément entremêlées. Lorsque le volume de transactions augmente — comme lors d'un lot de dizaines de milliers de lignes de commandes de vente EDIÉchange de données informatisé permettant l'envoi automatique de documents entre partenaires commerciaux. frappant simultanément la pile d'appels — ce manque d'architecture provoque de graves verrouillages de base de données, des fuites de mémoire et des défaillances du noyau Enterprise (kernelComposant central du serveur gérant les processus et la mémoire système.).
Ce guide fournit un exemple pratique de développement de BSFN JDE pour valider la logique métier en C, démontrant comment isoler les routines de validation volatiles de l'état persistant de la base de données. En découplant proprement les recherches en cache mémoire à l'aide des APIInterface permettant à différents logiciels de communiquer et d'échanger des informations. natives jdeCacheSystème de stockage temporaire en mémoire vive pour accélérer l'accès aux données. des mises à jour de tables physiques, vous pouvez réduire considérablement les allers-retours avec la base de données, souvent de plus des trois quarts, et éliminer les annulations de transactions (rollbacks) sous de lourdes charges de travail.
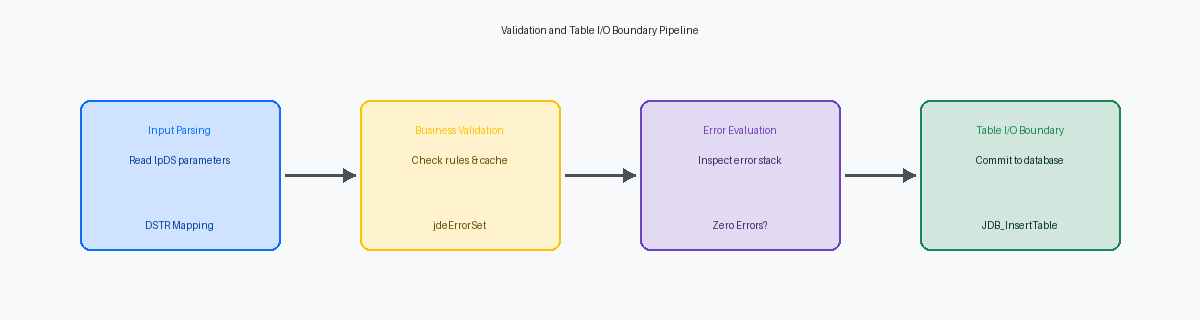
Conception de la structure de données (DSTR) BSFN pour la validation
En plus de deux décennies d'examen de fonctions métier en C personnalisées, les architectes d'entreprise constatent fréquemment que les développeurs déversent des dizaines de champs non organisés de la table F4101 Item Master directement dans une seule structure de données (DSTRStructure définissant les paramètres d'entrée et de sortie d'une fonction logicielle.). Ce modèle de conception garantit des maux de tête de maintenance et des goulots d'étranglement de performance lors du traitement par lots à haut volume dans des UBEProgramme de traitement par lots exécuté en arrière-plan pour les tâches de masse. comme le R41110A. Une DSTR de validation bien conçue doit séparer proprement les indicateurs de contrôle d'entrée, les valeurs métier comme LITM ou MCU, et les champs de statut de sortie pour maintenir une empreinte mémoire prévisible.
Pour éviter la corruption de la mémoire et la troncature silencieuse des données dans le code C, vous devez imposer l'utilisation d'éléments standard du Data DictionaryRépertoire central définissant les caractéristiques de tous les champs de données du système. tels que EV01 pour les indicateurs booléens et ERRC pour les indicateurs d'erreur. Passer un champ de caractère personnalisé au lieu de EV01 peut entraîner des erreurs d'alignement lorsque le moteur JDE mappe le tampon du middlewareLogiciel servant de pont entre différentes applications pour faciliter leurs échanges. au pointeur lpDS. Restreindre les indicateurs de contrôle à EV01 et ERRC garantit que le compilateur aligne correctement les membres de la structure sur des limites de 4 octets.
La conception de la DSTR avec un paramètre de code d'action dédié (utilisant l'élément ACTION, où '1' représente Valider et '2' représente Écrire) permet à une seule BSFN de gérer la validation interactive multi-passes dans des applications comme P4101. Lors des événements initiaux de sortie de contrôle et de modification, l'APPLApplication interactive utilisée par les utilisateurs finaux via une interface graphique. passe '1' pour exécuter une validation à faible surcharge sans valider d'enregistrements en base de données. Une fois que l'utilisateur clique sur OK, la même BSFN est invoquée avec le code d'action '2' pour exécuter l'insertion finale au sein de la transaction.
Chaque paramètre de cette DSTR doit correspondre directement au typedef struct généré par l'Object Management Workbench (OMW)Outil de développement de JD Edwards pour gérer le cycle de vie des objets. dans le fichier d'en-tête de la BSFN. Lors de la modification d'une DSTR, régénérez immédiatement cet en-tête pour éviter les décalages de pointeurs lorsque le compilateur C génère la DLLFichier contenant des fonctions partagées utilisées par plusieurs programmes en même temps.. Documenter la direction de chaque membre de la structure (IN, OUT, BOTH) à l'intérieur de cet en-tête garantit que les développeurs n'écrasent pas par inadvertance des valeurs d'entrée en lecture seule.
Implémentation du modèle de validation C et des API d'erreur
Dans les fonctions métier personnalisées comme B5501001, les développeurs échouent fréquemment à lier les échecs de validation directement aux contrôles de formulaire interactifs, laissant les utilisateurs devant des écrans vides sans indication de ce qui a échoué. Le framework standard de gestion des erreurs d'EnterpriseOne résout ce problème en s'appuyant sur l'APIInterface permettant à différents logiciels de communiquer et d'échanger des informations. jdeErrorSet pour associer des codes d'erreur spécifiques du Data Dictionary aux contrôles d'exécution. Lors de l'écriture du code C, vous devez passer l'élément DD exact, tel que 0002 (Enregistrement invalide) ou 4115 (Statut de lot invalide), garantissant que le client HTML met en évidence la colonne de la grille ou le champ de formulaire incriminé en rouge.
Pour que ce mappage fonctionne, le passage de la structure lpBhvrCom — le pointeur vers les spécifications de comportement commun — est obligatoire. Sans ce pointeur, le moteur d'exécution ne peut pas faire remonter l'erreur jusqu'au conteneur APPL interactif ni enregistrer l'échec au sein d'un processus par lots UBE. Lors d'une récente mise à niveau de la version 9.1 à 9.2 pour un distributeur mondial, nous avons résolu des dizaines de fonctions C personnalisées où les développeurs avaient passé NULL au lieu de lpBhvrCom, ce qui supprimait silencieusement des erreurs critiques d'allocation d'inventaire lors de la saisie des commandes de vente.
Un modèle de validation propre à l'intérieur de B5501001 utilise une vérification logique séquentielle qui interrompt tout traitement ultérieur dès qu'une erreur de sévérité critique est rencontrée. Au lieu d'imbriquer dix niveaux d'instructions if, vous évaluez chaque règle métier séquentiellement, appelez jdeErrorSet et retournez ER_ERROR immédiatement en cas d'échec. Coder en dur des chaînes de messages d'erreur directement dans le code source C est un anti-modèle grave qui brise le support multilingue et contourne le moteur centralisé JDE. Mappez toujours vos échecs de validation à des éléments définis du Data Dictionary, ce qui garantit que lorsqu'Oracle met à jour une routine de validation standard, votre code personnalisé hérite du comportement système mis à jour sans nécessiter de recompilation. Cette approche maintient l'empreinte de votre code personnalisé propre et assure la compatibilité avec les futures Tools Releases.
Découplage des recherches en cache des transactions de base de données
Interroger des tables physiques comme F4102 ou F41021 à l'intérieur d'une boucle de traitement de milliers d'enregistrements dégrade les performances de plusieurs fois par rapport aux recherches en cache mémoire. Lors de la validation d'enregistrements d'inventaire en masse dans des fonctions métier C personnalisées, solliciter la base de données de manière répétée pour les mêmes données de base est un échec architectural courant. L'alternative standard consiste à utiliser les APIInterface permettant à différents logiciels de communiquer et d'échanger des informations. JDE User Cache telles que jdeCacheInitFonction d'initialisation d'un espace de stockage en mémoire vive pour les données temporaires. et jdeCacheFetch pour charger les données de référence une seule fois en mémoire lors de l'initialisation.
Une conception de validation propre isole ces recherches basées sur la mémoire dans des fonctions d'aide internes dédiées au sein du fichier source C, gardant la logique métier principale claire. La création d'une aide localisée comme Ixxxxxx_RetrieveItemCache permet à votre fonction JDEBFRTN principale de rester concentrée sur les règles métier plutôt que sur la manipulation des pointeurs de cache. Cette séparation des préoccupations garantit que si vous modifiez la structure de la clé de cache, la modification est limitée à une seule fonction d'aide.
L'échec de la gestion du cycle de vie de ces allocations mémoire introduit de graves risques de stabilité pour votre serveur Enterprise. Une terminaison correcte du cache à l'aide de jdeCacheTerminate est critique pour éviter les fuites de mémoire qui finissent par épuiser le tas (heap) et faire planter les noyaux callObjectProcessus serveur dédié à l'exécution des fonctions métier à distance.. Dans un environnement à haut volume traitant quotidiennement des dizaines de milliers de lignes de commandes de vente, un handle de cache non libéré déclenchera une condition de mémoire insuffisante sur votre serveur Enterprise en quelques heures, forçant un redémarrage non planifié du service.
Pour éviter les conflits de sessions simultanées, configurez votre cache avec un nom unique utilisant le numéro de travail de l'utilisateur ou l'ID de session. Cela empêche plusieurs sessions HTML exécutant la même BSFN de corrompre les données de validation mises en cache les unes des autres. Sur la Tools Release 9.2.7, l'implémentation de caches indexés par session a résolu des problèmes intermittents de verrouillage d'enregistrements qui bloquaient auparavant une partie importante des transferts d'entrepôt simultanés, parfois jusqu'à quinze pour cent.

Établir la limite des entrées/sorties (I/O) de table dans les BSFN C
Dans le traitement de transactions multi-tables, en particulier lors de la mise à jour d'enregistrements d'inventaire critiques dans la table F41021 Inventory Master, mélanger la logique de validation avec les écritures en base de données provoque la corruption des données. Nous avons audité des modifications personnalisées de routage de réception où le développeur écrivait directement dans la base de données à l'intérieur d'une boucle, pour finalement rencontrer un échec de validation à mi-chemin du lot. Ce modèle entraîne des enregistrements orphelins car la moitié de la transaction a été validée. La règle doit être absolue : les écritures en base de données ne doivent jamais s'exécuter si une étape de validation a enregistré une erreur dans la structure LPBHVRCOM.
La séparation explicite des passes de validation des passes d'écriture empêche les écritures partielles et orphelines dans la base de données lors d'opérations multi-tables. Cela signifie qu'il faut d'abord parcourir l'intégralité de votre structure de données d'entrée ou de votre cache, évaluer les règles métier et stocker les erreurs en mémoire avant d'exécuter une seule ligne d'I/O. Si votre boucle de validation signale ne serait-ce qu'une erreur, vous quittez immédiatement la BSFN. Cette séparation nette réduit la contention de la base de données, car vous évitez de maintenir des verrous sur des tables comme la F41021 en attendant que les routines de validation se terminent.
Pour les tables personnalisées, l'utilisation des API JDB_OpenTable et JDB_InsertTable au sein d'une limite de transaction explicite garantit une conformité ACIDEnsemble de règles garantissant la validité et la sécurité des transactions en base de données. stricte. Vous devez passer le handle de session hUser de la structure lpBhvrCom directement dans ces API JDB pour les lier à la transaction active. Cette liaison garantit que si la transaction parente est annulée, vos insertions dans les tables personnalisées sont annulées avec elle.
Un piège courant consiste à effectuer des mises à jour de table à l'intérieur d'une boucle avant de vérifier que toutes les lignes d'entrée de la charge utile sont complètement valides. Dans un chargement par lots de factures volumineux, l'exécution d'une mise à jour sur l'une des premières lignes alors qu'une ligne suivante contient une succursale/usine invalide crée un grand livre auxiliaire incohérent. Validez toutes les lignes au préalable, et seulement lorsque le nombre d'erreurs est nul, lancez la boucle de transaction pour valider les modifications.
Un exemple concret de code de validation BSFN C
Un point d'échec courant dans les fonctions métier C personnalisées est l'encombrement de la fonction d'exportation principale avec la logique de validation, ce qui obscurcit la gestion de la mémoire et des erreurs. Pour éviter cela, le point d'entrée principal de la fonction métier doit analyser la structure lpDS et initialiser les variables d'état internes en toute sécurité avant que tout traitement ne commence. Déléguer le travail lourd à une fonction d'aide interne, I5501001_ValidateAndWrite, agit comme l'orchestrateur pour garder la fonction d'exportation principale propre et lisible.
Au sein d'une telle architecture, des vérifications explicites de pointeurs nuls sur les types de données JDE tels que MATH_NUMERICFormat numérique spécifique à JD Edwards pour assurer la précision des calculs. et JDEDATEFormat de date interne utilisé pour le stockage et le traitement dans JD Edwards. empêchent les violations de mémoire et les plantages système qui peuvent faire tomber un noyau callObjectProcessus serveur dédié à l'exécution des fonctions métier à distance. entier. Si vous passez un pointeur non alloué à FormatMathNumeric ou tentez de comparer une structure de date non initialisée, le noyau se termine immédiatement. L'implémentation d'une validation stricte des pointeurs à la limite de I5501001_ValidateAndWrite garantit que votre logique échoue gracieusement, renvoyant une erreur structurée à la pile d'appels au lieu d'un core dump.
L'implémentation suivante démontre cette ségrégation structurelle, montrant comment nous gérons les pointeurs structurels, exécutons les vérifications d'erreurs et effectuons une écriture de table conditionnelle à l'aide des API natives JDE.
static JDEDB_RESULT I5501001_ValidateAndWrite(LPBHVRCOM lpBhvrCom, LPVOID lpVoid, LPDSD5501001 lpDS) {
HREQUEST hRequest = NULL;
JDEDB_RESULT jdDbResult = JDEDB_PASSED;
if (lpDS == NULL || &lpDS->mnAddressNumber == NULL || &lpDS->jdDateUpdated == NULL) {
return JDEDB_FAILED;
}
if (FormatMathNumeric(NULL, &lpDS->mnAddressNumber) != ID_SUCCESS) {
return JDEDB_FAILED;
}
if (lpDS->cActionCode == 'A') {
jdDbResult = JDB_OpenTable(lpBhvrCom->hEnv, _J("F5501001"), NULL, NULL, NULL, NULL, &hRequest);
if (jdDbResult == JDEDB_PASSED) {
/* Logique d'insertion exécutée uniquement après une validation réussie */
JDB_CloseTable(hRequest);
}
}
return jdDbResult;
}Débogage et validation de l'exécution des BSFN C
Les échecs de validation locale sur un client lourd surviennent souvent parce que les développeurs s'appuient sur les fenêtres contextuelles d'exécution standard au lieu d'un traçage d'exécution approfondi. Pour isoler un échec de validation dans votre code C personnalisé, attachez le débogueur Visual Studio directement au processus active_run.exe actif sur votre client de développement. Cela vous permet de définir des points d'arrêt à l'intérieur du répertoire source (b9\DV920\source\B55VAL.c) et de parcourir ligne par ligne la fonction métier au fur et à mesure que le client web local déclenche les règles d'événement (ERRègles d'événements, le langage de programmation interne de JD Edwards.).
S'appuyer uniquement sur le débogage interactif fait l'impasse sur le contexte transactionnel, c'est pourquoi vous devez analyser le fichier jdedebug.log pour tracer la séquence exacte des appels d'API et des instructions SQLLangage standard pour la communication avec les bases de données.. Recherchez dans ce journal les API JDB_OpenTable et JDB_Fetch pour confirmer vos limites de requête. Un JDB_ClearSelection mal placé peut provoquer une passe de validation silencieuse sur un mauvais enregistrement, ce qui est facilement repérable dans un fichier journal de plusieurs milliers de lignes si vous filtrez par vos identifiants de table personnalisés.
Un code qui fonctionne parfaitement sur un client lourd local peut échouer de manière catastrophique sous charge sur un serveur Enterprise en raison d'une corruption de mémoire. Surveillez les journaux du noyau callObject sur votre serveur HTML pour identifier les fuites de mémoire ou les pointeurs non initialisés qui ne se manifestent que dans un environnement multi-threadé. Recherchez spécifiquement les erreurs COB0000012 ou les terminaisons soudaines du noyau, qui indiquent généralement que votre code C a écrit au-delà de la taille allouée d'une structure de données ou a omis de libérer un pointeur mémoire alloué via jdeAlloc.
Pour vous éloigner des cycles de tests manuels, automatisez la validation de votre logique métier C à l'aide de JD Edwards EnterpriseOne OrchestratorOutil d'automatisation et d'intégration de processus métier pour JD Edwards.. L'exécution de la BSFN directement à partir d'une demande de service personnalisée Orchestrator contourne entièrement le conteneur APPL. Cela vous permet d'exécuter des suites de tests de régression avec des dizaines de variations de charges utiles distinctes en quelques secondes, vérifiant que votre logique de validation renvoie systématiquement les codes d'erreur corrects sans avoir à cliquer manuellement dans une interface Power Forms.
Si vous auditez votre code C personnalisé pour éliminer les fuites de mémoire ou améliorer les performances de la Tools Release 9.2.8, notre bibliothèque de ressources comprend des analyses techniques plus approfondies sur la gestion du cache JDE et les opérations de cache utilisateur multi-threadées. Contactez notre équipe d'architecture d'entreprise pour planifier une revue de code de vos fonctions métier héritées.
