
Un traitement UBE à haute volumétrie qui traite 50 000 lignes de vente gaspille souvent 15 % à 20 % de sa fenêtre d'exécution en raison de recherches redondantes dans F0101. Même avec une indexation de base de données optimisée, accéder au même enregistrement de l'annuaire d'adresses 5 000 fois dans une seule exécution de lot crée un surcroît d'overhead SQL et de latence de middleware. Cet exemple de mise en cache BSFN JD Edwards réduit les lectures répétées F0101 en déplaçant la logique de recherche dans un segment de mémoire local, contournant ainsi la couche de base de données pour chaque demande après la récupération initiale.
La mise en œuvre correcte de ce modèle nécessite une structure JDECACHE basée sur des pointeurs dans une fonction commerciale C. Au lieu de s'appuyer sur le middleware standard pour gérer le tampon, nous contrôlons manuellement les opérations jdeCacheInit et jdeCacheFetch pour stocker les attributs F0101 tels que le type de recherche (AT1) ou le nom alpha (ALPH) directement en mémoire. Cette approche élimine les risques de cache « zombie » souvent trouvés dans le code personnalisé mal écrit en garantissant que l'appel jdeCacheTerminate est lié à l'événement de fin de processus de l'UBE ou de l'application. Dans un environnement 9.2 typique, cette configuration peut réduire les entrées-sorties physiques pour les tables de données maîtres d'un pourcentage significatif, souvent supérieur à 90 %, réduisant ainsi considérablement la contention de la base de données pendant les fenêtres de traitement de pointe.
Le coût de performance des recherches F0101 redondantes
Un UBE qui traite 50 000 lignes de commande souvent appelle une BSFN pour récupérer le nom alpha pour la même adresse de livraison des milliers de fois. Si votre boucle atteint 10 000 itérations et déclenche une instruction SELECT sur F0101 pour chaque enregistrement, vous effectuez essentiellement une attaque DOS contre votre propre base de données. Même avec une clé primaire bien indexée sur ABAN8, la latence aller-retour entre le serveur d'entreprise et le serveur de base de données n'est pas nulle. Dans une architecture standard, l'overhead de middleware de base de données pour une récupération de clé unique consomme généralement 1 à 3 millisecondes. Alors que 3 ms peuvent sembler négligeables, les multiplier par 10 000 itérations ajoute un surcroît d'overhead significatif, souvent d'une demi-minute ou plus de temps d'attente d'E/S pure pour une seule exécution d'UBE.
Les développeurs s'appuient souvent sur des fonctions de service standard comme GetAddressBookDescription (B0100066) car elles sont fiables et gèrent les vérifications d'erreurs nécessaires. Cependant, ces fonctions sont sans état ; elles ne mettent pas en cache les résultats entre les appels multiples dans le même thread. Chaque fois que B0100066 est invoquée, elle ouvre un curseur, exécute l'instruction SQL et récupère la ligne. Lorsque cela se produit à l'intérieur d'une boucle à haute volumétrie dans un R42520 Impressions de reçus ou un rapport d'intégrité financière personnalisé R55, le surcroît cumulé devient le goulet d'étranglement principal pour la fenêtre de lot.
La mise à l'échelle de la logique JDE pour les entreprises mondiales nécessite de s'éloigner de la mentalité de récupération à la demande pour les données maîtres qui changent rarement au cours d'une seule session. La réduction du nombre d'exécutions d'instructions SQL brutes est le levier le plus efficace dont dispose un développeur pour améliorer les performances sans demander de mises à niveau de matériel coûteuses ou de redimensionnement d'instances OCI. En mettant en œuvre un pointeur JDECACHE pour stocker les résultats de la première recherche F0101, les demandes suivantes pour le même AN8 peuvent être résolues en microsecondes via la mémoire plutôt qu'en millisecondes via le réseau. Ce déplacement transforme la dégradation des performances linéaires en un temps d'exécution quasi constant pour la résolution des données maîtres.
Conception de la structure de données de cache et de la clé
Une implémentation JDECACHE vit ou meurt par la typedef struct définie dans le fichier d'en-tête BSFN. J'ai vu des développeurs essayer de réutiliser des structures de données existantes (DSTR) pour le stockage du cache afin d'économiser du temps, mais c'est une erreur qui conduit souvent à des problèmes d'alignement de la mémoire ou à un surcroît de mémoire inutile. Vous devez définir une structure dédiée qui ne contient que les champs que vous souhaitez conserver. Pour une recherche F0101 à haute fréquence, votre structure doit commencer par le mnAddressNumber (MATH_NUMERIC) en tant qu'index principal, suivi des points de données spécifiques comme szNameAlpha (ALPH) et peut-être szTaxId (TAX1). La définition de ceci dans le fichier .h garantit que chaque fonction au sein de la source—que ce soit l'initialisation, la récupération ou la termination—fait référence à la même empreinte de mémoire tout au long de l'exécution.
L'unicité de la clé de cache est non négociable si vous souhaitez éviter l'overhead de JDECACHE_FetchRecords avec des filtres complexes. En définissant un index à clé unique sur mnAddressNumber, le gestionnaire de cache JDE effectue une recherche binaire sur les segments de mémoire, ce qui est significativement plus rapide qu'une recherche d'index SQL sur une grande table F0101 contenant 500 000+ enregistrements. Dans un environnement de distribution typique où un seul UBE peut traiter 10 000 lignes de vente, l'accès au cache pour les noms Sold-To et Ship-To réduit les appels de base de données totaux de 20 000 appels. Ce n'est pas seulement un gain marginal ; c'est la différence entre une exécution de lot de 15 minutes et une qui se termine en moins de cinq minutes.
L'efficacité provient du fait de remplir la structure avec chaque pièce de données dont l'application appelante pourrait avoir besoin plus tard dans le flux d'exécution. Si votre logique nécessite éventuellement le type de recherche (ATY) ou l'unité commerciale (MCU) de l'annuaire d'adresses, ajoutez-les à la structure maintenant. Une structure de 200 octets mise en cache pour 5 000 clients actifs consomme une empreinte de mémoire négligeable, généralement inférieure à quelques méga-octets de mémoire de poste de travail ou de serveur d'entreprise. Par rapport à la latence des appels JDB_FetchKeyed répétés sur un réseau congestionné vers une base de données hébergée par OCI, l'échange de mémoire est négligeable. Assurez-vous que votre tableau JDECACHE_KEYSEG correspond correctement à l'offset de mnAddressNumber dans la structure pour empêcher le middleware de récupérer le mauvais bloc de mémoire lors d'une opération de récupération.
Initialisation de JDECACHE dans la BSFN
Chaque développeur BSFN a éventuellement vu un noyau d'objet d'appel planter en raison de deux fonctions personnalisées différentes qui ont tenté d'initialiser un cache avec le même nom. Vous devez passer une chaîne unique et descriptive à l'API jdeCacheInit, telle que "C550101_AddressBookCache". L'utilisation d'un nom générique comme "AB_Cache" risque une collision avec les BSFN Oracle standard exécutés dans le même thread. Dans les environnements qui traitent 50 000 lignes de commande, une collision de nom peut corrompre l'espace de mémoire du noyau, entraînant des processus zombies sur le serveur d'entreprise.
Les noyaux d'objets d'appel multithreads réutilisent la mémoire, ce qui rend l'isolation de session une préoccupation majeure. Vous prévenez la contamination de données entre sessions en ajoutant le numéro de travail (JOBS) à la chaîne de nom de cache. Sans cet identifiant unique, l'utilisateur A peut récupérer des données de l'annuaire d'adresses mises en cache par l'utilisateur B. Dans un environnement 9.2, ne pas inclure le numéro de travail entraîne des bogues d'intégrité des données intermittents qui sont quasi impossibles à reproduire dans un environnement de développement local à utilisateur unique.
La définition de l'index de cache lors de l'initialisation détermine si les recherches suivantes fonctionnent à une complexité O(1) ou O(n). Vous définissez l'index en utilisant jdeCacheAddIndex immédiatement après l'initialisation, en le faisant correspondre au champ F0101.AN8. Pour un cache contenant 2 000 enregistrements, une analyse non indexée prend significativement plus de cycles CPU qu'une recherche clé. Cette différence de performance est critique lorsque la BSFN est appelée à l'intérieur d'une boucle dans un UBE lourd comme R42520.
La logique doit vérifier si la poignée de cache est valide pour minimiser l'overhead. La vérification de la variable hCache contre NULL garantit que si une BSFN est appelée 10 000 fois dans un thread, l'initialisation n'a lieu qu'une seule fois. Cette approche réduit le temps d'exécution d'un pourcentage significatif, souvent compris entre 10 % et 20 %, par rapport aux fonctions qui réouvrent les poignées à chaque appel.
Mise en œuvre de la logique de récupération ou d'insertion
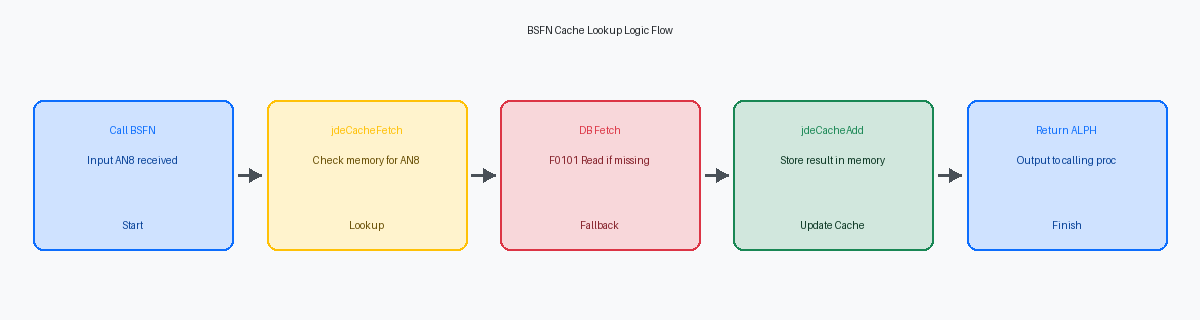
La logique BSFN commence par un appel immédiat à jdeCacheFetch en utilisant l'AN8 passé comme clé principale. Cette vérification se produit avant toute activité de base de données, garantissant que le système ne consomme des cycles CPU que si les données sont manquantes dans la mémoire de la session utilisateur. Dans un UBE à haute volumétrie qui traite 50 000 lignes de commande, cette seule ligne de code C peut éliminer des dizaines de milliers d'instructions SQL redondantes si la distribution de l'annuaire d'adresses est concentrée. La signature de la fonction nécessite la poignée de cache établie lors de l'initialisation et un pointeur vers la structure de clé contenant la valeur AN8.
Lorsque l'opération de récupération renvoie JDECACHE_NOT_FOUND, la BSFN bascule vers la base de données physique. C'est là que vous exécutez une instruction JDB_FetchKeyed standard contre la table F0101 pour récupérer le nom alpha ou le type de recherche requis pour la logique commerciale. Si la base de données retourne un enregistrement, la BSFN remplit la structure de données locale et appelle immédiatement jdeCacheAdd. En insérant l'enregistrement dans le cache à ce stade, vous transformez une opération d'E/S coûteuse en une écriture de mémoire de sous-millisecondes. Cela garantit que la prochaine demande pour le même AN8—que ce soit dans une boucle UBE ou une grille d'application—contourne entièrement la base de données.
Ce modèle de récupération ou d'insertion crée un tampon auto-remplissant qui s'adapte à la complexité du processus de lot. Pour un client de distribution typique exécutant JDE 9.2, nous constatons souvent que les BSFN personnalisées interrogent F0101 pour chaque ligne de détail, même lorsque un seul client représente une partie importante du volume de transactions, souvent supérieure à trois quarts. En utilisant cette logique, la base de données est interrogée exactement une fois par numéro d'adresse unique par session. L'encapsulation de ceci dans une BSFN C spécifique maintient une séparation claire des préoccupations, gardant l'application appelante inconsciente du mécanisme de mise en cache sous-jacent.
Si JDB_FetchKeyed ne parvient pas à trouver l'AN8, la BSFN doit renvoyer une erreur sans tenter de jdeCacheAdd. Tenter d'ajouter un enregistrement null au cache peut entraîner une corruption de la mémoire ou des résultats inattendus dans les tentatives suivantes. L'overhead de jdeCacheFetch est négligeable par rapport à une lecture de disque physique, ce qui rend ce modèle une norme de performance pour la personnalisation de niveau entreprise. Vous devriez recommander cette approche pour toute recherche de données maîtres qui se produit plus de 1 000 fois dans un seul thread d'exécution.
Gestion de la portée et de la termination du cache
Un seul UBE qui traite 50 000 enregistrements et qui ne parvient pas à terminer une instance de cache peut consommer plusieurs centaines de méga-octets de RAM dans le noyau d'objet d'appel (COK). Lorsque plusieurs utilisateurs déclenchent des fuites similaires, le COK atteint finalement sa limite de mémoire—souvent 2 Go sur les noyaux 32 bits—et plante, forçant un zombie de noyau et laissant tomber les sessions actives. Vous devez vérifier que jdeCacheTerminate est explicitement appelé pour chaque poignée de cache initialisée ; la simple fin de l'exécution de la BSFN ne libère pas la mémoire allouée dans la couche de middleware JDE.
Dans un processus de lot UBE standard, tel qu'une mise à jour F4211 à haute volumétrie, le cache doit persister tout au long des événements Do Section pour maximiser le taux de correspondance pour les recherches F0101. Le modèle optimal implique l'appel d'une BSFN de nettoyage lors de l'événement End Report. Cette BSFN doit référencer la poignée de cache hCache spécifique utilisée tout au long du travail pour garantir que la mémoire est effacée proprement avant la fin du thread de processus. Si vous utilisez un cache global partagé entre plusieurs BSFN dans un seul thread, la logique de termination doit être centralisée pour empêcher qu'une BSFN n'orphanise une poignée que une autre BSFN s'attend à être active.
Les applications interactives nécessitent une approche plus nuancée de la portée. Si un cache prend en charge un formulaire Power complexe avec plusieurs sous-formulaires, le développeur doit décider si le cache vit pour la durée de vie du formulaire ou est effacé après un événement spécifique. La persistance du cache au niveau du formulaire permet des réponses rapides de l'interface utilisateur pendant le défilement de la grille, mais nécessite un appel à la BSFN de termination lors de l'événement End Form. Dans les environnements avec 500+ utilisateurs concurrents, ne pas gérer cette portée conduit à une fragmentation de la mémoire sur les pools de COK du serveur d'entreprise.
L'utilisation correcte de la poignée de cache hCache garantit que vous terminez l'instance spécifique créée par votre processus plutôt que d'un pointeur global. Dans un environnement multithread, le passage de la poignée spécifique à la fonction de termination empêche l'accidental contamination croisée des données. Une erreur courante consiste à s'appuyer sur un nom de cache codé en dur dans l'appel de termination sans vérifier que la poignée est valide. Une conception BSFN fiable inclut une vérification d'une poignée nulle avant de tenter la termination, évitant ainsi les erreurs de violation de la mémoire tout en garantissant que la mémoire est restituée au système d'exploitation.
Résultats de benchmarking et limites d'invalidation
Dans un UBE à haute volumétrie qui traite 50 000 enregistrements, le remplacement des appels JDB_FetchKeyed directs à F0101 par une implémentation JDECACHE donne lieu à une réduction de 70 à 90 % du temps d'exécution de la BSFN. Ce saut de performance se produit parce que l'overhead de l'analyse des instructions SQL et des aller-retour réseau vers la couche de base de données est éliminé après la première rencontre d'un numéro d'adresse unique. Dans un scénario de client logistique, un UBE de manifeste d'expédition de 45 minutes a été réduit à moins de dix minutes simplement en mettant en cache le nom alpha et le type de recherche. Le gain d'efficacité est le plus prononcé lorsque le rapport entre les transactions et les entités uniques est élevé, comme 1 000 lignes de vente faisant référence à seulement 50 adresses de livraison distinctes.
L'intégrité des données repose sur la compréhension que JDECACHE est un instantané en mémoire, et non un reflet en temps réel de la base de données. Si un processus parallèle ou un thread différent met à jour l'enregistrement F0101 pendant l'exécution de votre BSFN, le cache reste inconscient et continue de servir des données obsolètes jusqu'à ce que le cache soit explicitement terminé ou que le processus se termine. Ce risque rend le modèle inadapté pour les tables de transactions volatiles comme F4211 ou F0911 où le statut de l'enregistrement change fréquemment dans le même millième de seconde. Pour les données maîtres comme l'annuaire d'adresses, où les modifications du nom du client ou du code fiscal se produisent via des applications de maintenance peu fréquentes, le risque d'une collision en cours de processus est statistiquement négligeable par rapport aux avantages de débit massif.
Cette stratégie de mise en cache est spécifiquement conçue pour les lectures de données maîtres lourdes qui restent statiques pour la durée d'un seul travail de lot ou d'une session interactive spécifique. Pour éviter les fuites de mémoire ou les erreurs « Mémoire insuffisante » sur le serveur d'entreprise, vous devez vérifier que la BSFN inclut un appel de termination à jdeCacheTerminate dans l'événement de fin de processus. Lors du déploiement de ces caches personnalisés en production, utilisez la section Métriques d'exécution dans Server Manager pour suivre l'utilisation des objets JDE et la consommation de mémoire par processus. Si vous observez l'empreinte de mémoire du noyau JDE augmenter de manière constante sans atteindre un plateau, cela indique généralement un échec pour effacer les segments de cache, ce qui peut finalement déstabiliser d'autres processus s'exécutant sur le même noyau d'objet d'appel.

