
Dans nos revues de code sur des dizaines d'environnements JDE 9.2Version moderne de l'ERP JD Edwards EnterpriseOne d'Oracle, intégrant des fonctionnalités cloud et de livraison continue., nous constatons régulièrement qu'une partie importante des fonctions métier C personnalisées (BSFNBusiness Function : module de code réutilisable écrit en C ou Event Rules pour exécuter des processus métier dans JD Edwards.) — souvent d'un tiers à la moitié — dupliquent inutilement la logique Oracle standard. Les développeurs clonent souvent des modules entiers comme B4200310 ou B1200010 juste pour exécuter une seule validation, au lieu d'implémenter un appel propre via un exemple jdeCallObject JDE BSFN pour exécuter une fonction métier réutilisable. Ce code redondant pose problème lors des mises à jour car il contourne les mises à jour de livraison continue d'Oracle. L'approche la plus propre consiste à appeler dynamiquement la fonction métier standard depuis votre code C personnalisé.
L'implémentation d'un modèle d'exécution dynamique précis à l'aide de jdeCallObjectAPI fondamentale de JD Edwards permettant d'appeler une fonction métier depuis un programme C. vous permet de réutiliser les fonctions métier standards tout en préservant pleinement les limites de transaction et la pile d'erreurs lpBhvrComStructure de données contenant le contexte d'exécution, comme les informations de session et l'état des transactions.. En transmettant la structure commune de comportement correcte et en mappant vos structures de données de manière dynamique, vous évitez de coder en dur des dépendances de base de données qui échouent lors des ESUElectronic Software Update : correctif logiciel livré par Oracle pour mettre à jour des composants spécifiques de JD Edwards.. Cette approche garantit que votre parc personnalisé reste léger, tolérant aux mises à jour et compatible avec la feuille de route de support d'Oracle jusqu'en 2034.
Le coût de la duplication de la logique métier JDE centrale
J'audite régulièrement des environnements JDE d'entreprise contenant 5 000 à 15 000 objets personnalisés et je constate qu'entre 10 % et 15 % des fonctions métier C personnalisées sont des clones inutiles de la logique standard. Les développeurs copient-collent souvent une fonction C standard dans un objet personnalisé « 55 » parce qu'ils souhaitent contourner une seule vérification de validation ou surcharger un paramètre codé en dur. Lorsque vous duplicatez une Master Business FunctionModule centralisé regroupant la logique métier complexe et les validations pour une entité majeure comme les ventes ou les stocks. complexe comme Sales Order Entry Edit Line (B4200310), vous héritez de milliers de lignes de logique très volatile que votre équipe doit désormais adapter manuellement lors de chaque mise à jour ou cycle d'Electronic Software Update (ESU).
Cette duplication brise le modèle de livraison continue d'Oracle. Au lieu de cloner des objets standards, l'invocation directe de la fonction métier standard à l'aide de l'API native jdeCallObject garantit que tous les correctifs logiciels critiques appliqués par Oracle se propagent automatiquement à vos applications personnalisées. Lorsqu'Oracle livre un correctif de calcul de taxe ou un patch d'allocation d'inventaire au code standard sous-jacent, votre wrapper personnalisé hérite immédiatement de cette mise à jour, éliminant complètement des semaines de fusion de code manuelle et de tests lors de votre prochaine mise à jour de Tools ReleaseCouche technologique de JD Edwards gérant l'infrastructure et l'interface, indépendamment des données applicatives. 9.2.
L'appel direct des BSFN standards existantes préserve également les routines de validation de base de données centrales et garantit l'intégrité transactionnelle sur les tables standards comme F4211 et F0911. B4200310, par exemple, gère des structures de mémoire internes complexes, des calculs de taxes et des règles de tarification avancées avant de valider les enregistrements. Contourner ces routines natives en écrivant des inserts SQL personnalisés ou du code C personnalisé dépouillé corrompt inévitablement les transactions en aval, entraînant des rapports d'intégrité du grand livre erronés que les équipes financières doivent rapprocher manuellement à la fin du mois.

Anatomie de l'API jdeCallObject et de la structure LPBHID
L'invocation directe d'une fonction métier à partir du code source C nécessite de contourner le moteur standard d' Event RulesLangage de programmation visuel propriétaire de JD Edwards utilisé pour créer la logique métier sans écrire de code C. et de s'interfacer directement avec le moteur d'exécution central de JDE. L'API jdeCallObject est la porte d'entrée pour cela, exigeant exactement quatre paramètres primaires transmis dans une séquence rigide : la chaîne du nom de la fonction cible (telle que "F4111EditLine"), le pointeur de contexte de comportement (lpBhvrCom), le pointeur de profil utilisateur (lpVoid) et le pointeur vers la structure de données cible allouée en mémoire. Les développeurs venant des Event Rules sous-estiment souvent la rigueur de cette liaison au niveau C, où la transmission d'un pointeur de structure nul ou mal transtypé déclenche une violation de mémoire immédiate et un kernelProcessus serveur gérant les opérations logiques, les accès aux données et la communication entre les composants JDE. zombie sur le serveur d'entreprise.
Le deuxième paramètre, lpBhvrCom, agit comme le système nerveux opérationnel de l'appel. Cette structure de comportement maintient les données d'état environnemental vitales, suivant les handles de connexion à la base de données actifs, les variables de session utilisateur et les limites critiques de traitement des transactions manuelles. Si vous exécutez une insertion multi-tables sur F0911 et F03B11 au sein d'une transaction active, la transmission d'un pointeur lpBhvrCom non initialisé ou corrompu brise la limite de transaction, provoquant la validation de la première insertion par le runtime tout en échouant silencieusement sur la seconde.
Chaque exécution de jdeCallObject produit un code de retour JDEDB_RESULT explicite qui doit être capturé et évalué. Une valeur de retour ER_SUCCESS (0) indique une exécution réussie, tandis que ER_ERROR (2) ou ER_WARNING (1) signale que la logique métier n'a pas pu terminer sa routine. Omettre l'évaluation immédiate de ce code de retour est une erreur courante et à haut risque dans les BSFN C personnalisées. Ne pas vérifier ER_ERROR avant de continuer permet au code en aval de s'exécuter aveuglément, écrivant des enregistrements incomplets dans des tables comme F4211 et corrompant l'intégrité transactionnelle de tout le thread de la base de données.
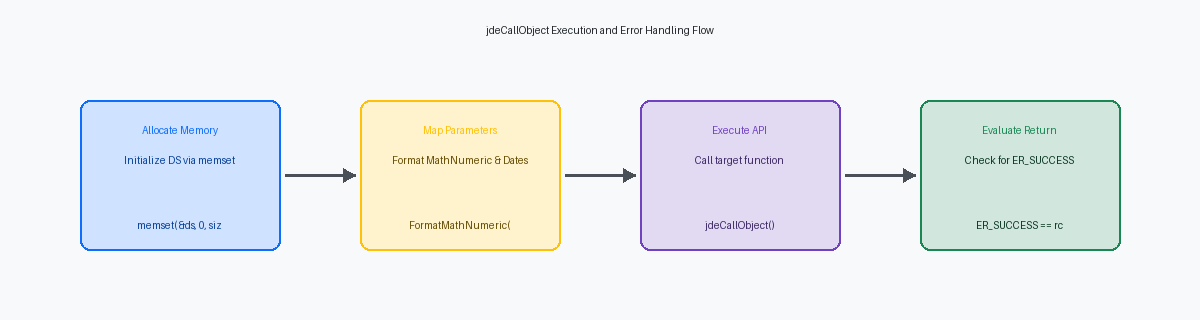
Allocation de structure de données et modèles de mappage
L'allocation de mémoire pour la structure de données d'une fonction métier cible nécessite le respect strict des règles d'alignement, d'autant plus que JDE est passé au traitement 64 bitsArchitecture de processeur permettant de traiter des volumes de données plus importants et d'adresser plus de mémoire vive. avec la Tools Release 9.2.5. Vous devez explicitement allouer cette mémoire en utilisant soit des variables de pile pour des portées locales plus petites, soit une allocation dynamique sur le tas (heap) via l'API jdeAlloc lors de la manipulation de tableaux de taille variable ou de pointeurs à longue durée de vie. Lors de l'utilisation de l'allocation sur le tas, un mauvais alignement d'une structure MATH_NUMERICType de données spécialisé de JD Edwards garantissant une précision décimale exacte pour les calculs financiers. peut provoquer des fautes de mémoire instantanées sur les serveurs d'entreprise Linux modernes.
Avant de transmettre ce bloc de mémoire à jdeCallObject, vous devez initialiser la structure de données cible avec des octets nuls à l'aide de memset pour effacer toute valeur résiduelle de la pile. L'omission de cette étape introduit souvent des bogues intermittents où des éléments non initialisés, comme un champ d'indicateur contenant des déchets de mémoire aléatoires, déclenchent de fausses erreurs de validation dans les Master Business Functions standards comme F4211 Edit Line (B4200310). Pour éviter les erreurs d'incompatibilité de type lors de la compilation sur votre compilateur d'entreprise (que ce soit Visual Studio ou gcc), votre BSFN appelante personnalisée doit explicitement inclure le fichier d'en-tête exact de la fonction cible, tel que b0100016.h pour l'Address Book MBF.
La gestion du mappage des données au sein de ces structures révèle les limites des opérateurs C standards, qui ne peuvent pas copier les types de données JDE complexes. Tenter une affectation directe sur une structure MATH_NUMERIC ou JDEDATE corrompra les pointeurs internes et les valeurs d'échelle, entraînant une corruption silencieuse de la base de données. Au lieu de cela, vous devez utiliser des API dédiées comme FormatMathNumeric pour convertir des valeurs numériques en chaînes, ou ParseDate et DeformatDate pour manipuler les champs de date en toute sécurité. Pour les copies directes de structure à structure, fiez-vous strictement à MathCopy et FormatDate pour préserver l'intégrité des positions décimales et des structures internes avant d'exécuter l'appel.
Implémentation d'un exemple d'appel jdeCallObject JDE BSFN
Le codage en dur des appels de Master Business Function à l'intérieur des fonctions métier C personnalisées est l'endroit où de nombreux développeurs juniors échouent, ce qui entraîne des fuites de mémoire ou des erreurs de pointeurs non mappés. Une implémentation standard et propre appelant l'Address Book Master MBF (B0100016) nécessite de déclarer la structure de données DSD0100016 directement dans votre code C personnalisé plutôt que de s'appuyer sur des pointeurs génériques. Cette structure doit être allouée sur la pile pour garantir la sécurité des threads lors de l'exécution sous l'architecture kernel JDE CallObject, qui gère des milliers de threads simultanés dans un environnement HTML de production typique.
Avant d'invoquer l'API, vous devez initialiser la structure à zéro à l'aide de memset pour empêcher la mémoire résiduelle de corrompre le cache JDE. Mappez votre numéro d'adresse cible au membre dsD0100016.mnAddressNumber en convertissant la chaîne d'entrée à l'aide de l'API deformatMathNumeric, qui analyse en toute sécurité la chaîne numérique dans le format propriétaire MATH_NUMERIC de JDE. Vous définissez ensuite explicitement le champ du code d'action, dsD0100016.cActionCode, sur 'Inquire' pour déclencher une lecture sur la table F0101.
Une fois la structure de données remplie, exécutez l'appel API jdeCallObject en transmettant la structure LPBHID, le nom de la fonction cible 'F0101GetAddressBookData' et un pointeur vers votre structure DSD0100016 initialisée. L'évaluation du code de retour n'est pas négociable ; vous devez vérifier si l'API renvoie ER_SUCCESS ou ER_ERROR. L'omission de cette validation est la raison principale pour laquelle des échecs silencieux se produisent, laissant les applications personnalisées avec des champs d'écran vides alors que les journaux du noyau se remplissent d'exceptions non gérées.
Si l'API renvoie ER_ERROR, ne laissez pas l'échec mourir dans la couche C. Extrayez le code d'erreur spécifique de la pile d'erreurs JDE à l'aide de l'API jdeErrorSet pour faire remonter le message au niveau de l'application interactive ou de l' UBEUniversal Batch Engine : moteur de JD Edwards responsable de l'exécution des rapports et des traitements de données en masse en arrière-plan.. Cela garantit que l'utilisateur final voit l'erreur exacte « Numéro d'adresse invalide » ou « Incompatibilité du type de recherche » sur son écran plutôt qu'une exception de client Web générique et inutile.
Gestion des limites de transaction et des piles d'erreurs
Un point de défaillance courant dans les interfaces financières personnalisées est la création de transactions GL orphelines dues à des connexions de base de données isolées. Lors de l'exécution de mises à jour transactionnelles comme Journal Entry Edit Line (B0900011), la BSFN enfant doit rejoindre la limite de transaction active de la fonction parente. Si vous exécutez B0900011 en dehors de la transaction du parent, un échec ultérieur dans les étapes de traitement des pièces ou des factures laisse des enregistrements F0911 non validés ou des soldes incohérents dans la table F0902. Vous devez configurer la relation parent-enfant pour qu'ils partagent une seule transaction de base de données, garantissant que soit tout est validé, soit tout est annulé.
La transmission du handle utilisateur actif (lpBhvrCom->hUser) lors de l'invocation de jdeCallObject garantit que les verrouillages et les deadlocks de base de données sont évités. Lorsque le runtime exécute des fonctions métier imbriquées, l'utilisation du pointeur hUser du parent permet au pilote de base de données de reconnaître que les opérations appartiennent au même thread de session. Si vous allouez par erreur une nouvelle session utilisateur via JDB_InitBhvr à l'intérieur de la BSFN enfant, la base de données la traite comme une connexion distincte. Cette erreur entraîne un blocage immédiat du thread lorsque l'enfant tente de mettre à jour une ligne F0911 verrouillée par la transaction non validée du parent.
Si une exécution enfant échoue, vous devez invoquer les routines standards de nettoyage du cache JDE ou de rollback pour éviter les enregistrements orphelins dans des tables comme F0911. L'utilisation du traitement manuel des transactions nécessite des appels explicites aux API de commit ou de rollback en fonction de l'état final du code de retour de jdeCallObject. Lorsque jdeCallObject renvoie ER_ERROR lors d'un appel à B0900011, vous devez immédiatement appeler jdeCallObject pour B0900012 (Journal Entry Document Clean Up) pour purger le cache. Ne pas déclencher ce nettoyage laisse des données d'en-tête et de détail obsolètes dans les structures du cache JDE, ce qui corrompt la transaction suivante traitée dans le même thread du kernel CallObject.
Impact sur les performances et gestion du cache local
L'exécution d'une boucle qui traite plus de 10 000 enregistrements dans un UBE personnalisé — tel qu'un processeur de mise à jour/édition de commandes client EDI entrantes — dégradera considérablement le débit du système si la fonction cible effectue des recherches redondantes dans la base de données. Une seule requête répétitive vers F0010 ou F0101 à l'intérieur de la boucle ajoute une exécution SQL cumulative et une latence réseau qui peuvent transformer une exécution de quelques minutes en un goulot d'étranglement de plusieurs heures. Ce surcoût est entièrement évitable si vous passez d'opérations liées au disque à des opérations liées à la mémoire.
Pour optimiser les performances, les développeurs doivent contourner les E/S disque répétitives en utilisant les API de cache JDE standards comme jdeCacheInit pour stocker et réutiliser les données de configuration statiques lors des appels répétitifs de fonctions enfants. Le chargement de tables de constantes ou de constantes de succursale/usine dans un cache mémoire utilisateur nommé pendant la phase d'initialisation permet au système de résoudre instantanément la logique de validation. La récupération d'un pointeur à partir de la mémoire locale prend moins d'une microseconde, tandis que l'interrogation de la base de données, même avec des index, entraîne un aller-retour réseau inévitable.
Un autre domaine critique d'optimisation est la gestion des curseurs et des handles de base de données. Maintenir les handles de table de base de données ouverts sur plusieurs itérations au lieu de laisser la BSFN appelée ouvrir et fermer les handles à chaque appel réduit considérablement le surcoût des curseurs de base de données. Par exemple, transmettre un pointeur de table persistant ou maintenir le handle actif dans une structure de données parente empêche le système d'allouer et de désallouer constamment des ressources du système d'exploitation. Enfin, vous devez configurer les BSFN appelantes et appelées pour qu'elles s'exécutent au sein du même thread de serveur d'entreprise. Cet alignement spécifique de l' OCMObject Configuration Manager : outil JD Edwards définissant l'emplacement d'exécution (serveur ou local) des objets et l'accès aux bases de données. empêche le noyau JDE d'initier une communication inter-processus ou des délais d'appel de procédure à distance, gardant toute la pile d'exécution locale et rapide.
Maîtriser jdeCallObject est la base pour stabiliser un parc de code personnalisé 9.2. Si vous optimisez la gestion de la mémoire ou déboguez des modèles de cache complexes, ce site contient des analyses approfondies sur l'utilisation de lpdsCommon et l'efficacité de l'API jdeCache. Vous pouvez également consulter mon portfolio de projets techniques pour voir comment ces modèles BSFN s'adaptent aux intégrations OCIOracle Cloud Infrastructure : plateforme de services cloud d'Oracle pour l'hébergement et la gestion d'infrastructures d'entreprise. à haut volume traitant des dizaines de milliers de transactions par jour. Ces ressources techniques se concentrent sur les 200 à 500 objets réellement impactés qui dictent la stabilité et les performances de votre environnement de production.
