Lors de l'audit des modifications personnalisées dans les environnements JDE 9.2Version 9.2 de JD Edwards EnterpriseOne, apportant des améliorations fonctionnelles et technologiques majeures., je trouve régulièrement un défaut architectural courant : les valeurs par défaut des colonnes pour les tables personnalisées (telles qu'une F550101Exemple de nom de table personnalisée dans JD Edwards, où le préfixe 55 indique un développement spécifique au client.) sont codées en dur dans plusieurs applications interactives (APPL)Applications JD Edwards accessibles via un navigateur web pour la saisie ou la consultation de données.. S'appuyer sur les contraintes par défaut au niveau de la base de données échoue car la couche middleware JDBCouche logicielle de JD Edwards qui gère la communication et la traduction des données entre l'application et la base de données. insère explicitement des blancs ou des zéros, écrasant les valeurs par défaut de la base de données. L'implémentation d'exemples JDE NERNamed Event Rule, un langage de programmation propriétaire de JDE compilé en C pour créer de la logique métier. pour les valeurs par défaut des tables personnalisées permet aux équipes de centraliser la validation et l'affectation avant d'appeler l'insertion d'E/S de table, garantissant l'intégrité des données sur tous les points d'entrée.
Ce guide fournit des modèles d'implémentation concrets pour centraliser la validation et l'affectation avant d'appeler l'insertion d'E/S de table. Le fait de déplacer cette logique hors des Event RulesInstructions de programmation ajoutées aux objets JDE pour définir leur comportement et leur logique métier. de la FDAForm Design Aid, l'outil graphique utilisé par les développeurs pour créer les écrans de JD Edwards. vers une fonction métier unique et réutilisable réduit l'empreinte du code personnalisé d'une partie significative des applications personnalisées, selon notre expérience d'environ un tiers à la moitié. Ce changement simplifie les futures mises à niveau de Tools ReleaseMise à jour de la couche technologique de JD Edwards, indépendante des données métier, améliorant la sécurité et les performances. et garantit un formatage cohérent des données, que les enregistrements proviennent d'une APPL, d'un UBEUniversal Batch Engine, un processus de traitement par lots utilisé pour les rapports ou les mises à jour massives. ou d'une orchestration basée sur AISApplication Interface Services, une interface permettant d'exposer la logique JDE à des applications externes via des services REST..
Le coût de la logique de valeurs par défaut dispersée dans les APPL
J'ai récemment audité un système d'expédition personnalisé où les développeurs avaient dispersé la logique de valeurs par défaut dans les événements Write Grid Line-BeforeÉvénement JDE s'exécutant juste avant l'insertion d'une ligne de grille dans la table de la base de données. et OK-Post Button Clicked de plusieurs APPL. Ce modèle de conception crée une dette technique immédiate car les Event Rules (ER)Scripting utilisé dans JD Edwards pour définir la logique métier des applications et des rapports. des applications interactives sont notoirement difficiles à tester unitairement et à maintenir en dehors de leur contexte d'exécution spécifique. Lorsque les exigences métier changent — comme la mise à jour d'un centre de profit par défaut ou d'un code d'état — vous êtes obligé d'extraire, de modifier et de construire des packages pour plusieurs applications interactives au lieu d'un seul composant réutilisable.
Considérez une table maîtresse personnalisée comme la F550101Exemple de nom de table personnalisée dans JD Edwards, où le préfixe 55 indique un développement spécifique au client., qui nécessite des valeurs par défaut pour une douzaine de champs distincts ou plus, y compris les colonnes d'audit standard, les types de recherche par défaut et les codes de devise. Si cette table est mise à jour par plusieurs APPL (un écran de saisie mobile, un gestionnaire maître de bureau et une application portail) parallèlement à plusieurs UBEUniversal Batch Engine, un processus de traitement par lots utilisé pour les rapports ou les mises à jour massives. batch exécutant des intégrations nocturnes, la duplication de cette logique de valeurs par défaut sur tous les points d'entrée garantit la corruption des données. Un développeur modifiant l'APPL de bureau oubliera inévitablement une affectation de valeur par défaut dans l'un des UBE d'arrière-plan, ce qui entraînera des enregistrements orphelins ou des valeurs nulles dans des colonnes critiques comme la classe GL ou le code d'explication fiscale.
L'encapsulation de cette logique de valeurs par défaut dans une Named Event Rule (NER)Langage de programmation propriétaire de JDE compilé en C pour créer de la logique métier réutilisable. dédiée réduit l'empreinte du code APPL de plus de la moitié sur les formulaires de saisie de données standard. Au lieu de maintenir des dizaines de lignes d'ER mappant les valeurs par défaut dans chaque formulaire, l'application interactive appelle simplement une seule BSFNBusiness Function, un composant logiciel réutilisable contenant une logique métier spécifique, écrit en C ou en NER. en passant la structure de données F550101 avant l'insertion. Ce changement architectural garantit une intégrité cohérente des données sur tous les canaux d'entrée et assure que tout ajustement futur des valeurs par défaut ne nécessite qu'une seule modification dans une BSFN centralisée.

Pourquoi les contraintes de base de données échouent dans JDE
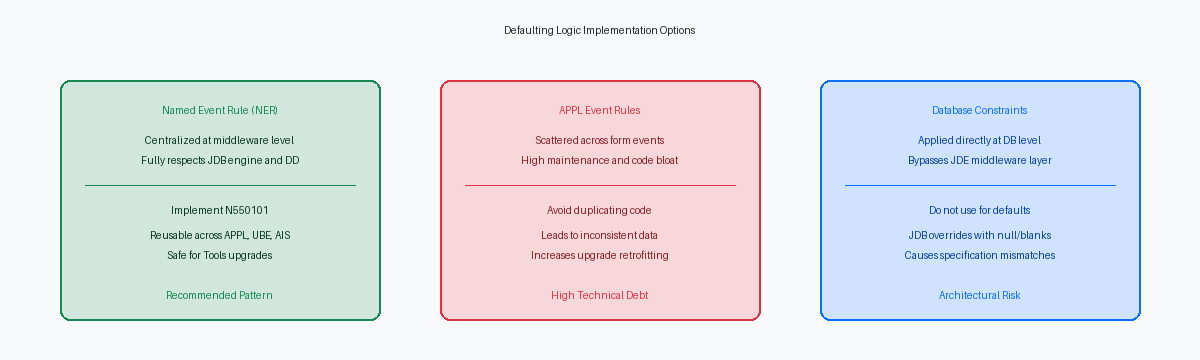
Les administrateurs de bases de données essaient souvent de contourner le développement JDE en exécutant une instruction ALTER TABLE pour appliquer une contrainte DEFAULT 'Y' sur une table personnalisée comme la F550101. Cette approche échoue immédiatement en raison de la conception du moteur middleware JDB. Lorsqu'une application ou un processus batch déclenche une insertion, la couche JDB n'omet pas les champs non mappés de l'instruction SQL. Au lieu de cela, elle construit explicitement une instruction INSERT contenant chaque colonne définie dans les Table SpecificationsDéfinition technique de la structure d'une table, incluant ses colonnes, ses index et ses propriétés de stockage.. Étant donné que le moteur JDB passe explicitement un blanc, un zéro ou un pointeur nul pour les variables non initialisées, le moteur de base de données traite cela comme une valeur explicite, écrasant complètement la contrainte par défaut au niveau de la base de données.
S'appuyer sur des contraintes au niveau de la base de données pour forcer des valeurs par défaut introduces des échecs silencieux et une dérive de configuration dans vos environnements. Lorsque vous promouvez la F550101 de DV920 à PY920 à l'aide de l'Object Management Workbench (OMW)L'outil de JD Edwards pour gérer le développement, les versions et le déploiement des objets. et que vous régénérez la table, l'outil de génération standard supprime et recrée la table physique. Ce processus efface toutes les contraintes SQL Server ou Oracle DB personnalisées. Les développeurs se demandent alors pourquoi un processus qui fonctionnait dans la base de données de développement ne parvient pas à remplir les valeurs par défaut en test ou en production.
Le modèle architectural correct consiste à appliquer les valeurs par défaut au niveau du middleware applicatif à l'aide d'une Named Event Rule. Parce qu'une NER s'exécute dans la pile d'appels standard d'EnterpriseOne — soit sur le serveur HTML, soit mappée sur un serveur d'entreprise via l'Object Configuration Manager (OCM)Le composant qui dirige l'exécution des objets vers le serveur ou la base de données appropriés. — elle respecte les règles natives du Data DictionaryRéférentiel centralisé définissant les caractéristiques, les formats et les règles de validation de tous les champs de données. de JDE et les Table SpecsSpécifications techniques définissant la structure, les colonnes et les index d'une table JD Edwards.. En interceptant les données avant qu'elles n'atteignent la couche JDB, la NER garantit que le moteur d'exécution écrit correctement et systématiquement les valeurs par défaut, que la transaction provienne d'une application interactive, d'un UBE batch ou d'une orchestration AISApplication Interface Services, interface permettant d'exposer la logique JDE à des applications externes via des services REST..
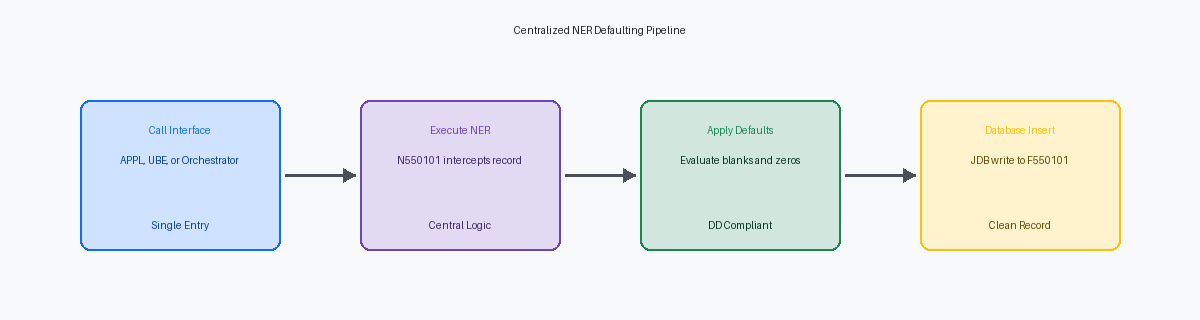
Conception d'une NER centralisée pour l'insertion en table
Déplacer la logique de valeurs par défaut des événements interactifs comme Grid Record is Fetched vers une Named Event RuleLangage de programmation propriétaire de JDE compilé en C pour créer de la logique métier réutilisable. centralisée, telle que N550101, est le seul moyen d'empêcher la corruption des données lorsque les intégrations externes contournent l'interface graphique. Lorsque vous construisez N550101 en tant que moteur dédié de validation pré-insertion et de valeurs par défaut, vous garantissez que chaque chemin d'écriture respecte les mêmes règles métier. Ce changement élimine le risque de champs d'en-tête manquants lorsque les intégrations écrivent directement dans les tables d'interface.
La base de ce modèle repose sur la structure de données associée, D550101Structure de données associée à une fonction métier, définissant ses paramètres d'entrée et de sortie., qui doit refléter les colonnes de la table personnalisée. En passant l'enregistrement complet de la table en tant que structure IN/OUT, la NER peut inspecter l'état de chaque champ et modifier les valeurs vides sur place. Si vous ne passez qu'un sous-ensemble de clés, vous finissez par écrire une logique de lecture redondante à l'intérieur de la BSFNBusiness Function, un composant logiciel réutilisable contenant une logique métier spécifique, écrit en C ou en NER., ce qui dégrade les performances lors du traitement de lots de milliers d'enregistrements.
À l'intérieur de la NERNamed Event Rule, un langage de programmation propriétaire de JDE compilé en C pour créer de la logique métier., la logique exécute une évaluation conditionnelle stricte : elle applique des valeurs par défaut comme la date système (SL DateToday) ou les Next Numbers uniquement si le paramètre entrant est vide ou égal à zéro. Par exemple, si l'appelant passe une date de transaction explicite, N550101 la respecte ; si elle est vide, la NER la remplit. Cela empêche d'écraser les saisies intentionnelles des utilisateurs par des valeurs système codées en dur lors des imports groupés par UBE.
Ce modèle de conception convertit la NER en un service centralisé accessible dans tout l'écosystème EnterpriseOne. Qu'une transaction provienne d'une application interactive P550101, d'un UBE batch R550101 ou d'un appel REST routé via l'AIS OrchestratorOutil permettant de créer des flux de travail automatisés en combinant plusieurs services et applications JD Edwards., les mêmes règles de valeurs par défaut s'appliquent. Ce point d'entrée unifié réduit considérablement votre empreinte de maintenance lors des mises à niveau de Tools Release, car vous n'avez qu'un seul objet à valider.
Analyse du code de la logique de valeurs par défaut
Dans les Event Rules de notre NERNamed Event Rule, un langage de programmation propriétaire de JDE compilé en C pour créer de la logique métier. personnalisée, la première ligne de défense est la validation de la structure de données entrante. Si un champ alphanumérique comme Company (CO) est égal à <Blank> ou si un champ numérique comme Address Number (AN8) est égal à <Zero>, la NER doit intercepter et appliquer la valeur par défaut. Nous implémentons cela à l'aide d'instructions If explicites vérifiant CO et AN8 avant toute E/S de table, empêchant la base de données de recevoir des enregistrements incomplets.
Lorsque la clé primaire de notre table personnalisée est laissée vide par le processus appelant, la NER récupère dynamiquement un identifiant unique. Nous appelons la fonction métier F0002 Get Next NumberSystème JDE générant automatiquement des numéros séquentiels uniques pour les documents ou les enregistrements de table. à l'intérieur de la NER, en passant le code système cible et l'index du numéro suivant pour remplir le champ clé. Cela garantit que même si un développeur oublie d'assigner une clé dans une APPL ou un UBE, la NER garantit l'intégrité de la base de données en générant automatiquement l'ID séquentiel suivant.
Le remplissage cohérent des champs d'audit est l'endroit où le codage manuel dans les APPL échoue souvent. Au sein de cette NERNamed Event Rule, un langage de programmation propriétaire de JDE compilé en C pour créer de la logique métier. centralisée, nous mappons explicitement les valeurs système JDE SL UserID au champ USER, SL DateToday à UPMJ, et l'heure système à TDAY. Cette conception garantit que chaque insertion, qu'elle soit initiée depuis une application interactive, un UBE batch ou une orchestration AIS externe, porte une piste d'audit identique et infalsifiable.
Pour empêcher l'application appelante de poursuivre une transaction corrompue, la NER expose un indicateur de retour, généralement EV01Type de données standard JDE utilisé pour les indicateurs booléens (0 ou 1) ou les drapeaux d'erreur. (cErrorFlag). Si une validation critique échoue — comme un code société invalide ou un échec dans la routine des numéros suivants — la NER définit cet indicateur à '1' et contourne l'insertion en table. L'APPL ou la fonction métier appelante évalue ce code de retour immédiatement après l'exécution, ce qui lui permet d'arrêter le traitement et d'annuler la transaction avant que des données invalides n'atteignent la base de données.
Simplification des APPL et modèles d'appel
Dans une application interactive typique d'extension du fichier maître client P550101, les développeurs parsèment souvent les événements "OK-Post Button Clicked" ou "Grid Record is Fetched" de dizaines de lignes de validation répétitive et d'affectations codées en dur. Le remplacement de cette logique dispersée par un appel unique à la Named Event Rule (NER)Langage de programmation propriétaire de JDE compilé en C pour créer de la logique métier réutilisable. N550101 réduit considérablement l'empreinte des Event Rules du formulaire. Pour les formulaires de type header-less detail, placer cet appel dans l'événement Write Grid Line-BeforeÉvénement JDE s'exécutant juste avant l'insertion d'une ligne de grille dans la table de la base de données. garantit que chaque ligne est traitée proprement avant d'atteindre la base de données. Pour les formulaires fix-inspect, l'événement "Add Record to DB - Before" sert de gardien optimal pour intercepter le tampon et appliquer les valeurs par défaut.
Le découplage de cette logique de la couche de présentation accélère directement les futurs cycles de mise à niveau. Lorsque vous passez de la version 9.1 à la 9.2, la comparaison et l'adaptation d'une APPL simplifiée avec des modifications minimales d'Event RulesInstructions de programmation ajoutées aux objets JDE pour définir leur comportement et leur logique métier. prennent quelques minutes au lieu de plusieurs heures. L'interface utilisateur devient un pur véhicule de saisie de données, tandis que les règles métier de base résident en toute sécurité à l'intérieur de la NER centralisée. Cette isolation évite les maux de tête courants lors des mises à niveau où les modifications de formulaires personnalisés sont écrasées ou nécessitent des fusions manuelles fastidieuses lors d'une mise à jour de Tools Release ou d'application.
Ce modèle architectural apporte des améliorations immédiates lors de l'intégration de processus batch comme l'UBEUniversal Batch Engine, un processus de traitement par lots utilisé pour les rapports ou les mises à jour massives. de téléchargement client R550101. Au lieu de dupliquer les règles de valeurs par défaut et de validation à l'intérieur de l'événement "Do Section" de l'UBE, le rapport batch appelle exactement la même BSFNBusiness Function, un composant logiciel réutilisable contenant une logique métier spécifique, écrit en C ou en NER. N550101. Qu'un enregistrement soit créé manuellement par un opérateur dans P550101 ou importé en masse via R550101 à partir d'un fichier plat externe, les mêmes valeurs par défaut de base de données sont appliquées de manière cohérente. Ce point d'entrée unifié élimine les écarts d'intégrité des données entre les saisies interactives et les interfaces batch.
Considérations de performance et de cache pour les NER par défaut
L'exécution d'une NERNamed Event Rule, un langage de programmation propriétaire de JDE compilé en C pour créer de la logique métier. personnalisée sur chaque insertion de ligne peut gravement dégrader les performances batchTraitement automatisé de gros volumes de données sans interaction humaine. si le code sous-jacent effectue des recherches en base de données non mises en cache. Pour un UBEUniversal Batch Engine, un processus de traitement par lots utilisé pour les rapports ou les mises à jour massives. à haut volume traitant des dizaines de milliers d'enregistrements, une fonction mal conçue transformera une exécution brève en un goulot d'étranglement prolongé. Pour éviter cela, votre conception doit viser un surcoût d'exécution inférieur à quelques millisecondes par insertion d'enregistrement lors du traitement en masse. Cette enveloppe de performance serrée est tout à fait réalisable si vous limitez la portée de la NER et gérez la récupération des données intelligemment.
Minimiser les allers-retours vers la base de données au sein de la NER est le moyen le plus efficace de protéger les performances du système. Au lieu d'exécuter des instructions directes de sélection ou de lecture unique sur les tables de contrôle pour chaque ligne, utilisez le JDE Service CacheMécanisme permettant de stocker des données fréquemment utilisées en mémoire pour accélérer les traitements et réduire les accès base de données. ou appelez des fonctions métier standard qui utilisent une mise en cache interne. Par exemple, lors de la validation ou de l'affectation de valeurs par défaut basées sur le centre de profit, routez la vérification via le cache de validation standard F0006 Branch/Plant plutôt que d'interroger la table physique de la base de données de manière répétée. Cela maintient les recherches dans la mémoire locale du serveur d'entreprise, réduisant le surcoût de chaque vérification à quelques microsecondes.
Gardez l'architecture de la NER simple en vous concentrant strictement sur les valeurs par défaut des données et la validation de base, en laissant la logique métier complexe aux fonctions de traitement en aval. Essayer d'exécuter des allocations d'inventaire multi-niveaux ou des vérifications de crédit à l'intérieur d'une routine de valeurs par défaut au niveau de la table est un modèle de conception qui invite aux blocages de base de données (deadlocks) et au gonflement de la pile d'appels. Si un champ nécessite des calculs conditionnels complexes, assignez une valeur par défaut de repli sûre dans la NER et laissez la Master Business FunctionFonction métier robuste regroupant toute la logique nécessaire pour valider et traiter une transaction complexe (ex: vente ou achat). suivante s'occuper du travail lourd.
La centralisation de la logique par défaut au sein d'une NER est une étape standard pour réduire un parc de code personnalisé qui dépasse souvent 5 000 à 15 000 objets. Si votre feuille de route 9.2.x.x implique des tables à haute concurrence, les articles connexes sur la gestion de la mémoire des BSFN CBusiness Function écrite en langage C, offrant des performances élevées et un accès direct aux API système de bas niveau. et les modèles de cache personnalisés fournissent la profondeur technique nécessaire pour prévenir les défaillances du noyau. Pour ceux qui gèrent des adaptations complexes, mon portefeuille de projets techniques contient des exemples spécifiques de nettoyages de personnalisation à l'échelle de l'entreprise et de stratégies d'optimisation de base de données qui ont réussi à réduire la durée des mises à niveau de plusieurs mois à seulement 6-9 semaines.
