
Chaque NER enregistré dans le Toolset finit par devenir un fichier .c généré dans votre répertoire source, pourtant de nombreux architectes les considèrent comme un juste milieu "sûr" sans tenir compte du coût d'exécution sous-jacent. La décision concernant JD Edwards NER vs BSFN et le moment d'utiliser chacun se résume souvent à un choix entre un développement rapide et une vitesse d'exécution brute. Dans les environnements à volume élevé – considérez un R42565 modifié traitant 50 000 lignes par heure – la surcharge incrémentielle de la structure de code générée par les NER et ses initialisations de variables redondantes peut gonfler une fenêtre de traitement par lots d'une marge mesurable, souvent autour de 15 %, par rapport à une implémentation C optimisée.
Bien que les NER offrent une interface lisible pour une validation simple, ils deviennent un inconvénient lors de la gestion de caches JDE complexes ou de pointeurs mémoire sur plus de 10 segments. Je rencontre régulièrement des "super-NERs" de 2 000 lignes qui sont fonctionnellement impossibles à déboguer par rapport à une BSFN C structurée utilisant des API standard comme jdeCacheFetch. Choisir le C n'est pas seulement une question de performance ; il s'agit d'accéder aux pointeurs lpBhvrCom et lpVoid que les NER ne peuvent pas atteindre, ce qui est essentiel pour les fonctions métier maîtresses personnalisées qui doivent maintenir leur état à travers des événements d'application ou d'UBE disparates.
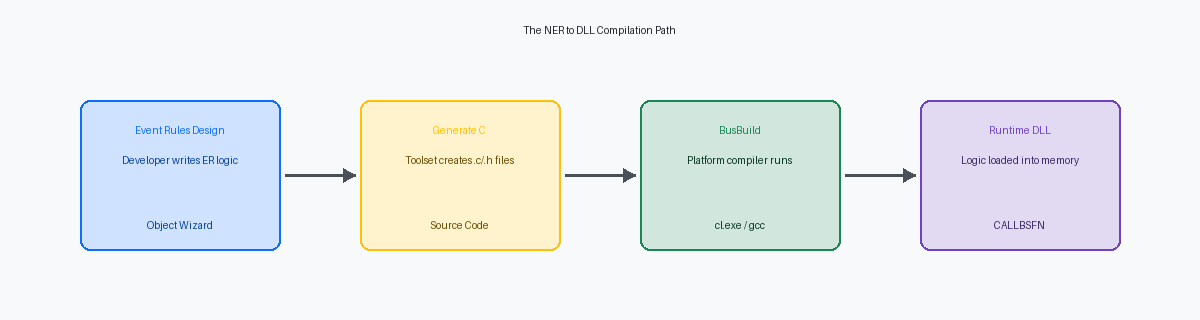
La réalité compilée des règles d'événements nommées
De nombreux développeurs traitent les règles d'événements nommées (Named Event Rules) comme une couche interprétée, mais la réalité se trouve dans les répertoires \source et \include de votre serveur de déploiement. Lorsque vous cliquez sur "Générer" dans le Toolset, JDE traduit vos règles d'événements en code C. Ce code source de fonction métier généré est ensuite alimenté dans le compilateur spécifique à la plateforme – Visual Studio pour Windows ou le compilateur approprié pour Linux – afin de produire la DLL ou la bibliothèque partagée finale. L'ouverture du fichier .c résultant pour un NER de taille moyenne révèle une sortie tentaculaire où 50 lignes de logique ER se transforment souvent en 500 lignes de code C.
Le générateur privilégie la sécurité à l'élégance, ce qui entraîne des initialisations de variables redondantes et des appels répétitifs de nettoyage d'erreurs avant chaque exécution d'API. Dans un NER complexe avec 150 variables, la surcharge liée à l'initialisation de chaque membre de la structure lpDS et des variables locales peut ajouter des millisecondes mesurables à l'exécution. Bien que négligeable pour un seul appel, cela devient un goulot d'étranglement de performance lorsque ce NER est imbriqué dans une boucle au sein d'un UBE traitant 100 000 enregistrements. Une BSFN C codée à la main contournerait cela en initialisant uniquement ce qui est nécessaire pour le chemin logique spécifique.
Les limitations fonctionnelles sont intégrées à l'éditeur NER, confinant les développeurs au sous-ensemble d'API JDE standard. Vous ne pouvez pas effectuer de manipulation directe de la mémoire ni appeler des DLL tierces externes sans passer par un wrapper C. Chaque NER est également inextricablement lié à sa structure de données (DSTR). L'ajout d'un simple indicateur nécessite de modifier la DSTR, de régénérer le fichier d'en-tête et de recompiler l'objet. Ce couplage rigide rend les NER moins agiles que les BSFN C, où les développeurs peuvent gérer des types de données variés ou internaliser les changements de logique avec beaucoup plus de fluidité que ne le permet l'éditeur ER.
Quand les BSFN C sont non négociables
L'écriture d'un algorithme de comptabilité analytique complexe impliquant des boucles récursives ou une concaténation de chaînes à haute fréquence à l'intérieur d'un NER introduit une couche d'abstraction qui dégrade les performances à grande échelle. Bien qu'un NER génère finalement un fichier .c et .h, la traduction de chaque affectation ou boucle par le moteur ER ajoute une surcharge inutile par rapport à l'arithmétique directe des pointeurs en C natif. Dans un UBE à volume élevé traitant 100 000 lignes de commandes clients, la latence cumulative de l'environnement d'exécution ER peut prolonger le temps d'exécution jusqu'à 25 % par rapport à une fonction C bien optimisée qui interagit directement avec les structures de données.
Un véritable contrôle architectural nécessite souvent l'API JDECACHE, qui est entièrement inaccessible depuis l'outil de conception NER. L'implémentation d'un cache nécessite de définir une structure C personnalisée pour mapper les clés et les attributs du cache, puis d'appeler jdeCacheInit et jdeCacheAdd en utilisant des pointeurs mémoire explicites. Les NER ne peuvent pas gérer la logique basée sur les pointeurs requise pour passer un handle entre les fonctions ou pour itérer à travers un cache à l'aide d'un curseur. Si votre exigence implique le stockage de données transactionnelles temporaires sur plusieurs appels BSFN sans accéder à la base de données physique – courant dans les Power Forms personnalisés ou le traitement EDI complexe – le C est la seule voie viable.
Les exigences d'intégration dépassent fréquemment les limites du Toolset JDE, nécessitant des appels directs à des DLL tierces externes ou à des API au niveau du système d'exploitation. Que vous invoquiez une bibliothèque cryptographique Windows spécialisée pour la signature de charge utile ou un utilitaire basé sur Linux pour la manipulation du système de fichiers, ces opérations nécessitent des déclarations typedef et des inclusions d'en-tête que l'environnement NER ne prend pas en charge. Tenter de combler ces lacunes par le biais des outils JDE standard aboutit généralement à des solutions de contournement fragiles qui augmentent la dette technique plutôt que de résoudre le problème de connectivité sous-jacent.
La gestion manuelle de la mémoire permet aux développeurs seniors d'implémenter des modèles de "Lazy Loading" (chargement paresseux) qui sont impossibles dans l'allocation mémoire automatisée d'un NER. En utilisant jdeAlloc et jdeFree délibérément, un développeur peut s'assurer que les grandes structures de données ne sont instanciées que lorsque cela est absolument nécessaire et libérées immédiatement après utilisation. Ce contrôle granulaire empêche le gonflement de la mémoire souvent observé dans le traitement par lots à grande échelle où des milliers d'instances NER pourraient autrement conserver des ressources plus longtemps que nécessaire, entraînant potentiellement un épuisement de la mémoire sur le serveur d'entreprise pendant les cycles de fin de mois de pointe.

Benchmarks de performance et surcharge d'exécution
Le traitement de 100 000 enregistrements via un téléchargement par lots R0911Z1 standard expose l'écart de performance brut entre NER et C. Lors d'un récent test de stress sur une architecture multi-tiers, une routine de validation basée sur NER a ajouté une augmentation de latence d'environ 17 % au temps d'exécution total de l'UBE par rapport à une BSFN C équivalente. Cette surcharge provient de la manière dont le moteur NER gère le mappage des variables. Chaque fois qu'un NER est appelé, le système mappe la structure de données (DSTR) aux variables ER internes, un processus significativement moins efficace que la manipulation directe des pointeurs en C.
La pénalité de performance implique un coût de commutation de contexte lorsque le moteur JDE passe de l'environnement d'exécution ER à la couche d'exécution C sous-jacente. Lorsqu'un NER appelle une API JDE standard, il enveloppe cet appel dans des couches d'abstraction. Une BSFN C exécute ces API directement, évitant cette couche de traduction. Pour un seul appel, la différence se mesure en microsecondes, mais sur une boucle de 100 000 enregistrements, ces microsecondes s'accumulent en minutes de cycles CPU gaspillés sur le serveur d'entreprise.
L'interaction directe avec la base de données offre l'avantage de performance le plus significatif pour le C. Alors que les NER s'appuient sur le wrapper d'E/S de table standard, les BSFN C utilisent directement JDB_OpenTable et JDB_Fetch. Cela permet à un développeur de spécifier uniquement les colonnes requises pour l'opération, réduisant la taille du tampon de récupération et minimisant le trafic réseau. L'E/S de table NER récupère souvent la ligne entière de la table en mémoire, une inefficacité massive lorsque vous n'avez besoin que d'un seul indicateur ou champ de date d'une table large comme F0911.
La complexité des NER atteint un plafond avec la logique récursive ou les boucles profondément imbriquées. Le code C généré par un NER est notoirement verbeux et peut entraîner des limitations de profondeur de pile. Si votre logique métier nécessite de scanner des nomenclatures multi-niveaux ou des recalculs de taxes complexes, la structure de code générée par le NER devient un goulot d'étranglement. Le déplacement de ces opérations vers une BSFN C permet une gestion de la mémoire plus propre et prévient les problèmes de débordement de pile lors du traitement de fin de mois.
Maintenabilité et écart de compétences des développeurs
Les NER agissent comme un pont, permettant aux consultants fonctionnels et aux développeurs juniors de diagnostiquer les problèmes de logique sans analyser les pointeurs ou les fichiers d'en-tête. Dans un environnement typique de 10 000 objets, une partie significative de la logique personnalisée, souvent estimée à 60 %, peut être maintenue par du personnel qui comprend le dictionnaire de données JDE mais n'a pas de formation formelle en C. Cette visibilité réduit l'effet "boîte noire" courant dans les systèmes hérités où les règles métier critiques sont enfouies dans des milliers de lignes de code.
La friction opérationnelle entre ces formats est la plus visible lors d'un scénario de panne de production. Le débogage d'un NER utilise le débogueur ER standard, un outil accessible à tout développeur disposant d'un client FAT. Inversement, le dépannage d'une BSFN C nécessite une installation locale de Visual Studio 2017 ou 2019 et la surcharge technique de l'attachement au processus actif activConsole.exe ou jdenet_n.exe. Cette exigence crée souvent un goulot d'étranglement, car de nombreuses organisations restreignent les droits d'administrateur locaux ou manquent de la licence de compilateur spécifique nécessaire pour un débogage C approfondi.
Une allocation mémoire mal gérée dans les BSFN C est la principale cause des "processus zombies" et des plantages du noyau sur le serveur d'entreprise. Un seul jdeFree() manquant ou un pointeur mal initialisé peut provoquer une fuite de mémoire à chaque exécution. Dans les environnements à volume élevé traitant 50 000 lignes par jour, ces fuites compromettent rapidement la stabilité. Les NER atténuent ce risque en déchargeant la gestion de la mémoire vers le moteur JDE, empêchant un développeur junior de faire planter un noyau par inadvertance via une simple erreur de syntaxe.
Le coût total de possession à long terme pour le code C personnalisé est plus élevé car le bassin de talents se réduit. Trouver une ressource qui comprend les nuances des API JDE – telles que jdeCallObject et la structure lpBhvrCom – tout en maintenant la sécurité de la mémoire C devient un cycle de recrutement de 6 mois. Les directeurs informatiques devraient auditer leur patrimoine personnalisé et viser une répartition 90/10 en faveur des NER ou des Orchestrations pour éviter la dépendance à un seul développeur senior.
Impact sur les cycles CNC et de construction de packages
Une construction complète de package serveur pour un environnement 9.2 typique consomme souvent 60 à 120 minutes de temps CPU sur le serveur de build. Bien que les NER et les BSFN C nécessitent ce cycle de déploiement pour déplacer la logique du référentiel de spécifications vers les répertoires bin/lib, la surcharge CNC pour les NER est discrètement plus élevée en raison de la génération de spécifications vers le code source. Si un développeur modifie une structure de données (DSTR) liée à un NER mais ne parvient pas à exécuter manuellement l'étape "Générer C", le busbuild échouera à l'étape de l'édition de liens, forçant un redémarrage du package et entraînant une perte de temps significative dans la fenêtre de maintenance.
Les BSFN C offrent un avantage stratégique pour la maintenance grâce à la portée des fonctions internes. Vous pouvez écrire une douzaine de sous-routines internes dans un seul fichier .c qui ne sont pas définies dans la DSTR. Cela vous permet de corriger un bug ou d'optimiser un calcul sans modifier l'interface publique de l'objet. Étant donné que la DSTR reste inchangée, vous évitez la chaîne de dépendances où chaque UBE ou APPL appelant nécessiterait autrement une nouvelle vérification ou une inclusion dans le package de mise à jour pour éviter les erreurs d'incompatibilité de version lors de l'exécution.
La transition vers l'architecture 64 bits dans Tools Release 9.2.5 a réduit l'écart de vitesse de compilation mais a augmenté le risque pour le code C manuel. Les NER gèrent la logique sous-jacente de la taille des pointeurs via le générateur fourni par Oracle, protégeant les développeurs des problèmes d'alignement de la mémoire. Inversement, les BSFN C nécessitent l'utilisation explicite de types de données spécifiques à JDE pour rester portables à travers le noyau d'entreprise. Un seul pointeur mal casté dans une fonction C personnalisée se manifestera comme une violation de mémoire dans les journaux du serveur d'entreprise, n'apparaissant souvent qu'après le déploiement du package et la tentative du noyau de charger la DLL.
L'approche hybride pour un JDE moderne
Une architecture mature utilise un NER comme un wrapper d'interface propre qui appelle des fonctions de travail C optimisées pour les tâches lourdes. Cela permet à la logique métier de rester visible dans le Toolset JDE tout en déchargeant les calculs complexes ou la manipulation de chaînes gourmandes en mémoire vers le C. Cette approche peut réduire considérablement le temps de débogage, atteignant souvent 40 %, car les développeurs peuvent suivre le flux de haut niveau dans le NER sans avoir besoin de parcourir 2 000 lignes de code C lourd en pointeurs.
Orchestrator cannibalise le cas d'utilisation des NER simples, en particulier pour les validations inter-fonctionnelles et les recherches de table de base. Lors d'un déploiement récent de 9.2.7, nous avons remplacé 15 NER personnalisés utilisés pour la validation des données par des Orchestrations, déplaçant ainsi efficacement cette logique hors de la couche d'application principale. Ce changement permet des modifications en temps réel sans un déploiement complet de package. En fin de compte, le choix entre NER et BSFN C est un équilibre entre l'agilité de développement et l'efficacité d'exécution ; bien que le NER reste la norme pour la visibilité, le BSFN C est requis pour un contrôle architectural de bas niveau et de haute performance.
