
De la liste brute à l’estimation : comment rendre défendable un upgrade JD Edwards
Un upgrade JD Edwards ne devrait pas commencer par une estimation. Il devrait commencer par une question beaucoup plus inconfortable : quel est réellement le périmètre à estimer ? En théorie, la réponse semble simple. On extrait les objets custom, on les compare au standard, on regarde ce qui a été modifié et on calcule le travail nécessaire pour les faire passer de la release source à la release cible. En pratique, cette séquence linéaire existe rarement. Les environnements réels contiennent des années d’interventions, des copies d’objets standard, des rapports qui ne sont plus jamais exécutés, des objets techniques, des versions modifiées, des objets créés pour des urgences depuis longtemps oubliées, des composants tiers, des personnalisations encore critiques et des personnalisations que plus personne n’utilise. Pour cette raison, l’estimation ne peut pas être la première étape : elle doit être la conséquence d’un processus de qualification.
Le point central consiste à transformer une liste bruteListe initiale, large et volontairement prudente, d’objets potentiellement pertinents pour l’upgrade. en une Suggested Object ListListe raisonnée des objets qui, après filtres et vérifications, méritent de rester dans le périmètre d’analyse ou d’estimation.. Cette transformation n’est pas un exercice de réduction numérique. On ne part pas de milliers d’objets avec l’objectif d’arriver à quelques centaines parce que « moins, c’est mieux ». On part d’une photographie large parce que, dans un assessment sérieux, perdre un objet important est plus dangereux qu’en analyser un de trop. Le filtrage sert donc à qualifier le périmètre : chaque objet doit être exclu, conservé, classifié ou réintégré pour une raison technique documentable.
Cette distinction change complètement la manière de lire le processus. Une liste initiale n’est pas encore une liste de travail. C’est une collection de candidats. Certains candidats seront confirmés, d’autres reclassifiés, d’autres encore pourront être sortis du périmètre opérationnel de l’upgrade. Mais aucune décision ne devrait être invisible. Un objet ne disparaît pas parce que quelqu’un veut réduire le nombre final. Il sort du périmètre uniquement s’il existe un critère vérifiable : par exemple parce qu’il est standard, parce qu’il appartient à une catégorie qui ne nécessite pas de retrofit applicatif, parce qu’il n’est plus utilisé, parce qu’il est traité séparément, ou parce que le client décide consciemment de ne pas l’inclure.
Pourquoi la liste initiale doit être large
La première erreur à éviter est de chercher une liste « propre » trop tôt. Dans un environnement JD Edwards mature, ce qui paraît simple peut cacher des dépendances complexes. Un rapport peut sembler custom tout en étant presque identique au standard. Une copie peut paraître anodine mais dériver d’un objet standard qu’Oracle a modifié dans la release cible. Une version batch peut sembler secondaire mais être utilisée lors de la clôture mensuelle. Un objet technique peut sembler hors périmètre, mais être nécessaire au fonctionnement d’une chaîne de processus. C’est pourquoi la phase initiale doit accepter une certaine redondance informative : mieux vaut partir large puis qualifier, plutôt que commencer trop étroitement et découvrir trop tard que des éléments pertinents ont été perdus.
Les extractionsFichiers produits à partir de l’environnement client décrivant les objets, versions, métadonnées, usages, différences et autres éléments utiles à l’assessment. reçues du client servent précisément à construire cette photographie initiale. Elles ne sont pas une simple annexe administrative : elles sont la matière première de tout le processus. Elles doivent être reçues, conservées, organisées et transformées en données exploitables sans perdre le lien avec la source d’origine. Cette séparation entre données reçues, données traitées et résultats finaux est essentielle pour la traçabilité. Si un chiffre est contesté, si un objet est réintégré, si une estimation est révisée, il doit être possible de remonter à la raison et à la source.
La liste brute n’est donc pas une erreur à corriger. C’est une phase nécessaire. Elle contient du bruit, mais elle contient aussi des signaux importants. Le travail de l’assessment consiste à distinguer les deux. La valeur ne réside pas dans la production immédiate d’une liste apparemment élégante, mais dans la construction d’un chemin qui explique clairement pourquoi certains éléments sont conservés et d’autres non.
Le filtrage n’est pas une coupe : c’est une classification
Le mot « filtrage » peut être trompeur. Il peut donner l’idée d’une coupe mécanique, presque comptable : on prend une liste, on supprime des lignes, on obtient un nombre plus petit. Dans un upgrade JD Edwards mené sérieusement, le filtrage est au contraire une classification progressive. Chaque objet est lu à travers une catégorie technique. Est-ce un objet standard ? Est-ce du custom pur ? Est-ce une modification directe d’un standard ? Est-ce une copie d’un standard ? Est-ce une version ? Est-ce un rapport batch ? Est-ce un objet qui n’est plus exécuté ? Est-ce un composant technique qui ne doit pas être estimé comme du développement applicatif ? Est-ce une anomalie à porter à l’attention du client ?
Cette classification est ce qui rend l’assessment défendable. Il ne suffit pas de dire qu’un objet a été exclu. Il faut pouvoir dire pourquoi. Il ne suffit pas de dire qu’un objet a été conservé. Il faut pouvoir expliquer quel risque il représente. Il ne suffit pas de dire qu’une copie a été identifiée. Il faut comprendre de quel standard elle dérive, si ce standard a changé, jusqu’où la copie s’est éloignée de la référence et quel travail sera nécessaire pour la porter sur la nouvelle release.
En ce sens, le filtrage ressemble davantage à une révision éditoriale qu’à un nettoyage automatique. Une révision éditoriale ne supprime pas des phrases au hasard : elle distingue ce qui est nécessaire, ce qui est redondant, ce qui est ambigu et ce qui exige une réécriture. De la même manière, le filtrage technique distingue les objets qui nécessitent un retrofit, ceux qui nécessitent une vérification, ceux qui nécessitent une décision, ceux qui ne doivent pas peser sur l’estimation et ceux qui ne peuvent pas être ignorés.
Objets standard, modifications et custom pur
L’une des premières distinctions concerne la nature de l’objet. Un objet standard pur ne doit pas être traité comme un objet custom. S’il ne contient pas de personnalisation client, il ne devrait pas peser comme activité de retrofit custom. Cela ne signifie pas que le standard est sans importance : le standard est la référence par rapport à laquelle l’impact de l’upgrade est mesuré. Mais l’estimation du travail custom doit se concentrer sur ce que le client a réellement modifié, copié, étendu ou créé.
Le cas des modifications directes d’objets standard est différent. Ici, le problème est immédiat : si le standard Oracle change dans la release cible, la personnalisation client doit être réinterprétée dans le nouveau contexte. Il ne s’agit pas seulement de déplacer du code ou des configurations d’un environnement à un autre. Il s’agit de comprendre si la modification client est encore valable, si elle entre en conflit avec le nouveau standard, si elle peut être supprimée parce qu’elle a été absorbée par la release cible, ou si elle doit être réécrite pour coexister avec le nouveau comportement.
Le custom purObjet créé par le client ou pour le client, pas nécessairement dérivé d’un objet standard Oracle. pose un autre type de problème. S’il est réellement indépendant du standard, il peut ne pas nécessiter de comparaison directe avec un objet Oracle source. Mais cela ne le rend pas automatiquement simple. Il peut dépendre de tables, fonctions, business views, data structures, processing options ou logiques qui changent entre les releases. Il peut compiler sans erreur mais produire des résultats différents. Il peut être techniquement valide mais fonctionnellement obsolète. Pour cette raison, le custom pur doit lui aussi être qualifié, pas seulement compté.
Le cas le plus délicat : les copies des standards
Les copies d’objets standard figurent souvent parmi les objets les plus critiques dans un upgrade JD Edwards. Une copie n’est pas un doublon et ce n’est pas un objet à écarter : c’est un objet custom qui conserve une relation technique avec un objet standard Oracle, le fameux based-onL’objet standard Oracle dont dérive une copie custom ou par rapport auquel elle doit être comparée.. Cette relation est au cœur du problème. Si une copie dérive d’un standard, son destin ne dépend pas seulement de ce que le client a fait sur la copie, mais aussi de ce qu’Oracle a fait sur le standard dans la nouvelle release.
Quand Oracle modifie l’objet standard dans la release cible, la copie ne peut pas être traitée comme si elle vivait isolément. Si la copie client est substantiellement identique au standard de départ, le travail peut être relativement simple : il peut être nécessaire de la recréer ou de la réaligner à partir du nouveau standard. Mais même dans ce cas, elle n’est pas écartée. Elle est classifiée comme copie à faible divergence, c’est-à-dire comme un objet qui peut être simple à gérer mais qui doit tout de même suivre le bon parcours.
Le vrai problème apparaît lorsque les deux lignes d’évolution ont bougé. D’un côté, Oracle a modifié le based-on dans la release cible ; de l’autre, le client a modifié la copie dans son propre environnement. À ce moment-là, l’upgrade devient un exercice de réconciliation entre deux histoires différentes du même objet. Il faut comprendre quelles modifications Oracle sont importantes, quelles personnalisations client doivent être préservées, quelles parties sont obsolètes, quelles parties entrent en conflit et quelle est la manière la plus sûre de reconstruire l’objet final. C’est là qu’une copie peut devenir beaucoup plus difficile qu’un custom pur.
C’est la raison pour laquelle les copies des standards ne devraient jamais être traitées comme des doublons. Une copie n’est pas une ligne à supprimer pour alléger la liste. C’est une catégorie d’analyse. Dans certains cas elle sera simple, dans d’autres elle sera complexe, dans d’autres encore elle nécessitera une comparaison très détaillée. Mais le critère n’est jamais « c’est une copie, donc on l’écarte ». Le bon critère est : c’est une copie, donc il faut identifier le based-on, mesurer l’écart, vérifier l’évolution du standard et estimer le travail de recomposition.
Ce sujet mérite un approfondissement autonome, car il implique des techniques de comparaison, de similarité, de structure, de nomenclature et de connaissance fonctionnelle. Pour une explication spécifique de l’identification des copies standard dans JD Edwards, on peut se référer à l’article Copies of JD Edwards Standards: how I identify them.
Last Run Date : quand l’usage réel entre dans l’assessment
Un autre critère crucial est la Last Run DateDate de dernière exécution connue d’un rapport ou d’une version batch. Elle est utilisée comme indicateur d’usage réel, non comme vérité absolue., souvent abrégée en LRD. Cette donnée introduit une dimension que la seule comparaison technique ne peut pas fournir : l’usage réel. Un objet peut être custom, techniquement valide et historiquement important, mais s’il n’a pas été exécuté depuis longtemps, il est raisonnable de se demander s’il doit encore entrer dans le périmètre opérationnel de l’upgrade.
Dans le cas des rapports batch et des versions, la Last Run Date est un indicateur particulièrement utile. En termes JD Edwards, la donnée de dernière exécution d’une version batch est normalement associée à la Versions List, c’est-à-dire à la table F983051Table JD Edwards des versions. Le champ VRVED est couramment utilisé comme Date - Last Executed pour les versions batch., en particulier au champ VRVEDChamp indiqué comme Date - Last Executed ; il représente la date de dernière exécution de la version.. L’historique des jobs soumis peut également fournir des informations utiles, par exemple à travers la logique des submitted jobs et de la table F986110Job Control Status Master : table qui conserve les enregistrements de statut des jobs soumis aux files.. Toutefois, ces données doivent être lues avec prudence : l’historique peut être affecté par des purges, des politiques de rétention, des configurations et des comportements différents selon les environnements.
Dans le processus d’assessment, un seuil pratique peut être celui des 18 mois. Si un rapport ne semble pas avoir été exécuté depuis plus de 18 mois, il peut devenir candidat à l’exclusion du périmètre opérationnel de l’upgrade. Le mot important est « candidat ». Cela ne signifie pas que le rapport est automatiquement supprimé, ignoré ou déclaré inutile. Cela signifie que la donnée d’usage ouvre une question : ce rapport sert-il encore ? A-t-il été remplacé ? Est-il exécuté manuellement de manière rare mais critique ? Est-il utilisé uniquement en clôture annuelle ? Est-il lancé par un autre processus qui ne met pas correctement à jour la date attendue ? Est-ce un objet d’urgence que le métier souhaite conserver ?
Cette prudence est essentielle. Un critère basé sur la LRD ne doit pas devenir une guillotine. Il doit devenir une conversation technique et fonctionnelle. Si un rapport ne tourne plus depuis deux ans et que personne ne sait plus à quoi il sert, il est raisonnable de ne pas le faire peser comme objet pleinement opérationnel. Si, au contraire, il ne tourne plus depuis deux ans parce qu’il est utilisé uniquement dans des scénarios exceptionnels mais réglementairement importants, la discussion change. La Last Run Date ne prend pas la décision à la place de l’analyste : elle rend visible une question qui resterait sinon cachée.
Le seuil des 18 mois n’est pas une vérité mathématique
Le seuil des 18 mois est utile parce qu’il oblige à distinguer les objets encore vivants des objets probablement dormants. Mais il ne doit pas être présenté comme une vérité mathématique. Dans certains contextes, un rapport non exécuté depuis 18 mois peut être sans importance. Dans d’autres, il peut être rare mais indispensable. Un processus annuel, une obligation fiscale, un contrôle d’audit ou une fonction d’urgence peuvent avoir une faible fréquence et une grande importance. C’est pourquoi le critère temporel doit être combiné avec la connaissance métier.
La bonne manière d’utiliser la LRD consiste à l’insérer dans une matrice de décision. Un rapport custom récent entre fortement dans le périmètre. Un rapport ancien, non exécuté et non reconnu par le métier peut être candidat à l’exclusion. Un rapport ancien mais confirmé par le client reste. Un rapport sans Last Run Date fiable nécessite une vérification supplémentaire. Dans tous les cas, la décision doit rester traçable.
C’est aussi un point important dans la relation avec le client. Dire « nous n’estimons pas ce rapport parce qu’il ne tourne plus depuis 18 mois » est trop faible. Dire « ce rapport est candidat à l’exclusion parce que la Last Run Date indique une absence d’usage récent ; nous demandons une confirmation fonctionnelle avant de le retirer du périmètre opérationnel » est beaucoup plus solide. Dans le premier cas, on impose une coupe. Dans le second, on construit une décision partagée.
Objets techniques, administratifs et anomalies
Tous les objets qui apparaissent dans la liste initiale ne doivent pas être traités comme du développement applicatif à rétrofiter. Certains appartiennent à des catégories techniques ou administratives qui exigent un traitement différent. Il peut s’agir d’éléments liés à des configurations, versions, métadonnées, structures de support ou composants qui ne représentent pas une modification applicative au sens traditionnel. Les inclure sans distinction dans l’estimation risque de gonfler le périmètre et de brouiller le travail réellement nécessaire.
Cela ne signifie pas que ces objets sont sans importance. Cela signifie qu’ils doivent être séparés. Un objet technique peut ne pas nécessiter de retrofit, mais nécessiter un contrôle. Une version peut ne pas être un programme, mais contenir des processing options, des data selections ou des paramètres opérationnels pertinents. Une anomalie peut ne pas se transformer immédiatement en heures de développement, mais indiquer un risque à clarifier avant de poursuivre. La qualité de l’assessment réside précisément dans la capacité à distinguer le travail de développement du travail de vérification, de configuration, de décision ou de nettoyage.
Les anomalies méritent un traitement spécifique. Dans un processus mature, elles ne doivent pas être cachées. Un objet sans correspondance claire, une copie avec based-on incertain, une version associée à un rapport peu clair, un enregistrement incohérent, un nom ambigu ou une information manquante ne devraient pas être forcés dans une catégorie uniquement pour fermer la liste. Ils doivent être mis en évidence. Parfois l’anomalie se résout par un contrôle technique. Parfois elle exige l’implication du client. Parfois elle devient une note dans l’estimation. Dans tous les cas, une liste avec des avertissements explicites vaut mieux qu’une liste apparemment propre mais construite sur des décisions non documentées.
Réintégrations manuelles : quand le jugement technique prévaut sur le filtre
Un bon processus de filtrage ne doit pas être aveugle. Les filtres sont nécessaires, mais ils ne doivent pas remplacer le jugement technique. Il existe des cas où un objet pourrait sembler excluable selon un critère automatique, mais doit être réintégré parce que l’analyste reconnaît un risque, une dépendance ou une particularité. C’est particulièrement vrai dans les systèmes JD Edwards avec de nombreuses années d’historique, où les conventions locales, les noms non standard et les solutions de projet peuvent rendre toute règle automatique imparfaite.
La réintégration manuelle n’est pas un échec de la méthode. C’est une composante nécessaire. Un assessment entièrement automatique peut être rapide, mais il risque d’être fragile. Un assessment technique sérieux combine règles, données et jugement. Le but n’est pas d’éliminer l’intervention humaine ; c’est de la rendre traçable. Si un objet est réintégré, la raison doit être claire. S’il est exclu malgré un avertissement, il doit être clair qui a pris la décision et sur quelle base.
Cet équilibre entre automatisation et responsabilité est l’une des différences entre une liste produite par un outil et un véritable processus d’upgrade assessment. L’outil peut accélérer, comparer, mettre en évidence, agréger, mesurer. Mais la valeur finale naît lorsque les résultats sont interprétés dans le contexte du client et de la release cible.
Ce que montrent les données historiques
Pour rendre la méthode concrète, il est utile d’observer un échantillon historique anonymisé composé de 54 runs d’assessment. L’échantillon contient 358,046 objets dans la liste brute initiale. Après la phase de qualification, la Suggested Object ListListe des objets qui restent dans le périmètre technique suggéré après exclusions, vérifications et classifications. contient 145,773 objets, tandis que 212,269 objets sont exclus ou sortis du périmètre opérationnel de l’upgrade.
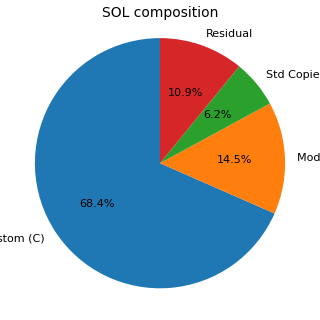
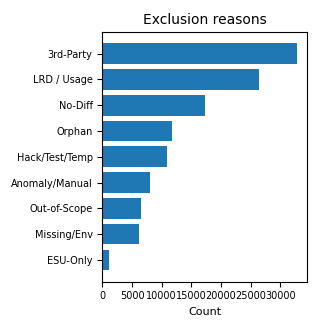
Dans le premier graphique, la catégorie Residual indique la partie de la Suggested Object List non couverte par les trois catégories C, M et Y présentées dans le résumé agrégé. Dans le second graphique, les raisons d’exclusion sont représentées par un graphique en barres parce que les catégories ne sont pas exclusives et ne peuvent donc pas être correctement représentées comme les parts d’un seul camembert.
| Indicateur | Valeur agrégée | Lecture de la donnée |
|---|---|---|
| Runs analysés | 54 | Assessments avec détail disponible et reliable au résumé. |
| Objets dans la liste brute | 358,046 | Périmètre initial volontairement large. |
| Objets dans la Suggested Object List | 145,773 (40.7%) | Objets restés dans le périmètre technique suggéré. |
| Objets exclus | 212,269 (59.3%) | Objets retirés du périmètre opérationnel après application des critères de filtrage. |
| Custom pur dans la SOL | 99,733 | Objets classifiés comme custom. |
| Standards modifiés dans la SOL | 21,145 | Objets standard modifiés par le client et conservés dans le périmètre. |
| Copies de standards dans la SOL | 8,989 (6.2% de la SOL) | Objets de type copie standard, à traiter comme catégorie critique et non comme doublons. |
| Objets exclus avant classification | 212,188 | Objets sortis du périmètre avant qu’il soit nécessaire d’établir le type de modification. |
| Standards modifiés exclus comme no-diff | 17,036 | Objets initialement classifiés comme modifiés, mais ensuite trouvés alignés avec le standard. |
| UBE/UBEVER dans la liste brute | 69,567 | Rapports et versions batch présents dans le périmètre initial. |
| UBE/UBEVER dans la SOL | 30,337 | Rapports et versions batch conservés dans le périmètre suggéré. |
| UBE/UBEVER exclus | 39,229 (56.4% des UBE/UBEVER bruts) | Rapports et versions batch exclus ou candidats à l’exclusion après qualification. |
| Exclusions LRD / usage non récent | 26,328 | Objets exclus avec une motivation liée à la Last Run Date ou à l’absence d’usage récent. |
| Exclusions no-diff | 17,297 | Objets exclus parce qu’ils ne présentent pas de différences pertinentes par rapport au standard. |
| Exclusions tiers | 32,896 | Objets rattachables à des composants hors du périmètre custom du client. |
| Hack, test ou temporaires | 10,852 | Objets exclus parce qu’ils sont liés à des tests, contournements temporaires ou éléments non structurels. |
| Orphelins | 11,676 | Objets identifiés comme n’étant plus reliés à un usage opérationnel clair. |
| ESU-only | 1,162 | Objets exclus parce qu’ils relèvent de logiques de mise à jour standard déjà couvertes par le chemin de release. |
| Missing / environment | 6,098 | Objets dont l’exclusion dépend de conditions d’environnement ou de données absentes. |
| Hors périmètre projet | 6,482 | Objets non pertinents pour le périmètre opérationnel de l’assessment. |
| Anomalies / revue manuelle | 8,079 | Cas nécessitant attention, confirmation ou jugement technique. |
| Exclus sans raison explicite | 89,300 | Contrôle qualité de la donnée : lignes exclues sans raison lisible dans le champ commentaires. |
Note méthodologique. Les catégories d’exclusion sont des flags non mutuellement exclusifs : un même objet peut avoir plusieurs raisons documentées, par exemple être un objet de test, un objet tiers et porter une indication LRD. Pour cette raison, les lignes relatives aux raisons d’exclusion ne doivent pas être additionnées entre elles. La donnée agrégée montre le poids des critères, non une répartition exclusive.
Ces chiffres rendent visible la valeur du filtrage. Dans l’échantillon historique, environ 59.3% des objets initiaux n’atteignent pas la Suggested Object List. Ce chiffre ne doit pas être lu comme une simple « réduction » : il doit être lu comme le résultat d’une classification technique. La liste brute capture tout ce qui pourrait être pertinent ; la liste suggérée conserve ce qui mérite d’être discuté, analysé ou estimé. Parmi ces objets restent près de 8,989 copies de standards, ce qui confirme un point essentiel : les copies ne sont pas traitées comme des déchets, mais comme une catégorie critique du retrofit.
La donnée sur les UBE et les versions batch est tout aussi significative. Sur 69,567 rapports ou versions présents dans le périmètre initial, 30,337 restent dans la liste suggérée et 39,229 sortent du périmètre opérationnel. Une partie importante de ces exclusions est liée à la LRD ou à des critères d’usage non récent. Ici encore, le chiffre ne remplace pas le jugement : un rapport rare peut être critique, mais un rapport non exécuté depuis des années doit au moins être questionné avant de peser dans l’estimation.
Enfin, la donnée sur les objets no-diff montre pourquoi il ne suffit pas de faire confiance à la classification initiale. Dans l’échantillon, 17,036 objets sont initialement rattachables à la catégorie des standards modifiés, puis exclus parce qu’ils ne présentent pas de différences pertinentes. C’est l’un des passages qui empêchent l’estimation de gonfler artificiellement : un objet qui semble modifié ne doit pas peser comme retrofit si la comparaison démontre qu’il est en réalité aligné avec le standard.
De la Suggested Object List à l’estimation
Ce n’est qu’après la phase de qualification qu’il devient raisonnable d’estimer. La Suggested Object List n’est pas le point final : c’est le point où l’estimation peut commencer sérieusement. À ce stade, les objets ne sont plus de simples noms. Ce sont des éléments classifiés : custom pur, modification d’un standard, copie de standard, rapport batch avec usage récent, rapport batch candidat à l’exclusion, version avec override, objet technique, anomalie, composant à vérifier, élément à discuter avec le client.
L’estimation doit partir de cette classification. Un custom pur, une modification directe d’un standard et une copie de standard n’ont pas le même profil de risque. Une copie presque identique au based-on et une copie fortement divergente ne demandent pas le même effort. Un rapport utilisé hier et un rapport non exécuté depuis des années n’ont pas le même poids opérationnel. Un objet avec anomalies ne peut pas être estimé comme s’il était parfaitement clair. L’estimation ne doit pas être une moyenne générique appliquée à une liste : elle doit être une évaluation dérivée de la nature de l’objet.
Dans cette seconde phase, chaque objet est traduit en travail potentiel. On ne demande plus seulement « qu’est-ce que c’est ? », mais « que faut-il faire pour le porter correctement sur la release cible ? ». La réponse peut inclure recompilation, comparaison, retrofit, reconstruction à partir du nouveau standard, vérification fonctionnelle, tests, adaptation des processing options, contrôle de data selection, analyse des dépendances ou simple confirmation d’exclusion. L’estimation devient ainsi le résultat d’une chaîne : données initiales, filtres, classification, décisions, effort.
Pourquoi une estimation sans filtrage est dangereuse
Estimer directement la liste brute est dangereux pour deux raisons opposées. La première est la surestimation. Si des objets standard, objets non utilisés, éléments techniques non applicatifs ou rapports dormants restent dans la liste, le client reçoit une estimation alourdie par du travail qui pourrait ne pas être nécessaire. Cela peut rendre le projet plus coûteux, plus difficile à approuver et moins transparent.
La seconde raison est la sous-estimation. Si les copies des standards sont lues comme de simples doublons, si les modifications directes des standards sont traitées comme du custom ordinaire, si les anomalies sont ignorées, l’estimation peut paraître plus légère mais devenir fragile. Le risque apparaît plus tard, lorsque le projet a déjà commencé et que les objets les plus complexes commencent à demander du temps non prévu.
Le filtrage sert à éviter ces deux erreurs. Ce n’est pas un mécanisme pour baisser l’estimation. C’est un mécanisme pour la rendre proportionnée. Il retire du poids là où le travail n’existe pas, mais ajoute de l’attention là où le risque est réel. C’est le point le plus important à communiquer au client : la réduction du périmètre n’est pas un raccourci, c’est une forme de précision.
La traçabilité comme valeur de la méthode
Un assessment d’upgrade ne produit pas seulement des chiffres. Il produit des décisions. Chaque exclusion, inclusion, réintégration ou classification est une décision. Si ces décisions ne sont pas tracées, l’estimation finale devient difficile à défendre. Si elles sont documentées, le client peut comprendre non seulement combien de travail est prévu, mais aussi pourquoi.
La traçabilité est importante aussi pour l’équipe projet. Lorsque l’upgrade entre en phase d’exécution, les personnes qui travaillent sur les objets doivent savoir d’où vient la classification. Elles doivent comprendre si un objet a été considéré comme copie, si le based-on est certain ou probable, si la Last Run Date a influencé la décision, si un rapport a été exclu sur confirmation du client, si un avertissement est resté ouvert. Sans cette mémoire, l’assessment risque de devenir un document statique. Avec cette mémoire, il devient un outil opérationnel.
La traçabilité sert aussi à gérer les révisions. Une estimation peut changer. Un client peut réintégrer un rapport. Un objet initialement considéré comme simple peut se révéler complexe. Une copie peut montrer un écart plus important que prévu. Si le processus est tracé, la révision est compréhensible. S’il ne l’est pas, chaque changement semble arbitraire.
Le rôle du client dans la validation du périmètre
Le client ne devrait pas recevoir la Suggested Object List comme un verdict. Il devrait la recevoir comme un périmètre technique à valider. L’équipe technique peut dire qu’un rapport ne semble pas avoir été exécuté depuis plus de 18 mois, mais seul le client peut confirmer si ce rapport est réellement abandonné. L’équipe technique peut identifier une copie et mesurer son écart, mais la connaissance fonctionnelle est souvent nécessaire pour comprendre quelles modifications sont encore pertinentes. L’équipe technique peut signaler une anomalie, mais le client peut savoir que cette anomalie correspond à une ancienne procédure, à un contournement ou à une personnalisation critique.
La qualité de l’upgrade dépend donc aussi de la manière dont le périmètre est discuté. Un assessment ne devrait pas produire une liste fermée en isolation. Il devrait produire une liste motivée, accompagnée de critères, notes, avertissements et questions. Ainsi, le client n’est pas obligé de faire confiance à un chiffre : il peut voir le chemin qui a produit ce chiffre.
C’est particulièrement important dans les projets où la pression économique est forte. Une liste trop grande fait peur. Une liste trop petite crée du risque. Une liste défendable permet une discussion rationnelle : quels objets sont certainement dans le périmètre, lesquels sont candidats à l’exclusion, lesquels demandent confirmation, lesquels sont techniquement critiques, lesquels sont fonctionnellement sensibles.
De la donnée technique à la décision de projet
La valeur finale de la procédure n’est pas seulement technique. Elle est décisionnelle. Un upgrade JD Edwards est un projet où le risque naît souvent de l’incertitude : ne pas savoir combien d’objets sont réellement concernés, ne pas savoir quelles copies sont critiques, ne pas savoir quels rapports sont encore utilisés, ne pas savoir si une estimation inclut des objets inutiles ou en exclut d’importants. La procédure réduit cette incertitude en transformant des informations dispersées en décisions visibles.
Cela ne signifie pas éliminer toute marge de doute. Dans un système complexe, le doute ne disparaît pas. Il est géré. Certains objets resteront avec des notes. Certaines décisions nécessiteront confirmation. Certaines estimations auront des marges. Certaines copies nécessiteront une analyse plus profonde. Mais une marge déclarée est très différente d’une marge cachée. La première peut être discutée. La seconde explose pendant le projet.
En ce sens, la procédure d’upgrade assessment n’est pas simplement une manière de produire une estimation. C’est une manière de construire la confiance. Confiance dans le fait que le périmètre n’est pas arbitraire. Confiance dans le fait que les objets critiques n’ont pas été simplifiés. Confiance dans le fait que les rapports non utilisés ont été traités avec méthode. Confiance dans le fait que les copies des standards ont été comprises pour ce qu’elles sont : souvent le point le plus délicat du retrofit.
Conclusion : l’upgrade comme réduction de l’incertitude
Un upgrade JD Edwards n’est pas seulement un passage technique d’une release à une autre. C’est un exercice de réduction de l’incertitude. Au début, il y a une masse d’objets potentiellement pertinents. À la fin, il doit y avoir un périmètre explicable, une liste suggérée, une estimation proportionnée et une série de décisions traçables. Le travail le plus important se situe précisément au milieu, dans la phase où la liste brute est transformée en connaissance.
Le filtrage est le cœur de ce processus, mais seulement s’il est compris correctement. Il ne sert pas à supprimer des lignes. Il sert à distinguer. Les objets standard ne doivent pas être confondus avec du custom. Les rapports non utilisés depuis plus de 18 mois peuvent être candidats à l’exclusion, mais pas supprimés sans jugement. Les anomalies doivent être mises en évidence, non cachées. Les réintégrations manuelles font partie de la méthode, ce ne sont pas des exceptions embarrassantes. Et les copies des standards ne sont pas des doublons : ce sont souvent les objets les plus délicats, parce qu’elles obligent à comparer l’évolution du client avec l’évolution du standard Oracle.
Ce n’est que lorsque ce travail a été fait que l’estimation devient crédible. Non parce qu’elle est parfaite, mais parce qu’elle est explicable. Et dans un upgrade complexe, une estimation explicable vaut beaucoup plus qu’une estimation apparemment précise mais dépourvue de mémoire technique.
