"Data Dictionary Item Not Found" est l'erreur qui fait dérailler le plus vite une journée JD Edwards. Les utilisateurs voient un Visual Assist cassé, un champ numérique rendu comme du texte, ou un Find-Browse qui ne renvoie rien alors qu'il renvoyait des lignes la veille — et le premier réflexe de la moitié des tickets de support que j'ai vus est d'accuser l'application, alors que la cause réelle se trouve presque toujours une couche plus bas : une entrée Data DictionaryLa couche de métadonnées JDE qui définit chaque data item (alias, longueur, décimales, glossaire, règles d'édition). Elle contrôle la façon dont chaque formulaire, BSFN et UBE interprète les colonnes sous-jacentes. qui ne correspond plus à ce que l'une des quatre couches de cache au-dessus d'elle a gardé en mémoire.
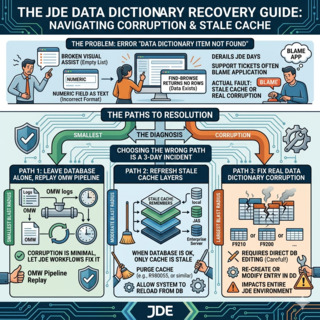
Ce guide décrit la procédure que j'utilise pour corriger les erreurs JD Edwards Data Dictionary lorsque la corruption est réelle, lorsqu'il ne s'agit que d'un cache obsolète, et lorsque le chemin le plus sûr consiste à laisser la base de données tranquille et à laisser le pipeline OMWObject Management Workbench : la console JDE qui suit le check-out, le check-in, la promotion et l'historique d'audit de chaque changement d'objet, y compris les items Data Dictionary. rejouer le changement. Les trois chemins ont des périmètres d'impact très différents, et le mauvais choix transforme une correction de 10 minutes en incident de 3 jours.
Pourquoi la hiérarchie de cache est presque toujours la vraie coupable
Avant de toucher une seule ligne dans F9200 ou F9210, intégrez ceci : JDE recherche un data item à travers quatre à cinq couches de cache successives, et n'importe laquelle d'entre elles peut contenir une copie obsolète de la définition alors que toutes les autres couches sont correctes. L'erreur vue par l'utilisateur est identique, que la corruption soit dans la base de données ou simplement dans un cache à vider.

Le fat client, lorsqu'il existe encore, met en cache les entrées DD localement dans les fichiers de specs du poste de travail. Le HTML ServerLe serveur web Java qui fournit l'interface web JDE EnterpriseOne. Il conserve des caches en mémoire, par utilisateur et par environnement, pour les métadonnées fréquemment utilisées, y compris les items Data Dictionary. conserve un cache JVM en mémoire, rafraîchi paresseusement. L'Enterprise ServerLe backend en C qui exécute les Call Object kernels, les UBE kernels et d'autres processus serveur. Son cache DD est conservé dans la mémoire de processus de chaque kernel et est indépendant du cache du HTML Server. conserve son propre cache dans chaque Call Object kernel — et oui, chaque kernel a sa propre copie, ce qui explique pourquoi deux utilisateurs exécutant le même formulaire peuvent observer des comportements différents. En dessous se trouvent les tables de specs par path code, puis les tables master centrales F9200 (Data Item Master), F9202 (alpha description), F9203 (traductions) et F9210 (Data Item Specifications).
La règle pratique : dans environ 70 à 80 % des tickets de « corruption Data Dictionary » sur lesquels j'ai travaillé, rien n'était corrompu. Un changement DD avait été promu, mais l'une des couches de cache au-dessus n'avait pas été rafraîchie, et l'application lisait simplement une ancienne définition. Vider les caches dans le bon ordre résout le problème en moins de 10 minutes et ne touche pas la base de données.
Les 20 à 30 % restants sont de vraies corruptions : une ligne absente de F9210 alors qu'elle existe dans F9200, une traduction obsolète dans F9203 pour un code langue qui n'est plus actif, ou une collision de clé primaire après une restauration échouée. Ces cas nécessitent des corrections chirurgicales, et c'est là que les sections suivantes comptent.
Les trois chemins de réparation et quand choisir chacun
Une fois que vous confirmez que le problème est reproductible entre utilisateurs et environnements — ce qui signifie qu'il ne s'agit pas simplement d'un cache obsolète isolé — vous avez trois options. La tentation est toujours de passer directement à SQL, et c'est presque toujours le mauvais choix.

Cache clear via Server Manager est toujours la première chose à essayer. Ouvrez Server Manager, choisissez l'instance HTML Server cible, allez dans Runtime Metrics et videz le cache Data Dictionary. Faites ensuite la même chose sur chaque logic kernel de l'Enterprise Server qui sert les utilisateurs affectés. L'opération entière prend 5 à 10 minutes et ne modifie aucune ligne dans la base de données. Si le symptôme disparaît, la corruption n'était jamais réelle — c'était une incohérence de cache — et c'est terminé.
P92001 (Data Dictionary Design) est l'application JDE standard pour gérer les items DD. Si le vidage du cache n'a pas aidé, ouvrez P92001 sur l'alias concerné, vérifiez que la définition correspond à ce que l'application attend, et si nécessaire réenregistrez l'item. P92001 écrit dans F9200/F9210, propage vers les tables de specs, et le changement devient partie intégrante de l'audit trail OMW. C'est le seul chemin de réparation qui survit proprement à un upgrade ou à un retrofit ESU, car il laisse un enregistrement traçable de qui a changé quoi et quand.
Direct SQL contre F9200/F9210/F9202/F9203 est le dernier recours. Vous ne l'utilisez que lorsque P92001 refuse d'opérer sur la ligne — typiquement à cause d'un enregistrement orphelin, d'un doublon qui ne devrait pas exister, ou d'une violation de clé primaire. La chirurgie SQL exige une sauvegarde complète des quatre tables avant de commencer, une validation du DBA et de l'équipe CNC, et un rapport d'intégrité immédiatement après. Du point de vue de JDE, elle n'est pas auditable : le changement ne laisse aucune trace OMW, aucun historique de version, aucun bouton de rollback.
Les requêtes de diagnostic qui disent ce qui ne va vraiment pas
Avant de décider quel chemin prendre, exécutez les quatre requêtes qui localisent la corruption. Elles prennent quelques secondes et économisent des heures de conjectures.
D'abord, confirmez que le data item existe dans F9200 (master) et F9210 (specifications) :
SELECT FRDTAI, FRDSCR, FRSY FROM F9200 WHERE FRDTAI = 'YOUR_ALIAS';
SELECT FROMDTAI, FROOWTP, FROODA FROM F9210 WHERE FROMDTAI = 'YOUR_ALIAS';Si F9200 renvoie une ligne mais F9210 n'en renvoie aucune, vous avez un orphelin classique : le master existe, les spécifications n'existent pas, et chaque formulaire qui référence l'alias échouera. L'inverse — F9210 sans F9200 — est plus rare mais pire, car le compilateur de specs a quelque chose contre quoi compiler, mais l'application ne peut jamais trouver le master.
Ensuite, vérifiez les alpha descriptions dans F9202 et les traductions dans F9203 pour les langues utilisées par le site :
SELECT FRLNGP, FRALPH FROM F9202 WHERE FRDTAI = 'YOUR_ALIAS';
SELECT FRLNGP, FRALPH FROM F9203 WHERE FRDTAI = 'YOUR_ALIAS';Une ligne F9203 manquante pour la langue active d'un utilisateur est la cause la plus fréquente des plaintes de « libellé vide » — le champ a une description en anglais mais pas en italien, et les utilisateurs italiens voient un en-tête vide. Ce n'est presque jamais de la « corruption » ; c'est une traduction qui n'a jamais été créée.
Troisièmement, comparez le master avec les tables de specs centrales pour le path code actif. Les tables de specs résident dans la data source spécifique au path code (DD910, DV920, PY920, PD920 selon la release et le path code) et sont alimentées par le processus de package build. Si F9210 indique decimals = 2 et que la table de specs indique decimals = 0, l'application lit la table de specs — le master en base est correct, les specs compilées sont incorrectes, et vous avez besoin d'un partial package build de l'item DD affecté, pas d'une correction de base de données.
Quatrièmement, exécutez R9202 (Data Dictionary Repair) en mode select sur l'alias pour obtenir un rapport généré par JDE sur l'intégrité des quatre tables. R9202 signale les orphelins, les traductions manquantes et les définitions incohérentes dans une seule sortie, formatée comme Oracle Support s'attendra à la voir si vous escaladez.
Ordre de cache clear : se tromper gaspille l'opération
Si vous décidez que le problème est le cache, l'ordre des opérations compte. Vider le cache de l'Enterprise Server avant celui du HTML Server signifie que le HTML Server peut repeupler le cache de l'Enterprise Server avec ses propres données obsolètes lors de la requête utilisateur suivante. La séquence correcte est top-down : d'abord les fat clients s'il y en a, puis HTML Server, puis les kernels de l'Enterprise Server, puis vérification que les tables de specs sont à jour.
Sur le HTML Server, Server Manager expose « Clear Data Dictionary Cache » sous les Runtime Metrics de l'instance JAS. Cela vide le cache JVM en mémoire sans redémarrer la JVM, donc les utilisateurs en sessions actives ne sont pas interrompus. La prochaine recherche DD effectuée par n'importe quel utilisateur récupère une copie fraîche depuis la couche inférieure.
Sur l'Enterprise Server, le cache vit dans la mémoire de processus de chaque Call Object kernel. Le vider exige soit de redémarrer le kernel (ce qui interrompt les appels en cours), soit d'utiliser l'interface de commande runtime du kernel via Server Manager. En pratique, sur un environnement chargé, l'approche la plus propre est un redémarrage rolling des Call Object kernels — arrêter une fraction à la fois, laisser le load balancer rediriger, répéter. L'opération entière sur une configuration de 16 kernels prend environ 8 à 12 minutes et reste invisible pour les utilisateurs.
Les tables de specs (DD3xxxnn-style central spec store) sont mises à jour pendant les package builds. Si un changement DD a été promu mais qu'aucun package build n'a été lancé, les tables de specs sont obsolètes et aucun vidage de cache n'aide — les kernels lisent un cache correct depuis des specs incorrectes. Un partial package build de l'item DD affecté, typiquement 5 à 15 minutes selon la taille de l'environnement, est la correction.
Quand SQL est inévitable, la procédure sûre
La chirurgie SQL sur les tables F92xx n'est justifiée que lorsque P92001 refuse de corriger la ligne et que le rapport d'intégrité confirme un véritable orphelin ou doublon. La procédure est la suivante :
Étape un, sauvegarde complète des tables F9200, F9202, F9203, F9210 dans la data source affectée, avec la date dans le nom de la sauvegarde. Pas un export logique — une copie CREATE TABLE AS SELECT qui vous permet de faire ensuite des comparaisons ligne par ligne. Sauter cette étape est la façon dont une correction de 20 minutes devient une restauration depuis bande.
Étape deux, identifier chaque ligne touchée par le changement à venir. Si vous supprimez un orphelin de F9210, recherchez toutes les lignes liées dans F9202, F9203 et les tables de specs qui référencent le même alias. Une correction propre supprime les lignes liées dans une seule transaction ; laisser des résidus dans F9203 signifie que la prochaine requête utilisateur sur cet alias rencontrera une erreur différente.
Étape trois, le DML dans une transaction avec rollback explicite en cas d'erreur. Pour une ligne F9210 orpheline sans master F9200, la forme sûre est :
BEGIN;
DELETE FROM F9210 WHERE FROMDTAI = 'ORPHAN_ALIAS'
AND NOT EXISTS (SELECT 1 FROM F9200 WHERE FRDTAI = 'ORPHAN_ALIAS');
-- verify row count matches expectation before commit
COMMIT;Étape quatre, exécutez de nouveau R9202. Le rapport doit maintenant revenir propre pour l'alias affecté. S'il signale encore un problème, restaurez depuis la sauvegarde et escaladez — vous avez rencontré quelque chose que la simple suppression ne corrige pas.
Étape cinq, videz les caches top-down (HTML, Enterprise, répéter) et reconstruisez l'item DD affecté dans les tables de specs via un partial package build. Sans cela, la base de données est maintenant correcte, mais les kernels continuent de lire l'ancien état cassé depuis leur propre cache.
Étape six, documentez la correction dans le journal de changement CNC avec l'alias, le SQL exécuté, les nombres de lignes avant et après, et la sortie du rapport d'intégrité. La chirurgie SQL n'est pas auditable depuis OMW, donc le seul audit trail que vous avez est celui que vous écrivez.
Les erreurs qui transforment une correction de 10 minutes en incident de 3 jours
La première erreur est de sauter le cache clear et de passer directement à SQL. Environ 75 % du temps, l'erreur visible par l'utilisateur n'était jamais une corruption de base de données — c'était un kernel lisant un cache obsolète. La chirurgie SQL dans cette situation n'aide pas, vous laisse avec un changement non auditable à investiguer plus tard, et risque d'introduire une vraie corruption par-dessus un non-problème.
La deuxième est de vider les caches dans le mauvais ordre. Vider d'abord le cache de l'Enterprise Server puis laisser le HTML Server le rafraîchir avec sa propre copie obsolète est une façon classique de passer une heure à se demander pourquoi rien n'a changé. Top-down est la règle, à chaque fois.
La troisième est d'appliquer le changement en PD sans le rejouer d'abord en DV et PY. Même une correction d'urgence devrait être appliquée en DV, vérifiée, puis promue via PY vers PD avec un projet OMW suivi — ou au minimum, le script SQL de replay devrait être réexécuté contre PY et DV une fois PD stable. Laisser les environnements désynchronisés transforme le prochain upgrade ou refresh en chasse aux écarts.
La quatrième est d'oublier que les items DD sont référencés par alias dans du code C compilé à l'intérieur des BSFNs. Si vous changez la taille ou les décimales d'un item DD sans reconstruire chaque BSFN qui l'utilise, le runtime voit une incompatibilité entre la structure C et la nouvelle définition DD. Cette incompatibilité peut provoquer des erreurs runtime dures dans le Call Object kernel — pas aussi dramatiques que certains anciens articles aiment le prétendre, mais réelles, et seulement corrigées par un rebuild BSFN complet des B-objects affectés.
La cinquième est de traiter la corruption F9203 comme un problème de base de données. La plupart des tickets de « traduction manquante » ne sont pas du tout de la corruption — ce sont des lignes de traduction qui n'ont simplement jamais été créées pour le code langue de l'utilisateur. La correction est une mise à jour P92001 avec la traduction manquante, pas une réparation SQL contre F9203.
Si ce niveau de détail opérationnel est ce dont vous avez besoin pour votre travail quotidien JD Edwards CNC et base de données, les articles liés sur ce site couvrent les modèles de projet OMW, les internes de package build et les optimisations côté SQL sur les tables standard JDE. Le portfolio de projets montre où ces techniques ont été appliquées à de vrais travaux de support production.
