
"Comment appeler JD Edwards" est la question que je reçois le plus souvent de la part des équipes qui construisent quelque chose qui touche l'ERP depuis l'extérieur — un flux Power Automate, un script Python pour la réconciliation nocturne, un front-end React pour le personnel d'entrepôt. En 2026, la réponse n'est plus "écrire un wrapper BSFN custom" : c'est AISApplication Interface Services : la passerelle REST fournie avec JD Edwards EnterpriseOne qui expose les services de formulaires, de données et d'orchestration via HTTP. et RESTRepresentational State Transfer : le style architectural basé sur HTTP utilisé par AIS, où chaque requête est stateless et porte sa propre authentification., et le choix que vous faites entre form services, data services et orchestrations détermine si votre intégration survivra à la prochaine Tools Release.
Voici le guide pratique de l'intégration JD Edwards AIS REST — comment le cycle de vie de l'appel fonctionne réellement, quand choisir chaque type d'appel, comment l'authentification et les session tokens se comportent en production, et les modes de défaillance qui rattrapent les intégrateurs au bout de six mois.
Pourquoi AIS a remplacé tout ce qui l'a précédé
Avant AIS, intégrer JD Edwards signifiait choisir l'une de trois options douloureuses : écrire un wrapper BSFNBusiness Function : code C compilé qui s'exécute dans le kernel JDE Call Object et expose la logique métier JDE aux appelants internes. custom et l'appeler via le protocole propriétaire JDENet, construire une interface flat-file Z-file, ou utiliser l'ancienne couche XML Interop que personne n'aime toucher. Les trois couplaient fortement le système externe aux internals JDE, et les trois cassaient lors des mises à niveau de Tools Release environ tous les 18 mois.
AIS, livré comme serveur Java standalone depuis Tools 9.2, expose trois familles d'endpoints REST : des form services qui pilotent une APPL comme le ferait un utilisateur, des data services qui lisent ou écrivent directement dans les tables et business views, et des orchestration services qui regroupent une séquence d'étapes dans un endpoint stable. Chacun résout un problème d'intégration différent, et choisir le mauvais est la cause la plus fréquente des intégrations qui fonctionnent en DV et s'effondrent en PD.
Le gain n'est pas seulement la modernité du protocole. AIS se situe en dehors du cycle de build du path code : une nouvelle orchestration passe en production sans server package, et le même endpoint s'exécute sur DV, PY et PD en changeant une seule entrée de configuration. Pour les organisations qui exploitent JDE en multi-site, cela suffit à justifier le coût de migration depuis les anciens styles d'interop.
Le cycle de vie d'un appel AIS, étape par étape
Chaque appel AIS suit le même parcours en cinq étapes, que vous lisiez l'inventaire ou que vous lanciez une sales order orchestration :
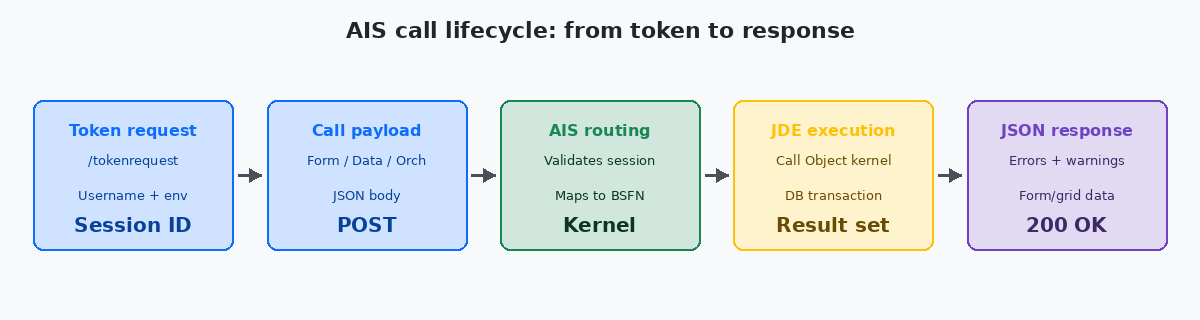
La première étape est la demande de token. Votre client effectue un POST vers /jderest/v2/tokenrequest avec username, password, environment et role. Le serveur AIS valide la sécurité JDE, ouvre une session Call Object pour votre compte et renvoie un session token (`jasToken`) plus le bloc userInfo. Ce token est valable pendant le timeout de session configuré — généralement 30 minutes d'inactivité — et représente un véritable slot kernel sur l'enterprise server. Traitez-le comme une ressource coûteuse : ne demandez jamais un nouveau token à chaque appel.
La deuxième étape est le payload de l'appel. Effectuez un POST vers /jderest/v2/formservice, /jderest/v2/dataservice, ou /jderest/v2/orchestrator/<name>. Le body est en JSON, la structure dépend du type d'appel, et le session token va dans le body, pas dans un header, pour les endpoints v2. L'erreur la plus fréquente au début est d'envoyer le token dans Authorization: Bearer, ce que l'API v2 ignore silencieusement.
La troisième étape est le routage AIS. Le serveur valide le token, mappe la requête vers un kernel Call Object et transmet l'appel via le runtime JDE standard — le même que celui utilisé par les sessions HTML Server. À partir de là, l'appel est indiscernable d'une transaction pilotée par un utilisateur : mêmes record locks, mêmes processing options, mêmes event rules déclenchées.
La quatrième étape est l'exécution JDE. Le kernel exécute la chaîne de business functions, atteint la base de données via JDBNET et assemble le résultat. C'est là que se consomme la majeure partie du temps réel — généralement 100–800 ms pour un seul appel form service sur un environnement sain, plus longtemps si l'APPL sous-jacente a une logique de fetch lourde ou si vous touchez une table très sollicitée comme F4211 pendant la clôture mensuelle.
La cinquième étape est la réponse JSON. AIS enveloppe la sortie du kernel dans une enveloppe stable : form data, grid rows, errors, warnings et un session token rafraîchi. Lisez toujours les tableaux errors et warnings même avec HTTP 200 — JDE renvoie les erreurs métier (stock insuffisant, format de date invalide) dans un body 200 OK, pas sous forme de codes d'erreur HTTP.
Choisir entre form, data et orchestration services
La plus grande décision d'architecture dans toute intégration AIS est de choisir lequel des trois types d'appel utiliser. Ils semblent interchangeables dans la première démo, mais ils ne le sont absolument pas en production.

Form services pilotent une APPL existante exactement comme le ferait un utilisateur. Vous spécifiez le formulaire (par exemple P4210_W4210A), l'action (Find, Add, Update) et les valeurs des champs. AIS exécute littéralement les event rules du formulaire de bout en bout. L'avantage est que toute la validation, les processing options et la logique événementielle que vous avez construites dans l'APPL s'exécutent automatiquement. L'inconvénient est que votre intégration casse dès que quelqu'un change le nom d'un contrôle de formulaire, réordonne une colonne de grid ou ajoute un champ obligatoire. Utilisez les form services pour des portages ponctuels d'interfaces legacy qui imitaient déjà les workflows utilisateur, pas pour de nouvelles intégrations.
Data services lisent ou écrivent directement dans une table ou une business view, en contournant entièrement la couche APPL. Ils sont rapides — généralement 30–80 ms par appel — et ignorent les event rules, ce qui est à la fois une fonctionnalité et un piège. Pour les intégrations de reporting en lecture seule, ils sont parfaits. Pour les écritures, ils sont dangereux : un insert data service dans F4211 ne déclenche pas la chaîne d'événements du sales order, donc votre NER custom qui maintient une table custom d'engagements ne s'exécute jamais, et trois semaines plus tard la finance demande pourquoi les engagements ne sont pas synchronisés.
Orchestrations sont le choix par défaut pour toute intégration non triviale en 2026. Vous les construisez dans Orchestrator Studio, les versionnez comme du code et les exposez comme endpoints REST nommés. Une orchestration peut regrouper un appel form service, une lookup data service, une notification et une étape Groovy custom dans une seule unité transactionnelle. Lorsque l'APPL sous-jacente change, l'orchestration absorbe le changement — le contrat de votre appelant externe reste stable. Toute nouvelle intégration devrait partir d'une orchestration, sauf raison spécifique de ne pas le faire.
Authentification, session tokens et le coût de l'erreur
L'authentification AIS est simple une fois que vous comprenez que le session token représente une vraie session, consommatrice de ressources, sur l'enterprise server. Chaque token maintient ouvert un slot kernel Call Object. Si vous construisez un client qui demande un token frais à chaque appel et ne se déconnecte jamais, vous épuiserez le pool de kernels. Sur un environnement 9.2 typique avec la configuration kernel par défaut, vous disposez de 50 à 200 kernels Call Object concurrents — épuisez-les et chaque utilisateur JDE, web client inclus, commencera à voir des erreurs "no available kernel".
Le bon pattern est le suivant : acquérir un token par processus, le réutiliser pendant toute la durée du travail, et appeler /jderest/v2/tokenrequest/logout une fois terminé. Pour les services long-running, rafraîchissez le token avant le timeout d'inactivité (généralement 30 minutes) en effectuant n'importe quel appel léger. AIS prend aussi en charge un pattern de session poolable où plusieurs tâches courtes partagent un token — approprié lorsque votre intégration est une fonction serverless susceptible de s'exécuter des centaines de fois par heure.
L'intégration OAuth 2.0 avec AIS existe, mais ce n'est pas un repas gratuit. AIS a toujours besoin d'un utilisateur JDE derrière chaque appel — OAuth amène votre utilisateur externe jusqu'à la passerelle AIS, mais AIS mappe ensuite cette identité vers un utilisateur JDE via le mapping basé sur les rôles défini dans Server Manager. Si le mapping est incorrect, votre utilisateur authentifié par OAuth s'exécute avec le mauvais rôle JDE et échoue à l'autorisation ou, pire, réussit avec des privilèges élevés. La table de mapping est l'artefact de sécurité le plus négligé dans les déploiements AIS.
Les service accounts sont la réalité pratique des intégrations système à système. Créez un utilisateur JDE dédié (pas un compte personnel) pour chaque système externe, limitez son rôle exactement à ce dont ce système a besoin, et faites tourner son mot de passe via Server Manager tous les 90 jours. Ne partagez jamais un service account entre deux intégrations — lorsque l'une d'elles est compromise ou génère du bruit d'audit, vous devez pouvoir désactiver uniquement celle-là.
Structure du payload, gestion des erreurs et ce qu'AIS ne vous dit pas
Le payload JSON des appels AIS est verbeux. Un appel form service à P4210 avec cinq valeurs de champs représente environ 1–2 Ko de JSON ; un fetch data service qui renvoie 200 lignes de grid représente 50–150 Ko. La majeure partie du volume correspond à des métadonnées structurelles, pas à des données métier. Pour les intégrations à fort volume, mesurez la taille réelle du payload par rapport à votre capacité réseau — un site distant sur un WAN à 10 Mbps qui exécute 30 fetches de grid par seconde saturera le lien bien avant que le serveur AIS ne ressente une quelconque charge.
La gestion des erreurs est l'endroit où la plupart des intégrations AIS sont silencieusement cassées. HTTP 200 ne signifie pas succès. Analysez toujours les tableaux warnings et errors dans le body de réponse. Un pattern typique : un ajout de sales order renvoie 200 OK avec un tableau errors vide mais un tableau warnings non vide contenant "Item not stocked at branch" — la commande a été créée, mais avec un statut qui nécessite une revue manuelle. Traiter 200 comme un succès et jeter le body fait perdre complètement ce signal. De même, AIS renvoie HTTP 400 pour les requêtes malformées mais HTTP 200 avec errors renseigné pour les violations de règles métier. Les deux doivent être gérés, dans des chemins de code différents.
L'enveloppe de réponse change entre les endpoints v1 et v2. v1 (encore présente sur les anciennes Tools Releases) enveloppe les données de grid dans fs_FORMNAME.data.gridData.rowset; v2 aplatit cela en formOutput et gridData. Mélanger les deux dans le même client est la plus grande source de bugs du type "ça marchait hier". Choisissez explicitement une version dans la configuration de votre client AIS et conservez-la pour toutes les intégrations sur le même environnement.
Les types de champs méritent une attention particulière. AIS renvoie les dates en Julian JDE (CYYDDD) ou en ISO selon l'endpoint et les paramètres de data dictionary du formulaire. Les champs numériques peuvent revenir sous forme de chaînes si le data item sous-jacent a des décimales — JDE les stocke comme des entiers et la décimale implicite vit dans le data dictionary, pas dans la donnée. Votre client doit réappliquer le positionnement décimal du data dictionary, sinon vous signalerez silencieusement des valeurs fausses de 100x ou 1000x.
Les erreurs qui cassent les intégrations AIS en production
Le premier mode de défaillance consiste à traiter AIS comme s'il s'agissait d'une web API stateless. Il est de style REST, mais le runtime JDE sous-jacent est profondément stateful : locks, processing options mises en cache par session, caches au niveau BSFN. Deux appels parallèles avec le même token peuvent entrer en collision d'une manière que deux appels parallèles vers un service REST stateless ne peuvent pas. Pour les intégrations concurrentes, utilisez un pool de tokens (un par worker) ou sérialisez les appels par business key.
Le deuxième consiste à ignorer le rythme auquel AIS transmet les appels au kernel. Le serveur AIS lui-même peut accepter des milliers de requêtes HTTP par seconde, mais chaque appel transmis consomme un slot kernel pendant toute la durée de la transaction JDE. Si votre intégration pousse 200 sales orders par seconde via un form service qui prend 600 ms chacun, vous avez besoin de 120 kernels concurrents rien que pour cette intégration — probablement plus que ce que possède tout l'environnement. Mesurez le throughput end-to-end par rapport à la capacité kernel réelle, pas par rapport à la couche HTTP AIS.
Le troisième consiste à construire des orchestrations qui appellent des form services en interne au lieu d'utiliser des data services ou des BSFN custom pour les parties qui n'ont pas besoin de logique APPL. Un appel form service dans une orchestration transporte tout l'overhead des event rules — 300–500 ms minimum — même quand tout ce qu'il fallait était une lecture de 30 ms. Pour les orchestrations qui s'exécutent des milliers de fois par heure, mélanger correctement les types d'appel fait la différence entre un temps d'exécution total de 8 secondes et un de 80 secondes.
Le quatrième consiste à laisser les orchestrations sans version. Orchestrator Studio prend en charge les versions pour une raison : une fois qu'une orchestration est consommée par un système externe, son contrat de requête et de réponse fait partie de votre API. La modifier en place sans incrémenter la version est la façon de casser tous les consommateurs downstream en même temps. Traitez les versions d'orchestration comme vous traitez les signatures BSFN.
Si ce niveau de détail est ce dont vous avez besoin pour votre travail d'intégration actuel, les articles associés de ce site couvrent les patterns Orchestrator Studio, la mesure des performances BSFN et les optimisations côté SQL qui accompagnent les lectures AIS à fort volume. Le portfolio de projets montre où ces techniques ont été appliquées à de vrais projets d'intégration ERP.
