La question la plus difficile à traiter sur toute installation JDE mature est l’une des plus simples à poser : "si je modifie cette table, quelle application custom casse ?" Cartographier les dépendances des business views dans les applications custom JD Edwards EnterpriseOne est la discipline qui transforme cette question d’un exercice forensic de plusieurs jours en une requête qui répond en quelques secondes. La plupart des installations comptent entre 80 et 400 business views custom superposées à des tables standard et custom, appelées par un nombre inconnu d’applications, d’UBEs et de formulaires — et personne ne dispose d’une vue actuelle de ce qui dépend de quoi.
Le coût de cette ignorance se paie à chaque changement. Une colonne ajoutée à F4211. Un nouvel index sur F0911. Une table custom renommée lors d’un nettoyage. Chaque changement se propage à toutes les business views qui référencent l’objet affecté, et chaque BV affecte chaque application construite au-dessus d’elle. Sans cartographie, l’impact est découvert lorsque quelque chose casse en PY, ou pire, en PD.
Pourquoi les business views sont le bon point d’ancrage de la cartographie
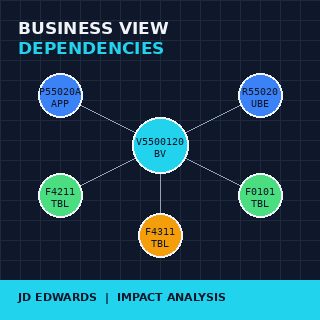
Une business view dans JDE n’est pas une vue de base de données. C’est un objet de métadonnées qui sélectionne des colonnes dans une ou plusieurs tables, définit des jointures entre elles, et expose le résultat comme un jeu de données rectangulaire unique auquel les formulaires, applications et UBEs se lient. La BV se situe entre les tables et le code, ce qui explique précisément pourquoi elle est le bon nœud pour ancrer toute cartographie de dépendances.
S’ancrer uniquement sur les tables produit du bruit — toutes les applications lisent des tables, directement ou indirectement, et le graphe résultant est trop dense pour être utile. S’ancrer sur les applications produit des lacunes — les applications appellent des BVs qui joignent plusieurs tables, et une question au niveau table traitée par une cartographie uniquement applicative perd en fidélité. La BV est le point de jonction naturel : elle sait quelles tables elle touche et elle est connue de chaque appelant situé au-dessus.
Côté upstream, chaque BV déclare ses tables sources dans la spec, enregistrée dans la table repository F98711Table de métadonnées des colonnes de business views — la table repository JDE qui enregistre quelles colonnes de quelles tables chaque business view expose, avec les définitions de jointure.. Côté downstream, chaque formulaire, application et UBE qui utilise une BV enregistre la relation dans F9860 avec un source type qui identifie le consommateur. Deux requêtes SQL correctement jointes produisent le graphe complet de toute l’installation.
L’autre raison d’ancrer la cartographie sur les BVs est qu’elles changent moins souvent que le code qui les utilise. Une BV avec vingt consommateurs peut être modifiée une fois par an ; les vingt applications au-dessus d’elle peuvent être touchées vingt fois sur la même période. Une cartographie construite sur la couche stable conserve son exactitude plus longtemps entre deux cycles de régénération.
Les tables repository qui contiennent la vérité
Le repository JDE — les métadonnées de chaque objet de l’installation — vit dans un petit ensemble de tables système, en lecture seule du point de vue du développeur et systématiquement sous-utilisées pour l’analyse. Les quatre tables importantes pour la cartographie des dépendances sont F9860, F98711, F98712 et F98750.
F9860 est le master Object Librarian. Chaque BSFN, application, UBE, business view et table y possède une ligne, avec OBNM (object name), FUNO (function use, qui identifie le type) et SRCTYPE (source type, qui distingue BV, APPL, UBE et TBL). Une simple requête sur F9860 filtrée sur les valeurs FUNO des business views renvoie la liste complète des BVs de l’installation ; filtrée sur les applications, elle renvoie la liste complète des formulaires au-dessus. Les valeurs de filtre sont documentées dans les définitions de tables standard et ne changent pas entre Tools Releases.
F98711 est la table de jointure au niveau colonne pour les business views. Chaque colonne qu’une BV expose correspond à une ligne, avec la table source et le champ source. L’agrégation de F98711 par nom de BV donne l’empreinte complète de chaque vue au niveau table — exactement ce dont le côté upstream de la cartographie des dépendances a besoin.
F98712 enregistre les sections de formulaires et de rapports qui se lient à une BV. Une application custom qui appelle trois BVs différentes à travers ses formulaires produit trois lignes dans F98712, indexées par nom d’application et nom de BV. C’est le côté downstream : quels appelants utilisent quelles vues.
F98750 est le magasin de données des specs dans les Tools Releases modernes — le contenu binaire des specs y est stocké, indexé par objet. Pour la cartographie des dépendances, F98750 n’est généralement pas la source principale, car les métadonnées lisibles se trouvent déjà dans les trois autres tables ; F98750 devient pertinente uniquement lorsqu’il faut poursuivre des détails au niveau spec que les tables de métadonnées ont aplatis.
Construire le graphe : de l’extraction SQL à une structure navigable
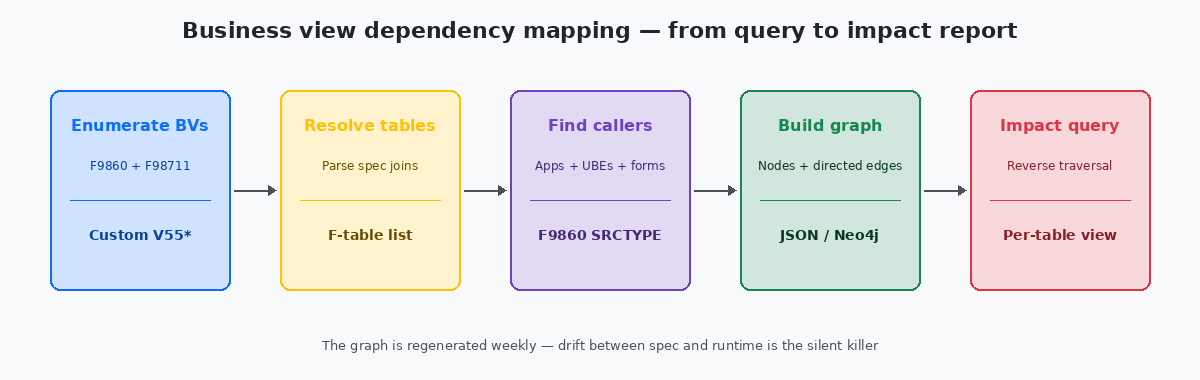
La partie mécanique de la cartographie est simple et régulièrement surcompliquée. Trois requêtes SQL sur le repository, exécutées en séquence, produisent tout ce qui est nécessaire à un graphe de dépendances complet pour une installation de toute taille.
La première requête énumère chaque business view custom — filtrée par préfixe de nom, généralement V55 à V59 dans les installations qui suivent la convention d’espace de noms réservée d’Oracle. La sortie est une liste plate avec le nom de la BV, sa description et son horodatage de dernière modification. Dans une installation typique de taille moyenne, cela renvoie 80 à 300 lignes en moins d’une seconde.
La deuxième requête résout chaque BV vers ses tables sources. Joindre F9860 à F98711 par OBNM et grouper par BV plus nom de table source produit une liste many-to-one — une ligne par relation BV-table. Une BV qui joint F4211 et F4101 produit deux lignes. Une BV qui touche huit tables en produit huit. Le volume total sur une installation réelle est généralement de 200 à 1 500 lignes.
La troisième requête trouve chaque appelant pour chaque BV en lisant F98712 et en rejoignant à nouveau F9860 pour enrichir l’appelant avec son type et sa description. C’est la plus grande des trois sorties, car une BV populaire peut avoir vingt ou trente appelants ; les volumes totaux peuvent atteindre plusieurs milliers de lignes sur les grandes installations, mais restent triviaux pour toute base de données moderne.
Les trois jeux de résultats deviennent les arêtes d’un graphe orienté : les tables pointent vers les BVs, les BVs pointent vers les appelants. Stocké en JSON, le graphe tient dans quelques centaines de kilo-octets et peut être chargé dans n’importe quel outil de visualisation, de Neo4jUne base de données graphe largement utilisée pour les analyses de dépendances, de réseaux et de relations. Stocke nativement les nœuds et les arêtes orientées, et répond aux requêtes d’accessibilité avec des instructions Cypher uniques. jusqu’à une page HTML statique avec une bibliothèque de layout force-directed. La visualisation compte moins que la structure sous-jacente — le même JSON répond aussi bien aux requêtes programmatiques qu’aux requêtes visuelles.
Les requêtes d’impact qui justifient l’effort
Un graphe de dépendances qui n’est jamais interrogé est du théâtre documentaire. Les requêtes qui justifient sa construction sont celles qui répondent aux vraies questions que les développeurs et les équipes CNC posent sous pression.
La première requête d’impact est une traversée inverse depuis une table : si F4211 va recevoir une colonne au prochain sprint, lister chaque BV custom qui la sélectionne, puis lister chaque appelant pour chaque BV. La réponse pilote le plan de tests de régression. Sur un graphe avec 200 BVs et 2 000 appelants, cette requête répond en quelques dizaines de millisecondes et produit une liste exhaustive d’une manière qu’aucun tableur n’a jamais pu garantir.
La deuxième requête d’impact est une traversée avant depuis une application : si la custom P55020A va être dépréciée, lister chaque BV qu’elle utilise, puis vérifier pour chaque BV si un autre appelant en dépend. Les vues sans autre consommateur deviennent elles-mêmes candidates à la dépréciation, et la chaîne continue jusqu’aux tables que plus rien ne lit. C’est la requête qui pilote le nettoyage de dette technique — les candidats apparaissent d’eux-mêmes une fois le graphe disponible.
La troisième requête est la détection des orphelins. Les BVs custom dans F9860 qui ont zéro ligne dans F98712 sont des orphelines — elles existent dans le repository mais rien ne les appelle. Les tables custom qu’aucune BV ne sélectionne sont des orphelines plus profondes. Sur une installation de 20 ans, les taux d’orphelins se situent généralement entre 5% et 15% du parc custom, et chaque orphelin est du code mort qui doit tout de même être transporté à travers chaque upgrade. Les faire apparaître est le premier usage pratique du graphe sur la plupart des installations.

Garder la cartographie fiable : cadence de régénération et dérive
Le mode de défaillance unique de toute cartographie de dépendances est l’obsolescence. Un graphe généré une seule fois au début d’un projet et jamais actualisé devient faux en quelques semaines — chaque check-in dans OMW qui ajoute ou modifie une BV crée un delta que le graphe statique ignore. La discipline qui garde la cartographie fiable est une régénération automatisée selon une cadence que l’équipe suit réellement.
La cadence qui fonctionne dans la plupart des installations est hebdomadaire. Un job planifié — script shell, petite UBE ou script Python connecté à la base JDE — exécute les trois requêtes repository, construit le JSON, archive la version précédente et publie le nouveau graphe à l’emplacement utilisé par l’équipe. Une cadence hebdomadaire est assez fréquente pour que la cartographie n’ait jamais plus de quelques jours de retard sur la réalité, et assez espacée pour que le job ne devienne pas du bruit.
Le diff entre deux snapshots consécutifs est plus utile que n’importe quel snapshot isolé. Les nouvelles BVs apparues cette semaine, les BVs dont les tables sources ont changé, les BVs qui ont gagné ou perdu des appelants — ce sont les éléments à faire remonter dans la revue hebdomadaire de l’équipe. Une BV qui gagne soudain une cinquième table dans sa jointure est une opportunité de code review ; une BV qui a perdu son dernier appelant restant est une candidate à la suppression. Le diff représente vingt lignes de script et transforme le graphe d’un document de référence en boucle de feedback sur ce que l’équipe construit réellement.
Pour approfondir le contexte, les articles liés sur le retrofit des copies de standard, le cadrage des upgrades Tools Release et les stratégies d’archivage des tables F couvrent la couche opérationnelle sur laquelle repose cette cartographie. Le portefeuille de projets techniques de ce site documente deux outils de dépendance en production qui ont produit les modèles décrits ici.