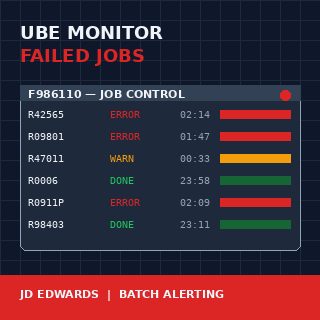
Un moniteur de jobs batch JD Edwards EnterpriseOne pour les rapports UBE échoués fait partie de ces développements qui se rentabilisent dès le premier mois et continuent à rapporter à chaque clôture trimestrielle. La console Server Manager vous indiquera qu’un job s’est terminé en erreur, mais elle ne réveillera personne pour autant, et elle ne vous dira pas que le traitement de confirmation R42565 a échoué pour la troisième nuit consécutive à 02:14. Lorsque le responsable d’entrepôt appelle à 7 h du matin pour demander pourquoi aucun pick slip n’a été imprimé, les données ont déjà quatre heures de retard et la matinée est déjà perdue.
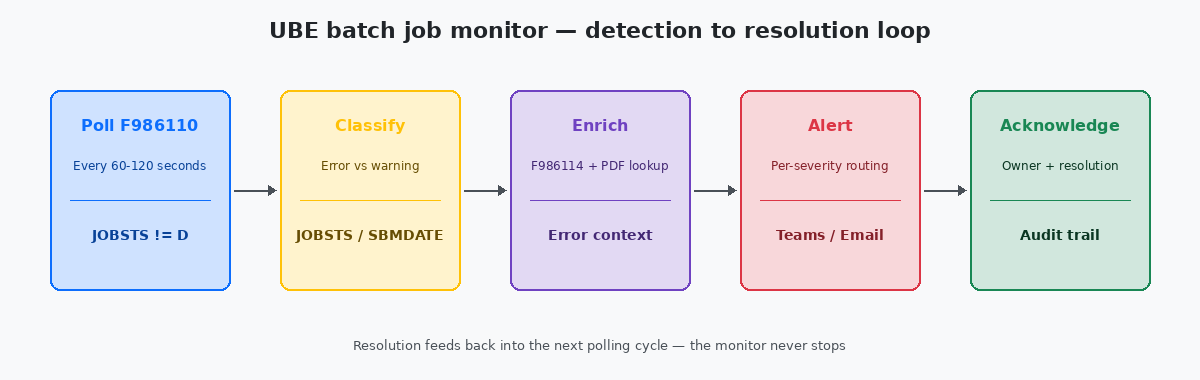
Toute installation JDE mature avec laquelle j’ai travaillé finit par construire l’un de ces moniteurs. Ceux qui fonctionnent partagent trois propriétés : ils interrogent F986110Job Control Master — la table JDE qui enregistre chaque soumission UBE, son code de statut, ses heures de début et de fin, ainsi que le serveur sur lequel elle s’est exécutée. à une cadence serrée, ils classent les erreurs par impact, et ils routent les alertes vers les canaux correspondant à leur sévérité. Ceux qui échouent sont généralement limités aux e-mails, déclenchent une alerte pour tout, et sont mis en sourdine par l’équipe d’exploitation en moins de six semaines.
Ce que "failed" signifie réellement dans F986110
Le Job Control Master est la source de vérité unique pour l’exécution batch dans JDE E1. Chaque soumission UBE y écrit une ligne, identifiée par JOBNBR, avec une colonne JOBSTS qui passe par un petit ensemble de valeurs à caractère unique : W (en attente), P (en cours de traitement), D (terminé), E (erreur), CE (annulé avec erreur), S (annulé par l’utilisateur), H (suspendu). Un moniteur naïf surveille JOBSTS = E et envoie une alerte. Un moniteur utile connaît la différence entre E et CE, traite les jobs H de plus de 30 minutes comme un problème distinct, et reconnaît qu’un job P qui tourne depuis six heures alors qu’il se termine normalement en douze minutes est aussi un échec, simplement plus silencieux.
Les colonnes SBMDATE et SBMTIME donnent l’horodatage de soumission ; ENDDATE et ENDTIME donnent l’achèvement. L’écart entre la soumission et l’heure système courante permet de signaler les jobs bloqués. La colonne PID indique de quelle UBE il s’agissait, ce qui compte car l’échec de R0006 (EDI inbound) a des conséquences aval différentes de l’échec de R09801 (Post General Ledger), et le moniteur doit savoir distinguer les deux.
La colonne SRVRNM indique quel serveur enterprise a exécuté le job. Dans une installation multi-serveurs, ce n’est pas une information cosmétique — une défaillance récurrente sur un serveur alors que les autres fonctionnent correctement est un problème d’infrastructure, pas un problème UBE, et le moniteur doit faire ressortir ce schéma.
La boucle de polling et pourquoi le timing compte plus que la logique
Le moniteur fonctionnel le plus simple est une requête SQL sur F986110 exécutée toutes les 60 à 120 secondes par un job planifié. Exécutez-la plus fréquemment et vous chargez la base de données sans bénéfice humain — personne ne réagira à une alerte en moins d’une minute de toute façon. Exécutez-la moins fréquemment et vous perdez la capacité de détecter les échecs à cycle court avant que le prochain job dépendant ne tente de démarrer.
La requête elle-même est directe : récupérer chaque ligne où JOBSTS est dans ('E','CE') et où ENDDATE est supérieur ou égal au high-water mark du cycle de polling précédent. Suivez le high-water mark dans une petite table custom afin qu’un redémarrage du moniteur ne rejoue pas toutes les erreurs des six derniers mois. Le modèle est le même principe d’idempotence qui s’applique à tout chargement de données — exécuter le moniteur deux fois doit produire un seul ensemble d’alertes, pas deux.
Le piège que la plupart des builds manquent est la gestion des fuseaux horaires. F986110 stocke les dates au format julien JDE et les heures sous forme d’entiers HHMMSS, les deux dans le fuseau horaire du serveur enterprise. Si le moniteur s’exécute sur un autre hôte dans un autre fuseau horaire, la logique de comparaison doit convertir explicitement. J’ai déjà débogué un moniteur qui manquait silencieusement toutes les erreurs entre 23:00 et minuit parce que la comparaison franchissait une limite de date du mauvais côté.
Classer la sévérité sans écrire mille règles
L’instinct lors du premier build est d’écrire une règle par UBE. À 40 règles, vous avez déjà un désordre ingérable, et à 200, personne ne sait plus quelles règles s’appliquent encore. Le modèle qui passe à l’échelle est la sévérité par catégorie, pas par job.
Trois catégories couvrent environ 95% des installations réelles. Critique signifie avec impact sur le chiffre d’affaires ou la conformité : EDI inbound et outbound (R47*), confirmation d’expédition des commandes clients (R42565), facturation (R42565, R03B11Z1I), clôture de période (R09801, R0911P, R09866), génération de paie. Standard signifie avec impact métier mais pas le jour même : rapports d’intégrité des fichiers maîtres, jobs de réorganisation, moniteurs de réplication. Noisy signifie des erreurs qui reviennent de façon prévisible et sont généralement des problèmes de données : rapports d’intégrité signalant des enregistrements orphelins connus, UBEs custom qui échouent fréquemment sur de mauvaises entrées.
La classification se trouve dans une petite table de correspondance indexée par PID, avec Standard comme valeur par défaut pour tout ce qui n’est pas mappé. Les nouvelles UBEs sont ajoutées à cette table dans le cadre de la checklist de promotion de développement, pas après coup. Le moniteur lit la table de correspondance une fois par cycle de polling et la met en cache pour le reste du cycle.

Router les alertes vers les canaux réellement lus
L’e-mail est l’endroit où les alertes vont mourir. La première version de chaque moniteur dont j’ai hérité envoyait ses messages à une liste de distribution de douze personnes ; au troisième mois, dix d’entre elles avaient une règle Outlook déplaçant les messages vers un dossier que personne n’ouvre. Le modèle qui fonctionne est le routage par sévérité : les alertes critiques vont vers un système de paging avec rotation d’astreinte, les alertes standard vont dans un canal Teams ou Slack dédié avec l’équipe d’exploitation, les alertes noisy vont dans un e-mail digest quotidien qui résume au lieu de spammer.
Le modèle du canal Teams est le cheval de bataille des alertes standard. Un webhook reçoit une payload JSON avec JOBNBR, PID, serveur, horodatage de l’erreur, et un lien direct vers la sortie PDFLe fichier de sortie UBE généré pour chaque job batch, stocké dans le répertoire PrintQueue sur le serveur enterprise. Le contexte de l’erreur se trouve généralement dans les dernières pages. et le job log dans la console web Server Manager. Le lien compte — sans lui, chaque alerte coûte cinq minutes de navigation avant que l’ingénieur puisse commencer le diagnostic. Avec lui, le diagnostic se fait souvent directement depuis l’alerte.
Le système de paging, qu’il s’agisse de PagerDutyUne plateforme de réponse aux incidents largement utilisée, qui gère les plannings d’astreinte, les alertes téléphoniques, les SMS et l’escalade automatique lorsque les alertes ne sont pas acquittées dans une fenêtre définie., d’Opsgenie ou de l’un des équivalents open source, ne devrait se déclencher que sur environ cinq à dix PIDs au total, pas sur chaque ligne rouge de F986110. Moins il y a de jobs qui réveillent les gens à 3 h du matin, plus le moniteur conserve sa crédibilité. La liste des UBEs éligibles au paging doit être revue chaque trimestre, car certains jobs deviennent critiques et d’autres cessent de l’être.
La déduplication des alertes est le détail que chaque équipe rate lors du premier build. Quand la clôture de période échoue, elle n’échoue pas isolément — une erreur R09801 signifie généralement que R0911P et R09866 échoueront aussi dans les dix minutes suivantes, car ils dépendent du même état de données. Sans déduplication, l’ingénieur d’astreinte reçoit quatre alertes pour une seule cause racine et doit les regrouper mentalement. Le modèle qui fonctionne est une fenêtre d’alerte de cinq minutes, indexée par catégorie et serveur, dans laquelle le moniteur émet une alerte agrégée listant tous les échecs liés au lieu de se déclencher quatre fois. Vingt lignes de logique de regroupement, amélioration mesurable du temps moyen d’acquittement.
Enrichir les alertes avec le contexte dont l’ingénieur d’astreinte a réellement besoin
La différence entre une alerte utile et une taxe sur l’attention tient au contexte joint. Un simple "R42565 failed on server JDE_ENT01" force l’ingénieur à se connecter à Server Manager, trouver le job, télécharger le PDF, l’ouvrir, faire défiler jusqu’en bas et lire la pile d’erreurs. Multipliez cela par chaque alerte et le moniteur devient une perte de productivité.
L’enrichissement qui se rentabilise vient de la jointure entre F986110 et F986114 (le détail des étapes du job) et de l’inclusion directe des dernières lignes du job log dans la payload d’alerte. Le message d’erreur — "Invalid Branch/Plant for Item 30000" ou "Mandatory Processing Option PR1 not set" — indique en cinq secondes à l’ingénieur d’astreinte s’il s’agit d’un problème de données (appeler l’analyste) ou d’un problème de code (appeler le développeur). Sans cette ligne, chaque alerte est un pile ou face.
Le deuxième enrichissement qui passe à l’échelle est la détection de récurrence. Si le même PID a échoué trois nuits de suite à peu près à la même heure, la payload d’alerte doit le dire. Le correctif est rarement le même que pour une panne ponctuelle, et l’intervenant doit savoir ce qu’il regarde avant de commencer. Une petite table de récurrence, indexée par PID et réinitialisée chaque semaine, représente cinquante lignes de SQL et économise des heures par mois.
Le dernier élément, souvent ignoré, est la boucle d’acquittement. Quand l’ingénieur d’astreinte corrige un job, il doit pouvoir marquer l’alerte comme résolue avec un court commentaire — "PO bad data, fixed in F4311 batch 1207" — et ce commentaire doit arriver dans une petite table d’historique du moniteur. Trois mois plus tard, quand la même UBE échoue le même jour du mois, l’intervenant suivant voit la résolution précédente et reconnaît le schéma en trente secondes au lieu de repartir de zéro. La piste d’audit donne aussi au responsable des opérations quelque chose de concret à mettre dans le rapport trimestriel de stabilité : non pas "le moniteur a détecté 247 erreurs", mais "247 erreurs, temps moyen d’acquittement 11 minutes, trois principaux responsables R47011, R42565, R09801, tous corrigés dans le SLA". Ce sont les données qui justifient le build.
Si le monitoring batch est le type de discipline opérationnelle que vous souhaitez développer, les articles liés sur la configuration de JDE Server Manager, la conception des checkpoints et redémarrages UBE, ainsi que les stratégies d’archivage F986110 couvrent la pile opérationnelle depuis l’autre côté. Le portefeuille de projets techniques de ce site documente deux des moniteurs de production qui ont produit les modèles décrits ici.