
Ce qu’est réellement un tableau de bord du risque de retrofit
À la base, c’est un score de risque par objet, calculé avant le début du travail de retrofit et présenté de manière à permettre à l’équipe de prioriser. Les données d’entrée viennent de trois sources : la sortie de l’étape Custom Code AnalyzerLe concept technique qui produit la décision par objet — conserver, retrofitter, supprimer, réécrire. Sa sortie est l’entrée principale du tableau de bord., la télémétrie runtime de l’environnement source et le graphe de dépendances des objets JDE touchés. La sortie est une valeur unique par objet — de 1 à 10, vert/orange/rouge ou autre — avec le détail des facteurs qui l’ont produite.
Une valeur unique compte parce qu’une fenêtre de développement de 9 semaines représente environ 70 jours ouvrés pour l’équipe de développement. Avec 350 objets impactés, cela donne environ cinq heures par objet en moyenne, tests inclus. Un tel tableau de bord indique quels objets méritent une journée et lesquels méritent quinze minutes. Sans lui, chaque objet reçoit la même allocation ; les objets dangereux sont sous-testés et les objets triviaux sont surconçus.
La partie “tableau de bord” du nom compte également. Ce n’est pas une liste, ce n’est pas un verdict — c’est une vue que le chef de projet et le lead developer regardent chaque lundi matin pour décider où affecter les deux prochaines semaines d’effort. Statique au début, puis mise à jour au fur et à mesure que le retrofit progresse et que les hypothèses sont validées.
Pourquoi cette discipline a émergé
Parce que l’alternative — traiter le travail de retrofit comme une liste plate de 350 lignes toutes pondérées de la même façon — a un mode d’échec prévisible. L’équipe commence par le haut de l’ordre alphabétique, consomme les six premières semaines sur des UBEsUniversal Batch Engine — le moteur d’exécution batch de JDE. Les UBEs custom sont les objets les plus nombreux et généralement les moins risqués dans un patrimoine de retrofit. custom faciles dans les préfixes A et B, puis découvre en semaine sept que les trois BSFNsBusiness Functions — code C compilé dans le runtime JDE. Elles se trouvent en bas du graphe de dépendances et cassent tout lorsqu’elles échouent. custom au cœur du flux order entry sont impraticables dans leur forme actuelle. À ce moment-là, le budget est déjà consommé.
Le tableau de bord du risque inverse cette logique. Les objets les plus dangereux sont traités en premier, lorsque l’équipe est fraîche et qu’il reste du temps pour escalader. Les objets triviaux sont placés en queue de planning, là où un développeur junior peut en traiter dix en une journée. Même volume total de travail, résultat complètement différent en semaine neuf.
C’est aussi pourquoi les équipes avec de bons chefs de projet se rapprochent de cette discipline même lorsqu’aucun artefact formel n’existe. Elles reconstruisent le tableau de bord mentalement, sur un tableau blanc ou dans un tableur à moitié cassé — parce que sans lui l’upgrade part en retard ou part cassé, et elles ont déjà vu les deux.
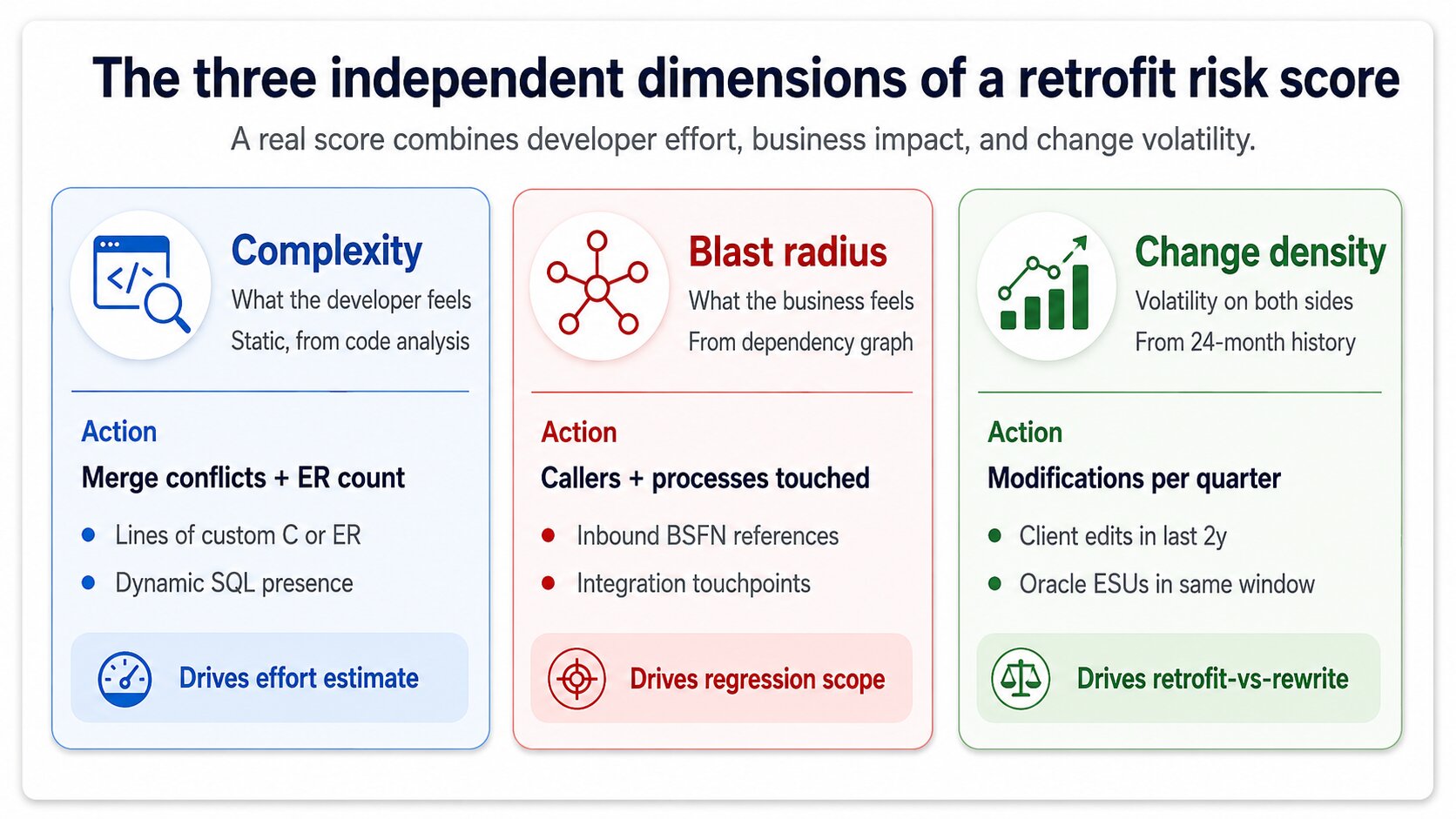
Les trois dimensions d’entrée d’un vrai score de risque
Un score à une seule dimension est une supposition. Un score à trois dimensions est un jugement d’ingénierie défendable. Les trois dimensions qui comptent vraiment sont la complexité, le blast radius et la change density, et un tableau de bord sérieux les calcule indépendamment avant de les combiner.
La complexité est ce que ressent le développeur. Nombre de conflits de merge prévus par l’étape de fingerprint, lignes de code custom dans l’objet, présence d’Event RulesLa couche de scripting visuel de JDE attachée aux formulaires et aux applications. Le retrofit des Event Rules est plus difficile que celui du code C, car le diff est visuel et non textuel. plutôt que de simple C, présence de SQL dynamique. Une BSFN custom avec 40 lignes de C inchangées et une variable renommée est complexité 1. Une application custom avec 200 Event Rules et des changements Oracle conflictuels dans trois sous-formulaires est complexité 9.
Le blast radius est ce que ressent le métier. Combien d’autres objets dépendent de celui-ci, combien de processus métier le traversent, combien d’intégrations l’appellent. Une UBE custom que personne n’exécute a un blast radius de 1 même si son code est difficile. Une BSFN custom appelée par 47 applications à travers order entry, manufacturing et finance a un blast radius de 9 même si son code est trivial à merger. Les deux dimensions sont indépendantes, et un bon tableau de bord ne les fusionne jamais trop tôt.
La change density est le signal de volatilité. À quelle fréquence l’objet de l’environnement source a été modifié au cours des 24 derniers mois, et combien d’ESUs Oracle a livrés sur l’équivalent standard pendant la même période. Une change density élevée des deux côtés signifie que les futurs retrofits seront plus difficiles, pas seulement celui-ci — le score doit refléter le coût stratégique du retrofit par rapport à une réécriture sur la base Oracle actuelle.
Comment la télémétrie runtime affine le score
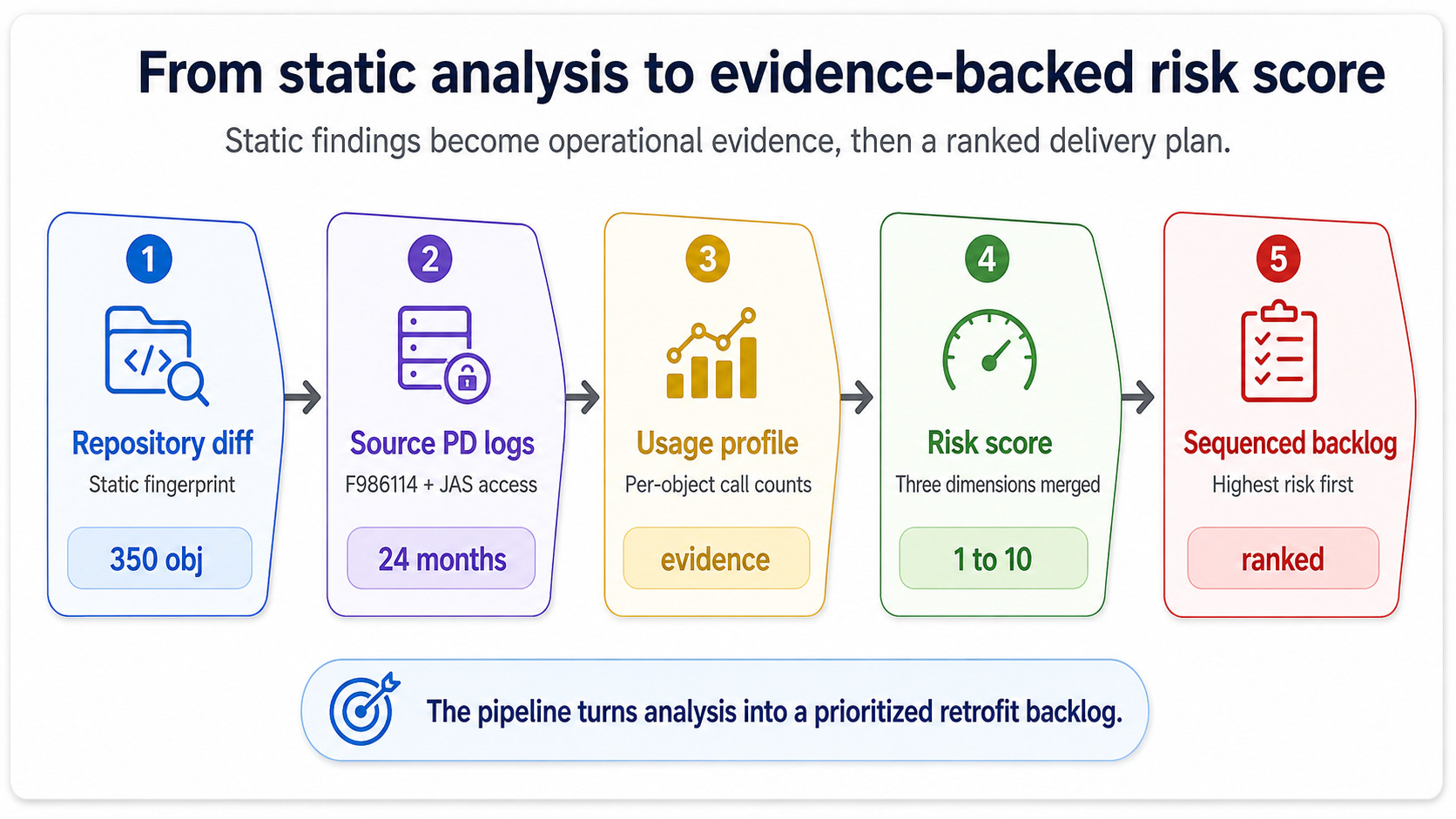
Les dimensions ci-dessus peuvent toutes être calculées statiquement, à partir du référentiel et de l’historique des changements. Le tableau de bord du risque devient utile — et pas seulement un exercice académique — lorsque vous y intégrez les données runtime de l’environnement source.
L’environnement source PDEnvironnement de production dans JDE — l’environnement live. Les logs d’exécution PD sont la source de vérité pour savoir quels objets sont réellement utilisés et à quelle fréquence. sait des choses que l’analyse statique ignore. Il sait quelles UBEs custom n’ont pas été exécutées une seule fois au dernier trimestre, quelles BSFNs custom ont été appelées 11 millions de fois, quelles applications custom ont concentré des logs d’erreur dans les semaines précédant la planification du go-live. Extraire les compteurs d’exécution de F986114La table de contrôle des jobs de JDE. Elle enregistre chaque soumission UBE et constitue la source canonique de la télémétrie d’exécution batch dans l’environnement source. pour la partie batch et des logs d’accès JAS pour la partie interactive donne un profil d’usage qui transforme le “blast radius” d’une estimation en preuve.
C’est ce mouvement qui transforme le tableau de bord d’un tableur statique en un outil auquel le chef de projet fait réellement confiance. Un score vert soutenu par zéro exécution est honnête. Un score vert qui ignore 11 millions d’appels est un projet en attente d’échec au cutover.
À quoi ressemble le tableau de bord au niveau artefact
La forme physique varie — certaines équipes utilisent une page Confluence, d’autres un rapport Power BI sur un extract SQL, les plus disciplinées utilisent un CSV plat que tout le monde peut filtrer. La forme importe peu. Ce qui compte, c’est que pour chacun des 350 objets impactés, vous puissiez répondre à quatre questions en moins d’une minute.
Quel est le score, et qu’est-ce qui l’a produit. Qui possède cet objet pendant le retrofit. Quel est l’effort prévu et quel est le périmètre de régression prévu. Quel est l’état courant — non démarré, en développement, en test, validé. Si le tableau de bord ne peut pas répondre à ces quatre questions à la demande pour n’importe quel objet, ce n’est pas un tableau de bord du risque, c’est une liste. La distinction n’est pas pédante : les listes ne changent pas les comportements, les tableaux de bord oui.
L’autre exigence au niveau artefact est que le tableau de bord se mette à jour. Une estimation de retrofit écrite en semaine zéro sera fausse en semaine trois — certains objets s’avéreront plus difficiles, d’autres triviaux — et le tableau de bord doit absorber ces corrections sans cérémonie. Les équipes qui traitent le scoring initial comme une vérité absolue livrent en retard. Celles qui le traitent comme une hypothèse en révision continue livrent à temps.
Où le tableau de bord s’insère dans le reste de l’upgrade
Il alimente deux consommateurs en aval. L’équipe de développement l’utilise pour séquencer le travail, en prenant les objets au score le plus élevé dès la première semaine et en gardant les objets triviaux pour la fin du planning. L’équipe de test l’utilise pour définir le périmètre de régression : les objets à blast radius élevé tirent davantage de processus métier dans la couverture de régression, tandis que les objets à faible blast radius peuvent être couverts par de simples smoke tests automatisés.
Le troisième consommateur est le comité de pilotage, et c’est là que la plupart des équipes sous-estiment l’artefact. Agrégé en un graphique de distribution, le tableau de bord indique au CIO si le retrofit va tenir dans le périmètre ou non — bien avant que l’équipe de développement ne remonte cette information par les canaux de reporting habituels. Un tableau de bord fortement rouge est une conversation budgétaire en semaine deux, pas une urgence en semaine huit. Ce signal précoce est la deuxième sortie la plus précieuse de la discipline, après la priorisation quotidienne.
En amont, le tableau de bord dépend entièrement de la qualité de sortie des étapes smart filter et fingerprint. Garbage in, dashboard inutile out. C’est pourquoi cette discipline ne vit jamais isolée — elle est la troisième étape d’un pipeline en quatre étapes, et sauter le travail amont pour passer directement au scoring produit des chiffres auxquels personne ne fait confiance.
Ce que cela signifie pour votre périmètre d’upgrade
Si le partenaire qui exécute votre retrofit ne peut pas vous montrer un backlog scoré par risque ou un équivalent défendable dès la première semaine de développement, vous avez un problème que vous ne connaissez pas encore. L’artefact n’a pas besoin de porter ce nom exact — des synonymes comme matrice de triage retrofit, backlog pondéré par impact ou ordre de travail scoré par risque décrivent la même discipline — mais les trois dimensions d’entrée et les quatre questions au niveau artefact ne sont pas négociables.
Demandez à le voir. Demandez quels objets ont obtenu les scores les plus élevés et pourquoi. Demandez comment la télémétrie runtime de votre environnement source a été intégrée. Si les réponses sont vagues, l’équipe découvrira les objets dangereux lentement, sur votre temps. Le coût de cette découverte, sur un patrimoine typique de 9.1 vers 9.2, se situe quelque part entre trois et six semaines supplémentaires de développement, avec un impact visible sur le passage des tests de régression.
Si vous souhaitez un second avis sur la solidité de votre plan de retrofit en matière de scoring et de priorisation, réservez une consultation gratuite. Nous parcourrons les dimensions sur votre environnement spécifique, regarderons où se trouve la télémétrie runtime dans votre environnement source, et vous dirons honnêtement si le travail devant vous est correctement pondéré — ou si le projet est à une mauvaise semaine d’une conversation budgétaire.