
Un upgrade de Tools Release ou un passage de 9.1 à 9.2 est signé comme "réussi" dès que le nouvel environnement permet de se connecter. C’est la partie facile. La partie difficile — et celle qui produit les mauvaises surprises tardives après go-live que toute installation JDE finit par redouter — est la validation des sorties UBE JD Edwards EnterpriseOne pour les tests d’upgrade. La trial balance qui sort avec un centime d’écart par rapport à la baseline, le registre des factures qui imprime les noms clients dans un ordre légèrement différent, la clôture de période qui totalise correctement mais casse le flux de consolidation aval parce que deux colonnes ont changé de position : ce sont les erreurs qui apparaissent trois semaines après l’utilisation en PD, lorsque les personnes qui auraient pu les détecter sont déjà passées au projet suivant.
La solution n’est pas plus d’effort ni plus de testeurs ; la solution est un pipeline de comparaison structuré qui exécute la même UBE avec les mêmes entrées sur l’ancienne release et sur la nouvelle, normalise les sorties et indique à l’équipe en quelques minutes quels jobs sont inchangés, lesquels diffèrent pour des raisons connues et lesquels diffèrent pour des raisons qui nécessitent une investigation.
Ce que "la même sortie" signifie réellement après un upgrade
Le premier piège de chaque projet de test d’upgrade est de traiter "même sortie" comme un contrôle binaire. Ce n’est presque jamais le cas. Un PDF UBE qui contenait "Run Date: 2024-09-15" dans son en-tête lors du run baseline contiendra "Run Date: 2024-09-22" lors du run cible, et un diff naïf au niveau octet signalera chaque page comme différente. Il en va de même pour l’en-tête JOBNBR, le nom utilisateur imprimé, le nom du serveur intégré à la page de garde et les numéros de page qui se décalent si une ligne de données provoque un retour à la ligne sur une limite de page différente.
Une comparaison utile des sorties traite les divergences en trois catégories. La première catégorie est attendue et ignorable — dates, numéros de job, identifiants serveur, horodatages de génération. La deuxième est attendue et intentionnelle — changements que l’upgrade est censé introduire, comme une nouvelle colonne ajoutée par une Application Update ou un champ renommé après un spec merge. La troisième est inattendue — tout ce que l’upgrade n’est pas censé toucher mais qui se lit désormais différemment.
Le seul rôle du pipeline de validation est de pousser chaque sortie dans l’une de ces trois catégories avec un haut niveau de confiance. La première catégorie est résolue par des règles de normalisation appliquées avant la comparaison. La deuxième est résolue par un registre des changements connus maintenu par l’équipe. La troisième est ce que le rapport de régression fait remonter, et ce que l’équipe doit réellement investiguer.
Construire la baseline avant la fermeture de la fenêtre d’upgrade
Une baseline capturée après le début de l’upgrade n’est pas une baseline. La première discipline consiste à verrouiller l’environnement source — généralement PYPrototype environment — le niveau de test JDE où le code promu est exercé sur une copie de données proche de la production avant d’être déplacé vers PD. L’endroit naturel pour exécuter les UBEs de baseline, car les données ressemblent à la production. avec une copie récente des données de production — et à exécuter chaque UBE in-scope avec des entrées soigneusement conservées. Les sorties PDF vont dans un dossier versionné ; les sorties table, lorsque les UBEs écrivent dans des tables F* au lieu de seulement produire des PDF, sont snapshottées avec des comptages de lignes, des contrôles de sommes et un hash des colonnes pertinentes.
La liste des UBEs in-scope est elle-même un livrable. Dans une installation typique de taille moyenne, le catalogue UBE complet compte 300 à 700 jobs, mais la liste in-scope pour la validation d’upgrade est beaucoup plus réduite — les 40 à 80 rapports que le métier exécute réellement régulièrement, plus les rapports financiers et opérationnels standard qui pilotent la clôture de période. La règle que j’applique : toute UBE qui apparaît dans F986110 avec une exécution réussie au cours des 90 derniers jours est in-scope ; tout ce qui est plus ancien est dormant ou remplacé par un autre mécanisme, et l’équipe doit confirmer avant de l’ajouter.
Le jeu d’entrées pour chaque UBE est la partie la plus souvent oubliée. Une UBE possède des processing options, des critères de data selection et un comportement dépendant des dates. Le run baseline doit capturer les trois exactement — processing options enregistrées comme modèle PO versionné, data selection sérialisée dans un fichier, et date système figée via la date "as of" de l’UBE lorsque c’est possible. Sans cette discipline, une sortie "différente" trois mois plus tard peut simplement provenir d’une entrée différente, et l’effort de validation ne produit aucun signal exploitable.
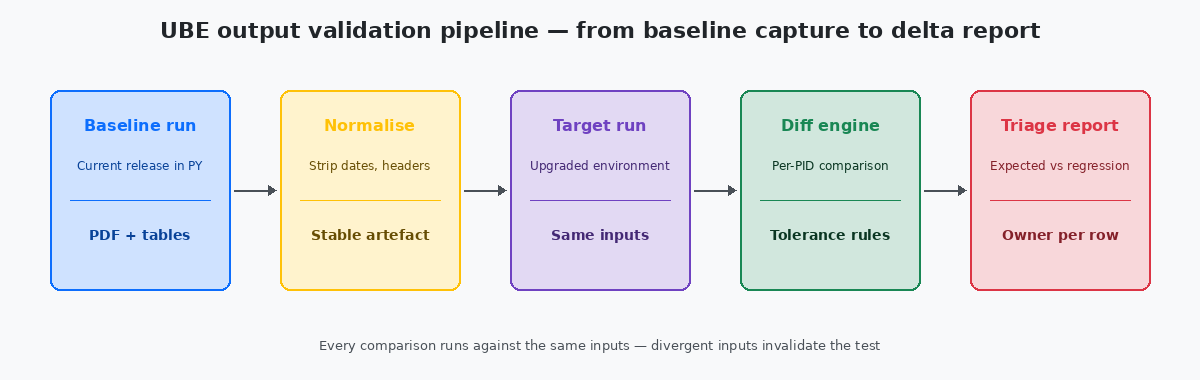
Normaliser les sorties pour que le diff ait du sens
La normalisation est ce qui distingue un pipeline de validation fonctionnel d’un générateur de bruit. Le pipeline doit transformer les sorties baseline et cible avec le même ensemble de règles avant toute comparaison. Les règles ne sont pas exotiques ; elles sont simplement régulièrement oubliées.
Pour les sorties PDF, la normalisation standard supprime l’en-tête de page de garde, c’est-à-dire run date, JOBNBR, utilisateur, serveur, retire les numéros de page, compacte les espaces répétés et remplace la date système imprimée par un jeton fixe partout où elle apparaît. Sur une sortie réglementée où la page de garde elle-même compte — registres de paie, formulaires fiscaux, rapports d’audit — la page de garde est exclue du diff du corps et comparée séparément avec un ensemble de règles plus réduit que les auditeurs accepteront.
Pour les UBEs à sortie table qui écrivent dans des tables F, la normalisation consiste à projeter la table de sortie sur les colonnes qui représentent réellement l’état métier. Les colonnes d’audit comme USER, PID, JOBN, UPMJ, UPMT et TDAY sont exclues du diff parce qu’elles diffèrent toujours entre les runs et n’ont pas de signification métier dans ce contexte. Les colonnes restantes sont triées dans un ordre canonique avant le hash, afin qu’une UBE qui écrit les mêmes lignes dans une séquence physique différente, ce qui peut arriver après un changement d’index, produise tout de même un hash identique.
Les règles de normalisation elles-mêmes vivent dans un seul fichier de configuration versionné dans le projet d’upgrade. Vingt règles couvrent environ 90% des UBEs dans une installation typique ; dix de plus sont généralement nécessaires pour les UBEs qui produisent des sorties au format inhabituel, comme des lettres custom, des fichiers EDI ou des rapports de calcul de paie. Le coût d’écriture de ces règles est rentabilisé dès la première exécution du pipeline contre une release cible, lorsque le diff est lisible au lieu d’être écrasant.
Exécuter la comparaison et trier le diff
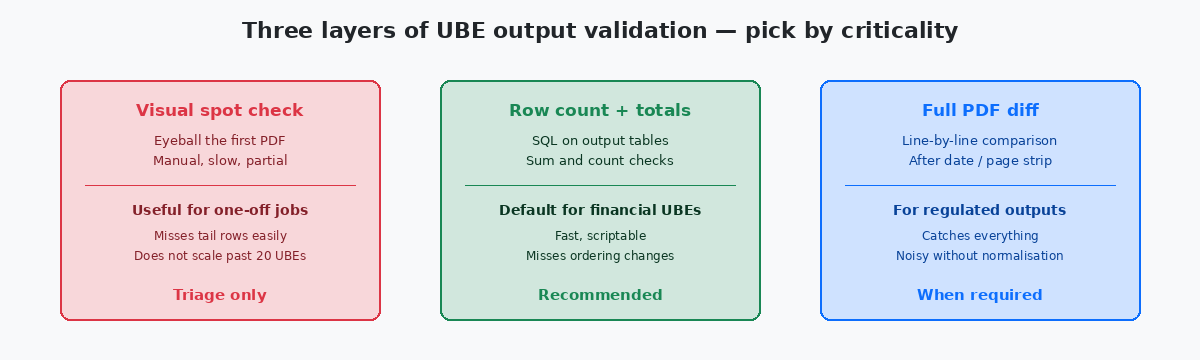
Une fois la baseline capturée et les règles de normalisation définies, la comparaison elle-même est la partie la plus simple du pipeline. Un script — généralement 200 à 400 lignes de Python ou de shell — parcourt la liste des UBEs in-scope, récupère l’artefact baseline pour chacune, récupère l’artefact cible, applique la normalisation et exécute le diff. La sortie est un rapport structuré : une ligne par UBE, avec des colonnes pour le statut (match / known-difference / regression), la taille du diff et un lien vers la vue côte à côte pour revue humaine.
Le registre des changements connus est le fichier qui maintient la pertinence du rapport. Pour chaque UBE dont l’upgrade change légitimement la sortie, une entrée dans le registre l’indique, avec la raison ("Application Update 23 added column COST-CENTER to R09801 output"), et le diff de cette UBE est marqué known-difference plutôt que regression. Sans ce registre, chaque Application Update produit des dizaines de fausses régressions et l’équipe commence à ignorer le rapport — moment où les vraies régressions se cachent dans le bruit.
Le triage de la liste de régressions se fait par criticité. Les UBEs financières — clôture de période, trial balance, A/R aging, A/P proof, rapports fiscaux — sont investiguées en premier et exigent une signature nominative de la finance avant la promotion de l’upgrade. Les UBEs opérationnelles — pick lists, confirmations d’expédition, work order travelers — viennent ensuite. Les rapports de management internes viennent en dernier ; certains peuvent légitimement être différés à la semaine post-upgrade si le métier l’accepte par écrit.
Boucler la boucle : quand la validation est réellement terminée
Un effort de validation d’upgrade se termine lorsqu’un document est signé, pas lorsque la dernière UBE a été comparée. Ce document est un résumé de régression : total des UBEs in-scope, nombre de correspondances exactes, nombre de correspondances après ajustements des changements connus, nombre de régressions investiguées et leurs résolutions, et liste explicite des UBEs différées pour suivi post-upgrade avec le business owner ayant accepté chaque report.
Les signataires ne sont pas l’équipe de développement. Ce sont les business owners des processus concernés — finance pour les rapports financiers, opérations pour les rapports opérationnels, RH pour la paie si elle est in-scope. L’équipe de développement prépare le document et produit les preuves ; le métier signe qu’il accepte le résultat. Sans cette signature, la validation est incomplète, quel que soit le nombre d’UBEs comparées.
Les artefacts produits par le pipeline — sorties baseline, sorties cible, règles de normalisation, registre des changements connus, rapports de diff — sont archivés pendant toute la durée du projet d’upgrade plus l’horizon d’audit typique, généralement sept ans pour les sorties financières. Deux ans plus tard, lorsqu’un auditeur demande "comment saviez-vous que R09801Post General Ledger — l’UBE standard JDE qui poste les écritures de journal batch de F0911 vers F0902. L’UBE la plus validée dans la plupart des installations, car le reporting financier en dépend. produisait les mêmes totaux de période avant et après l’upgrade ?", la réponse est un dossier, pas un souvenir.
La dernière discipline opérationnelle consiste à automatiser suffisamment le pipeline pour pouvoir le relancer à chaque Application UpdateLe format de livraison continue d’Oracle pour JDE 9.2, qui regroupe les changements d’objets standard entre les grands cycles de Tools Release. Chacune est un mini-upgrade qui bénéficie du même pipeline de validation. cumulative, pas seulement lors du grand upgrade tous les trois ans. Un pipeline qui coûte trois mois à construire la première fois et une semaine à exécuter ensuite fait la différence entre une installation compatible avec les upgrades et une installation où chaque décision de Tools Release devient une question de risque au niveau du board.
Pour approfondir le contexte, les articles liés sur les modèles de checkpoint et de restart UBE, sur le cadrage des upgrades Tools Release et sur les stratégies d’archivage F986110 couvrent la couche opérationnelle sur laquelle repose ce pipeline de validation. Le portefeuille de projets techniques de ce site documente deux suites de validation en production qui ont produit les modèles décrits ici.