Seleziona la tua lingua
Il mio Blog

- Dettagli
-
 By Vincenzo Caserta
By Vincenzo Caserta - Categoria: Il mio blog
Dati recenti di telemetria del 2026 suggeriscono che un server web enterprise medio genera ormai oltre 1,2 terabyte di dati di log al mese, un volume che rende l’ispezione manuale non solo inefficiente, ma matematicamente impossibile per operatori umani. In un’epoca in cui i microserviziUno stile architetturale che struttura un’applicazione come una raccolta di piccoli servizi autonomi, modellati attorno a un dominio di business. dominano il panorama, il semplice log Nginx si è evoluto da file di testo a flusso critico di dati ad alta velocità. Eppure molti amministratori restano legati a workflow manuali arcaici, incapaci di catturare il vero stato della loro infrastruttura. Capire come automatizzare la gestione dei log Nginx non è più un lusso; è un requisito fondamentale per mantenere integrità e performance dei sistemi in un mondo iperconnesso.
- Dettagli
- By Vincenzo Caserta
- Categoria: Il mio blog
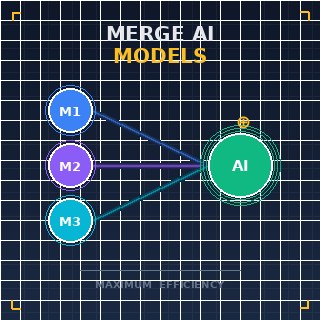
In un laboratorio high-tech a Zurigo, un data scientist osserva uno schermo dove due distinti spiriti neurali stanno per diventare uno solo. Un modello è un maestro della biologia molecolare, mentre l'altro è un esperto di fluidodinamica; separatamente sono brillanti, ma insieme potrebbero rivoluzionare i sistemi di somministrazione dei farmaci. Questa è la realtà del 2026, dove la sfida principale non è più solo costruire sistemi più grandi, ma capire come unire più Large Language Models (LLM)Sistemi di intelligenza artificiale addestrati su enormi quantità di testo per comprendere e generare un linguaggio simile a quello umano. specializzati in un'unica intelligenza coesa. Questo processo, noto come model merging, è passato da curiosità sperimentale a standard ingegneristico critico, consentendo agli sviluppatori di sintetizzare i punti di forza di diverse architetture senza i costi proibitivi di un nuovo addestramento da zero.

- Dettagli
- By Vincenzo Caserta
- Categoria: Il mio blog
Immaginate un ricercatore genomico nel 2026 che tenta di isolare una singola variante proteica da una libreria di cinquantamila voci utilizzando un elemento select HTML standard. Il browser si blocca, la barra di scorrimento diventa microscopica e l'esperienza utente crolla sotto il peso di eccessivi nodi DOMIl Document Object Model è un'interfaccia di programmazione per documenti web, che rappresenta la pagina in modo che i programmi possano modificarne struttura e contenuto.. Per risolvere questo problema, dobbiamo andare oltre gli elementi statici e adottare componenti programmabili. Imparare come creare un dropdown dinamico con ricerca non è più solo una preferenza UI/UXDesign dell'Interfaccia Utente e dell'Esperienza Utente focalizzato sugli aspetti estetici e funzionali dell'interazione umana con il software.; è una necessità tecnica per piattaforme di gestione dati e visualizzazione scientifica ad alte prestazioni.

- Dettagli
- By Vincenzo Caserta
- Categoria: Il mio blog
Perché i nostri modelli predittivi più avanzati, nonostante siano stati addestrati sull'hardware più costoso disponibile nel 2026, crollano ancora di fronte a un minimo cambiamento nel contesto ambientale? Questo fallimento non è un bug del software, ma un'inevitabilità matematica: l'incapacità delle attuali architetture di migrare con successo la JD (Joint Distribution) da un dominio sorgente a un dominio target. Mentre spingiamo i confini dei sistemi autonomi e della modellazione scientifica in tempo reale, l'industria ha finalmente riconosciuto che i dati non sono una risorsa statica. Per mantenere l'accuratezza, dobbiamo trattare i dati come un'entità fluida che richiede sofisticate strategie di traslocazione. Capire come migrare la JD non è più un esercizio accademico; è la pietra angolare di un'intelligenza artificiale robusta.
Altri articoli …
Pagina 1 di 18