

Nei miei oltre vent'anni di sviluppo JDEAbbreviazione di JD Edwards EnterpriseOne, un sistema ERP (Enterprise Resource Planning) sviluppato da Oracle per la gestione delle operazioni aziendendali., ho visto centinaia di tabelle personalizzate corrotte perché gli sviluppatori trattavano il Data DictionaryUn repository centrale in JD Edwards che definisce le proprietà e le regole di validazione per tutti gli elementi di dati, come tipi, lunghezze e valori consentiti. come una funzionalità solo per l'interfaccia utente. Quando si sposta la logica in una BSFNAbbreviazione di Business Function, un componente riutilizzabile in JD Edwards che incapsula la logica aziendale. Può essere scritta in C (C BSFN) o come NER., la rete di sicurezza dell'Applicazione (APPL)Un programma interattivo in JD Edwards, spesso con un'interfaccia utente, utilizzato per inserire, visualizzare o modificare dati. scompare. Se la tua logica non invoca esplicitamente la validazione di tabelle personalizzate JD Edwards BSFN con elementi del Data Dictionary, sei a una chiamata UBEAbbreviazione di Universal Batch Engine, un processo batch in JD Edwards utilizzato per eseguire operazioni non interattive, come report o aggiornamenti massivi di dati. o AISAbbreviazione di Application Interface Services, un server RESTful in JD Edwards che fornisce API per l'integrazione con applicazioni esterne e dispositivi mobili. di distanza da un database pieno di UDCAbbreviazione di User Defined Code, un sistema in JD Edwards per definire e gestire elenchi di valori predefiniti e codificati, utilizzati per la validazione dei dati. non validi e record orfani. Affidarsi alle proprietà "Check" nel designer di form è un errore da principiante che espone tutti i punti di inserimento dati non UI a dati errati.
Costruire un confine di validazione a livello di dati richiede di bypassare la comodità del motore dei form e di interagire direttamente con il runtime JDEL'ambiente in cui i programmi e le funzioni di JD Edwards vengono eseguiti, gestendo l'interazione con il database e la logica aziendale.. In un tipico ambiente EnterpriseOne 9.2Una specifica versione del sistema ERP JD Edwards EnterpriseOne, che include miglioramenti e nuove funzionalità rispetto alle versioni precedenti., una singola orchestrazioneIn JD Edwards, una sequenza di passi automatizzati che combinano diverse funzionalità (come query, chiamate a BSFN o API) per eseguire un processo aziendale complesso. può bypassare ogni vincolo a livello di UI, portando a problemi di integrità dei dati che spesso richiedono un'intera settimana lavorativa di pulizia manuale SQL per essere risolti. Spostare queste regole nelle API CInterfacce di programmazione in linguaggio C che consentono agli sviluppatori di interagire direttamente con le funzionalità e i dati di JD Edwards a un livello più basso. assicura che, sia che i dati provengano da un'app mobile o da un'importazione di file flat legacyUn file di testo semplice, spesso proveniente da sistemi più vecchi, utilizzato per importare o esportare dati senza una struttura complessa o un formato specifico., la tabella rimanga protetta dagli stessi vincoli rigidi definiti nel DDAbbreviazione di Data Dictionary, un repository centrale in JD Edwards che definisce le proprietà e le regole di validazione per tutti gli elementi di dati..
Definire il confine di validazione per le tabelle personalizzate
Negli ambienti legacy 9.1Una versione precedente del sistema ERP JD Edwards EnterpriseOne, con funzionalità e architetture che possono differire dalle versioni più recenti., trovo spesso logiche di validazione critiche intrappolate negli eventi Control Exited/Changed-InlineEventi specifici nel designer di form di JD Edwards che attivano la logica quando un utente esce da un campo o ne modifica il valore. di un'applicazione P55Una convenzione di denominazione per le applicazioni personalizzate in JD Edwards, dove "P" indica un programma e "55" è un prefisso per gli oggetti personalizzati.. Questo debito architetturale diventa una passività quando è necessario caricare dati tramite un processo batch R55Una convenzione di denominazione per i report o processi batch personalizzati in JD Edwards, dove "R" indica un report e "55" è un prefisso per gli oggetti personalizzati. o una chiamata AIS esterna. Affidarsi allo strato applicativo per imporre l'integrità presuppone che ogni punto di ingresso sia un essere umano davanti a uno schermo. Una chiamata diretta di Table I/OOperazioni di Input/Output dirette su una tabella del database in JD Edwards, come inserimento, aggiornamento o eliminazione di record. in una UBE bypassa ogni riga di codice ERAbbreviazione di Event Rules, il linguaggio di programmazione grafico utilizzato in JD Edwards per definire la logica aziendale all'interno di applicazioni e report. nella tua APPL, lasciando la tua tabella personalizzata vulnerabile a record orfani o codici di stato non validi.
Spostare il confine di validazione a una Master Business Function (MBF)Una Business Function principale che incapsula la logica di validazione e manipolazione dei dati per un'entità aziendale, garantendo coerenza. assicura che lo strato dati non sia mai "sottile". Quando si incapsula la validazione all'interno di una BSFN basata su C o di una NERAbbreviazione di Named Event Rule, un tipo di Business Function in JD Edwards scritta usando le Event Rules, che può essere riutilizzata in diverse applicazioni. strutturata, si crea un guardiano unificato che rispetta sia le regole del Data Dictionary sia la logica relazionale complessa prima che avvenga un commitL'operazione che rende permanenti le modifiche apportate a un database, salvando i dati in modo definitivo..
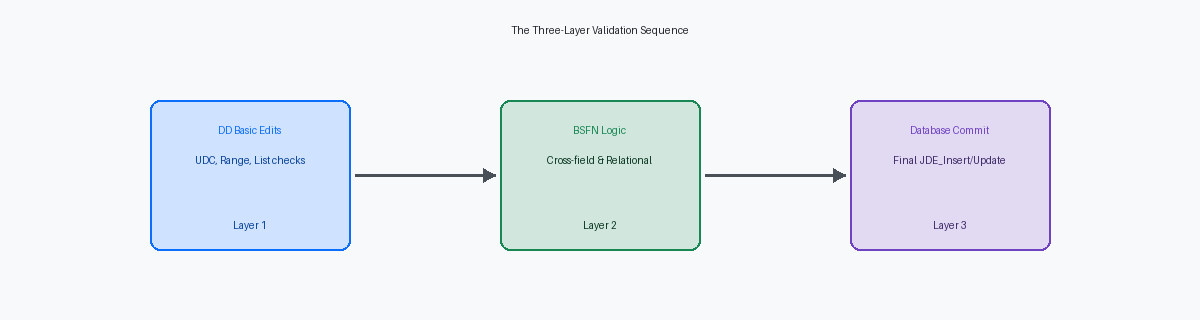
Applicare il Data Dictionary per vincoli rigidi
Lo schema di una tabella personalizzata è affidabile solo quanto gli elementi del Data Dictionary (DD)Le singole definizioni all'interno del Data Dictionary di JD Edwards, che specificano le proprietà e le regole di validazione per i campi del database. che ne supportano le colonne. Affidarsi alla logica BSFN per intercettare una stringa malformata o un intero fuori intervallo è un fallimento architetturale quando il DD fornisce la validazione nativa di Range, List e UDCTipi di regole di validazione configurabili nel Data Dictionary di JD Edwards: intervallo di valori, elenco predefinito e codici definiti dall'utente.. Ad esempio, definire un campo "Status" con un controllo hard-coded nel codice C richiede una build completa del packageIl processo di compilazione e distribuzione di tutti i componenti di JD Edwards (codice, oggetti) su un server, necessario per rendere effettive le modifiche al codice C. per una singola modifica di valore. Un elemento DD supportato da UDC consente a un analista aziendale di aggiornare la tabella F0005La tabella di sistema in JD Edwards che memorizza i User Defined Codes (UDC), consentendo la gestione centralizzata degli elenchi di valori. tramite P0004AL'applicazione di JD Edwards utilizzata per gestire i User Defined Codes (UDC), permettendo agli utenti di configurare e aggiornare gli elenchi di valori. in pochi secondi senza toccare una singola riga di codice.
Quando si scrive una BSFN C per validare un record di tabella personalizzata, il primo passo dovrebbe essere l'invocazione dello stack di validazione standard tramite l'API C jdeCallObjectUna funzione API in linguaggio C di JD Edwards utilizzata per invocare altre Business Functions (BSFN) da un programma C.. Nello specifico, la chiamata a B0000016 (VerifyUDC)Una Business Function standard di JD Edwards (spesso con alias X0005) utilizzata per verificare se un valore è un User Defined Code (UDC) valido. assicura che la tua logica personalizzata rispetti gli stessi controlli di integrità F0005La tabella di sistema in JD Edwards che memorizza i User Defined Codes (UDC), consentendo la gestione centralizzata degli elenchi di valori. utilizzati dalle applicazioni standard P4210L'applicazione standard di JD Edwards per l'inserimento degli ordini di vendita, che include la validazione dei dati. o P4310L'applicazione standard di JD Edwards per l'inserimento degli ordini di acquisto, che include la validazione dei dati.. Questo approccio mantiene un'unica fonte di verità per i codici validi, prevenendo i problemi di "dati fantasma" che si verificano quando le BSFN personalizzate e le applicazioni standard non concordano su ciò che costituisce un valore valido.
Gli elementi DD personalizzati dovrebbero essere configurati con specifiche Edit RulesRegole di modifica configurabili nel Data Dictionary di JD Edwards (tramite P92001) che definiscono i vincoli di validazione per i campi, come intervalli o formati. in P92001L'applicazione di JD Edwards per la gestione del Data Dictionary, dove gli sviluppatori configurano le proprietà e le regole di validazione per gli elementi di dati. per automatizzare l'integrità di base dei dati prima ancora che la BSFN inizi la sua esecuzione. Se un campo richiede un intervallo numerico specifico o un valore da un elenco predefinito, impostare questi vincoli a livello di DD scarica l'onere della validazione dallo strato applicativo al motore JDEIl componente software principale di JD Edwards che gestisce l'esecuzione delle applicazioni, la logica aziendale e l'interazione con il database.. In un ambiente ad alto volume che elabora decine di migliaia di record all'ora tramite una UBE personalizzata, questo scarico riduce l'overhead dello stack di chiamateLa sequenza di funzioni o programmi attivi in un dato momento durante l'esecuzione di un programma, che mostra l'ordine delle chiamate. facendo fallire i record non validi al punto di ingresso più precoce possibile.
L'hard-coding dei valori di validazione all'interno di una BSFN è una trappola di manutenzione che ho visto far deragliare numerosi progetti di upgrade alla versione 9.2. Ogni volta che una regola aziendale cambia, si deve affrontare una revisione del codice, una promozione OWMAbbreviazione di Object Workbench, l'ambiente di sviluppo integrato (IDE) di JD Edwards utilizzato per creare, modificare e gestire gli oggetti del sistema. e un deployment del packageIl processo di distribuzione di un package compilato di JD Edwards (che contiene modifiche al codice e agli oggetti) sui server di ambiente. attraverso il path codeUn identificatore in JD Edwards che rappresenta un ambiente specifico (es. DV920, PY920, PD920) e il set di oggetti associati.. L'utilizzo di vincoli guidati dal DD sposta quella logica nello strato dei metadatiIl livello in JD Edwards dove vengono definite le informazioni sui dati (come le regole del Data Dictionary) piuttosto che i dati stessi o la logica applicativa. dove appartiene. La gestione di questi vincoli tramite P92001 assicura che la tua logica di validazione rimanga visibile all'intero team IT piuttosto che essere sepolta in un file sorgente che solo uno sviluppatore può decifrare.

Implementare la logica BSFN per la validazione incrociata dei campi
Le modifiche del Data Dictionary come il controllo di intervallo o l'elenco di valori falliscono nel momento in cui la tua logica richiede un confronto relazionale tra due campi distinti. Ad esempio, assicurare che una "Data di Spedizione" (SDTJ)Un elemento del Data Dictionary in JD Edwards che rappresenta la "Data di Spedizione" (Ship Date). non sia precedente a una "Data Ordine" (TRDJ)Un elemento del Data Dictionary in JD Edwards che rappresenta la "Data Ordine" (Transaction Date). in una tabella personalizzata richiede una BSFN C perché il DD non può fare riferimento al valore di un altro campo in tempo reale. In un ambiente di produzione ad alto volume che elabora migliaia di record personalizzati quotidianamente, scaricare questa logica su una BSFN assicura che le regole aziendali complesse siano applicate in modo coerente sia nelle applicazioni interattive che negli upload batch.
All'interno del sorgente C, il puntatore lpBhvrCom->hToolkitUn puntatore all'handle del toolkit di runtime di JD Edwards, utilizzato nelle Business Functions C per accedere a servizi di sistema e gestire gli errori. è la tua interfaccia principale per interagire con lo stato interno del motore JDE. Devi passare questo handle all'API jdeErrorSetUna funzione API in linguaggio C di JD Edwards utilizzata per registrare messaggi di errore e associarli a specifici campi o controlli dell'interfaccia utente. per assicurarti che gli errori siano correttamente mappati al membro specifico della struttura dati e visualizzati nell'interfaccia utente. Senza inizializzare e utilizzare correttamente l'handle del toolkit, i tuoi errori di validazione potrebbero essere registrati nel jdedebug.logUn file di log generato dal motore di JD Edwards che registra informazioni dettagliate sull'esecuzione del sistema, inclusi errori e messaggi di debug. ma non riusciranno a fermare la transazione o a evidenziare il campo incriminato in rosso su un Power FormUn tipo avanzato di form interattivo in JD Edwards, che offre maggiore flessibilità e funzionalità rispetto ai form standard. o una griglia standard.
Uno stack di validazione professionale si esegue in una gerarchia specifica: primo, lasciare che il DD gestisca i valori nulli e la formattazione di base; secondo, usare la BSFN per eseguire controlli relazionali contro tabelle master come Company Constants (F0010)La tabella di sistema in JD Edwards (F0010) che memorizza le impostazioni e i parametri globali per ciascuna azienda definita nel sistema. o Address Book (F0101)La tabella di sistema in JD Edwards (F0101) che memorizza le informazioni anagrafiche di tutte le entità (clienti, fornitori, dipendenti).. Se stai validando un campo personalizzato contro una specifica Business Unit (MCU)Un elemento del Data Dictionary in JD Edwards (MCU) che rappresenta un'unità aziendale o un centro di costo, utilizzato per la contabilità e la reportistica., la BSFN dovrebbe prima verificare che la MCU esista in F0006La tabella di sistema in JD Edwards che memorizza le definizioni delle Business Unit (MCU), inclusi i loro nomi e proprietà. prima di procedere con la logica incrociata dei campi. Questo impedisce al codice di eseguire costose istruzioni SelectUn'istruzione SQL utilizzata per recuperare dati da una o più tabelle del database. su dati malformati che avrebbero dovuto essere intercettati dalle regole di modifica di base del DD.
Il passo finale nella BSFN è il ritorno esplicito del valore JDEBFRTNUn tipo di dato o macro in JD Edwards che rappresenta il valore di ritorno di una Business Function (BSFN), indicando successo o errore., tipicamente ER_SUCCESSUn valore di ritorno standard in JD Edwards che indica che una Business Function o un'operazione è stata completata con successo. o ER_ERRORUn valore di ritorno standard in JD Edwards che indica che una Business Function o un'operazione ha riscontrato un errore.. Se la tua logica incrociata dei campi rileva un intervallo di date non valido o un record mancante in F0101, restituire ER_ERROR è l'unico meccanismo che indica al motore di runtime JDE di interrompere il processo di commit. In uno scenario di inserimento standard, la mancata restituzione del codice corretto significa che il sistema potrebbe procedere con un InsertUn'operazione SQL per aggiungere nuovi record a una tabella del database. o UpdateUn'operazione SQL per modificare i dati esistenti in uno o più record di una tabella del database. di I/O della tabella anche se jdeErrorSet è stato chiamato, portando a problemi di integrità dei dati che sono notoriamente difficili da riconciliare nelle tabelle SQL di produzione.
Gestione degli errori e mappatura dei messaggi
Un errore comune nelle BSFN C personalizzate è l'hard-coding delle stringhe di errore o la mancata mappatura dei codici di ritorno allo stack di errori JDE. Quando una validazione fallisce contro una tabella personalizzata, restituire un semplice '1' all'APPL o UBE chiamante è insufficiente per la risoluzione dei problemi. Devi mappare ogni fallimento a uno specifico ID errore del Data DictionaryUn codice numerico o alfanumerico definito nel Data Dictionary di JD Edwards per identificare specifici messaggi di errore standardizzati., come 0001 per un 'Numero Rubrica non valido' o 0002 per 'Record non valido'. Utilizzando l'API jdeErrorSet, inietti variabili di runtime nel testo del glossario. Passare lo specifico mnAddressNumberUn elemento del Data Dictionary in JD Edwards che rappresenta il numero di rubrica, un identificatore univoco per entità come clienti o fornitori. nella struttura dell'errore consente all'utente di vedere esattamente quale record ha causato il fallimento, piuttosto che indovinare da un messaggio generico. Questo assicura che il puntatore lpBhvrComUn puntatore all'handle del toolkit di runtime di JD Edwards, utilizzato nelle Business Functions C per accedere a servizi di sistema e gestire gli errori. riporti lo stato corretto al form interattivo o al motore batch.
In ambienti UBE ad alto volume e multi-threadedUn'applicazione o un processo che può eseguire più parti di codice contemporaneamente, migliorando le prestazioni in ambienti ad alto volume., una gestione impropria dello stack di errori porta a errori fantasma o perdite di memoria all'interno del motore JDE. Se la tua BSFN viene chiamata all'interno di un loop che elabora migliaia di record, la mancata pulizia dello stack di errori o l'assegnazione errata dell'idControlUn identificatore univoco per un controllo (campo, pulsante) all'interno di un form o di un'applicazione JD Edwards, utilizzato per riferirsi ad esso programmaticamente. può far sì che un messaggio dal record 5 appaia sul record 500. Ho visto kernel di produzioneIl processo principale del server di JD Edwards che gestisce l'esecuzione delle Business Functions e delle applicazioni in un ambiente live. bloccarsi perché uno sviluppatore ha allocato memoria per una stringa di errore personalizzata ma non è riuscito a liberarla dopo la chiamata jdeErrorSet. Attieniti agli elementi DD standard e lascia che il middleware gestisca il ciclo di vita della memoria dello stack di errori. Questo è particolarmente critico quando si esegue su Tools Releases a 64 bitVersioni degli strumenti di sviluppo e runtime di JD Edwards che supportano architetture a 64 bit, consentendo una maggiore gestione della memoria. dove lo spazio di indirizzamento della memoria è più grande ma comunque finito.
Affidarsi al Glossary Text del Data DictionaryIl testo descrittivo associato a un elemento del Data Dictionary in JD Edwards, che può essere tradotto in diverse lingue per la localizzazione. fornisce un'esperienza localizzata senza richiedere modifiche al codice per i deployment internazionali. Quando si definisce un errore nel DD, il runtime JDE recupera automaticamente la versione tradotta in base alla lingua del profilo utente. Per validazioni complesse in cui un messaggio breve è insufficiente, è possibile collegare l'ID errore a F00165 Media ObjectsLa tabella di sistema in JD Edwards (F00165) che memorizza oggetti multimediali (come testo lungo, immagini o documenti) associati a record o elementi. per fornire passaggi di risoluzione dettagliati. Questo trasforma un messaggio di sistema criptico in una SOPAbbreviazione di Standard Operating Procedure, una serie di istruzioni passo-passo per eseguire un'attività o un processo in modo coerente. funzionale per l'utente finale. È la differenza tra un ticket di help desk ad alta priorità e un errore di inserimento dati auto-corretto che non lascia mai il reparto.
Il costo prestazionale della validazione ridondante
Un errore comune nell'elaborazione batch ad alto volume è trattare il Data Dictionary come una risorsa gratuita. Se una UBE elabora set di record a sei cifre e la BSFN C chiama JDECM_GetDictColInfoUna funzione API in linguaggio C di JD Edwards utilizzata per recuperare informazioni dettagliate su una colonna del Data Dictionary. per ogni riga per controllare i trigger decimaliRegole o proprietà definite nel Data Dictionary di JD Edwards che specificano come gestire i valori decimali per un campo., si introduce un enorme collo di bottiglia I/O. In un ambiente di distribuzione, abbiamo ridotto il tempo di esecuzione di un upload di vendite personalizzato da diverse ore a meno di trenta minuti spostando questi recuperi di metadati fuori dal loop principale di elaborazione delle righe.
Gli sviluppatori efficaci utilizzano il puntatore lpBhvrComUn puntatore all'handle del toolkit di runtime di JD Edwards, utilizzato nelle Business Functions C per accedere a servizi di sistema e gestire gli errori. o una struttura dati personalizzata per memorizzare i metadati DD una sola volta. Il recupero delle informazioni sulle colonne tramite JDECM_GetDictColInfo dovrebbe avvenire durante la fase di inizializzazione o la prima iterazione, quindi essere memorizzato nello spazio di memoria della BSFN. Questo assicura che il runtime non acceda ripetutamente alle tabelle F9210La tabella di sistema in JD Edwards che memorizza le definizioni degli elementi del Data Dictionary. e F9211La tabella di sistema in JD Edwards che memorizza le informazioni sulle colonne delle tabelle, inclusi i riferimenti al Data Dictionary. per informazioni che rimangono statiche durante l'esecuzione.
Chiamare VerifyUDC (X0005)Una Business Function standard di JD Edwards (alias X0005) utilizzata per verificare se un valore è un User Defined Code (UDC) valido. all'interno di un loop per un valore che non cambia — come un codice Company costante — è uno spreco di cicli CPU. Un pattern più efficiente prevede la validazione del valore costante una volta all'inizio del processo e l'impostazione di un flag booleanoUna variabile che può assumere solo due valori, tipicamente "vero" o "falso", utilizzata per indicare lo stato di una condizione. nella struttura dati interna. Se il flag è vero, la logica procede; altrimenti, il processo termina prima che il primo record venga letto dalla tabella personalizzata.
Quando la tua BSFN esegue la validazione relazionale contro master JDE standard come F0101La tabella di sistema in JD Edwards (F0101) che memorizza le informazioni anagrafiche di tutte le entità (clienti, fornitori, dipendenti). o F4101La tabella di sistema in JD Edwards (F4101) che memorizza le informazioni sugli articoli (Item Master), inclusi i dettagli e le proprietà di ogni prodotto., gli indici mancantiStrutture speciali in un database che migliorano la velocità di recupero dei dati, ma se assenti, possono rallentare notevolmente le query. sulle tabelle personalizzate sono fatali. Una tabella con 500.000 record priva di un indice primarioUn indice speciale in un database che identifica in modo univoco ogni record in una tabella, garantendo l'integrità dei dati e velocizzando le ricerche. sul numero articolo breve (ITM)Un elemento del Data Dictionary in JD Edwards (ITM) che rappresenta un codice breve e univoco per identificare un articolo o un prodotto. forza una scansione completa della tabellaUn'operazione inefficiente in un database in cui il sistema deve leggere ogni riga di una tabella per trovare i dati desiderati. per ogni controllo di validazione. Assicurati che la tua tabella personalizzata abbia un indice primario che si allinei con le istruzioni di recupero della BSFN per mantenere tempi di risposta inferiori al secondo.
Testare lo stack di validazione in OWM
Testare una BSFN in isolamento è uno spreco di tempo senza un harness controllatoUn ambiente di test strutturato che fornisce input specifici e controlla l'esecuzione di un componente software (come una BSFN) per verificarne il comportamento.. Vedo sviluppatori passare ore a richiamare manualmente una funzione da un'applicazione standard, il che è inefficiente e soggetto a errori umani. Costruisci una UBE driverUn processo batch (UBE) in JD Edwards progettato per richiamare e testare altre Business Functions o logiche in modo automatizzato. o una semplice APPL di testUn'applicazione interattiva in JD Edwards creata specificamente per testare funzionalità o Business Functions in un ambiente controllato. con campi di input specifici per simulare 10-15 scenari di dati non validi. Questo include il test di valori limite, puntatori nulli e tipi di dati non corrispondenti. Un oggetto di test dedicato ti consente di ripetere l'esecuzione in meno di un minuto dopo ogni ricostruzione del codice CIl processo di ricompilazione del codice sorgente C di una Business Function in JD Edwards dopo aver apportato modifiche. in OWM, assicurando che la logica resista a casi limite come quantità negative o date GiulianeUn formato di data utilizzato in JD Edwards, dove l'anno è rappresentato da tre cifre (es. 123 per 2023) e il giorno dell'anno da tre cifre (es. 001-365). non valide.
Un test di validazione efficace richiede più che cercare un errore rosso sullo schermo. Avvia il JDE DebuggerUno strumento di debug fornito con JD Edwards che consente agli sviluppatori di esaminare l'esecuzione del codice, impostare breakpoint e ispezionare le variabili. e imposta breakpointUn punto nel codice sorgente dove l'esecuzione del programma si ferma temporaneamente, consentendo allo sviluppatore di esaminare lo stato del programma. a ogni istruzione di ritorno all'interno del codice sorgente. Devi ispezionare i valori di ritorno delle chiamate jdeErrorSet e assicurarti che la struttura dati lpBhvrComUn puntatore all'handle del toolkit di runtime di JD Edwards, utilizzato nelle Business Functions C per accedere a servizi di sistema e gestire gli errori. sia correttamente popolata prima che la funzione esca per prevenire fallimenti silenziosi in produzione.
Se stai lottando con problemi persistenti di integrità dei dati nei moduli JDE personalizzati, o stai architettando nuove integrazioni che dipendono da tabelle personalizzate, dovremmo parlarne. Posso aiutarti a valutare la tua architettura di validazione a livello di BSFN e implementare uno strato dati più resiliente.
