
Quando una gridUna tabella interattiva all'interno di un'applicazione JD Edwards utilizzata per visualizzare e gestire righe di dati. personalizzata in un'applicazione come P554210 impiega più di dieci secondi per caricare 500 record, i team basisIl team tecnico responsabile dell'installazione, configurazione e manutenzione dell'infrastruttura software e dei server. incolpano immediatamente gli indici del database o le dimensioni della heap JVMLa porzione di memoria dedicata alla Java Virtual Machine per la gestione degli oggetti e dei dati durante l'esecuzione. di WebLogicIl server applicativo di Oracle che ospita l'interfaccia web e la logica di JD Edwards.. Nella stragrande maggioranza degli audit di performance condotti su EnterpriseOne 9.2, l'infrastruttura è perfettamente adeguata; il collo di bottiglia sono le Event Rules (ER)Il linguaggio di programmazione visuale utilizzato in JD Edwards per definire la logica di business senza scrivere codice complesso. sincrone eseguite sul server JASJava Application Server, il componente che trasforma la logica di JD Edwards in un'interfaccia web accessibile via browser. per ogni singola riga. Ottenere tempi di risposta inferiori al secondo richiede di abbandonare lo scaricabarile sull'infrastruttura e concentrarsi sull'ottimizzazione delle performance delle grid APPL JD Edwards per grandi dataset all'interno del runtime engine di JDE.
Un'efficace ottimizzazione della grid si basa sull'eliminazione del sovraccarico dovuto ai roundtrip iterativi verso il database e all'esecuzione sincrona delle Business Function (BSFN)Moduli di codice riutilizzabili, scritti in C o in Event Rules, che eseguono specifiche operazioni di business.. Spostando la pesante logica di validazione dall'evento Grid Record Is Fetched all' I/O di tabellaOperazioni di Input/Output, ovvero la lettura o la scrittura di dati all'interno delle tabelle del database. asincrono o all'elaborazione in background, gli sviluppatori possono ridurre le chiamate al database dal 70% all'80%. Se il tuo team di sviluppo scrive ancora loop ER procedurali che leggono la stessa tabella delle costanti per ogni riga della grid, sta degradando gravemente l'esperienza utente.
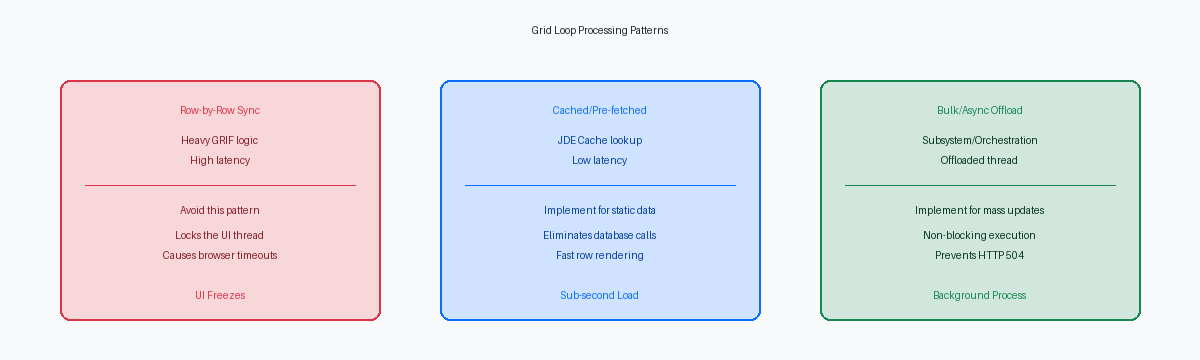
La trappola del Grid Loop e l'esecuzione riga per riga
Gli audit tecnici delle APPL personalizzate rivelano frequentemente centinaia di righe di Event Rules inserite direttamente nell'evento Grid Record Is Fetched (GRIFGrid Record Is Fetched: un evento che viene eseguito ogni volta che il sistema recupera una singola riga dal database.). Questo evento viene attivato in modo sincrono per ogni singola riga del database recuperata prima che venga renderizzata sullo schermo. Se un utente interroga 500 righe di ordini di vendita in una versione personalizzata di P4210, il motore JAS è costretto a eseguire l'intero blocco di ER per 500 volte consecutive prima di presentare i dati al browser.
La penalità in termini di performance aumenta quando gli sviluppatori inseriscono pesanti Master Business FunctionsBSFN complesse progettate per gestire intere transazioni, come l'inserimento di un ordine, garantendo l'integrità dei dati. o BSFN C personalizzate come GetAuditInfo (B9800100) all'interno di questo loop. Quello che dovrebbe essere un pulito recupero SQLStructured Query Language, il linguaggio standard utilizzato per comunicare e interrogare i database relazionali. dal database di due secondi si trasforma rapidamente in un blocco del browser che dura quasi un minuto. Questa latenza è causata dai costanti roundtrip di rete tra l'HTML server e l'Enterprise logic server, poiché ogni singola riga richiede la propria serializzazione round-trip per eseguire la logica di business.
Per risolvere questo collo di bottiglia, sposta completamente la logica di validazione non essenziale fuori dal GRIF. Spostare la formattazione visiva nell'evento Write Grid Line-Before garantisce che JDE elabori solo le 10-20 righe effettivamente visibili nel viewport della pagina corrente della grid. Per i calcoli pesanti, eseguirli in modo asincrono o posticiparli fino a quando una riga non viene selezionata può ridurre i tempi di caricamento iniziale della pagina del 75%-80%.
Se è necessario calcolare i valori al momento del fetch, configura le proprietà della grid per l'elaborazione "page-at-a-time" invece di caricare l'intero set di record. Questa modifica limita l'esecuzione sincrona del GRIF alla dimensione della pagina attiva della grid, impedendo al client web di bloccarsi su tabelle contenenti decine di migliaia di record.

Ottimizzazione della selezione dei dati con letture selettive
Consentire a un utente di eseguire una ricerca non filtrata su una form Find/Browse su una tabella F4211 o F0911 da milioni di righe introduce gravi rischi operativi. La query SQL aperta risultante costringe il server JAS ad allocare memoria heap per centinaia di migliaia di righe della grid, scatenando un OutOfMemoryErrorUn errore critico che si verifica quando il server ha esaurito la memoria disponibile per eseguire le operazioni. e facendo crashare la sessione HTML attiva. In un recente audit tecnico, abbiamo risolto un problema in cui alcune query aperte simultanee su F4211 esaurivano la memoria JVM e bloccavano un'intera istanza HTML, interrompendo decine di utenti attivi.
Per prevenire scansioni complete su tabelle che superano i diversi milioni di righe, gli sviluppatori devono imporre almeno un campo filtro indicizzato sulle form find/browse. Impostare la proprietà "Filter Criteria" su "Equal" su una colonna indicizzata come SDKCOO o SDDOCO costringe l'ottimizzatore del database a eseguire un index seekUn'operazione di ricerca efficiente in cui il database trova rapidamente i dati utilizzando un indice, senza leggere l'intera tabella. invece di una costosa scansione della tabella. Se l'utente lascia vuoti questi campi obbligatori, l'applicazione dovrebbe bloccare programmaticamente la query nell'evento "Button Clicked" del pulsante Find prima di interrogare il database.
Quando i filtri statici non sono sufficienti, l'uso della funzione di sistema Set Selection dinamicamente nella sequenza di eventi "Clear Select" e "Set Selection" limita la clausola WHERE SQL prima che la grid esegua il suo fetch primario. Fondamentalmente, le proprietà della grid devono essere configurate per l'elaborazione "Page-at-a-Time" invece di caricare tutti i record in memoria contemporaneamente. Ciò limita il fetch iniziale del database alla dimensione della pagina della grid (tipicamente da 10 a 50 righe), prevenendo l'esaurimento della memoria e mantenendo tempi di risposta inferiori al secondo.
Il costo delle chiamate BSFN e Database ripetitive
L'esecuzione di una singola Business Function (BSFN) che richiede 10 millisecondi (apparentemente trascurabili) aggiunge dieci secondi di latenza pura quando eseguita sequenzialmente su una grid da 1.000 righe. Questo accumulo di latenza si verifica frequentemente nell'evento Grid Record is Fetched, dove gli sviluppatori inseriscono abitualmente BSFN standard o personalizzate per recuperare descrizioni ausiliarie o convalidare codici per riga. Il degrado delle performance aumenta quando queste BSFN all'interno del loop aprono e chiudono ripetutamente gli handle di tabella, come nel caso della chiamata 'F0005 Get UDC' per recuperare le descrizioni dei codici definiti dall'utente per ogni singola riga.
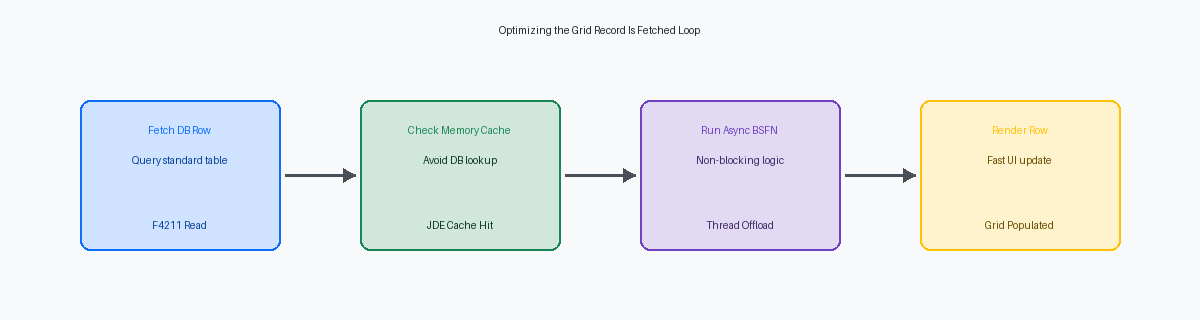
Per eliminare migliaia di operazioni di selezione ridondanti sul database, gli sviluppatori dovrebbero memorizzare nella cache i dati di validazione statici o semi-statici utilizzando le APIApplication Programming Interface: un insieme di procedure che permettono a diversi componenti software di comunicare tra loro. JDE Cache come jdeCacheInit durante l'evento Dialog is Initialized prima del caricamento della grid. Invece di interrogare il database o eseguire letture della tabella F0005 migliaia di volte per un caricamento di una grid di grandi dimensioni, una BSFN C personalizzata può caricare i valori UDCUser Defined Codes: tabelle di codici personalizzabili utilizzate in JD Edwards per definire valori validi per specifici campi. richiesti o i record di riferimento incrociato in una cache residente in memoria una sola volta. Le ricerche in memoria in meno di un millisecondo sostituiscono quindi l'I/O del disco e i salti di rete, riducendo il tempo di elaborazione per riga da 12 millisecondi a meno di un millisecondo.
Quando i calcoli complessi sono inevitabili, passa dall'esecuzione riga per riga all'elaborazione batch (bulk processing). Passa array pre-caricati o strutture dati contenenti tutti i campi chiave a una Business Function C personalizzata in una singola chiamata mappata in memoria, invece di chiamare la BSFN una volta per ogni riga della grid. Questo cambiamento strutturale consente alla BSFN di eseguire una singola operazione di apertura del database, eseguire fetch massivi, elaborare la logica in RAM e restituire il dataset al livello applicativo. L'implementazione di questo pattern su una schermata di disponibilità dell'inventario ad alto volume può ridurre i tempi di transazione dell'80%-85%, portando i tempi di caricamento della schermata da quindici secondi a meno di tre secondi.
Manipolazione del Grid Buffer e impronta di memoria
Analizziamo frequentemente ambienti di produzione in cui la JVM del server HTML crasha con eccezioni OutOfMemoryError durante i picchi di spedizione o fatturazione. Il colpevole è tipicamente una power form personalizzata o una P42101 pesantemente modificata contenente grid con oltre 100 colonne. Ogni singola riga caricata in queste grid larghe istanzia un enorme set di variabili grid buffer nella heap di memoria JAS. Ciò moltiplica l'impronta di memoria quando cinquanta o più utenti simultanei interrogano grandi dataset.
Gli sviluppatori aggravano questa pressione sulla memoria utilizzando funzioni di sistema come 'Copy Grid Row To Grid Buffer' all'interno degli eventi Grid Record Is Fetched o Write Grid Line-Before. Questa funzione di sistema non si limita a fare riferimento alla memoria esistente; duplica l'intera struttura dati di 100 colonne all'interno della heap di memoria JAS. Quando eseguita sequenzialmente su un fetch di 1.000 righe, questa allocazione ridondante innesca pause aggressive di garbage collectionUn processo automatico della JVM che tenta di recuperare memoria eliminando oggetti che non sono più utilizzati dall'applicazione. della JVM che bloccano il client web.
Un errore comune è nascondere le colonne inutilizzate tramite Event Rules utilizzando la funzione di sistema Set Grid Column Attribute. Nascondere visivamente una colonna non impedisce al server JAS di recuperare, elaborare e serializzare quei dati. Eliminare completamente queste colonne morte dal layout della grid, invece di nasconderle tramite ER, riduce la dimensione del payload di serializzazione di oltre la metà e stabilizza il profilo di memoria del server web. Ad esempio, ridurre una grid da 120 colonne ai 20 campi effettivamente richiesti riduce il sovraccarico di memoria per riga di circa l'80%.
Gestione di grandi dataset con elaborazione asincrona
Una sessione web bloccata durante il salvataggio di una grid da 500 righe è tipicamente causata dall'esecuzione sincrona di una pesante logica di validazione. Quando si inserisce una BSFN di validazione personalizzata negli eventi della grid "Row Exit & Changed - Asynchronous" o "Row Is Selected", gli sviluppatori devono esplicitamente contrassegnare tale BSFN come asincrona nelle proprietà delle Event Rules. Questa opzione di configurazione indica al server HTML di restituire immediatamente il controllo al livello di presentazione, impedendo all'interfaccia utente di bloccarsi mentre l'enterprise server elabora la logica di business in un thread parallelo.
Per elaborare calcoli pesanti su una grid di grandi dimensioni senza degradare l'esperienza utente, sposta l'esecuzione nell'evento "Post Button Clicked" di un pulsante nascosto. In un'APPL di allocazione dell'inventario di un cliente di distribuzione, abbiamo sostituito i calcoli della grid in linea con un sistema in cui il pulsante "OK" scrive le righe modificate in una cache di memoria e poi clicca programmaticamente su un pulsante "Process" nascosto. L'esecuzione della logica di calcolo massivo nell'evento "Post Button Clicked" di questo controllo nascosto garantisce che il thread primario della grid rimanga reattivo, evitando le trappole dell'elaborazione sincrona che causano latenza nel browser.
Quando un utente tenta di aggiornare massivamente più di 200 righe della grid contemporaneamente, elaborare tali modifiche all'interno del thread interattivo dell'APPL è un anti-pattern architetturale. Un approccio più efficiente consiste nello scrivere i dati della grid modificati in una tabella di staging personalizzata e attivare immediatamente una UBEUniversal Batch Engine: un processo che esegue report o elaborazioni massive di dati in background senza interazione dell'utente. di sottosistema (come un driver personalizzato della serie R55) o chiamare un'OrchestrationUno strumento moderno di JD Edwards per automatizzare processi complessi e integrare sistemi esterni tramite servizi web. basata su AIS per elaborare il batch in background. Questo spostamento mantiene pulito il thread di runtime interattivo ed elimina gli errori di timeout del gateway HTTP 504 che si verificano tipicamente quando WebLogic o un bilanciatore di carico F5 terminano una connessione dopo la soglia predefinita di 120 secondi.
Strumenti diagnostici per individuare i colli di bottiglia della Grid
Gli amministratori di database presentano frequentemente un piano di esecuzione SQL inferiore al millisecondo per dimostrare la salute del database, eppure una grid standard come P42101 o P4312 può comunque impiegare più di dieci secondi per renderizzare 200 righe. Questa discrepanza si verifica perché le metriche a livello di database non rilevano la latenza a livello applicativo introdotta dall'esecuzione delle Event Rules (ER). Quando le ER vengono eseguite su eventi come Grid Record Is Fetched, il tempo speso nell'elaborazione delle assegnazioni di variabili e nell'I/O di tabella avviene interamente al di fuori della visuale del motore del database.
Isola questa latenza correlando il jas.log con un'analisi mirata del call stackL'elenco ordinato delle funzioni e dei processi che il sistema sta eseguendo in un determinato momento. nel jdedebug.log sull'Enterprise Server. Il jas.log cattura il timestamp preciso in cui il server HTML richiede i dati della grid, mentre il jdedebug.log traccia l'esatto costo in millisecondi di ogni esecuzione di BSFN attivata dalle ER. L'analisi di questi log rivela il sovraccarico cumulativo di centinaia di fetch F4101 sequenziali che avvengono per ogni riga della grid.
Utilizza il Performance Monitor all'interno di Server Manager per tracciare i roundtrip da JAS a Enterprise Server. Questo strumento espone il volume di salti di rete generati da eccessive chiamate BSFN dal tier di presentazione. Se un singolo caricamento di una grid di 100 righe produce centinaia di roundtrip, hai un indicatore chiaro che la logica appartiene a una business function C consolidata piuttosto che a singole righe di ER.
Enfin, utilizza l'Event Rules Debugger per scorrere i loop della grid e osservare gli stati delle variabili in tempo reale. Ciò consente di individuare errori di logica condizionale che causano loop infiniti o fetch ridondanti dei medesimi record di dati anagrafici. Questo tracciamento pratico è il modo più diretto per verificare perché una grid stia eseguendo decine di letture di database non necessarie per una singola riga.
L'ottimizzazione delle performance della grid in un ambiente 9.2.x è solo uno strato dello stack; i colli di bottiglia risiedono spesso in un'inefficiente gestione della cache delle BSFN o in piani di esecuzione SQL non ottimizzati. Se le tue applicazioni personalizzate sono lente, isolare queste inefficienze a livello applicativo è il primo passo per ripristinare la stabilità del sistema e la produttività degli utenti.
Per assistenza nell'audit delle tue applicazioni EnterpriseOne personalizzate o nell'ottimizzazione delle performance del tuo server JAS, contatta il nostro team di consulenza ERP enterprise per pianificare una revisione tecnica.
