

Quando una APPLApplicazione interattiva di JD Edwards utilizzata dagli utenti per visualizzare o inserire dati. Find/Browse personalizzata che interroga le tabelle F4211 o F0911 impiega più di qualche secondo per restituire le righe nella gridLa griglia o tabella all'interno di una schermata JDE dove vengono visualizzati i record., gli sviluppatori tendono immediatamente a incolpare l'indicizzazione del database o la latenza di rete. Nella stragrande maggioranza degli audit di performance che eseguo, il collo di bottiglia è auto-inflitto all'interno di JDE. La correlazione tra le performance di una form di ricerca personalizzata JDE APPL e il design della business viewOggetto JDE che definisce quali tabelle e campi vengono utilizzati da un'applicazione o un report. è diretta: l'unione di dozzine di colonne non necessarie in una BSVW personalizzata costringe il database a eseguire costosi table scanOperazione lenta in cui il database legge ogni singola riga di una tabella per trovare i dati. invece di puliti index seekOperazione veloce in cui il database usa un indice per saltare direttamente ai dati richiesti..
Per correggere una schermata di ricerca lenta, non limitarti a chiedere al tuo DBA di creare un altro indice composito personalizzato. Invece, rifattorizza l'applicazione per allineare le mappature Grid Line-to-Business View con le chiavi primarie esistenti e analizza l'evento Grid Record is FetchedEvento software di JD Edwards che viene eseguito ogni volta che una riga di dati viene caricata nella griglia. alla ricerca di loop di I/O nascosti sulle tabelle F4101 o F0101. Limitare la tua BSVW personalizzata ai soli campi essenziali (tipicamente meno di una dozzina) richiesti per i criteri di ricerca e la visualizzazione iniziale della grid può ridurre i tempi di esecuzione SQL su una tabella con decine di milioni di righe a meno di un quarto di secondo.
Il costo delle Business View sovraccariche su tabelle di grandi dimensioni
Vediamo cosa succede nel database quando uno sviluppatore crea una form find/browse personalizzata utilizzando una business view standard come V4211A, o una personalizzata che richiama tutti i campi dalla tabella F4211 Sales Order Detail. Il middleware del database JDE (JDBComponente software di JD Edwards che gestisce la comunicazione tra l'applicazione e il database.) genera un'istruzione SELECT contenente ogni singola colonna definita in quella business view, indipendentemente dal fatto che quei campi siano posizionati sulla form o nella grid. Per la F4211, che contiene più di cento colonne, questo pattern di design pigro costringe il database a recuperare e trasmettere centinaia di byte di dati inutili per riga, gonfiando il payload di rete e sprecando memoria del buffer poolArea della memoria del database utilizzata per memorizzare temporaneamente i dati letti dal disco. del database per dati che non verranno mai visualizzati dall'utente.
Per prevenire questo sovraccarico su form di ricerca ad alto volume, gli sviluppatori devono creare una business view dedicata e snella, contenente solo l'essenziale. Ciò significa selezionare solo le chiavi primarie (SDKCOO, SDDOCO, SDDCTO, SDLNID), i campi specifici utilizzati come filtri di ricerca nell'header e le poche colonne effettivamente renderizzate nella grid. Ridurre una business view da oltre cento colonne a una o due dozzine può tagliare drasticamente i tempi di esecuzione SQL e ridurre significativamente il consumo di memoria dell'application server, spesso fino a due terzi, durante le sessioni utente intense.
Un altro comune killer delle performance è l'unione di tabelle all'interno della business view per visualizzare campi descrittivi, come l'unione di F4211 a F4101 sul short item number (SDITM). Se queste chiavi di join non sono correttamente allineate con gli indici del database esistenti, l'ottimizzatore del database ignorerà completamente l'indice primario della F4211. Invece di un rapido index range scanOperazione in cui il database legge un intervallo di valori da un indice, più efficiente di una scansione totale., il database esegue un costoso nested loopMetodo di unione tabelle in cui il database confronta ogni riga di una tabella con le righe di un'altra. o un hash join che innesca un full table scan su milioni di righe di ordini di vendita, trasformando una ricerca da meno di un secondo in un blocco del sistema di diversi minuti.
Come la mappatura dei criteri di ricerca determina la selezione degli indici
Quando un utente clicca su "Find" in una form Find/Browse, l'EnterpriseOne HTML server traduce i campi Form Control (FC) mappati come filtri in una clausola SQL WHERE dinamica. Se la tua applicazione personalizzata interroga una tabella ad alto volume come la F4211, che spesso supera i diversi milioni di righe, l'ottimizzatore del database si affida alla corrispondenza di quei campi filtro con le strutture degli indici. Mappare un campo filtro a una colonna non indicizzata costringe il database a valutare ogni riga, trasformando una query da millisecondi in un drenaggio di sistema di diversi secondi.
Le ricerche con wildcardCarattere jolly (come %) usato nelle ricerche per rappresentare uno o più caratteri ignoti. non limitate che utilizzano il segno di percentuale su colonne prive di indicizzazione adeguata causano un grave degrado delle performance. Quando un utente inserisce un valore parziale in un campo descrittivo non indicizzato, il motore del database abbandona gli index range scans e ricorre a un full table scan. Per evitare ciò, gli sviluppatori devono configurare le proprietà della form per limitare l'uso delle wildcard su campi di ricerca ad alto volume o imporre l'inserimento obbligatorio su campi indicizzati.
Gli sviluppatori devono far corrispondere i controlli dei criteri di ricerca direttamente alle colonne principali degli indici primari o secondari della tabella. Ad esempio, se hai un indice secondario personalizzato sulla tabella Sales Order Detail (F4211) definito con Business Unit (MCU), Order Type (DCTO) e Line Number (LNID), i campi FC della form di ricerca devono essere presentati in quell'esatto ordine gerarchico. Omettere la colonna principale MCU e filtrare solo per DCTO rende inutile l'indice secondario, poiché l'ottimizzatore non può eseguire un index seek senza la colonna chiave più a sinistra.
Configurare l'operatore di confronto in Form Design Aid è altrettanto critico. Selezionare un operatore di confronto "Like" invece di "Equal To" su campi numerici, come lo Short Item Number (ITM), impedisce all'ottimizzatore del database di eseguire index seek precisi. Il database è costretto a trattare il campo numerico come una stringa di caratteri per valutare il pattern, il che può aumentare l'utilizzo della CPU sul database server di quasi la metà durante le ore di punta.
La trappola dell'evento Grid Rec is Fetched e i loop di esecuzione ER
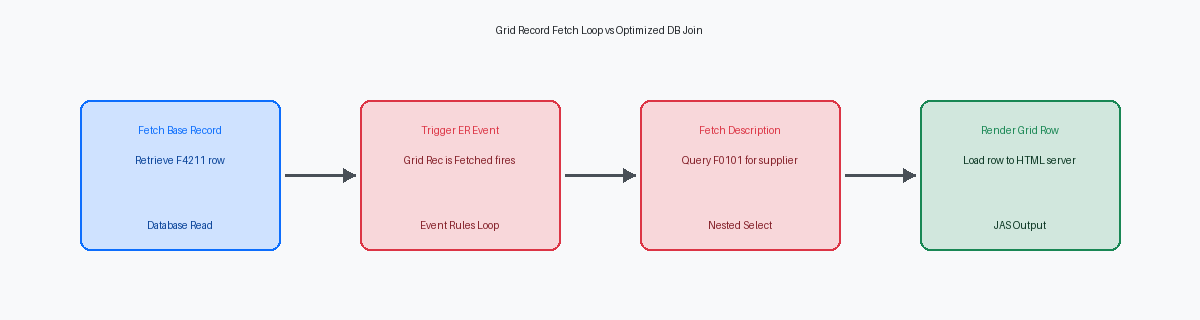
Inserire fetch del database o complesse business function CProgrammi scritti in linguaggio C che eseguono logiche di business complesse all'interno di JD Edwards. all'interno dell'evento Grid Record is Fetched è l'errore architettonico più comune che vedo nelle applicazioni Find/Browse personalizzate. Gli sviluppatori usano spesso questo evento per recuperare dati supplementari, come il recupero di un nome alfa dalla tabella Address Book Master (F0101) per ogni riga. Se una query utente restituisce diverse centinaia di record nella grid, una singola business function di fetch F0101 all'interno di questo evento viene eseguita centinaia di volte. Quella che sembra una chiamata al database trascurabile a livello di millisecondi durante lo sviluppo locale, si trasforma in un ritardo cumulativo di diversi secondi in produzione quando moltiplicata per quelle centinaia di righe.
Per eliminare questo loop di esecuzione, è necessario spostare l'onere del recupero dati sul motore del database o sulla memoria. Invece di eseguire chiamate JDB_Fetch o BSFN seriali per riga, modifica la business view sottostante per unire direttamente le tabelle di descrizione, come il collegamento di F4211 a F4101 per le descrizioni degli articoli. Se un join diretto tra tabelle è impossibile a causa di una logica di business complessa, sostituisci gli accessi al database riga per riga con un pattern di cacheArea di memoria veloce utilizzata per conservare dati consultati frequentemente, evitando nuovi accessi al database. basato sulla memoria. L'uso delle APIInsieme di procedure e funzioni che permettono a diverse applicazioni di comunicare tra loro. di cache JDE come JDEDB_CreateCache e JDB_FindKey all'interno delle tue Event Rules ti consente di recuperare i dati di riferimento una sola volta ed eseguire ricerche in memoria ad alta velocità.
Per le form di ricerca ad alto volume che elaborano migliaia di righe, la strategia più efficace è disabilitare completamente l'evento Grid Record is Fetched. Puoi pre-caricare dati master statici, come termini di pagamento o centri di costo, in una cache runtime personalizzata durante l'evento Post Dialog is Initialized. Interrogando queste tabelle statiche una sola volta all'avvio della form, puoi popolare le colonne della grid utilizzando veloci lookup in memoria invece di innescare istruzioni SQL ripetitive. L'implementazione di questo cambiamento su una form di ricerca di ordini di lavoro ad alto utilizzo riduce tipicamente i tempi di caricamento dello schermo da diversi secondi a frazioni di secondo.
Configurazione del caricamento Grid: Page-at-a-Time vs. Load-All
Le grid JDE standard operano in modalità Page-at-a-Time, recuperando solo da 10 a 50 record per soddisfare i requisiti di visualizzazione iniziale. Questo comportamento predefinito riduce al minimo l'impronta di memoria sull'HTML server e mantiene il tempo di esecuzione SQL iniziale sotto il quarto di secondo. I problemi sorgono quando gli sviluppatori abilitano la proprietà Load All Grid Records per supportare l'ordinamento lato client o i requisiti di esportazione senza considerare il volume della tabella sottostante. In un ambiente di produzione dove la F4211 contiene decine di milioni di righe, una configurazione Load All senza filtri obbligatori rappresenta un rischio per la stabilità del middleware.
Quando un utente esegue una ricerca aperta su una grid Load All, il server JASJava Application Server, il componente web che gestisce l'interfaccia utente di JD Edwards. tenta di costruire l'intero oggetto grid in memoria prima di renderizzare la risposta. Vediamo costantemente esaurimento della heap JVMLa porzione di memoria dedicata alla Java Virtual Machine per gestire gli oggetti dell'applicazione. del JAS a circa 10.000 - 15.000 record, a seconda della larghezza della business view e del numero di colonne nascoste. Questa pressione sulla memoria innesca cicli aggressivi di Garbage CollectionProcesso automatico di gestione della memoria che libera lo spazio occupato da oggetti non più utilizzati., facendo impennare l'utilizzo della CPU sul web server e risultando infine in un 504 Gateway Timeout o in una Web Client Exception per l'utente finale.
Gli sviluppatori devono mitigare questo rischio utilizzando la funzione di sistema Set Max Rows Spoken all'interno degli eventi Dialog is Initialized o Find Button Clicked. Limitare le righe restituite a 500 o 1.000 record fornisce dati sufficienti per l'uso funzionale, garantendo al contempo che la heap del JAS rimanga stabile. Se la query supera questo limite, il sistema interrompe il recupero, impedendo al payload XML di gonfiarsi a una dimensione che il browser o la heap Java non possono gestire.
La logica di validazione nell'evento Button Clicked dovrebbe bloccare esplicitamente le ricerche in cui i campi indice critici come DCTO, KCO o AN8 sono lasciati nulli. Controllando lo stato di questi campi filtro e utilizzando la funzione Set Control Error, costringi gli utenti a fornire criteri selettivi che il database può effettivamente ottimizzare. Questo guardrail architettonico è più efficace di qualsiasi query governor a livello di database, poiché arresta il drenaggio delle risorse a livello applicativo, riducendo la frequenza degli errori "Out of Memory" del JAS dell'80% - 90% in ambienti di distribuzione ad alto volume.

Analisi dell'esecuzione SQL tramite i log CallObject e JAS
Una form di ricerca che si blocca per dieci secondi o più raramente è un errore di logica applicativa; è quasi sempre un'istruzione SQL non ottimizzata che colpisce una tabella con milioni di righe come la F4211 o la F0911. Non è possibile diagnosticare questi colli di bottiglia solo dal Form Design Aid (FDA) perché il middleware JDB astrae il livello fisico del database. È necessario catturare l'SQL grezzo abilitando il logging CallObject (jdedebug.log) sul fat client o tramite Server Manager per una specifica sessione web per vedere esattamente cosa viene chiesto al database.
Nel jdedebug.log, cerca la stringa "SELECT ... FROM" seguita dalla riga "OCI Execute" o "SQL Execute". Questo fornisce il tempo di esecuzione dell'istruzione SQL nel jdedebug.log in microsecondi, consentendo di individuare quale fetch specifico sta bloccando l'interfaccia utente. Contemporaneamente, i log di debug JAS consentono di correlare l'azione dell'utente JDE a uno specifico ID thread, assicurandoti di non inseguire un'istruzione fantasma da una UBEUniversal Batch Engine, il motore che esegue i report e i processi massivi in background in JD Edwards. in background o da una sessione utente diversa.
Copia l'istruzione SQL letterale dal log, inclusi i segnaposto dei parametri, ed esegui un EXPLAIN PLANStrumento del database che mostra il percorso scelto per eseguire una query SQL e i relativi costi. nel tuo studio di gestione del database. È un malinteso comune che JDE utilizzi sempre l'indice definito nella Business View (BSVW). Se l'utente filtra su una colonna non indicizzata nell'header della grid, l'ottimizzatore del database potrebbe optare per un full table scan, indipendentemente da come avevi previsto che la ricerca si comportasse durante la fase di sviluppo.
Il degrado delle performance deriva anche da istruzioni SQL ad alta frequenza e bassa durata che indicano nested loop. Se le tracce mostrano centinaia di istruzioni SELECT identiche che colpiscono la F0101 in un breve intervallo di pochi secondi, probabilmente hai una logica nell'evento Grid Rec is Fetched che esegue un fetch manuale per i dati master. Questa elaborazione riga per riga aggiunge un enorme sovraccarico alla comunicazione tra JAS ed Enterprise server. Spostare questi fetch nel join iniziale della BSVW o utilizzare una BSFN C con un handle memorizzato in cache può ridurre quelle centinaia di viaggi verso il database a una singola esecuzione.
L'ottimizzazione di una business view APPL personalizzata comporta molto più della semplice selezione delle colonne; richiede un'immersione profonda nel piano di esecuzione SQL sottostante e nella selezione degli indici. Quando il tuo ambiente EnterpriseOne 9.2 è sintonizzato per allineare il design applicativo con le realtà del database, elimini la latenza che gli utenti finali scambiano per instabilità del sistema.
