

Molte business function (BSFN)Componenti logici di JD Edwards che contengono codice C o Java per eseguire calcoli o processi aziendali. in C personalizzate nelle installazioni legacy di JDEJD Edwards EnterpriseOne: un sistema ERP (Enterprise Resource Planning) completo sviluppato da Oracle. sono monoliti immantenibili di migliaia di righe, dove la logica di validazione, le ricerche nella cache di memoria e l'I/O diretto sulle tabelle sono irrimediabilmente intrecciati. Quando il volume delle transazioni aumenta drasticamente—come un batch di decine di migliaia di righe di ordini di vendita EDIElectronic Data Interchange: standard per lo scambio elettronico di documenti commerciali tra sistemi informatici diversi. che colpiscono simultaneamente lo stack di chiamate—questa mancanza di architettura causa gravi blocchi del database, memory leakUn errore di gestione della memoria che si verifica quando un programma non rilascia la RAM non più necessaria. e guasti ai kernel enterpriseI processi fondamentali del server JD Edwards che gestiscono l'esecuzione della logica di business e le connessioni..
Questa guida fornisce un esempio pratico di sviluppo BSFN JDE per validare la logica di business in C, dimostrando come isolare le routine di validazione volatili dallo stato persistente del database. Disaccoppiando nettamente le ricerche nella cache di memoria, utilizzando le APIApplication Programming Interface: un insieme di definizioni e protocolli per la creazione e l'integrazione di software applicativi. native jdeCacheUn set di API native di JD Edwards per gestire la memorizzazione temporanea di dati nella memoria RAM., dagli aggiornamenti delle tabelle fisiche, è possibile ridurre significativamente i round-trip al database, spesso di oltre tre quarti, ed eliminare i rollbackOperazione di ripristino che riporta il database a uno stato precedente in caso di errore durante una transazione. delle transazioni sotto carichi di lavoro enterprise pesanti.
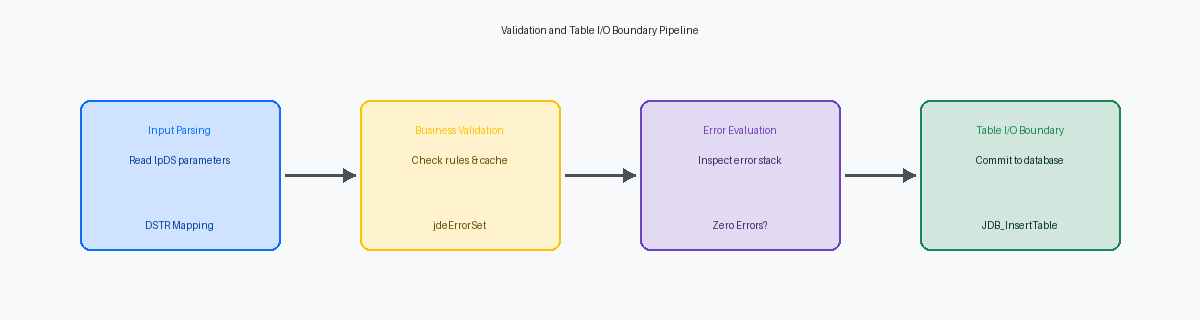
Progettazione della Data Structure della BSFN per la Validazione
In oltre due decenni di revisione di business function in C personalizzate, gli enterprise architect trovano frequentemente sviluppatori che scaricano dozzine di campi non organizzati dalla tabella F4101 Item Master direttamente in una singola Data Structure (DSTR)La definizione dei parametri di input e output che una Business Function utilizza per scambiare dati con il sistema.. Questo design pattern garantisce mal di testa in fase di manutenzione e colli di bottiglia nelle prestazioni durante l'elaborazione batch ad alto volume in UBEUniversal Batch Engine: il motore di JD Edwards per l'esecuzione di report e processi di elaborazione massiva. come R41110A. Una DSTR di validazione ben progettata deve segregare nettamente i flag di controllo dell'input, i valori di business come LITM o MCU e i campi di stato dell'output per mantenere un footprint di memoria prevedibile.
Per prevenire la corruzione della memoria e il troncamento silenzioso dei dati all'interno del codice C, è necessario imporre l'uso di elementi standard del Data DictionaryIl catalogo centrale di JD Edwards che definisce tutti i campi dati, i loro tipi e le regole di validazione. come EV01 per i flag booleani e ERRC per gli indicatori di errore. Il passaggio di un campo carattere personalizzato invece di EV01 può portare a disallineamenti quando il motore JDE mappa il buffer del middlewareSoftware che agisce come strato intermedio per facilitare la comunicazione tra diverse applicazioni o componenti software. sul puntatore lpDS. Limitare i flag di controllo a EV01 e ERRC garantisce che il compilatore allinei correttamente i membri della struttura su limiti di 4 byte.
La progettazione della DSTR con un parametro action code dedicato (utilizzando l'elemento DD ACTION, dove '1' rappresenta Validate e '2' rappresenta Write) consente a una singola BSFN di gestire la validazione interattiva multi-pass in applicazioni come P4101. Durante gli eventi iniziali control-exited-and-changed, l'APPL passa '1' per eseguire una validazione a basso sovraccarico senza committare i record del database. Una volta che l'utente clicca su OK, la stessa BSFN viene invocata con l'action code '2' per eseguire l'inserimento finale all'interno della transazione.
Ogni parametro in questa DSTR deve mapparsi direttamente alla corrispondente typedef struct generata dall'Object Management Workbench (OMW)L'ambiente di sviluppo integrato di JD Edwards per la gestione del ciclo di vita degli oggetti. all'interno del file header della BSFN. Quando si modifica una DSTR, rigenerare immediatamente questo header per prevenire offset dei puntatori quando il compilatore C compila la DLLDynamic Link Library: file che contengono librerie di funzioni caricate ed eseguite dai programmi a runtime.. Documentare la direzione di ogni membro della struct (IN, OUT, BOTH) all'interno di questo header garantisce che gli sviluppatori non sovrascrivano inavvertitamente i valori di input in sola lettura.
Implementazione del Pattern di Validazione C e API di Errore
Nelle business function personalizzate come B5501001, gli sviluppatori spesso non riescono a collegare i fallimenti della validazione direttamente ai controlli della form interattiva, lasciando gli utenti davanti a schermi vuoti senza alcuna indicazione di cosa sia fallito. Il framework standard di gestione degli errori di EnterpriseOne risolve questo problema affidandosi all'API jdeErrorSet per associare specifici codici di errore del Data Dictionary ai controlli runtime. Quando si scrive codice C, è necessario passare l'elemento DD esatto, come 0002 (Record Invalid) o 4115 (Lot Status Invalid), garantendo che il client HTML evidenzi in rosso la colonna della griglia o il campo della form incriminato.
Per far funzionare questa mappatura, il passaggio della struttura lpBhvrCom—il puntatore alle specifiche di comportamento comuni—è obbligatorio. Senza questo puntatore, il motore runtime non può propagare l'errore verso l'alto fino al container APPL interattivo o registrare il fallimento all'interno di un processo batch UBE. In un recente aggiornamento dalla versione 9.1 alla 9.2 per un distributore globale, abbiamo risolto dozzine di funzioni C personalizzate in cui gli sviluppatori avevano passato NULL invece di lpBhvrCom, il che sopprimeva silenziosamente errori critici di allocazione dell'inventario durante l'inserimento degli ordini di vendita.
Un pattern di validazione pulito all'interno di B5501001 utilizza un controllo logico sequenziale che interrompe l'elaborazione ulteriore nell'istante in cui viene riscontrato un errore di gravità critica. Invece di annidare dieci livelli di istruzioni if, si valuta ogni regola di business sequenzialmente, si chiama jdeErrorSet e si restituisce immediatamente ER_ERROR in caso di fallimento. L'hardcoding delle stringhe dei messaggi di errore direttamente all'interno del codice sorgente C è un grave anti-pattern che interrompe il supporto multilingua e scavalca il motore JDE centralizzato. Mappare sempre i fallimenti della validazione a elementi definiti del Data Dictionary garantisce che, quando Oracle aggiorna una routine di validazione standard, il codice personalizzato erediti il comportamento di sistema aggiornato senza richiedere una ricompilazione. Questo approccio mantiene pulito il footprint del codice personalizzato e garantisce la compatibilità con le future Tools Release.
Disaccoppiamento delle Ricerche in Cache dalle Transazioni del Database
Interrogare tabelle fisiche come F4102 o F41021 all'interno di un loop di elaborazione di migliaia di record degrada le prestazioni di diverse volte rispetto alle ricerche nella cache di memoria. Quando si validano record di inventario massivi in business function C personalizzate, colpire ripetutamente il database per gli stessi dati master è un comune fallimento architettonico. L'alternativa standard è l'utilizzo delle API JDE User Cache come jdeCacheInit e jdeCacheFetch per caricare i dati di riferimento una sola volta in memoria durante l'inizializzazione.
Un design di validazione pulito isola queste ricerche basate sulla memoria in funzioni helper interne dedicate all'interno del file sorgente C, mantenendo pulita la logica di business principale. La creazione di un helper localizzato come Ixxxxxx_RetrieveItemCache mantiene la funzione JDEBFRTN primaria focalizzata sulle regole di business piuttosto che sulla manipolazione dei puntatori della cache. Questa separazione delle responsabilità garantisce che, se si modifica la struttura della chiave della cache, la modifica sia limitata a una singola funzione helper.
La mancata gestione del ciclo di vita di queste allocazioni di memoria introduce gravi rischi di stabilità per l'Enterprise Server. La corretta terminazione della cache tramite jdeCacheTerminate è fondamentale per prevenire memory leak che alla fine esauriscono l'heap e mandano in crash i kernel callObject. In un ambiente ad alto volume che elabora decine di migliaia di righe di ordini di vendita al giorno, un handle di cache non rilasciato scatenerà una condizione di out-of-memory sull'Enterprise Server nel giro di poche ore, forzando un riavvio non pianificato del servizio.
Per prevenire conflitti tra sessioni concorrenti, configurare la cache con un nome univoco utilizzando il numero di lavoro (job number) dell'utente o l'ID sessione. Ciò impedisce a più sessioni HTML che eseguono la stessa BSFN di corrompere reciprocamente i dati di validazione memorizzati nella cache. Sulla Tools Release 9.2.7, l'implementazione di cache con chiave di sessione ha risolto problemi intermittenti di blocco dei record che in precedenza bloccavano una parte significativa dei trasferimenti di magazzino concorrenti, a volte fino al quindici percento.

Definizione del Confine di Table I/O nelle BSFN in C
Nell'elaborazione di transazioni multi-tabella, in particolare quando si aggiornano record di inventario critici nella tabella F41021 Inventory Master, mescolare la logica di validazione con le scritture nel database causa la corruzione dei dati. Abbiamo revisionato modifiche personalizzate al receipt routing in cui lo sviluppatore scriveva direttamente nel database all'interno di un loop, solo per riscontrare un fallimento della validazione a metà del batch. Questo pattern produce record orfani perché metà della transazione è stata committata. La regola deve essere assoluta: le scritture nel database non dovrebbero mai essere eseguite se un qualsiasi passaggio di validazione ha registrato un errore nella struttura LPBHVRCOM.
Separare esplicitamente i passaggi di validazione dai passaggi di scrittura previene scritture parziali e orfane nel database nelle operazioni multi-tabella. Ciò significa iterare prima attraverso l'intera Data Structure di input o la cache, valutare le regole di business e memorizzare gli errori in memoria prima di eseguire una singola riga di I/O. Se il loop di validazione segnala anche un solo errore, si esce immediatamente dalla BSFN. Questa netta separazione riduce la contesa del database, poiché si evita di mantenere blocchi su tabelle come la F41021 mentre si attende il completamento delle routine di validazione.
Per le tabelle personalizzate, l'uso delle API JDB_OpenTable e JDB_InsertTable all'interno di un confine di transazione esplicito garantisce una stretta conformità ACIDInsieme di proprietà (Atomicità, Consistenza, Isolamento, Durabilità) che garantiscono l'affidabilità e la sicurezza delle transazioni nel database.. È necessario passare l'handle di sessione hUser dalla struttura lpBhvrCom direttamente in queste API JDB per associarle alla transazione attiva. Questo legame garantisce che se la transazione padre esegue il rollback, anche gli inserimenti nelle tabelle personalizzate eseguano il rollback con essa.
Una trappola comune è eseguire aggiornamenti delle tabelle all'interno di un loop prima di verificare che tutte le righe di input nel payload siano completamente valide. In un caricamento batch di fatture di grandi dimensioni, l'esecuzione di un aggiornamento su una delle prime righe mentre una riga successiva contiene un branch/plant non valido crea un subledger incoerente. Validare tutte le righe in anticipo e, solo quando il conteggio degli errori è zero, avviare il loop di transazione per committare le modifiche.
Un Esempio Concreto di Codice di Validazione BSFN in C
Un punto di fallimento comune nelle business function C personalizzate è l'ingombro della funzione di esportazione principale con la logica di validazione, il che offusca la gestione della memoria e degli errori. Per evitare ciò, il punto di ingresso principale della business function deve analizzare la struttura lpDS e inizializzare le variabili di stato interne in modo sicuro prima che inizi qualsiasi elaborazione. Delegare il lavoro pesante a una funzione helper interna, I5501001_ValidateAndWrite, funge da orchestratore per mantenere la funzione di esportazione principale pulita e leggibile.
All'interno di questa architettura, i controlli espliciti sui puntatori nulli sui tipi di dati JDE come MATH_NUMERICUn tipo di dato specifico di JD Edwards utilizzato per gestire calcoli numerici ad alta precisione. e JDEDATELa struttura dati interna utilizzata da JD Edwards per rappresentare e manipolare le date nel codice C. prevengono violazioni di memoria e crash di sistema che possono abbattere un intero kernel callObject. Se si passa un puntatore non allocato a FormatMathNumeric o si tenta di confrontare una struttura di data non inizializzata, le prestazioni del kernel terminano immediatamente. L'implementazione di una rigorosa validazione dei puntatori al confine di I5501001_ValidateAndWrite garantisce che la logica fallisca in modo controllato, restituendo un errore strutturato allo stack di chiamate invece di un core dump.
La seguente implementazione dimostra questa segregazione strutturale, mostrando come gestiamo i puntatori strutturali, eseguiamo i controlli degli errori ed eseguiamo una scrittura in tabella condizionale utilizzando le API JDE native.
static JDEDB_RESULT I5501001_ValidateAndWrite(LPBHVRCOM lpBhvrCom, LPVOID lpVoid, LPDSD5501001 lpDS) {
HREQUEST hRequest = NULL;
JDEDB_RESULT jdDbResult = JDEDB_PASSED;
if (lpDS == NULL || &lpDS->mnAddressNumber == NULL || &lpDS->jdDateUpdated == NULL) {
return JDEDB_FAILED;
}
if (FormatMathNumeric(NULL, &lpDS->mnAddressNumber) != ID_SUCCESS) {
return JDEDB_FAILED;
}
if (lpDS->cActionCode == 'A') {
jdDbResult = JDB_OpenTable(lpBhvrCom->hEnv, _J("F5501001"), NULL, NULL, NULL, NULL, &hRequest);
if (jdDbResult == JDEDB_PASSED) {
/* Logica di inserimento eseguita solo dopo una validazione riuscita */
JDB_CloseTable(hRequest);
}
}
return jdDbResult;
}Debugging e Validazione dell'Esecuzione delle BSFN in C
I fallimenti della validazione locale su un fat client si verificano spesso perché gli sviluppatori si affidano ai popup runtime standard invece di un tracciamento profondo dell'esecuzione. Per isolare un fallimento della validazione nel codice C personalizzato, collegare il debugger di Visual Studio direttamente al processo active_run.exe attivo sul client di sviluppo. Questo consente di impostare breakpoint all'interno della directory sorgente (b9\DV920\source\B55VAL.c) e procedere riga per riga attraverso la business function mentre il web client locale attiva le Event Rules.
Affidarsi al debugging interattivo fa perdere il contesto transazionale, motivo per cui è necessario analizzare il jdedebug.log per tracciare l'esatta sequenza di chiamate API e istruzioni SQL. Cercare in questo log le API JDB_OpenTable e JDB_Fetch per confermare i confini delle query. Una JDB_ClearSelection fuori posto può causare un passaggio di validazione silenzioso su un record errato, il che è facilmente individuabile in un file di log di migliaia di righe se si filtra per gli ID delle tabelle personalizzate.
Il codice che gira perfettamente su un fat client locale può fallire catastroficamente sotto carico su un enterprise server a causa della corruzione della memoria. Monitorare i log del kernel callObject sul server HTML per identificare memory leak o puntatori non inizializzati che si manifestano solo in un ambiente multi-threadUna tecnica informatica che permette a un programma di eseguire più operazioni contemporaneamente per migliorare le prestazioni.. Cercare specificamente gli errori COB0000012 o terminazioni improvvise del kernel, che tipicamente indicano che il codice C ha scritto oltre la dimensione allocata di una Data Structure o non è riuscito a liberare un puntatore di memoria allocato tramite jdeAlloc.
Per allontanarsi dai cicli di test manuali, automatizzare la validazione della logica di business C utilizzando JD Edwards EnterpriseOne OrchestratorUno strumento di JD Edwards per automatizzare processi e integrare sistemi esterni tramite servizi web REST.. L'esecuzione della BSFN direttamente da una richiesta di servizio personalizzata di Orchestrator scavalca completamente il container APPL. Ciò consente di eseguire suite di test di regressione con dozzine di variazioni di payload distinte in pochi secondi, verificando che la logica di validazione restituisca costantemente i codici di errore corretti senza dover cliccare manualmente attraverso un'interfaccia Power Forms.
Se stai revisionando il tuo codice C personalizzato per eliminare i memory leak o migliorare le prestazioni della Tools Release 9.2.8, la nostra libreria di risorse include approfondimenti tecnici sulla gestione della cache JDE e sulle operazioni di cache utente multi-thread. Contatta il nostro team di enterprise architecture per pianificare una code review delle tue business function legacy.
