

Un singolo jdeAllocAPI di JD Edwards utilizzata per riservare dinamicamente una porzione di memoria RAM durante l'esecuzione di un programma. gestito male o un handle di cache non rilasciato all'interno di una BSFNBusiness Function: un modulo di codice C o Java che esegue logica di business all'interno di JD Edwards. custom chiamata in un UBEUniversal Batch Engine: un processo che esegue report o elaborazioni massive di dati in background. ad alto volume come R42565 può mandare in crash un kernel CallObjectProcesso del server EnterpriseOne responsabile dell'esecuzione delle Business Function richieste dagli utenti. in pochi minuti, terminando istantaneamente decine di sessioni utente attive su quel JVMJava Virtual Machine: l'ambiente software che esegue le applicazioni Java e gestisce le risorse di sistema. specifico. Durante il troubleshooting di ambienti EnterpriseOne 9.2 instabili, spesso tracciamo processi zombie persistenti e leak di memoriaCondizione in cui un programma occupa RAM senza rilasciarla, esaurendo progressivamente le risorse del server. riconducibili a errori comuni di gestione della memoria JDE BSFN nel codice custom, piuttosto che a problemi sottostanti del database o del middleware OCIOracle Cloud Infrastructure: la piattaforma di servizi cloud fornita da Oracle per ospitare applicazioni e database..
Gli strumenti generici di analisi statica C falliscono in questo contesto perché non comprendono le APIApplication Programming Interface: un insieme di procedure e funzioni che permettono a un programmatore di interagire con il sistema JDE. specifiche di JDE—come jdeAlloc, le manipolazioni MATH_NUMERICStruttura dati speciale di JDE usata per gestire calcoli matematici e numeri con decimali in modo preciso. o jdeCacheInit—che governano lo heapArea di memoria RAM utilizzata per l'allocazione dinamica dei dati durante l'esecuzione di un software. di memoria di EnterpriseOne. Analizzando come si comportano i puntatori non inizializzati e le chiamate jdeFree mancanti sotto carichi di transazioni ad alta concorrenza, possiamo sostituire le congetture difensive con correzioni di codice precise e ripetibili che garantiscono la stabilità del server.
Puntatori lpDs non allocati e membri di struttura Null
In oltre due decenni di troubleshooting di business function C custom, poche viste sono frustranti come un file di crash dumpFile che registra lo stato della memoria di un programma al momento di un errore fatale per facilitarne l'analisi. di un kernel CallObject che mostra una violazione di accesso (0xC0000005 su Windows o SIGSEGV su Linux) a uno specifico offset di memoria all'interno di una DLL custom. Questo crash spesso risale a uno sviluppatore che presume che ogni membro del puntatore alla struttura dati JDE (lpDsPuntatore alla struttura dati che contiene i parametri di input e output scambiati con una Business Function.) sia completamente popolato dall'applicazione chiamante. Quando un'applicazione interattiva o un'orchestrazione chiama una business function, i parametri opzionali lasciati non mappati nel toolset non passano valori vuoti o zero di default; passano puntatori nulli.
Tentare di leggere o scrivere in queste posizioni di puntatori non allocati all'interno di una business function C custom scatena un segmentation faultErrore critico che avviene quando un programma tenta di accedere a una zona di memoria non autorizzata o non allocata. immediato sul server enterprise. In un'architettura JDE multi-threadCapacità di un software di eseguire più parti di codice contemporaneamente per ottimizzare le prestazioni., questo non è un fallimento isolato e silenzioso. Un singolo membro di struttura null non gestito non fa fallire solo la transazione corrente; termina l'intero processo del kernel CallObject. Questa terminazione immediata disconnette bruscamente ogni sessione utente attiva attualmente instradata verso quello specifico ID di processo, cancellando i loro dati transazionali non salvati e costringendoli a ristabilire la connessione.
Per prevenire questi outage in produzione, la programmazione difensiva deve essere imposta nei tuoi standard di progettazione. È necessario scrivere controlli NULL espliciti sia per il puntatore padre lpDs che per i suoi singoli membri prima che avvenga qualsiasi assegnazione di memoria, copia di stringhe o manipolazione matematica. Prima di eseguire una funzione di utilità per stringhe o chiamare un'API JDE come MathCopy, verifica che il puntatore di destinazione sia valido utilizzando un blocco condizionale come if (lpDs != NULL && lpDs->lpMember != NULL). L'implementazione di questa validazione di base nelle business function custom più critiche eliminerà la stragrande maggioranza dei riavvii inspiegabili del kernel del server enterprise.
Buffer Overflow delle stringhe con le API di gestione stringhe JDE
Vedo ancora business function C legacy scritte con funzioni di stringa ANSI C standard come strcpy e sprintf invece degli equivalenti API JDE. Queste funzioni standard bypassano la gestione della lunghezza dei caratteri unicode di JDE, che si aspetta JCHARTipo di dato utilizzato da JDE per supportare i caratteri Unicode, occupando solitamente due byte per carattere. (due byte per carattere nel runtime JDE) invece dei caratteri standard a byte singolo. Quando una BSFN custom elabora dati di stringhe multi-byte utilizzando API C standard, calcola erroneamente l'occupazione effettiva di memoria, scrivendo oltre i confini previsti e corrompendo silenziosamente lo heap.
Dichiarare un buffer di destinazione senza tenere conto del terminatore null (ad esempio, usando char szBuffer[11] per una stringa di 10 caratteri ma non riuscendo a scalare per elementi unicode a doppio byte) corrompe la memoria adiacente. Nella Tools ReleaseVersione dei componenti tecnologici di base di JD Edwards che gestiscono l'interazione tra software e hardware. 9.2.5 a 64 bit, le regole di allineamento della memoria rendono questi buffer overflowAnomalia in cui un programma scrive dati oltre il limite di memoria assegnato, corrompendo i dati adiacenti. ancora più distruttivi corrompendo gli indirizzi dei puntatori adiacenti nello heap. Poiché il compilatore a 64 bit allinea le strutture dati a confini rigorosi di 8 byte, un buffer overflow che in precedenza scriveva in byte di padding innocui in un'architettura a 32 bit ora sovrascrive direttamente indirizzi di memoria attivi, scatenando crash immediati del kernel CallObject.
Gli sviluppatori devono dimensionare i buffer custom utilizzando la lunghezza definita nel Data DictionaryDatabase centrale che definisce le proprietà, le lunghezze e le descrizioni di tutti i campi dati usati in JDE. più uno e imporre il controllo dei limiti utilizzando la macro DIM con jdeStrncpy. Sostituire le assegnazioni dirette con jdeStrncpy(lpDs->szTarget, lpDs->szSource, DIM(lpDs->szTarget) - 1) garantisce che l'operazione di copia si interrompa in modo sicuro invece di invadere gli indirizzi di memoria adiacenti. L'implementazione di questo controllo difensivo nel repository C custom previene la corruzione della memoria prima ancora che il codice raggiunga il runtime del server enterprise.

Il Dangling Pointer e il jdeFree mancante
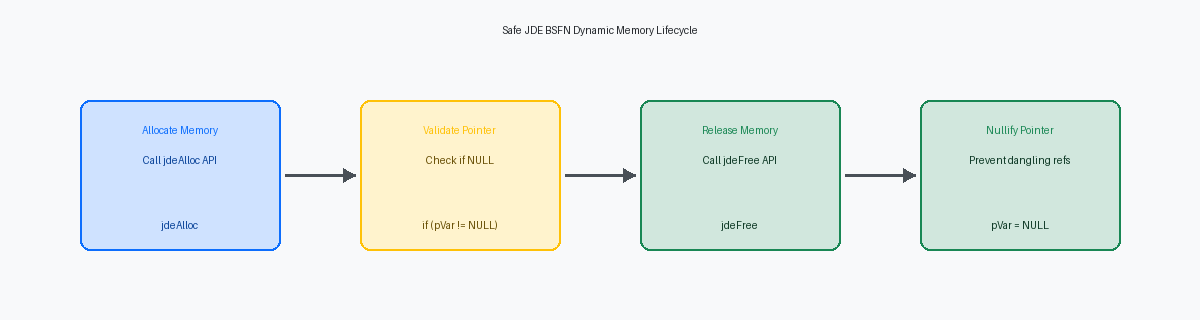
Un piccolo leak di memoria sembra trascurabile durante gli unit test su un client di sviluppo locale, ma diventa fatale in produzione. Considera un UBE custom di riconciliazione inventario che elabora un loop di decine di migliaia di record. Se una business function C custom chiamata all'interno di quel loop alloca memoria tramite jdeAlloc ma non riesce a rilasciarla, quel minuscolo leak si accumula in una perdita significativa su scala di megabyte. Su un'architettura kernel CallObject a 32 bit, o anche sotto pesanti carichi di lavoro enterprise multi-thread su Tools Release a 64 bit come la 9.2.7, questo leak cumulativo esaurisce rapidamente lo spazio di indirizzamento del kernel, scatenando un processo zombie e un fallimento improvviso del job.
Per prevenire questi leak, ogni blocco di memoria heap allocato dinamicamente tramite jdeAlloc deve avere un corrispondente jdeFree garantito prima che la business function termini. Gli sviluppatori spesso disseminano istruzioni return nel loro codice C durante la validazione dei parametri o la gestione degli errori di fetch dal database, bypassando la logica di pulizia in fondo al file sorgente. L'implementazione di un pattern a punto di uscita singolo—utilizzando una variabile locale come idReturnCode e un'istruzione goto Cleanup;—garantisce che il flusso di esecuzione passi sempre attraverso il blocco di deallocazione, indipendentemente da dove si verifichi un errore nella logica di business.
Rilasciare la memoria è solo metà della battaglia; devi anche neutralizzare il puntatore stesso. Immediatamente dopo l'esecuzione di jdeFree(pMyStructure), assegna pMyStructure = NULL; per cancellare l'indirizzo dalla memoria stackArea di memoria utilizzata per gestire le variabili locali e le chiamate alle funzioni durante l'esecuzione.. Questo passaggio esplicito previene gli errori di double-free, che si verificano quando un successivo blocco di gestione degli errori tenta di rilasciare lo stesso puntatore due volte, mandando istantaneamente in crash il motore runtime di JDE. Elimina anche i riferimenti a puntatori sospesi (Dangling PointerUn puntatore che punta ancora a un indirizzo di memoria che è già stato liberato, causando instabilità o crash.), garantendo che qualsiasi lettura accidentale successiva di quella variabile puntatore fallisca in modo prevedibile e sicuro durante lo sviluppo piuttosto che corrompere la memoria silenziosamente in produzione.
Inizializzazioni errate di strutture MathNumeric e Date
Un crash in produzione in un UBE custom di post-elaborazione voucher globali ha rivelato che migliaia di righe di prima nota F0911 avevano importi corrotti a causa di una variabile locale MATH_NUMERIC non inizializzata in una business function C custom. Gli sviluppatori provenienti da un background C standard spesso commettono l'errore di assegnare valori direttamente utilizzando operatori C standard come = invece di utilizzare API specifiche di JDE. Un MATH_NUMERIC è una struttura complessa contenente una rappresentazione in stringa di un array di caratteri, un byte per il segno e metadati sulla posizione decimale. Assegnare direttamente un valore letterale o non inizializzare la variabile lascia spazzatura casuale dello stack in questi campi interni, che il middleware del database inserisce poi direttamente nelle tabelle JDE come F0911 o F4211.
Per prevenire dati spazzatura, alcuni sviluppatori usano memsetFunzione C utilizzata per riempire un blocco di memoria con un valore specifico, spesso usata per azzerare strutture. per pulire l'intera struttura dati, ma questa è una scorciatoia pericolosa. Eseguire memset su una struttura JDE complessa può inavvertitamente cancellare puntatori interni critici, flag di configurazione della valuta o metadati su cui il motore runtime di JDE fa affidamento durante l'esecuzione. Invece, è necessario inizializzare queste variabili utilizzando API designate come ZeroMathNumeric per azzerare in modo sicuro il valore, o ParseNumericString per convertire una rappresentazione in stringa in una struttura numerica JDE valida.
Regole simili si applicano alla struttura JDEDATE, dove la manipolazione manuale dei byte o la copia diretta di stringhe bypassano la logica di validazione del kernel JDE. Se popoli manualmente i componenti di giorno, mese o anno senza validazione, rischi di corrompere il confine di memoria della data, portando a fallimenti silenziosi del database durante gli aggiornamenti della F4211. Usa sempre le API JDE designate come DeformatDate e FormatDate per manipolare in modo sicuro i campi data, assicurando che il motore runtime interpreti correttamente i dati del calendario e mantenga l'integrità strutturale della memoria.
Leak di memoria della Cache JDE e fallimenti nella pulizia della sessione
Una singola sessione utente che esegue l'applicazione di inserimento ordini di vendita P42101 non dovrebbe mai consumare gigabyte di RAM del server enterprise. Eppure, questo esatto scenario si verifica quando le business function custom utilizzano in modo errato le API della cache JDE come jdeCacheInit e jdeCacheAdd. Sebbene queste API siano essenziali per passare dati transazionali tra più chiamate BSFN in una singola sessione, esse allocano memoria direttamente dallo heap del sistema operativo. Se il ciclo di vita di questa memoria non è gestito esplicitamente, il processo del kernel CallObject manterrà quei byte fino a quando l'utente non si disconnette o viene raggiunta la soglia di riciclo del kernel.
La causa principale di questo gonfiore è quasi sempre un percorso di errore non gestito. Quando una validazione fallisce o un inserimento nel database restituisce un errore, gli sviluppatori spesso scrivono un'istruzione return ER_ERROR; anticipata. Se questa uscita avviene prima di eseguire jdeCacheTerminate, lo specifico handle di cache rimane orfano. Il runtime di EnterpriseOne non ha una garbage collectionSistema automatico di gestione della memoria che libera le risorse non più utilizzate dal programma; assente nel codice C di JDE. integrata per le cache utente custom; si affida interamente al codice C per pulire dopo se stesso. In ambienti ad alto volume, un utente che inserisce ripetutamente ordini multi-riga durante un turno standard può facilmente lasciare orfane numerose istanze di cache, portando l'utilizzo della memoria del kernel a limiti critici.
Per prevenire questi leak di memoria, è necessario implementare blocchi di gestione degli errori strutturati che garantiscano la pulizia prima di qualsiasi istruzione di return. Ogni BSFN C custom che utilizza la cache deve avere un punto di uscita unificato, tipicamente etichettato CleanUp:, dove jdeCacheTerminate viene chiamato sistematicamente utilizzando l'esatto handle della cache. Dovresti anche utilizzare l'API jdeCacheTerminateAll durante gli eventi di fine documento o chiusura applicazione per assicurarti che non rimangano riferimenti sospesi in memoria. L'implementazione di questo pattern nei tuoi wrapper custom della P42101 stabilizzerà immediatamente l'utilizzo della RAM del server enterprise, mantenendo il consumo di memoria del kernel sotto i 200MB per sessione utente attiva.
Diagnosticare i crash di memoria tramite i log del kernel CallObject
Un utente che esegue un'applicazione custom di inserimento vendite vede improvvisamente apparire l'errore "COB0000012: CallObject Runtime Error" sullo schermo del client HTML. Questo errore è la firma classica di un kernel CallObject che ha subito una violazione di memoria fatale, tipicamente causata da un puntatore non allocato o da un buffer overflow in una business function C custom. Quando si verifica questa violazione dei confini, il motore EnterpriseOne termina immediatamente il thread, generando un log JDEDEBUG e un corrispondente dump della console sul server enterprise.
Per individuare la causa principale, è necessario bypassare l'errore HTML generico e ispezionare il file di crash dump del server enterprise, come un core dump su Linux o un file .dmp su Windows. Analizzando il call stack all'interno di questo crash dump, gli sviluppatori possono tracciare il percorso di esecuzione fino all'esatto file sorgente C e al numero di riga in cui si è verificato l'accesso alla memoria non valido. Confrontando questo stack trace con il log JDEDEBUG dello stesso ID thread si rivela l'elenco preciso dei parametri passati alla BSFN incriminata subito prima del crash.
Non devi aspettare un crash totale per rilevare problemi di memoria. Il Server ManagerInterfaccia web di Oracle per amministrare, configurare e monitorare i server e i processi di JD Edwards. di Oracle consente agli amministratori di monitorare il consumo di memoria del kernel CallObject in tempo reale, visualizzando metriche come la dimensione della memoria virtuale e il numero di thread. Se l'impronta di memoria di uno specifico kernel sale costantemente da una base bassa fino a diversi gigabyte nel giro di poche ore, sei di fronte a un leak di memoria progressivo. Isolare questi kernel che perdono memoria nel Server Manager durante i test di accettazione utente impedisce al codice instabile di raggiungere l'ambiente di produzione.
Gestire i puntatori ed evitare leak di memoria nelle BSFN C è fondamentale per mantenere la stabilità del kernel JDE, specialmente nel passaggio alla Tools Release 9.2.8. Se stai gestendo un codebase custom legacy, stabilire rigorosi standard di gestione della memoria è il modo più efficace per prevenire downtime non pianificati del server enterprise.
