

Un processo UBEUnità di Elaborazione Batch. Un programma eseguito in background in JD Edwards per elaborare grandi volumi di dati o eseguire compiti complessi senza interazione diretta dell'utente. ad alto volume che elabora 50.000 righe di vendita spesso spreca il 15% o il 20% della sua finestra di esecuzione in ricerche ridondanti di F0101La tabella principale dell'Address Book in JD Edwards, che memorizza informazioni su clienti, fornitori e altri contatti aziendali.. Anche con l'indicizzazione del databaseUna tecnica per migliorare la velocità di recupero dei dati da una tabella del database, creando una struttura che consente ricerche più rapide. ottimizzata, l'accesso allo stesso record dell'Address Book 5.000 volte in un'unica esecuzione del batch crea un sovraccarico di SQLStructured Query Language. Un linguaggio standard utilizzato per gestire e interrogare i database relazionali. e una latenza del middlewareSoftware che collega componenti software o applicazioni, consentendo loro di comunicare e scambiare dati. In JDE, gestisce la comunicazione tra client, server applicativi e database.. Questo esempio di cache BSFNUna tecnica per memorizzare temporaneamente i risultati delle funzioni aziendali (BSFN) in memoria, riducendo la necessità di accedere ripetutamente al database. di JD EdwardsUn sistema ERP (Enterprise Resource Planning) sviluppato da Oracle, utilizzato per gestire le operazioni aziendali quotidiane come contabilità, produzione e gestione della catena di approvvigionamento. riduce le letture ripetute di F0101 spostando la logica di ricerca in un segmento di memoria locale, bypassando il livello del database per ogni richiesta dopo la prima fetchL'operazione di recuperare dati da una fonte, tipicamente un database, in memoria per l'elaborazione..
L'implementazione di questo pattern richiede una struttura JDECACHEUn'API di JD Edwards che consente agli sviluppatori di implementare cache in memoria per migliorare le prestazioni delle applicazioni, riducendo gli accessi ripetuti al database. basata su puntatori all'interno di una funzione aziendale CUn componente software riutilizzabile in JD Edwards, scritto in linguaggio C, che incapsula la logica aziendale e può essere chiamato da diverse applicazioni o report.. Invece di affidarsi al middleware standard per gestire il bufferUn'area di memoria temporanea utilizzata per archiviare dati mentre vengono spostati da un luogo all'altro, o per compensare le differenze di velocità tra i dispositivi., controlliamo manualmente le operazioni jdeCacheInitUna funzione API di JDECACHE utilizzata per inizializzare una nuova istanza della cache in memoria, preparandola per l'uso. e jdeCacheFetchUna funzione API di JDECACHE utilizzata per recuperare un record dalla cache in memoria, se presente. per memorizzare attributi F0101 come il tipo di ricerca (AT1Un campo in JD Edwards, tipicamente nella tabella F0101, che indica il tipo di ricerca o categoria per un record dell'Address Book.) o il nome alfa (ALPHUn campo in JD Edwards, tipicamente nella tabella F0101, che memorizza il nome alfa o descrittivo di un'entità dell'Address Book.) direttamente in memoria. Questo approccio elimina i rischi di cache "zombie"Una cache che non è stata correttamente terminata o rilasciata, occupando memoria inutilmente e potenzialmente causando problemi di prestazioni o stabilità del sistema. spesso trovati in codici personalizzati scritti male, assicurando che la chiamata jdeCacheTerminateUna funzione API di JDECACHE utilizzata per rilasciare la memoria allocata da un'istanza della cache, pulendo le risorse. sia legata all'evento di fine del processo UBE o dell'applicazione. In un ambiente tipico 9.2, questa configurazione può ridurre l'I/O fisicoOperazioni di Input/Output che coinvolgono l'accesso diretto a dispositivi di archiviazione fisici, come dischi rigidi, che sono più lenti rispetto all'accesso alla memoria RAM. per le tabelle dei dati masterDati fondamentali e di riferimento utilizzati in tutta l'organizzazione, come informazioni su clienti, prodotti o fornitori, che cambiano raramente. di una percentuale significativa, nella nostra esperienza spesso superiore al 90%, riducendo notevolmente la contesa del databaseSituazione in cui più processi o utenti tentano di accedere o modificare gli stessi dati del database contemporaneamente, causando rallentamenti o blocchi. durante le finestre di elaborazione di picco.
Il costo delle prestazioni delle ricerche ripetute di F0101
Un UBEUnità di Elaborazione Batch. Un programma eseguito in background in JD Edwards per elaborare grandi volumi di dati o eseguire compiti complessi senza interazione diretta dell'utente. che elabora 50.000 righe di ordine di vendita spesso chiama una BSFNBusiness Function. Un componente software riutilizzabile in JD Edwards che incapsula la logica aziendale, spesso scritto in C o NER (Named Event Rule). per recuperare il nome alfa per lo stesso indirizzo di spedizione migliaia di volte. Se il tuo ciclo raggiunge 10.000 iterazioni e attiva una istruzione SELECTUn'istruzione SQL utilizzata per recuperare dati da una o più tabelle in un database. su F0101La tabella principale dell'Address Book in JD Edwards, che memorizza informazioni su clienti, fornitori e altri contatti aziendali. per ogni record, stai effettivamente attaccando il tuo stesso database. Anche con una chiave primariaUna colonna o un insieme di colonne in una tabella di database che identifica in modo univoco ogni riga, garantendo l'integrità dei dati. ben indicizzata su ABAN8Il campo del numero di indirizzo (Address Book Number) nella tabella F0101 di JD Edwards, spesso utilizzato come chiave primaria., la latenza di andata e ritorno tra il server EnterpriseIl server applicativo in un ambiente JD Edwards che esegue la logica aziendale, le funzioni batch (UBE) e gestisce le comunicazioni con il database. e il server del databaseUn computer dedicato che ospita il database e gestisce le richieste di accesso ai dati da parte di altre applicazioni o server. non è nulla. In un'architettura standard, il sovraccarico del middlewareSoftware che collega componenti software o applicazioni, consentendo loro di comunicare e scambiare dati. In JDE, gestisce la comunicazione tra client, server applicativi e database. del database per una singola fetchL'operazione di recuperare dati da una fonte, tipicamente un database, in memoria per l'elaborazione. della chiave primaria consuma tipicamente da 1 a 3 millisecondi. Mentre 3ms sembra banale, moltiplicarlo per 10.000 iterazioni aggiunge un sovraccarico significativo, spesso più di mezzo minuto o più di tempo di attesa di I/OInput/Output. Si riferisce alle operazioni di lettura e scrittura di dati tra un sistema informatico e un dispositivo di archiviazione o un altro sistema. puro per una singola esecuzione UBE.
Gli sviluppatori si affidano frequentemente a funzioni di servizio standard come GetAddressBookDescription (B0100066) perché sono affidabili e gestiscono il necessario controllo degli errori. Tuttavia, queste funzioni sono senza statoSi riferisce a un sistema o componente che non conserva alcuna informazione sulle interazioni precedenti. Ogni richiesta è trattata come nuova e indipendente.; non memorizzano nativamente i risultati tra più chiamate all'interno dello stesso threadUna singola sequenza di esecuzione all'interno di un processo. Più thread possono esistere all'interno dello stesso processo ed eseguire compiti in parallelo.. Ogni volta che B0100066 viene invocata, apre un cursoreUn costrutto del database che consente di attraversare le righe di un set di risultati una alla volta, tipicamente utilizzato per elaborare i dati riga per riga., esegue l'SQLStructured Query Language. Un linguaggio standard utilizzato per gestire e interrogare i database relazionali. e recupera la riga. Quando ciò accade all'interno di un ciclo ad alto volume in un R42520Un report standard di JD Edwards, specificamente il programma di stampa delle bolle di accompagnamento per gli ordini di vendita. Stampa bolle di accompagnamento o in un report di integrità finanziaria personalizzato R55Una convenzione di denominazione per report personalizzati in JD Edwards, dove "R" indica un report e "55" è un prefisso comune per gli oggetti personalizzati., il sovraccarico cumulativo diventa il principale collo di bottiglia per la finestra del batchIl periodo di tempo designato, spesso durante le ore non di punta, in cui vengono eseguiti i processi batch ad alto volume per minimizzare l'impatto sugli utenti interattivi..
La scalabilità della logica JDEAbbreviazione comune per JD Edwards, il sistema ERP di Oracle. per le imprese globali richiede di allontanarsi dalla mentalità di recupero su richiesta per i dati masterDati fondamentali e di riferimento utilizzati in tutta l'organizzazione, come informazioni su clienti, prodotti o fornitori, che cambiano raramente. che raramente cambiano durante una singola sessione. La riduzione del numero di esecuzioni di SQLStructured Query Language. Un linguaggio standard utilizzato per gestire e interrogare i database relazionali. grezzo è il lever più efficace che uno sviluppatore ha per migliorare le prestazioni senza richiedere costosi aggiornamenti hardware o ridimensionamenti di istanze OCIOracle Cloud Infrastructure. Si riferisce a server virtuali o servizi di database ospitati sulla piattaforma cloud di Oracle.. Implementando un puntatore JDECACHEUn'API di JD Edwards che consente agli sviluppatori di implementare cache in memoria per migliorare le prestazioni delle applicazioni, riducendo gli accessi ripetuti al database. per memorizzare i risultati della prima ricerca F0101La tabella principale dell'Address Book in JD Edwards, che memorizza informazioni su clienti, fornitori e altri contatti aziendali., le richieste successive per lo stesso AN8Il campo del numero di indirizzo (Address Book Number) nella tabella F0101 di JD Edwards, utilizzato per identificare univocamente un'entità. possono essere risolte in microsecondi tramite memoria anziché millisecondi tramite la rete. Questo spostamento trasforma la degradazione delle prestazioni lineari in un tempo di esecuzione quasi costante per la risoluzione dei dati master.
Progettazione della struttura dei dati della cache e della chiave
Un'implementazione JDECACHEUn'API di JD Edwards che consente agli sviluppatori di implementare cache in memoria per migliorare le prestazioni delle applicazioni, riducendo gli accessi ripetuti al database. vive o muore per la typedef structUna dichiarazione in linguaggio C che crea un nuovo tipo di dati composto, consentendo di raggruppare variabili di diversi tipi sotto un unico nome. definita nel file di intestazione BSFNUn file .h associato a una Business Function (BSFN) in JD Edwards, che contiene le definizioni delle strutture dati e le firme delle funzioni.. Ho visto sviluppatori tentare di riutilizzare strutture di dati esistenti (DSTRData Structure. Una struttura di dati predefinita in JD Edwards, utilizzata per passare parametri tra funzioni o per definire record.) per l'archiviazione della cache per risparmiare tempo, ma questo è un errore che spesso porta a problemi di allineamento della memoriaIl processo di organizzare i dati in memoria in modo che siano posizionati a indirizzi che sono multipli di una certa dimensione, migliorando l'efficienza di accesso della CPU. o a un sovraccarico di memoria non necessario. Devi definire una struttura dedicata che contenga solo i campi che intendi memorizzare. Per una ricerca F0101La tabella principale dell'Address Book in JD Edwards, che memorizza informazioni su clienti, fornitori e altri contatti aziendali. ad alta frequenza, la tua struttura dovrebbe iniziare con il mnAddressNumberIl nome di una variabile in JD Edwards, tipicamente di tipo MATH_NUMERIC, che rappresenta il numero di indirizzo. (MATH_NUMERICUn tipo di dati numerico specifico di JD Edwards, utilizzato per valori che richiedono precisione matematica, come quantità o importi monetari.) come indice primario, seguito da punti di dati specifici come szNameAlphaIl nome di una variabile in JD Edwards, tipicamente di tipo ALPH, che rappresenta il nome alfa o descrittivo. (ALPHUn campo in JD Edwards, tipicamente nella tabella F0101, che memorizza il nome alfa o descrittivo di un'entità dell'Address Book.) e forse szTaxIdIl nome di una variabile in JD Edwards, tipicamente di tipo TAX1, che rappresenta l'identificativo fiscale. (TAX1Un campo in JD Edwards, tipicamente nella tabella F0101, che memorizza l'identificativo fiscale di un'entità.). Definire questo nel file .hUn file di intestazione in linguaggio C, che contiene dichiarazioni di funzioni, definizioni di macro e strutture dati, per essere incluso in altri file sorgente. assicura che ogni funzione all'interno della sorgente - sia che si tratti dell'inizializzazione, della fetchL'operazione di recuperare dati da una fonte, tipicamente un database, in memoria per l'elaborazione. o della terminazione - faccia riferimento allo stesso identico footprint di memoriaLa quantità di memoria RAM utilizzata da un programma, un processo o una struttura dati durante la sua esecuzione. in tutta la durata.
L'unicità della chiave della cache è non negoziabile se si desidera evitare il sovraccarico di JDECACHE_FetchRecordsUna funzione API di JDECACHE che recupera record dalla cache, potenzialmente con filtri, ma meno efficiente di una ricerca diretta per chiave. con filtri complessi. Definendo un indice a chiave singola su mnAddressNumberIl nome di una variabile in JD Edwards, tipicamente di tipo MATH_NUMERIC, che rappresenta il numero di indirizzo., il gestore della cache JDEAbbreviazione comune per JD Edwards, il sistema ERP di Oracle. esegue una ricerca binariaUn algoritmo di ricerca efficiente che trova la posizione di un elemento in un elenco ordinato dividendo ripetutamente a metà la parte dell'elenco che potrebbe contenere l'elemento. attraverso i segmenti di memoria, che è significativamente più veloce di una ricerca di indice SQLStructured Query Language. Un linguaggio standard utilizzato per gestire e interrogare i database relazionali. su una grande tabella F0101La tabella principale dell'Address Book in JD Edwards, che memorizza informazioni su clienti, fornitori e altri contatti aziendali. che contiene 500.000+ record. In un ambiente di distribuzione tipico in cui un singolo UBEUnità di Elaborazione Batch. Un programma eseguito in background in JD Edwards per elaborare grandi volumi di dati o eseguire compiti complessi senza interazione diretta dell'utente. potrebbe elaborare 10.000 righe di vendita, colpire la cache per i nomi Sold-ToIl cliente a cui viene venduta la merce o il servizio in un ordine di vendita. e Ship-ToL'indirizzo o l'entità a cui la merce deve essere spedita in un ordine di vendita. riduce le chiamate totali al database di 20.000 chiamate. Ciò non è solo un guadagno marginale; è la differenza tra un'esecuzione del batch di 15 minuti e una che termina in meno di 5 minuti.
L'efficienza deriva dal riempire la struttura con ogni pezzo di dati che l'applicazione chiamante potrebbe aver bisogno in seguito nel flusso di esecuzione. Se la tua logica richiede eventualmente il tipo di ricerca (ATYUn campo in JD Edwards, tipicamente nella tabella F0101, che indica il tipo di ricerca o categoria per un record dell'Address Book. Simile ad AT1.) o l'unità aziendale (MCUBusiness Unit. Un campo in JD Edwards che rappresenta un'unità organizzativa o un centro di costo, utilizzato per la contabilità e la rendicontazione.) dall'Address Book, aggiungili alla struttura ora. Una struttura di 200 byte memorizzata per 5.000 clienti attivi consuma un'impronta di memoria trascurabile, tipicamente inferiore a pochi megabyte di memoria del workstation o del server aziendaleIl server applicativo in un ambiente JD Edwards che esegue la logica aziendale, le funzioni batch (UBE) e gestisce le comunicazioni con il database.. Rispetto alla latenza delle chiamate JDB_FetchKeyedUna funzione API di JD Edwards utilizzata per recuperare un record da una tabella del database utilizzando una chiave specifica. ripetute su una rete congestionata a un database ospitato OCIOracle Cloud Infrastructure. Si riferisce a server virtuali o servizi di database ospitati sulla piattaforma cloud di Oracle., lo scambio di memoria è trascurabile. Assicurati che il tuo array JDECACHE_KEYSEGUna struttura o un array utilizzato in JDECACHE per definire i segmenti della chiave di ricerca all'interno della struttura della cache. si mappi correttamente all'offsetLa distanza o la posizione di un elemento dati rispetto all'inizio di una struttura di memoria o di un blocco di dati. di mnAddressNumberIl nome di una variabile in JD Edwards, tipicamente di tipo MATH_NUMERIC, che rappresenta il numero di indirizzo. all'interno della struttura per evitare che il middlewareSoftware che collega componenti software o applicazioni, consentendo loro di comunicare e scambiare dati. In JDE, gestisce la comunicazione tra client, server applicativi e database. recuperi il blocco di memoria sbagliato durante un'operazione di fetchL'operazione di recuperare dati da una fonte, tipicamente un database, in memoria per l'elaborazione..
Inizializzazione di JDECACHE all'interno della BSFN
Ogni sviluppatore BSFNBusiness Function. Un componente software riutilizzabile in JD Edwards che incapsula la logica aziendale, spesso scritto in C o NER (Named Event Rule). ha eventualmente visto un crash del kernel dell'oggetto di chiamataIl componente del server Enterprise di JD Edwards responsabile dell'esecuzione delle Business Functions (BSFN) e della gestione delle risorse di memoria e dei thread. a causa di due funzioni personalizzate diverse che hanno tentato di inizializzare una cache con lo stesso nome. Devi passare una stringa univoca e descrittiva all'APIApplication Programming Interface. Un insieme di definizioni e protocolli che consentono a diverse applicazioni software di comunicare tra loro. jdeCacheInitUna funzione API di JDECACHE utilizzata per inizializzare una nuova istanza della cache in memoria, preparandola per l'uso., come ad esempio "C550101_AddressBookCache". Utilizzare un nome generico come "AB_Cache" rischia una collisioneSi verifica quando due o più elementi tentano di utilizzare la stessa risorsa o lo stesso identificatore contemporaneamente, portando a errori o comportamenti inattesi. con BSFN Oracle standard in esecuzione nello stesso threadUna singola sequenza di esecuzione all'interno di un processo. Più thread possono esistere all'interno dello stesso processo ed eseguire compiti in parallelo.. In ambienti che elaborano 50.000 righe di ordine di vendita, una collisione di nomi può corrompere lo spazio di memoria del kernel, portando a processi zombieUn processo che ha completato la sua esecuzione ma la cui voce nella tabella dei processi rimane perché il suo processo padre non ha ancora letto il suo stato di uscita. sul server EnterpriseIl server applicativo in un ambiente JD Edwards che esegue la logica aziendale, le funzioni batch (UBE) e gestisce le comunicazioni con il database..
I kernel dell'oggetto di chiamata multithreadingLa capacità di un sistema operativo o di un'applicazione di eseguire più thread contemporaneamente, consentendo l'esecuzione parallela di diverse parti di un programma. riutilizzano la memoria, rendendo l'isolamento della sessioneLa garanzia che i dati e le risorse di una sessione utente siano separati e non influenzino o siano influenzati da altre sessioni. una preoccupazione principale. Previene la contaminazione dei dati tra sessioni aggiungendo il numero di lavoro (JOBSIl numero di lavoro o ID del processo in JD Edwards, un identificatore univoco per ogni esecuzione di un UBE o di un'applicazione.) alla stringa del nome della cache. Senza questo identificatore univoco, l'utente A potrebbe recuperare i dati dell'Address Book memorizzati nella cache dall'utente B. In un ambiente 9.2, non includere il numero di lavoro provoca errori di integrità dei datiLa precisione, la coerenza e l'affidabilità dei dati durante il loro ciclo di vita, garantendo che i dati siano validi e non corrotti. intermittenti che sono quasi impossibili da replicare in un ambiente di sviluppo locale a utente singolo.
Impostare l'indice della cache durante l'inizializzazione determina se le ricerche successive operano a complessità O(1)Complessità temporale costante. Significa che il tempo di esecuzione di un algoritmo rimane lo stesso indipendentemente dalla dimensione dell'input. o O(n)Complessità temporale lineare. Significa che il tempo di esecuzione di un algoritmo cresce linearmente con la dimensione dell'input.. Definisci l'indice utilizzando jdeCacheAddIndexUna funzione API di JDECACHE utilizzata per definire un indice sulla cache, migliorando la velocità delle ricerche per chiave. immediatamente dopo l'inizializzazione, mappandolo sul campo F0101La tabella principale dell'Address Book in JD Edwards, che memorizza informazioni su clienti, fornitori e altri contatti aziendali..AN8Il campo del numero di indirizzo (Address Book Number) nella tabella F0101 di JD Edwards, utilizzato per identificare univocamente un'entità.. Per una cache che contiene 2.000 record, una scansione non indicizzata richiede molti più cicli CPULe unità di tempo più piccole misurate da un processore, che rappresentano il numero di operazioni elementari che la CPU può eseguire. di una ricerca chiaviata. Questa differenza di prestazioni è critica quando la BSFNBusiness Function. Un componente software riutilizzabile in JD Edwards che incapsula la logica aziendale, spesso scritto in C o NER (Named Event Rule). viene chiamata all'interno di un ciclo in un UBEUnità di Elaborazione Batch. Un programma eseguito in background in JD Edwards per elaborare grandi volumi di dati o eseguire compiti complessi senza interazione diretta dell'utente. pesante come R42520Un report standard di JD Edwards, specificamente il programma di stampa delle bolle di accompagnamento per gli ordini di vendita..
La logica deve verificare se il handle della cacheUn identificatore o un puntatore che rappresenta un'istanza specifica della cache in memoria, consentendo al programma di interagire con essa. è valido per minimizzare il sovraccarico. Verificare la variabile hCacheIl nome comune per la variabile che memorizza l'handle della cache in JD Edwards, utilizzato per riferirsi a un'istanza specifica della cache. contro NULLUn valore speciale che indica l'assenza di un valore o un puntatore che non punta a nessuna posizione di memoria valida. assicura che se una BSFNBusiness Function. Un componente software riutilizzabile in JD Edwards che incapsula la logica aziendale, spesso scritto in C o NER (Named Event Rule). viene chiamata 10.000 volte all'interno di un threadUna singola sequenza di esecuzione all'interno di un processo. Più thread possono esistere all'interno dello stesso processo ed eseguire compiti in parallelo., l'inizializzazione si verifichi solo una volta. Questo approccio riduce il tempo di esecuzione di una percentuale significativa, spesso tra il 10% e il 20%, rispetto alle funzioni che riaprono i handle su ogni chiamata.
Implementazione della logica di fetch o inserimento
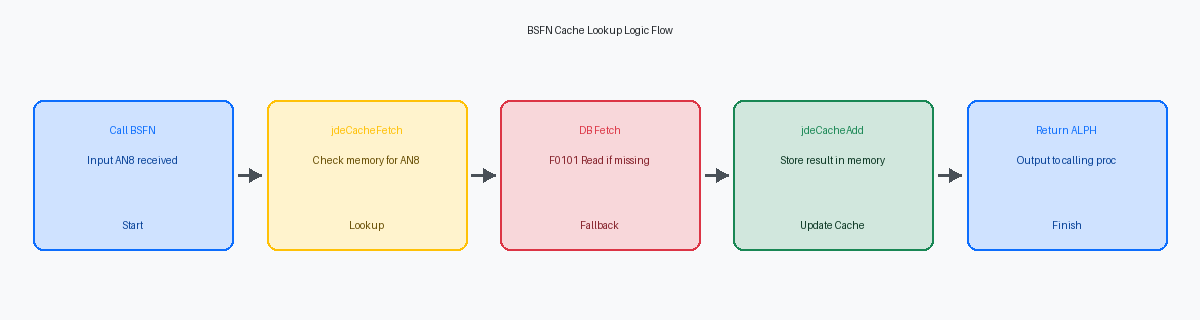
La logica BSFNBusiness Function. Un componente software riutilizzabile in JD Edwards che incapsula la logica aziendale, spesso scritto in C o NER (Named Event Rule). inizia con una chiamata immediata a jdeCacheFetchUna funzione API di JDECACHE utilizzata per recuperare un record dalla cache in memoria, se presente. utilizzando l'AN8Il campo del numero di indirizzo (Address Book Number) nella tabella F0101 di JD Edwards, utilizzato per identificare univocamente un'entità. passato come chiave primariaUna colonna o un insieme di colonne in una tabella di database che identifica in modo univoco ogni riga, garantendo l'integrità dei dati.. Questo controllo si verifica prima di qualsiasi attività del database, assicurando che il sistema consumi solo cicli CPULe unità di tempo più piccole misurate da un processore, che rappresentano il numero di operazioni elementari che la CPU può eseguire. se i dati sono mancanti nella memoria della sessione dell'utente. In un UBEUnità di Elaborazione Batch. Un programma eseguito in background in JD Edwards per elaborare grandi volumi di dati o eseguire compiti complessi senza interazione diretta dell'utente. ad alto volume che elabora 50.000 righe di ordine di vendita, questa singola riga di codice CIl codice sorgente scritto nel linguaggio di programmazione C, spesso utilizzato in JD Edwards per le Business Functions (BSFN) ad alte prestazioni. può eliminare decine di migliaia di istruzioni SQLStructured Query Language. Un linguaggio standard utilizzato per gestire e interrogare i database relazionali. ridondanti se la distribuzione dell'address book è concentrata. La firma della funzioneLa dichiarazione di una funzione che include il suo nome, il tipo di ritorno e i tipi e l'ordine dei suoi parametri. richiede il handle della cacheUn identificatore o un puntatore che rappresenta un'istanza specifica della cache in memoria, consentendo al programma di interagire con essa. stabilito durante l'inizializzazione e un puntatore alla struttura della chiave che contiene il valore AN8.
Quando l'operazione di fetchL'operazione di recuperare dati da una fonte, tipicamente un database, in memoria per l'elaborazione. restituisce JDECACHE_NOT_FOUNDUn codice di ritorno dall'API JDECACHE che indica che il record cercato non è stato trovato nella cache., la BSFNBusiness Function. Un componente software riutilizzabile in JD Edwards che incapsula la logica aziendale, spesso scritto in C o NER (Named Event Rule). passa al database fisico. Questo è il punto in cui esegui una normale JDB_FetchKeyedUna funzione API di JD Edwards utilizzata per recuperare un record da una tabella del database utilizzando una chiave specifica. sulla tabella F0101La tabella principale dell'Address Book in JD Edwards, che memorizza informazioni su clienti, fornitori e altri contatti aziendali. per recuperare il nome alfa o il tipo di ricerca richiesto per la logica aziendale. Se il database restituisce un record, la BSFN popola la struttura dei dati locale e chiama immediatamente jdeCacheAddUna funzione API di JDECACHE utilizzata per aggiungere un nuovo record alla cache in memoria.. Inserendo il record nella cache in questo punto, si trasforma un'operazione I/OInput/Output. Si riferisce alle operazioni di lettura e scrittura di dati tra un sistema informatico e un dispositivo di archiviazione o un altro sistema. costosa in una scrittura in memoria sub-millisecondi. Ciò assicura che la prossima chiamata per lo stesso AN8Il campo del numero di indirizzo (Address Book Number) nella tabella F0101 di JD Edwards, utilizzato per identificare univocamente un'entità. - sia in un ciclo UBEUnità di Elaborazione Batch. Un programma eseguito in background in JD Edwards per elaborare grandi volumi di dati o eseguire compiti complessi senza interazione diretta dell'utente. o in una griglia dell'applicazioneUn componente dell'interfaccia utente in JD Edwards che visualizza i dati in formato tabellare, consentendo agli utenti di visualizzare e interagire con più record. - bypassi completamente il database.
Questo pattern di fetchL'operazione di recuperare dati da una fonte, tipicamente un database, in memoria per l'elaborazione. o inserimento crea un buffer auto-popolanteUn'area di memoria temporanea che si riempie automaticamente con i dati man mano che vengono richiesti, riducendo la necessità di accessi futuri alla fonte originale. che si scala con la complessità del processo batch. Per un cliente di distribuzione tipico che esegue JDEAbbreviazione comune per JD Edwards, il sistema ERP di Oracle. 9.2, spesso troviamo BSFNBusiness Function. Un componente software riutilizzabile in JD Edwards che incapsula la logica aziendale, spesso scritto in C o NER (Named Event Rule). personalizzate che interrogano F0101La tabella principale dell'Address Book in JD Edwards, che memorizza informazioni su clienti, fornitori e altri contatti aziendali. per ogni riga di dettaglio, anche quando un singolo cliente rappresenta una parte significativa del volume delle transazioni, spesso superiore ai tre quarti. Utilizzando questa logica, il database viene interrogato esattamente una volta per ogni AN8Il campo del numero di indirizzo (Address Book Number) nella tabella F0101 di JD Edwards, utilizzato per identificare univocamente un'entità. univoco per sessione. Incapsulare ciò all'interno di una specifica BSFNBusiness Function. Un componente software riutilizzabile in JD Edwards che incapsula la logica aziendale, spesso scritto in C o NER (Named Event Rule). CIl linguaggio di programmazione C, spesso utilizzato in JD Edwards per le Business Functions (BSFN) ad alte prestazioni. mantiene una netta separazione delle preoccupazioniUn principio di progettazione software che suggerisce di dividere un programma in sezioni distinte, ognuna delle quali affronta una preoccupazione specifica., mantenendo l'applicazione chiamante all'oscuro del meccanismo di caching sottostante.
Se JDB_FetchKeyedUna funzione API di JD Edwards utilizzata per recuperare un record da una tabella del database utilizzando una chiave specifica. non trova l'AN8Il campo del numero di indirizzo (Address Book Number) nella tabella F0101 di JD Edwards, utilizzato per identificare univocamente un'entità., la BSFNBusiness Function. Un componente software riutilizzabile in JD Edwards che incapsula la logica aziendale, spesso scritto in C o NER (Named Event Rule). deve restituire un errore senza tentare di eseguire jdeCacheAddUna funzione API di JDECACHE utilizzata per aggiungere un nuovo record alla cache in memoria.. Tentare di aggiungere un record nullUn record che non contiene dati validi o che è stato inizializzato con valori nulli, indicando l'assenza di informazioni. alla cache può portare a corruzione della memoriaUn errore in cui il contenuto di una posizione di memoria viene modificato in modo non intenzionale, portando a comportamenti imprevedibili o crash del programma. o risultati inaspettati in tentativi successivi. Il sovraccarico di jdeCacheFetchUna funzione API di JDECACHE utilizzata per recuperare un record dalla cache in memoria, se presente. è trascurabile rispetto a una lettura del disco fisicoL'operazione di recuperare dati direttamente da un dispositivo di archiviazione fisico, come un disco rigido, che è relativamente lenta., rendendo questo pattern uno standard di prestazioni per la personalizzazione di livello aziendale. Si consiglia di raccomandare questo approccio per qualsiasi ricerca di dati masterDati fondamentali e di riferimento utilizzati in tutta l'organizzazione, come informazioni su clienti, prodotti o fornitori, che cambiano raramente. che si verifichi più di 1.000 volte in un singolo threadUna singola sequenza di esecuzione all'interno di un processo. Più thread possono esistere all'interno dello stesso processo ed eseguire compiti in parallelo. di esecuzione.
Gestione dell'ambito della cache e terminazione
Un singolo UBEUnità di Elaborazione Batch. Un programma eseguito in background in JD Edwards per elaborare grandi volumi di dati o eseguire compiti complessi senza interazione diretta dell'utente. che elabora 50.000 record che non termina un'istanza di cache può consumare diverse centinaia di megabyte di RAMRandom Access Memory. Un tipo di memoria volatile utilizzata dai computer per archiviare temporaneamente i dati e il codice dei programmi in esecuzione. all'interno del kernel dell'oggetto di chiamataIl componente del server Enterprise di JD Edwards responsabile dell'esecuzione delle Business Functions (BSFN) e della gestione delle risorse di memoria e dei thread. (COKCall Object Kernel. Il componente del server Enterprise di JD Edwards responsabile dell'esecuzione delle Business Functions (BSFN) e della gestione delle risorse.). Quando più utenti attivano perdite di memoriaUn tipo di bug in cui un programma non rilascia la memoria che non è più necessaria, portando a un consumo crescente di RAM e potenziali crash. simili, il COK alla fine raggiunge il suo limite di memoria - spesso 2GB su kernel a 32 bitUn sistema operativo o un componente software progettato per funzionare con architetture a 32 bit, che tipicamente hanno un limite di memoria indirizzabile di 4 GB. - e si blocca, costringendo un kernel zombieUn processo che ha completato la sua esecuzione ma la cui voce nella tabella dei processi rimane perché il suo processo padre non ha ancora letto il suo stato di uscita. e facendo cadere le sessioni attive. Devi verificare che jdeCacheTerminateUna funzione API di JDECACHE utilizzata per rilasciare la memoria allocata da un'istanza della cache, pulendo le risorse. venga chiamato esplicitamente per ogni handle della cacheUn identificatore o un puntatore che rappresenta un'istanza specifica della cache in memoria, consentendo al programma di interagire con essa. inizializzato; semplicemente lasciare che la BSFNBusiness Function. Un componente software riutilizzabile in JD Edwards che incapsula la logica aziendale, spesso scritto in C o NER (Named Event Rule). finisca l'esecuzione non rilascia la memoria allocata nel livello del middlewareSoftware che collega componenti software o applicazioni, consentendo loro di comunicare e scambiare dati. In JDE, gestisce la comunicazione tra client, server applicativi e database. JDEAbbreviazione comune per JD Edwards, il sistema ERP di Oracle..
In un processo UBEUnità di Elaborazione Batch. Un programma eseguito in background in JD Edwards per elaborare grandi volumi di dati o eseguire compiti complessi senza interazione diretta dell'utente. batch standard, come un aggiornamento F4211La tabella dei dettagli degli ordini di vendita in JD Edwards, che memorizza le singole righe degli ordini. ad alto volume, la cache dovrebbe persistere attraverso gli eventi Do Section per massimizzare il tasso di hitLa percentuale di volte in cui un elemento richiesto viene trovato nella cache, indicando l'efficacia della cache nel ridurre gli accessi alla fonte originale. per le ricerche F0101La tabella principale dell'Address Book in JD Edwards, che memorizza informazioni su clienti, fornitori e altri contatti aziendali.. Il pattern ottimale coinvolge la chiamata a una BSFN di puliziaUna Business Function (BSFN) progettata specificamente per rilasciare risorse, come la memoria della cache, alla fine di un processo o di una sessione. durante l'evento End ReportUn punto specifico nell'esecuzione di un report UBE in JD Edwards in cui viene eseguita una logica di chiusura o di pulizia.. Questa BSFN deve fare riferimento al handle della cacheUn identificatore o un puntatore che rappresenta un'istanza specifica della cache in memoria, consentendo al programma di interagire con essa. hCache specifico utilizzato in tutto il lavoro per assicurarsi che la memoria venga pulita prima che il threadUna singola sequenza di esecuzione all'interno di un processo. Più thread possono esistere all'interno dello stesso processo ed eseguire compiti in parallelo. del processo termini. Se si utilizza una cache globaleUna cache accessibile e potenzialmente condivisa da più componenti o thread all'interno di un'applicazione o di un sistema. condivisa tra più BSFNBusiness Function. Un componente software riutilizzabile in JD Edwards che incapsula la logica aziendale, spesso scritto in C o NER (Named Event Rule). in un singolo thread, la logica di terminazione deve essere centralizzata per evitare che una BSFN orfani un handleSi verifica quando un handle a una risorsa non viene più gestito o rilasciato correttamente, portando a perdite di memoria o risorse non disponibili. che un'altra BSFN si aspetta sia attivo.
Le applicazioni interattiveApplicazioni software che consentono agli utenti di interagire direttamente con esse, ricevendo input e fornendo output in tempo reale. richiedono un approccio più sfumato all'ambito. Se una cache supporta un modulo di Power FormUn tipo avanzato di modulo in JD Edwards che consente una maggiore flessibilità e funzionalità, spesso con più sottomoduli e controlli. complesso con più sottomoduliComponenti più piccoli all'interno di un modulo più grande, che raggruppano funzionalità correlate o visualizzano dati specifici., lo sviluppatore deve decidere se la cache vive per la durata del modulo o viene cancellata dopo un evento specifico. Persistere la cache a livello di modulo consente risposte rapide dell'interfaccia utente durante lo scorrimento della grigliaUn componente dell'interfaccia utente in JD Edwards che visualizza i dati in formato tabellare, consentendo agli utenti di visualizzare e interagire con più record., ma richiede una chiamata alla BSFNBusiness Function. Un componente software riutilizzabile in JD Edwards che incapsula la logica aziendale, spesso scritto in C o NER (Named Event Rule). di terminazione nell'evento End FormUn punto specifico nell'esecuzione di un modulo interattivo in JD Edwards in cui viene eseguita una logica di chiusura o di pulizia.. In ambienti con 500+ utenti concurrentiIl numero di utenti che accedono e utilizzano un sistema o un'applicazione contemporaneamente., non gestire questo ambito porta a memoria frammentataUna condizione in cui la memoria disponibile è divisa in molti piccoli blocchi non contigui, rendendo difficile allocare grandi blocchi di memoria. attraverso le risorse del server aziendaleIl server applicativo in un ambiente JD Edwards che esegue la logica aziendale, le funzioni batch (UBE) e gestisce le comunicazioni con il database. COKCall Object Kernel. Il componente del server Enterprise di JD Edwards responsabile dell'esecuzione delle Business Functions (BSFN) e della gestione delle risorse..
Utilizzare il handleUn identificatore o un puntatore che rappresenta un'istanza specifica della cache in memoria, consentendo al programma di interagire con essa. hCache correttamente assicura che si stia terminando l'istanza specifica creata dal proprio processo anziché un puntatore globaleUn puntatore che è accessibile da qualsiasi parte del programma, potenzialmente causando problemi di gestione della memoria se non usato con cautela.. In un ambiente multithreadingLa capacità di un sistema operativo o di un'applicazione di eseguire più thread contemporaneamente, consentendo l'esecuzione parallela di diverse parti di un programma., passare il handle specifico indietro alla funzione di terminazione evita la contaminazione accidentale dei dati. Un errore comune è affidarsi a un nome di cache codificato in modo rigido nella chiamata di terminazione senza verificare che il handle sia valido. La progettazione BSFNBusiness Function. Un componente software riutilizzabile in JD Edwards che incapsula la logica aziendale, spesso scritto in C o NER (Named Event Rule). affidabile include un controllo per un handle nullUn valore speciale che indica l'assenza di un valore o un puntatore che non punta a nessuna posizione di memoria valida. prima di tentare la terminazione, evitando errori di violazione della memoriaUn errore che si verifica quando un programma tenta di accedere a una posizione di memoria a cui non ha il permesso di accedere, spesso causando un crash. mentre si assicura che l'heapUn'area di memoria utilizzata per l'allocazione dinamica, dove i programmi possono richiedere blocchi di memoria di dimensioni variabili durante l'esecuzione. venga restituito al SOSistema Operativo. Il software che gestisce le risorse hardware e software di un computer, fornendo servizi comuni per i programmi..
Risultati di benchmarking e limiti di invalidazione
In un UBEUnità di Elaborazione Batch. Un programma eseguito in background in JD Edwards per elaborare grandi volumi di dati o eseguire compiti complessi senza interazione diretta dell'utente. ad alto volume che elabora 50.000 record, sostituire le chiamate JDB_FetchKeyedUna funzione API di JD Edwards utilizzata per recuperare un record da una tabella del database utilizzando una chiave specifica. dirette a F0101La tabella principale dell'Address Book in JD Edwards, che memorizza informazioni su clienti, fornitori e altri contatti aziendali. con un'implementazione JDECACHEUn'API di JD Edwards che consente agli sviluppatori di implementare cache in memoria per migliorare le prestazioni delle applicazioni, riducendo gli accessi ripetuti al database. produce una riduzione del 70-90% del tempo di esecuzione della BSFNBusiness Function. Un componente software riutilizzabile in JD Edwards che incapsula la logica aziendale, spesso scritto in C o NER (Named Event Rule).. Questo balzo di prestazioni si verifica perché il sovraccarico dell'istruzione SQLStructured Query Language. Un linguaggio standard utilizzato per gestire e interrogare i database relazionali. e dei round-trip di reteIl tempo impiegato per inviare un segnale o un pacchetto di dati da un punto all'altro e ricevere una conferma di ritorno, misurando la latenza della rete. al livello del database viene eliminato dopo il primo incontro di un numero di indirizzo univoco. In uno scenario di logistica client, un UBE di manifesti di spedizione di 45 minuti è stato ridotto a meno di 10 minuti semplicemente memorizzando il nome alfa e il tipo di ricerca. Il guadagno di efficienza è più pronunciato quando il rapporto tra transazioni ed entità univoche è alto, come 1.000 righe di vendita che fanno riferimento a solo 50 indirizzi di spedizione distinti.
L'integrità dei datiLa precisione, la coerenza e l'affidabilità dei dati durante il loro ciclo di vita, garantendo che i dati siano validi e non corrotti. dipende dalla comprensione che JDECACHEUn'API di JD Edwards che consente agli sviluppatori di implementare cache in memoria per migliorare le prestazioni delle applicazioni, riducendo gli accessi ripetuti al database. è uno snapshot in memoriaUna copia dei dati presenti in memoria in un momento specifico, che non si aggiorna automaticamente con i cambiamenti successivi alla fonte originale., non uno specchio in tempo reale del database. Se un processo paralleloUn processo che viene eseguito contemporaneamente a un altro processo, spesso su core CPU diversi, per migliorare le prestazioni. o un threadUna singola sequenza di esecuzione all'interno di un processo. Più thread possono esistere all'interno dello stesso processo ed eseguire compiti in parallelo. diverso aggiorna il record F0101La tabella principale dell'Address Book in JD Edwards, che memorizza informazioni su clienti, fornitori e altri contatti aziendali. durante l'esecuzione della BSFNBusiness Function. Un componente software riutilizzabile in JD Edwards che incapsula la logica aziendale, spesso scritto in C o NER (Named Event Rule)., la cache rimane all'oscuro e continua a servire dati obsoletiDati che non sono più aggiornati o accurati perché la loro fonte originale è stata modificata dopo che sono stati memorizzati nella cache. fino a quando la cache non viene esplicitamente terminata o il processo non termina. Questo rischio rende il pattern non adatto per tabelle transazionaliTabelle del database che memorizzano i dettagli delle transazioni aziendali, come ordini di vendita o registrazioni contabili, che cambiano frequentemente. volatile come F4211La tabella dei dettagli degli ordini di vendita in JD Edwards, che memorizza le singole righe degli ordini. o F0911La tabella del registro generale (General Ledger) in JD Edwards, che memorizza tutte le transazioni contabili. dove lo stato del record cambia frequentemente all'interno dello stesso millisecondo. Per i dati masterDati fondamentali e di riferimento utilizzati in tutta l'organizzazione, come informazioni su clienti, prodotti o fornitori, che cambiano raramente. come l'Address Book, dove i cambiamenti al nome del cliente o all'ID fiscale avvengono tramite applicazioni di manutenzione infrequenti, il rischio di una collisioneSi verifica quando due o più elementi tentano di utilizzare la stessa risorsa o lo stesso identificatore contemporaneamente, portando a errori o comportamenti inattesi. a metà del processo è statisticamente trascurabile rispetto ai massicci vantaggi di throughputLa quantità di lavoro o dati che un sistema può elaborare in un dato periodo di tempo, indicando la sua capacità di elaborazione..
Questa strategia di caching è progettata specificamente per i dati masterDati fondamentali e di riferimento utilizzati in tutta l'organizzazione, come informazioni su clienti, prodotti o fornitori, che cambiano raramente. che rimangono statici per la durata di un singolo lavoro batch o di una sessione interattiva specifica. Per evitare perdite di memoriaUn tipo di bug in cui un programma non rilascia la memoria che non è più necessaria, portando a un consumo crescente di RAM e potenziali crash. o errori "Out of Memory" sul server EnterpriseIl server applicativo in un ambiente JD Edwards che esegue la logica aziendale, le funzioni batch (UBE) e gestisce le comunicazioni con il database., devi verificare che la BSFNBusiness Function. Un componente software riutilizzabile in JD Edwards che incapsula la logica aziendale, spesso scritto in C o NER (Named Event Rule). includa una chiamata di terminazione a jdeCacheTerminateUna funzione API di JDECACHE utilizzata per rilasciare la memoria allocata da un'istanza della cache, pulendo le risorse. nell'evento di fine del processoUn punto specifico nell'esecuzione di un processo o di un report in JD Edwards in cui viene eseguita una logica di chiusura o di pulizia.. Quando si distribuiscono queste cache personalizzate in produzione, utilizzare la sezione Metriche di runtime in Server ManagerUno strumento di amministrazione in JD Edwards utilizzato per gestire e monitorare i server, le applicazioni e i componenti del sistema. per tenere traccia dell'utilizzo degli oggetti JDEComponenti software in JD Edwards, come applicazioni, report, Business Functions o tabelle, che costituiscono il sistema. e del consumo di memoria per processo. Se si osserva che l'impronta di memoria del kernel JDEIl componente del server Enterprise di JD Edwards responsabile dell'esecuzione delle Business Functions (BSFN) e della gestione delle risorse di memoria e dei thread. sale costantemente senza raggiungere un plateauUn punto in cui una quantità o un valore smette di aumentare e si stabilizza, indicando che una risorsa ha raggiunto un limite o un equilibrio., ciò indica generalmente un fallimento nel pulire i segmenti della cache, che può destabilizzare altri processi in esecuzione sullo stesso kernel dell'oggetto di chiamataIl componente del server Enterprise di JD Edwards responsabile dell'esecuzione delle Business Functions (BSFN) e della gestione delle risorse di memoria e dei thread..

