

Nelle nostre revisioni del codice in decine di ambienti JDE 9.2, riscontriamo regolarmente che una parte significativa delle business function C personalizzate (BSFN)BSFN: moduli di codice scritti in C o Event Rules che eseguono logica di business specifica all'interno di JD Edwards. — spesso da un terzo alla metà — duplica inutilmente la logica Oracle standard. Gli sviluppatori spesso clonano interi moduli come B4200310 o B1200010 solo per eseguire una singola validazione, invece di implementare un pulito esempio di chiamata JDE BSFN jdeCallObjectAPI fondamentale di JD Edwards utilizzata per invocare una business function da un programma C o da un'altra funzione. per eseguire una business function riutilizzabile. Questo codice ridondante si rompe durante gli aggiornamenti perché bypassa gli aggiornamenti di continuous deliveryModello di rilascio software che prevede il rilascio frequente e automatizzato di piccoli aggiornamenti e correzioni. di Oracle. L'approccio più corretto è chiamare la business function standard dinamicamente dal proprio codice C personalizzato.
L'implementazione di un pattern di esecuzione dinamica preciso utilizzando jdeCallObject consente di riutilizzare le business function standard preservando integralmente i confini transazionali e lo stack degli errori lpBhvrComStruttura dati che trasporta il contesto di esecuzione, come le informazioni sulla sessione utente e lo stato delle transazioni.. Passando la corretta struttura behavior common e mappando le strutture dati in modo dinamico, si evita di codificare dipendenze dal database che falliscono durante gli ESUElectronic Software Update: pacchetti di patch rilasciati da Oracle per correggere bug o aggiornare il sistema JD Edwards.. Questo approccio garantisce che il patrimonio di personalizzazioni rimanga snello, tollerante agli aggiornamenti e compatibile con la roadmap di supporto Oracle fino al 2034.
Il Costo della Duplicazione della Logica di Business Core di JDE
Eseguo regolarmente audit di ambienti JDE aziendali contenenti da 5.000 a 15.000 oggetti personalizzati e scopro che tra il 10% e il 15% delle business function C personalizzate sono cloni non necessari della logica standard. Gli sviluppatori spesso copiano e incollano una funzione C standard in un oggetto personalizzato '55' perché vogliono bypassare un singolo controllo di validazione o sovrascrivere un parametro hardcoded. Quando si duplica una master business functionFunzioni centralizzate che garantiscono l'integrità dei dati validando e scrivendo record nelle tabelle principali di JD Edwards. complessa come Sales Order Entry Edit Line (B4200310), si ereditano migliaia di righe di logica altamente volatile che il team dovrà ora adattare manualmente durante ogni ciclo di aggiornamento o Electronic Software Update (ESU).
Questa duplicazione interrompe il modello di continuous delivery di Oracle. Invece di clonare oggetti standard, invocare direttamente la business function standard utilizzando l'API nativa jdeCallObject garantisce che eventuali correzioni software critiche applicate da Oracle si propaghino automaticamente alle applicazioni personalizzate. Quando Oracle rilascia una correzione per il calcolo delle imposte o una patch per l'allocazione dell'inventario al codice standard sottostante, il wrapper personalizzato eredita immediatamente tale aggiornamento, eliminando completamente settimane di unione manuale del codice e test durante il prossimo aggiornamento di Tools ReleaseInsieme di componenti tecnologici e runtime che supportano le applicazioni e l'infrastruttura di JD Edwards. 9.2.
Chiamare direttamente le BSFN standard esistenti preserva anche le routine di validazione del database core e garantisce l'integrità transazionale tra le tabelle standard come F4211 e F0911. B4200310, ad esempio, gestisce complesse strutture di memoria interna, calcoli fiscali e regole di pricing avanzate prima di confermare i record. Bypassare queste routine native scrivendo insert SQLLinguaggio standard utilizzato per interrogare, inserire e aggiornare i dati all'interno dei database relazionali. personalizzati o codice C personalizzato ridotto all'osso corrompe inevitabilmente le transazioni a valle, portando a report di integrità del libro giornale errati che i team finanziari devono riconciliare manualmente a fine mese.

Anatomia dell'API jdeCallObject e della Struttura LPBHID
L'invocazione diretta di una business function dall'interno del codice sorgente C richiede di bypassare il motore standard delle Event RulesLinguaggio di programmazione visuale proprietario di JD Edwards usato per definire la logica applicativa. e di interfacciarsi direttamente con il motore runtime core di JDE. L'API jdeCallObject è il gateway per questo, e richiede esattamente quattro parametri primari passati in una sequenza rigida: la stringa del nome della funzione di destinazione (come "F4111EditLine"), il puntatore al contesto di comportamento (lpBhvrCom), il puntatore al profilo utente (lpVoid) e il puntatore alla struttura dati di destinazione allocata in memoria. Gli sviluppatori che passano dalle Event Rules spesso sottovalutano il rigore di questo binding a livello C, dove il passaggio di un puntatore a una struttura nullo o castato in modo improprio scatena un'immediata violazione di memoria e un kernelProcessi lato server che gestiscono le richieste degli utenti, la memoria e l'esecuzione del codice in JD Edwards. zombie sul server enterprise.
Il secondo parametro, lpBhvrCom, funge da sistema nervoso operativo per la chiamata. Questa struttura di comportamento mantiene i dati vitali dello stato ambientale, tracciando gli handle di connessione al database attivi, le variabili di sessione utente e i confini critici dell'elaborazione manuale delle transazioni. Se si sta eseguendo un inserimento multi-tabella tra F0911 e F03B11 all'interno di una transazione attiva, il passaggio di un puntatore lpBhvrCom non inizializzato o corrotto interrompe il confine della transazione, causando il commit del primo inserimento da parte del runtime mentre il secondo fallisce silenziosamente.
Ogni esecuzione di jdeCallObject produce un codice di ritorno JDEDB_RESULTTipo di dato che restituisce l'esito (successo o errore) di una chiamata a una funzione database o API. esplicito che deve essere catturato e valutato. Un valore di ritorno ER_SUCCESS (0) indica un'esecuzione riuscita, mentre ER_ERROR (2) o ER_WARNING (1) segnala che la logica di business non è riuscita a completare la sua routine. Saltare la valutazione immediata di questo codice di ritorno è una svista comune e ad alto rischio nelle BSFN C personalizzate. Il mancato controllo di ER_ERROR prima di procedere consente al codice a valle di essere eseguito ciecamente, scrivendo record incompleti in tabelle come F4211 e corrompendo l'integrità transazionale dell'intero thread del database.
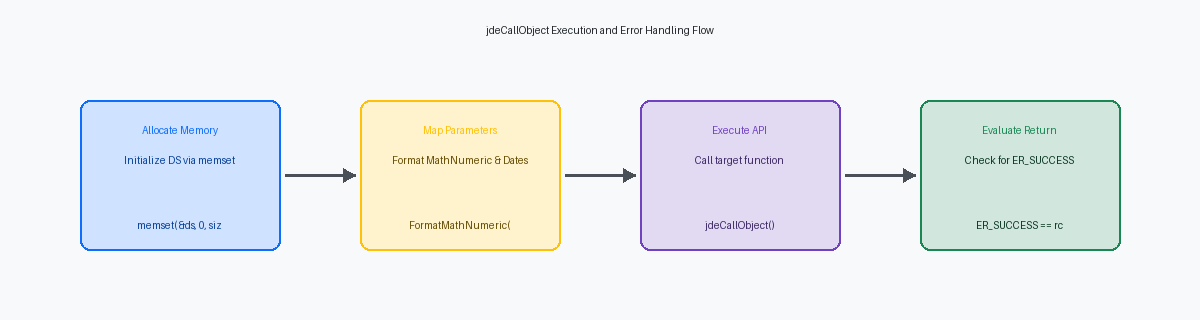
Allocazione della Struttura Dati e Pattern di Mappatura
L'allocazione della memoria per la struttura dati di una business function di destinazione richiede il rigoroso rispetto delle regole di allineamento, specialmente da quando JDE è passato all'elaborazione a 64 bitArchitettura informatica che permette di processare dati e indirizzare memoria in blocchi di 64 bit. con Tools Release 9.2.5. È necessario allocare esplicitamente questa memoria utilizzando variabili stack per scope locali più piccoli, o l'allocazione dinamica heap tramite l'API jdeAllocAPI specifica di JD Edwards utilizzata per allocare dinamicamente memoria nel sistema. quando si gestiscono array di dimensioni variabili o puntatori a lunga durata. Quando si utilizza l'allocazione heap, il disallineamento di una struttura MATH_NUMERICStruttura dati proprietaria di JD Edwards per la gestione precisa di numeri decimali e calcoli matematici. può causare guasti di memoria istantanei sui moderni server enterprise Linux.
Prima di passare questo blocco di memoria a jdeCallObject, è necessario inizializzare la struttura dati di destinazione a byte nulli utilizzando memset per eliminare eventuali valori spazzatura dello stack. Saltare questo passaggio introduce spesso bug intermittenti in cui elementi non inizializzati, come un campo flag contenente residui di memoria casuali, innescano falsi fallimenti di validazione nelle master business function standard come F4211 Edit Line (B4200310). Per prevenire errori di mancata corrispondenza del tipo in fase di compilazione sul compilatore enterprise (sia esso Visual Studio o gcc), la BSFN chiamante personalizzata deve includere esplicitamente l'header fileFile con estensione .h contenente definizioni di funzioni e strutture dati necessarie al compilatore C. esatto della funzione di destinazione, come b0100016.h per la MBF dell'Address Book.
La gestione della mappatura dei dati all'interno di queste strutture rivela i limiti degli operatori C standard, che non possono copiare tipi di dati JDE complessi. Il tentativo di un'assegnazione diretta su una struttura MATH_NUMERIC o JDEDATE corromperà i puntatori interni e i valori di scala, portando a una corruzione silenziosa del database. Invece, è necessario utilizzare API dedicate come FormatMathNumeric per convertire i valori numerici in stringhe, o ParseDate e DeformatDate per manipolare in sicurezza i campi data. Per le copie dirette da struttura a struttura, affidarsi rigorosamente a MathCopy e FormatDate per preservare l'integrità delle posizioni decimali e delle strutture interne prima di eseguire la chiamata.
Implementazione di un Esempio di Chiamata JDE BSFN jdeCallObject
L'hardcoding delle chiamate alle master business function all'interno di business function C personalizzate è il punto in cui molti sviluppatori junior falliscono, con conseguenti perdite di memoria o errori di puntatori non mappati. Un'implementazione standard e pulita che chiama la MBF dell'Address Book (B0100016) richiede la dichiarazione della struttura dati DSD0100016 direttamente nel codice C personalizzato invece di affidarsi a puntatori generici. Questa struttura deve essere allocata sullo stack per garantire la thread-safety quando eseguita sotto l'architettura del kernel JDE CallObject, che gestisce migliaia di thread simultanei in un tipico ambiente HTML di produzione.
Prima di invocare l'API, è necessario inizializzare a zero la struttura utilizzando memset per evitare che la memoria sporca corrompa la cache JDE. Mappare l'input Address Number di destinazione al membro dsD0100016.mnAddressNumber convertendo la stringa di input tramite l'API deformatMathNumeric, che analizza in sicurezza la stringa numerica nel formato proprietario MATH_NUMERIC di JDE. Quindi si imposta esplicitamente il campo del codice azione, dsD0100016.cActionCode, su 'Inquire' per attivare un recupero in sola lettura dalla tabella F0101.
Con la struttura dati popolata, eseguire la chiamata API jdeCallObject passando la struttura LPBHID, il nome della funzione di destinazione 'F0101GetAddressBookData' e un puntatore alla struttura DSD0100016 inizializzata. La valutazione del codice di ritorno non è negoziabile; è necessario verificare se l'API restituisce ER_SUCCESS o ER_ERROR. Saltare questa validazione è il motivo principale per cui si verificano guasti silenziosi, lasciando le applicazioni personalizzate con campi dello schermo vuoti mentre i log del kernel sottostante si riempiono di eccezioni non gestite.
Se l'API restituisce ER_ERROR, non lasciare che il fallimento muoia nel livello C. Estrarre il codice di errore specifico dallo stack degli errori JDE utilizzando l'API jdeErrorSet per far risalire il messaggio fino all'applicazione interattiva o al livello UBEUniversal Batch Engine: il motore di JD Edwards responsabile dell'esecuzione di report e processi massivi in background.. Ciò garantisce che l'utente finale veda l'errore esatto "Address Number Invalid" o "Search Type Mismatch" sul proprio schermo invece di una generica e inutile eccezione del client web.
Gestione dei Confini Transazionali e degli Stack di Errore
Un punto di errore comune nelle interfacce finanziarie personalizzate è la creazione di transazioni GL orfane a causa di connessioni al database isolate. Quando si eseguono aggiornamenti transazionali come Journal Entry Edit Line (B0900011), la BSFN figlia deve unirsi al confine transazionale attivo della funzione padre. Se si esegue B0900011 al di fuori della transazione del padre, un successivo fallimento nelle fasi di elaborazione del voucher o della fattura lascia record F0911 non confermati o saldi non corrispondenti nella tabella F0902. È necessario configurare la relazione padre-figlio in modo che condividano una singola transazione del database, garantendo che o tutto venga confermato o tutto venga annullato.
Il passaggio dell'handle utente attivo (lpBhvrCom->hUser) all'interno dell'invocazione jdeCallObject garantisce che vengano evitati blocchi e deadlock del database. Quando il runtime esegue business function nidificate, l'utilizzo del puntatore hUser del padre consente al driver del database di riconoscere che le operazioni appartengono allo stesso thread di sessione. Se si alloca erroneamente una nuova sessione utente tramite JDB_InitBhvr all'interno della BSFN figlia, il database la tratta come una connessione separata. Questo errore porta al blocco immediato del thread quando la figlia tenta di aggiornare una riga F0911 bloccata dalla transazione non confermata del padre.
Se l'esecuzione di una figlia fallisce, è necessario invocare le routine standard di pulizia della cache JDE o di rollback per evitare record orfani in tabelle come F0911. L'uso dell'elaborazione manuale delle transazioni richiede chiamate esplicite alle API di commit o rollback a seconda dello stato finale del codice di ritorno di jdeCallObject. Quando jdeCallObject restituisce ER_ERROR durante una chiamata a B0900011, è necessario chiamare immediatamente jdeCallObject per B0900012 (Journal Entry Document Clean Up) per svuotare la cache. Il mancato avvio di questa pulizia lascia dati di intestazione e dettaglio obsoleti nelle strutture della cache JDESistema di memorizzazione temporanea in RAM per velocizzare l'accesso ai dati ricorrenti ed evitare accessi al database., che corrompono la transazione successiva elaborata nello stesso thread del kernel call object.
Impatto sulle Prestazioni e Gestione della Cache Locale
L'esecuzione di un ciclo che elabora più di 10.000 record in un UBE personalizzato — come un processore di modifica/aggiornamento degli ordini di vendita EDI in entrata — degraderà gravemente il throughputMisura della quantità di dati o transazioni elaborate da un sistema in un determinato periodo di tempo. del sistema se la funzione di destinazione esegue ricerche ridondanti nel database. Una singola query ripetitiva a F0010 o F0101 all'interno del ciclo aggiunge un'esecuzione SQL cumulativa e una latenza di rete che possono trasformare un'esecuzione di pochi minuti in un collo di bottiglia di diverse ore. Questo sovraccarico è interamente evitabile se si passa da operazioni legate al disco a operazioni legate alla memoria.
Per ottimizzare le prestazioni, gli sviluppatori devono bypassare l'I/O ripetitivo su disco utilizzando le API standard della cache JDE come jdeCacheInit per memorizzare e riutilizzare i dati di configurazione statici tra le chiamate ripetitive alle funzioni figlie. Il caricamento di tabelle costanti o costanti di branch/plant in una cache di memoria utente denominata durante la fase di inizializzazione consente al sistema di risolvere istantaneamente la logica di validazione. Il recupero di un puntatore dalla memoria locale richiede meno di un microsecondo, mentre l'interrogazione del database, anche con hit degli indici, comporta un inevitabile round-trip di rete.
Un'altra area critica di ottimizzazione è la gestione dei cursori e degli handle del database. Mantenere aperti gli handle delle tabelle del database attraverso più iterazioni invece di consentire alla BSFN chiamata di aprire e chiudere gli handle a ogni singola chiamata riduce significativamente il sovraccarico dei cursori del database. Ad esempio, passare un puntatore a una tabella persistente o mantenere l'handle attivo in una struttura dati padre impedisce al sistema di allocare e deallocare costantemente risorse del sistema operativo. Infine, è necessario configurare le BSFN chiamanti e chiamate per l'esecuzione all'interno dello stesso identico thread del server enterprise. Questo specifico allineamento dell'Object Configuration Manager (OCM)OCM: tabella di configurazione che stabilisce se un oggetto deve essere eseguito localmente o su uno specifico server. (OCM) impedisce al kernel JDE di avviare comunicazioni tra processi o ritardi nelle chiamate di procedure remote, mantenendo l'intero stack di esecuzione locale e veloce.
Padroneggiare jdeCallObject è la base per stabilizzare un patrimonio di codice personalizzato 9.2. Se stai ottimizzando la gestione della memoria o eseguendo il debug di pattern di cache complessi, questo sito contiene approfondimenti sull'uso di lpdsCommon e sull'efficienza delle API jdeCache. Puoi anche consultare il mio portfolio di progetti tecnici per vedere come questi pattern BSFN scalano in integrazioni OCIOracle Cloud Infrastructure: la piattaforma di servizi cloud di Oracle per l'hosting di applicazioni e database enterprise. ad alto volume che elaborano decine di migliaia di transazioni giornaliere. Queste risorse tecniche si concentrano sui 200–500 oggetti realmente impattanti che dettano la stabilità e le prestazioni del tuo ambiente di produzione.
