

Le Table I/O standard delle Event Rules (ER)Linguaggio di programmazione visuale di JD Edwards per definire la logica di business senza scrivere codice complesso. sono sufficienti per applicazioni interattive a basso volume, ma falliscono in presenza di carichi di lavoro ad alta concorrenza. Quando si hanno da 50 a 100 thread concorrenti provenienti da chiamate rapide di AIS OrchestratorStrumento di JD Edwards per creare integrazioni e automazioni basate su servizi web. o UBEUniversal Batch Engine: componente che gestisce l'esecuzione di report e processi massivi in background. multi-thread che colpiscono le stesse tabelle custom F55, la mancanza di controllo esplicito sul blocco dei record nelle ER porta a dirty readsSituazione in cui una transazione legge dati modificati da un'altra transazione non ancora confermata, rischiando errori. e violazioni della chiave primariaCampo o insieme di campi che identifica in modo univoco ogni riga di una tabella in un database.. Per prevenire la corruzione dei dati, gli sviluppatori devono andare oltre le ER di base e implementare un rigoroso pattern JDE BSFNBusiness Function: moduli di codice (solitamente in C) che eseguono logiche di business riutilizzabili nel sistema. table IO basato su C per leggere e aggiornare le tabelle custom in sicurezza.
Spostando questa logica in una BSFN in C, è possibile utilizzare APIInterfaccia di programmazione che permette a diverse applicazioni o componenti software di comunicare tra loro. come JDB_FetchForUpdate all'interno di confini transazionali espliciti. Ciò garantisce che un record sia bloccato a livello di database dal momento in cui viene letto fino all'esecuzione di JDB_CommitTransaction o JDB_RollbackTransaction. Nella nostra esperienza, la sostituzione degli aggiornamenti ER standard con questo pattern in interfacce ad alto volume riduce i deadlockSituazione di stallo in cui due processi si bloccano a vicenda aspettando il rilascio di risorse occupate dall'altro. del database dal 70% all'80%, garantendo che le tabelle custom di JDE 9.2 mantengano un'integrità assoluta dei dati.
Il Rischio di Aggiornamenti di Tabelle non Bloccati in JDE
In ambienti ad alto throughput, fare affidamento sulle Table I/O standard delle Event Rules (ER) per gli aggiornamenti è un rischio. Consideriamo una tabella custom di allocazione dell'inventario, F55101, che gestisce da 100 a 200 sessioni AIS concorrenti che inviano ordini da una piattaforma di e-commerce esterna. Quando due sessioni HTML parallele recuperano contemporaneamente lo stesso record F55101, entrambe leggono l'identico saldo iniziale, calcolano le rispettive allocazioni e scrivono i dati. La seconda scrittura sovrascrive silenziosamente la prima, causando un classico fallimento di concorrenza "last-in-wins" che corrompe il registro fisico delle scorte.
Le Table I/O standard di JDE nelle Event Rules utilizzano per impostazione predefinita una concorrenza ottimistica senza blocco a livello di database. In un ambiente kernel CallObjectProcesso server di JD Edwards dedicato all'esecuzione delle logiche di business (BSFN). multi-thread, questa mancanza di protezione porta a un'immediata corruzione dei dati sotto un pesante volume transazionale. Gli sviluppatori spesso presumono che il middlewareSoftware che funge da intermediario tra diverse applicazioni, strumenti o database per facilitare la comunicazione. del database JDE gestisce tutto automaticamente, ma le istruzioni SQLLinguaggio standard utilizzato per gestire, interrogare e manipolare i dati all'interno di un database. Update standard delle ER vengono eseguite come operazioni SQL distaccate. Senza un lock attivo, non c'è alcuna protezione contro un altro thread che modifichi la riga nella finestra di millisecondi tra le fasi di fetch e update.
Per eliminare queste race conditionsProblema informatico in cui il risultato di un processo dipende dalla sequenza o dalla tempistica di eventi non controllati. e le letture sporche (dirty reads), è necessario implementare il blocco esplicito dei record utilizzando le API a livello di database. Un pattern di aggiornamento sicuro richiede di avvolgere sia le operazioni di fetch che di update all'interno di un unico confine di transazione database atomico. Utilizzando JDB_FetchForUpdate all'interno di un confine di transazione manuale in una business function C, il motore del database mantiene un lock a livello di riga dal momento della lettura fino al commit o al rollback della transazione, costringendo i thread concorrenti a mettersi in coda correttamente.

Definizione della Tabella Custom e della Struttura Dati
I problemi di integrità del database negli ambienti enterprise derivano spesso da chiavi primarie tipizzate male nelle tabelle custom. Per lo schema della nostra tabella custom F550101, definiamo la chiave primaria utilizzando un UKIDUnique Key ID: un numero univoco assegnato a ogni record per garantirne l'identificazione precisa nel database. a 15 cifre insieme al Document Number (DOCO) e al Document Type (DCTO). Questa specifica struttura composita, abbinata a un campo di stato custom che richiede aggiornamenti condizionali, richiede una validazione rigorosa per prevenire collisioni di scrittura concorrente quando più processori batch vengono eseguiti simultaneamente.
Mappare l'UKID a un tipo di dati standard MathNumericFormato dati specifico di JD Edwards per gestire numeri e calcoli con precisione decimale garantita. nella struttura dati della business function previene gli errori di troncamento silenziosi che si verificano quando gli sviluppatori mappano chiavi primarie numeriche a tipi interi C standard. Nel design delle tabelle JDE, far corrispondere direttamente il tipo di colonna del database alle strutture interne dell'API garantisce che il motore di runtime dell'Enterprise Server elabori i valori in modo identico senza perdita di precisione sia sui kernel Linux che Windows.
Per coordinare scritture sicure, la struttura dati della business function deve passare esplicitamente il puntatore al confine della transazione e un flag di successo o fallimento all'applicazione interattiva chiamante o all'UBE. Se si verifica un conflitto di blocco dei record durante la fase di fetch-for-update, la business function assegna un flag di codice di ritorno specifico per comunicare il fallimento del lock o l'errore di validazione. Ciò consente all'applicazione interattiva chiamante di attivare istantaneamente un rollback del database o presentare un messaggio di errore chiaro all'utente invece di lasciare che lo stack di chiamateStruttura dati che memorizza informazioni sulle funzioni attive in un programma durante la sua esecuzione. fallisca silenziosamente. In genere mappiamo questo flag a un elemento dati a 1 carattere come EV01 nella struttura dati per mantenere l'interfaccia leggera e standard.
Il Pattern Safe Read-Before-Update in BSFN C
Un errore comune nelle business function C custom è presumere che un fetch standard metta in sicurezza un record per la modifica. In ambienti ad alta concorrenza, come un grande centro di distribuzione con centinaia di utenti simultanei che eseguono conferme pick-slip parallele, due thread leggeranno frequentemente lo stesso record F554211 contemporaneamente, portando a scritture sporche. Per evitare ciò, il primo passo è aprire la tabella di destinazione con l'API JDB_OpenTable, passando esplicitamente l'handle di transazione attivo dalla struttura lpBhvrcom per abilitare le funzionalità di rollback.
Una volta che l'handle della tabella è attivo, è necessario chiamare immediatamente l'API JDB_SetBehavior con l'opzione JDB_BEHAVIOR_LOCK. Questa specifica chiamata API istruisce il motore del database — sia esso in esecuzione su Oracle 19c o Microsoft SQL Server 2019 — a emettere un equivalente di SELECT FOR UPDATE a livello di database. Senza questo flag di comportamento impostato esplicitamente, un fetch standard non pone un lock esclusivo sulla riga, lasciando il record vulnerabile a letture sporche da parte di applicazioni interattive concorrenti o UBE batch.
Con il comportamento di blocco stabilito, eseguire JDB_FetchKeyed per recuperare il record specifico e verificarne lo stato corrente prima di applicare qualsiasi logica di business custom. In un'applicazione reale di registro inventario custom, questo passaggio garantisce che la quantità disponibile non sia cambiata tra la visualizzazione iniziale della griglia di ricerca e l'evento di aggiornamento effettivo del database. Fare affidamento sui valori a video invece di questo fetch fresco e bloccato è il modo in cui discrepanze di inventario dal 5% al 10% si insinuano nel sistema.
Se il record di destinazione è già bloccato da un altro thread del database, il motore del database rifiuterà la richiesta. Invece di lasciare che il kernel CallObject fallisca o vada in timeout — il che può causare il crash della sessione HTML dell'utente su Tools ReleaseVersione dei componenti tecnologici di base di JD Edwards che gestiscono l'infrastruttura e il runtime. 9.2.8 — è necessario gestire l'errore JDB_ERR_RECORD_LOCKED con grazia nel codice C. Intercettate questo codice di ritorno, chiamate jdeSetGBLError per inviare un messaggio intuitivo alla coda degli errori standard di JDE e uscite dalla funzione in modo pulito per mantenere la stabilità del sistema.
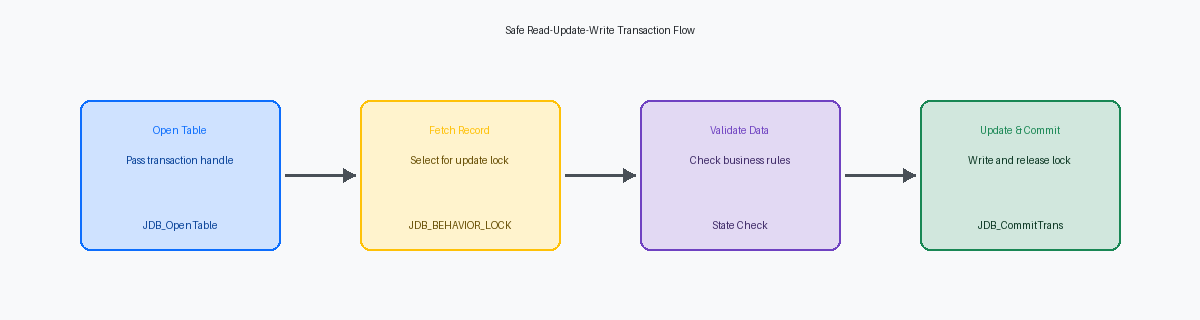
Implementazione dei Confini Transazionali e Rollback
Un disastro comune in ambienti ad alto volume, come l'elaborazione di 10.000-15.000 righe d'ordine di vendita all'ora tramite EDIElectronic Data Interchange: standard per lo scambio elettronico di documenti commerciali tra aziende diverse., è l'insorgenza di lock database orfani. Per prevenire ciò, la BSFN C custom deve legare esplicitamente le sue operazioni di database al confine transazionale attivo del chiamante. Ciò si ottiene passando l'handle di transazione dell'ambiente dalla struttura lpBhvrCom alle API JDB_OpenTableUser o JDB_StartTransaction, garantendo che le operazioni sulla tabella custom partecipino alla transazione padre.
Se una validazione delle regole di business fallisce dopo il recupero del record — come trovare un codice di stato imprevisto 560 invece di 520 — è necessario attivare immediatamente un rollback. Chiamare JDB_RollbackTransaction utilizzando l'handle di transazione attivo garantisce che eventuali inserimenti o aggiornamenti precedenti non confermati all'interno di quel confine specifico vengano istantaneamente annullati a livello di database. La mancata esecuzione di questa API lascia il database in uno stato incoerente, dove esistono record padre orfani senza i corrispondenti dettagli figli.
Una volta superata la validazione e quando l'operazione JDB_UpdateKeyed restituisce uno stato JDEDB_PASSED con successo, è necessario confermare prontamente la transazione. L'esecuzione di JDB_CommitTransaction scrive le modifiche in modo permanente nel database e, cosa fondamentale, rilascia il lock esclusivo sulla riga del database. In ambienti ad alta concorrenza, ritardare questo commit anche solo di 200-300 millisecondi può causare una lock escalation in SQL Server o Oracle Database, bloccando UBE e applicazioni interattive concorrenti.
Un errore critico durante la gestione degli errori è saltare le routine di pulizia quando si esce anticipatamente dalla funzione. Se si esce dal codice C in seguito a un fallimento della validazione senza chiamare JDB_CloseTable, il middleware JDE mantiene attivo l'handle della tabella in memoria. Questa omissione causa un memory leak silenzioso nel CallObject Kernel, consumando tipicamente da 15 a 30 KB per handle perso, e mantiene i lock del database aperti indefinitamente fino al riciclo del processo kernel.
Esempio di Codice: Dettagli di Implementazione BSFN C
Nelle nostre verifiche delle business function C custom, troviamo frequentemente instabilità del kernel CallObject causata da un'inizializzazione pigra dei puntatori. Per prevenire la corruzione della memoria all'interno del runtime JDE, è necessario inizializzare esplicitamente le variabili locali, inclusi l'handle utente HUSER e l'handle di richiesta tabella HREQUEST, utilizzando API standard come memset. Se si lasciano questi puntatori non inizializzati, un kernel CallObject multi-thread in esecuzione sul server enterprise finirà per fare riferimento a indirizzi di memoria obsoleti, portando a crash intermittenti difficili da isolare in Server Manager.
Una volta stabilito l'handle utente, l'apertura della tabella custom di destinazione richiede un passaggio di validazione che gli sviluppatori spesso saltano. È necessario controllare esplicitamente il valore di ritorno di JDB_OpenTable rispetto a JDEDB_PASSED. Un fallimento sulla configurazione errata della mappatura Object Configuration Manager (OCM) o un problema di connessione al database sottostante. Intercettate questo errore tempestivamente previene operazioni successive su un handle di richiesta nullo, che innescherebbe una violazione di accesso fatale nel kernel.
Quando si esegue l'aggiornamento effettivo, il codice deve utilizzare l'API JDB_UpdateKeyed piuttosto che funzioni di aggiornamento generiche. Questa API richiede di popolare e passare l'esatta struttura della chiave della tabella custom, garantendo che il motore del database colpisca solo la riga specifica corrispondente alla chiave univoca. Definendo esplicitamente la struttura dell'indice, si evita che il database passi a una scansione completa della tabella (full-table scan), che è una causa comune di lock escalation durante l'elaborazione ad alto volume.
Infine, la funzione deve instradare tutti i percorsi logici attraverso un blocco di pulizia dedicato alla fine del codice. Questa routine di uscita deve chiamare JDB_CloseTable e JDB_FreeUser per rilasciare le risorse allocate. La mancata liberazione di questi handle causa una frammentazione cumulativa della memoria nel kernel CallObject, costringendo infine a un riciclo del kernel durante le ore di picco operativo.
Test e Validazione delle Prestazioni dei Lock
Per dimostrare che la business function C custom gestisce la concorrenza senza deadlock, avviate due esecuzioni UBE locali parallele che puntano allo stesso intervallo di record. Aprite i file JDEDEBUG.log risultanti e cercate specificamente l'istruzione SQL contenente SELECT ... FOR UPDATE (o l'equivalente WITH (UPDLOCK) se state utilizzando Microsoft SQL Server). Se non vedete questa esatta sintassi immediatamente prima della vostra istruzione di aggiornamento, le vostre Table I/O stanno bypassando il meccanismo di blocco nativo del motore del database, lasciando la vostra tabella custom vulnerabile a letture sporche.
Durante le ore di picco, quando i volumi transazionali superano le 50.000-100.000 scritture all'ora, monitorate la lock escalation del database utilizzando la vista V$LOCK di Oracle o le Dynamic Management Views (DMV) di SQL Server. È necessario verificare che i lock a livello di riga non stiano passando a lock a livello di tabella, il che blocca le sessioni utente in applicazioni standard come P4210 o P4312. Se si verifica l'escalation, di solito è perché il confine della transazione viene mantenuto aperto troppo a lungo da una chiamata JDB_CommitTransaction mal posizionata.
Per ridurre al minimo la durata di questi lock del database, mappate la BSFN custom nell'Object Configuration Manager per essere eseguita esclusivamente sull'enterprise server. L'esecuzione della logica di business localmente su un server HTML o su una workstation introduce hop di rete che allungano i tempi di mantenimento dei lock. Un tipico ciclo sicuro di lettura-aggiornamento all'interno di un ambiente enterprise server ben ottimizzato dovrebbe essere eseguito in meno di 20 millisecondi, rispetto agli oltre 100 millisecondi se eseguito attraverso una WANWide Area Network: rete di telecomunicazioni che si estende su una grande distanza geografica per collegare diverse reti locali. o una sottorete mal instradata. Mantenete bassa questa latenza di rete per evitare che il lock contentionConflitto che si verifica quando troppi processi cercano di bloccare la stessa risorsa, rallentando il sistema. degradi le prestazioni delle applicazioni interattive concorrenti.
L'implementazione di questi pattern sicuri di Table IO è essenziale quando si gestisce un parco di codice custom da 5.000 a 15.000 oggetti. Garantire che il team di sviluppo applichi costantemente questi confini transazionali è ciò che separa le implementazioni enterprise stabili da quelle afflitte da lock intermittenti del database e fallimenti del kernel. Per un approfondimento sull'ottimizzazione delle business function basate su C, contattate il nostro team di architettura enterprise per pianificare un audit del codice.
