
Durante l'audit di modifiche custom negli ambienti JDE 9.2Versione del software gestionale JD Edwards EnterpriseOne., trovo regolarmente un difetto architetturale comune: i valori predefiniti delle colonne per le tabelle custom (come una F550101) sono cablati in più applicazioni interattive (APPL)Programmi JD Edwards dotati di interfaccia grafica per l'interazione con l'utente.. Affidarsi ai vincoli di default a livello di database fallisce perché il layer middleware JDBStrato software che gestisce la comunicazione tra le applicazioni JD Edwards e il database. inserisce esplicitamente spazi vuoti o zeri, sovrascrivendo i default del database. L'implementazione di esempi JDE NERLinguaggio di programmazione visuale per creare logica di business riutilizzabile. per i valori predefiniti delle tabelle custom consente ai team di centralizzare la validazione e l'assegnazione prima di chiamare l'insert di Table I/OOperazioni di lettura o scrittura dati all'interno delle tabelle del database., garantendo l'integrità dei dati in tutti i punti di ingresso.
Questa guida fornisce modelli di implementazione concreti per centralizzare la validazione e l'assegnazione prima di chiamare l'insert di Table I/O. Spostare questa logica fuori dalle Event RulesIstruzioni di programmazione eseguite al verificarsi di specifici eventi nel software. di FDAForm Design Aid, lo strumento per sviluppare le interfacce utente in JD Edwards. e in una singola business function riutilizzabile riduce l'impronta del codice custom di una parte significativa delle applicazioni, nella nostra esperienza circa da un terzo alla metà. Questo cambiamento semplifica i futuri aggiornamenti dei Tools ReleaseAggiornamenti tecnici della piattaforma tecnologica sottostante di JD Edwards. e garantisce una formattazione coerente dei dati, sia che i record provengano da una APPL, un UBEUniversal Batch Engine, il sistema per l'esecuzione di report e processi massivi. o un'orchestrazione basata su AISApplication Interface Services, interfaccia per integrare JDE con sistemi esterni via web..
Il costo della logica di default sparsa nelle APPL
Recentemente ho analizzato un sistema di spedizione custom dove gli sviluppatori avevano sparso la logica di default negli eventi Write Grid Line-Before e OK-Post Button Clicked di diverse APPL. Questo modello di progettazione crea un debito tecnico immediato perché le Event Rules (ER) delle applicazioni interattive sono notoriamente difficili da testare e mantenere al di fuori del loro specifico contesto di runtime. Quando i requisiti aziendali cambiano, come l'aggiornamento di un branch/plant predefinito o di un codice di stato, si è costretti a fare il check-out, modificare e creare pacchetti per più applicazioni interattive invece di un singolo componente riutilizzabile.
Consideriamo una tabella master custom come la F550101, che richiede valori predefiniti per una dozzina o più di campi distinti, inclusi i campi standard di audit, i tipi di ricerca predefiniti e i codici valuta. Se questa tabella viene aggiornata da più APPL (una schermata di inserimento mobile, un gestore master desktop e un'applicazione portale) insieme a diversi UBE batch che eseguono integrazioni notturne, duplicare quella logica di default su tutti i punti di ingresso garantisce la corruzione dei dati. Uno sviluppatore che modifica l'APPL desktop dimenticherà inevitabilmente l'assegnazione di un valore di default in uno degli UBE in background, causando record orfani o valori nulli in colonne critiche come la GL class o il tax explanation code.
Incapsulare questa logica di default all'interno di una Named Event Rule (NER) dedicata riduce l'impronta del codice APPL di oltre la metà nei moduli standard di inserimento dati. Invece di mantenere decine di righe di ER che mappano i valori di default in ogni form, l'applicazione interattiva chiama semplicemente una singola BSFNBusiness Function, un modulo di codice riutilizzabile che esegue specifiche operazioni logiche. passando la struttura dati della F550101 prima dell'insert. Questo spostamento architetturale garantisce una coerenza dell'integrità dei dati su tutti i canali di ingresso e assicura che qualsiasi futura regolazione dei valori predefiniti richieda una singola modifica in una BSFN centralizzata.

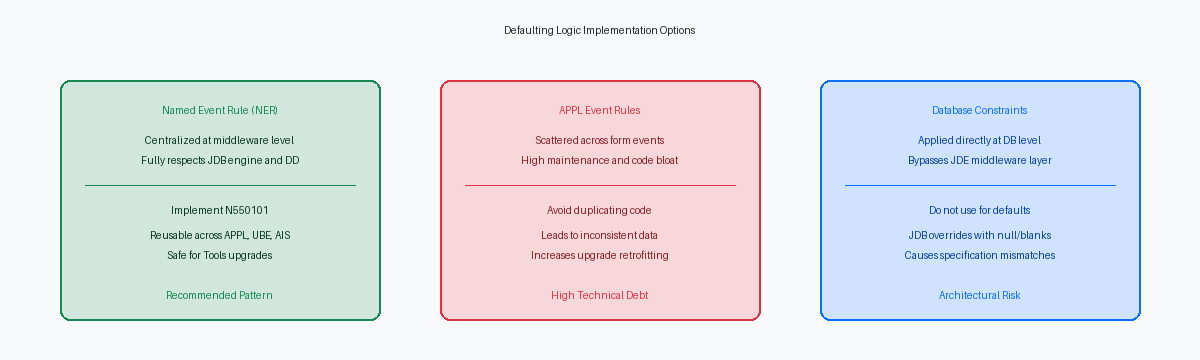
Perché i vincoli di default del database falliscono in JDE
Gli amministratori di database spesso cercano di bypassare lo sviluppo JDE eseguendo un'istruzione ALTER TABLE per applicare un vincolo DEFAULT 'Y' su una tabella custom come la F550101. Questo approccio fallisce immediatamente a causa del design del motore middleware JDB. Quando un'applicazione o un processo batch attiva un inserimento, il layer JDB non omette i campi non mappati dall'istruzione SQLLinguaggio standard utilizzato per interrogare e gestire i dati nei database.. Al contrario, costruisce esplicitamente un'istruzione INSERT contenente ogni colonna definita nelle Table Specifications. Poiché il motore JDB passa esplicitamente uno spazio vuoto, uno zero o un puntatore nullo per le variabili non inizializzate, il motore del database lo tratta come un valore esplicito, sovrascrivendo completamente il vincolo di default a livello di database.
Affidarsi ai vincoli a livello di database per forzare i valori predefiniti introduce fallimenti silenziosi e derive di configurazione tra i vari ambienti. Quando si promuove la F550101 da DV920 a PY920 utilizzando l' Object Management Workbench (OMW)Strumento per gestire lo sviluppo e il trasferimento degli oggetti tra ambienti. e si rigenera la tabella, lo strumento di generazione standard elimina e ricrea la tabella fisica. Questo processo cancella qualsiasi vincolo SQL Server o Oracle DB personalizzato. Gli sviluppatori si ritrovano quindi a chiedersi perché un processo che funzionava nel database di sviluppo non riesca a popolare i valori predefiniti in test o produzione.
Il modello architetturale corretto consiste nell'imporre i valori predefiniti a livello di middleware applicativo utilizzando una Named Event Rule. Poiché una NER viene eseguita all'interno dello stack di chiamate standard di EnterpriseOne — sia sul server HTML che mappata su un enterprise server tramite Object Configuration Manager (OCM)Configurazione che stabilisce dove viene eseguita la logica o dove risiedono i dati. — rispetta le regole native del Data DictionaryCatalogo centrale che definisce le proprietà di ogni campo dati nel sistema. di JDE e le Table Specs. Intercettando i dati prima che raggiungano il layer JDB, la NER garantisce che il motore di runtime scriva correttamente i valori di default in modo coerente, sia che la transazione provenga da un'applicazione interattiva, un UBE batch o un'orchestrazione AIS.
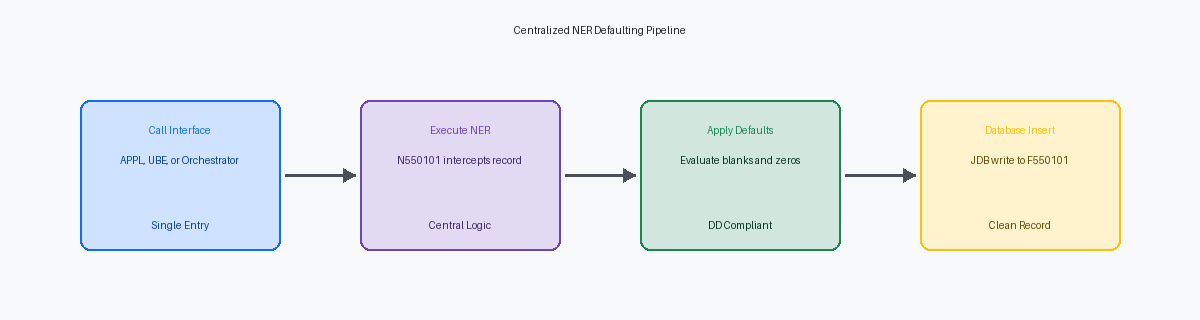
Progettazione della NER centralizzata per l'inserimento in tabella
Spostare la logica di default dagli eventi interattivi come Grid Record is Fetched a una Named Event Rule centralizzata, come N550101, è l'unico modo per prevenire la corruzione dei dati quando le integrazioni esterne bypassano la GUIInterfaccia grafica che permette all'utente di interagire con il software tramite elementi visivi.. Quando si costruisce N550101 come motore dedicato alla validazione pre-insert e al defaulting, si garantisce che ogni percorso di scrittura rispetti le stesse regole di business. Questo cambiamento elimina il rischio di perdere i campi dell'header quando le integrazioni scrivono direttamente nelle tabelle di interfaccia.
Il fondamento di questo modello risiede nella data structure associata, D550101, che deve rispecchiare le colonne della tabella custom. Passando l'intero record della tabella come una struttura IN/OUT, la NER può ispezionare lo stato di ogni campo e modificare i valori vuoti sul posto. Se si passa solo un sottoinsieme di chiavi, si finisce per scrivere logica di fetch ridondante all'interno della BSFN, il che degrada le prestazioni durante l'elaborazione di batch di migliaia di record.
All'interno della NER, la logica esegue una valutazione condizionale rigorosa: applica valori predefiniti come la data di sistema (SL DateToday) o i Next NumbersSistema automatico per la generazione di numeri sequenziali univoci. solo se il parametro in entrata è vuoto o zero. Ad esempio, se il chiamante passa una data di transazione esplicita, N550101 la rispetta; se è vuota, la NER la popola. Ciò impedisce di sovrascrivere input intenzionali dell'utente con default di sistema cablati durante le importazioni batch tramite UBE.
Questo modello di progettazione trasforma la NER in un servizio centralizzato accessibile in tutto l'ecosistema EnterpriseOne. Sia che una transazione provenga da un'applicazione interattiva P550101, un UBE batch R550101 o una chiamata RESTStandard di comunicazione web per lo scambio di dati tra applicazioni diverse. instradata tramite l'AIS Orchestrator, si applicano esattamente le stesse regole di default. Questo punto di ingresso unificato riduce significativamente l'impronta di retrofitting durante gli aggiornamenti dei Tools Release, poiché si ha un solo oggetto da convalidare.
Analisi del codice della logica di default
Nelle Event Rules della nostra NER custom, la prima linea di difesa è la validazione della struttura dati in entrata. Se un campo alfanumerico come Company (CO) è uguale a <Blank> o un campo numerico come Address Number (AN8) è uguale a <Zero>, la NER deve intercettare e applicare il default. Implementiamo questo utilizzando istruzioni If esplicite che controllano CO e AN8 prima che avvenga qualsiasi Table I/O, impedendo al database di ricevere record incompleti.
Quando la chiave primaria della nostra tabella custom viene lasciata vuota dal processo chiamante, la NER recupera dinamicamente un identificatore univoco. Chiamiamo la business function F0002 Get Next Number all'interno della NER, passando il codice del sistema di destinazione e l'indice del next number per popolare il campo chiave. Ciò garantisce che anche se uno sviluppatore dimentica di assegnare una chiave in una APPL o in un UBE, la NER garantisce l'integrità del database generando automaticamente l'ID sequenziale successivo.
Il popolamento coerente dei campi di audit è il punto in cui la codifica manuale nelle APPL spesso fallisce. All'interno di questa NER centralizzata, mappiamo esplicitamente i valori di sistema JDE SL UserID al campo USER, SL DateToday a UPMJ e l'ora di sistema a TDAY. Questo design assicura che ogni inserimento, sia esso avviato da un'applicazione interattiva, un UBE batch o un'orchestrazione AIS esterna, porti una traccia di audit identica e a prova di manomissione.
Per impedire all'applicazione chiamante di procedere con una transazione corrotta, la NER espone un flag di ritorno, tipicamente cErrorFlag (EV01). Se una validazione critica fallisce — come un codice azienda non valido o un errore nella routine dei next numbers — la NER imposta questo flag a '1' e bypassa l'inserimento nella tabella. L'APPL chiamante o la business function valuta questo codice di ritorno immediatamente dopo l'esecuzione, consentendo di interrompere l'elaborazione e annullare la transazione prima che dati non validi raggiungano il database.
Semplificazione delle APPL e modelli di chiamata
In una tipica applicazione interattiva P550101 per l'estensione dell'anagrafica clienti, gli sviluppatori spesso riempiono gli eventi "OK-Post Button Clicked" o "Grid Record is Fetched" con decine di righe di validazioni ripetitive e assegnazioni cablate. Sostituire questa logica sparsa con una singola chiamata alla Named Event Rule (NER) N550101 riduce significativamente l'impronta delle Event Rules della form. Per le form header-less detail, inserire questa chiamata nell'evento Write Grid Line-Before garantisce che ogni riga venga elaborata correttamente prima di raggiungere il database. Per le form fix-inspect, l'evento "Add Record to DB - Before" funge da gatekeeper ottimale per intercettare il buffer e applicare i default.
Disaccoppiare questa logica dal layer di presentazione accelera direttamente i futuri cicli di aggiornamento. Quando si passa dalla 9.1 alla 9.2, confrontare e adattare un'APPL semplificata con modifiche minime alle Event Rules richiede minuti invece di ore. L'interfaccia utente diventa un puro veicolo di inserimento dati, mentre le regole di business principali risiedono in sicurezza all'interno della NER centralizzata. Questo isolamento previene il comune mal di testa degli upgrade in cui le modifiche alle form custom vengono sovrascritte o richiedono faticose unioni manuali durante un aggiornamento dei Tools Release o dell'applicazione.
Questo modello architetturale offre miglioramenti immediati quando si integrano processi batch come l'UBE di caricamento clienti R550101. Invece di duplicare le regole di default e validazione all'interno dell'evento "Do Section" dell'UBE, il report batch chiama la stessa identica business function N550101. Sia che un record venga creato manualmente da un operatore in P550101 o importato in blocco tramite R550101 da un file flat esterno, vengono applicati coerentemente gli stessi default del database. Questo singolo punto di manutenzione elimina le discrepanze di integrità dei dati tra inserimenti interattivi e interfacce batch.
Considerazioni su prestazioni e cache per i default NER
Eseguire una NER custom su ogni singolo inserimento di riga può degradare gravemente le prestazioni batch se il codice sottostante esegue ricerche nel database non memorizzate in cacheMemoria temporanea ad alta velocità utilizzata per ridurre i tempi di accesso ai dati richiesti frequentemente.. Per un UBE ad alto volume che elabora decine di migliaia di record, una funzione mal progettata trasformerà una breve esecuzione in un prolungato collo di bottiglia. Per evitare ciò, il design deve puntare a un overhead di esecuzione inferiore a pochi millisecondi per inserimento di record durante l'elaborazione massiva. Questo stretto margine di prestazioni è del tutto realizzabile se si limita l'ambito della NER e si gestisce il recupero dei dati in modo intelligente.
Ridurre al minimo i roundtrip al database all'interno della NER è il modo più efficace per proteggere le prestazioni del sistema. Invece di eseguire istruzioni dirette di select o fetch-single contro le tabelle di controllo per ogni riga, utilizza la JDE Service CacheMemoria temporanea del server utilizzata per velocizzare il recupero di dati frequenti. o chiama business function standard che impiegano il caching interno. Ad esempio, quando si convalidano o si impostano valori predefiniti basati sulla business unit, instrada il controllo attraverso la cache di validazione standard F0006 Branch/Plant piuttosto che interrogare ripetutamente la tabella fisica del database. Ciò mantiene le ricerche nella memoria locale dell'enterprise server, riducendo l'overhead di ogni controllo a microsecondi.
Mantieni l'architettura della NER semplice concentrandoti rigorosamente sul defaulting dei dati e sulla validazione di base, lasciando la logica di business complessa alle funzioni di elaborazione a valle. Cercare di eseguire allocazioni di inventario multi-livello o controlli del credito all'interno di una routine di default a livello di tabella è un modello di progettazione che invita a deadlockErrore che si verifica quando due processi si bloccano a vicenda sul database. del database e a un eccessivo gonfiore dello stack di chiamate. Se un campo richiede calcoli condizionali complessi, assegna un default di fallback sicuro nella NER e lascia che la successiva Master Business FunctionLogica complessa centralizzata che gestisce transazioni complete su tabelle principali. gestisca il lavoro pesante.
Centralizzare la logica di default all'interno di una NER è una mossa standard per ridurre un patrimonio di codice custom che spesso supera i 5.000-15.000 oggetti. Se la tua roadmap 9.2.x.x prevede tabelle ad alta concorrenza, gli articoli correlati sulla gestione della memoria delle C BSFN e sui modelli di cache custom forniscono la profondità tecnica necessaria per prevenire guasti del kernelProcesso fondamentale del sistema che gestisce le operazioni principali del server.. Per coloro che gestiscono retrofit complessi, il mio portfolio di progetti tecnici contiene esempi specifici di pulizia delle personalizzazioni su scala enterprise e strategie di ottimizzazione del database che hanno ridotto con successo la durata degli upgrade da diversi mesi a sole 6-9 settimane.
