

In un tipico ambiente JDE enterpriseJD Edwards EnterpriseOne, un software ERP di Oracle per la gestione integrata dei processi aziendali complessi., una singola tabella custom come la F55101 ha spesso la sua logica di Select, Fetch, Insert e Update duplicata in 15 o 20 diversi APPLApplicazioni interattive di JD Edwards con cui gli utenti interagiscono tramite interfaccia web. e UBEUniversal Batch Engine, programmi utilizzati per elaborazioni massive di dati o generazione di report.. Questo approccio "copia-incolla" alle Event Rules (ER)Linguaggio di programmazione visuale proprietario di JD Edwards per definire la logica di business. crea un enorme onere di manutenzione; una semplice modifica allo schema del database—come l'aggiunta di un campo category code di 10 caratteri—costringe gli sviluppatori a rifattorizzare e testare manualmente dozzine di singoli oggetti. L'adozione di un pattern JDE NERNamed Event Rule, una funzione di business riutilizzabile scritta utilizzando il linguaggio delle Event Rules. table IOOperazioni di Input/Output (lettura, scrittura, modifica) eseguite direttamente sulle tabelle del database. unificato per evitare blocchi ER ripetuti consolida queste operazioni di database in una singola Named Event Rule guidata da azioni.
Incapsulando tutte le interazioni con il database per una tabella all'interno di una singola NER, si riduce il volume delle ER custom dal 30% al 50% e si stabilisce un layer di accesso ai dati pulito e modulare direttamente nel set di strumenti JDE. Invece di disperdere istruzioni Table I/O grezze tra i progetti dell'Object Management Workbench (OMW)Lo strumento di JD Edwards per la gestione del ciclo di vita degli oggetti e dello sviluppo software., gli sviluppatori chiamano una BSFNBusiness Function, componenti software riutilizzabili che contengono logica di business specifica in JD Edwards. centralizzata utilizzando un semplice parametro action-code (ad esempio, 'A' per Add, 'U' per Update, 'F' for Fetch). Questo cambiamento riduce drasticamente i tempi di retrofitting durante gli aggiornamenti di Tools ReleaseLo strato tecnologico di base che gestisce l'interazione tra il software JD Edwards e l'infrastruttura hardware. e garantisce l'assoluta integrità dei dati in tutti i punti di ingresso, dalle applicazioni interattive ai payload in entrata di AIS OrchestrationStrumento per automatizzare processi JDE e integrare sistemi esterni tramite servizi web REST..
Il costo della Table IO dispersa nelle Event Rules
Quando modifichiamo una tabella custom come la F55101—ad esempio aggiungendo un campo cost center (MCU) da 10 caratteri o una data di audit—il mal di testa immediato non è la rigenerazione della tabella stessa. Il vero dolore è dare la caccia alle 10 o 15 diverse applicazioni interattive (APPL) e report batch (UBE) in cui uno sviluppatore ha trascinato e rilasciato manualmente i blocchi di Event Rules Fetch, Select e Update. La duplicazione della Table I/O in questi oggetti crea un'impronta di manutenzione esponenziale, trasformando un semplice aggiornamento dello schema di due ore in un esercizio di ricerca e sostituzione di più giorni tra i progetti dell'Object Management Workbench (OMW).
In un ambiente standard 9.2, una tabella custom come la F55101 ha spesso le sue operazioni CRUDAcronimo per le operazioni base del database: Create (Creazione), Read (Lettura), Update (Aggiornamento) e Delete (Cancellazione). copiate e incollate in 10-15 punti di ingresso distinti, che vanno dalla schermata di manutenzione primaria agli UBE EDI custom. Ciascuno di questi blocchi Event Rules ripetuti rappresenta un punto critico di fallimento. Uno sviluppatore che modifica un'istruzione Select o Update in un report batch personalizzato potrebbe facilmente omettere un campo indice chiave come UKIDUnique Key ID, un identificatore numerico univoco utilizzato per distinguere i record in una tabella. o LNID, portando a scansioni di tabella che degradano le prestazioni del database sul vostro database Oracle o SQL Server.
Questa architettura dispersa paralizza anche la capacità di applicare l'integrità globale dei dati o una registrazione coerente degli audit. Se l'azienda decide di registrare ogni modifica ai campi di stato della F55101 in una tabella di audit personalizzata, è necessario inserire manualmente tale logica di logging in più oggetti chiamanti individualmente. Se si dimentica anche una sola schermata interattiva, la traccia di audit di conformità si interrompe. Per evitare ciò, la mia raccomandazione diretta è di isolare tutte le interazioni del database per la F55101 in una singola business function dedicata prima del prossimo aggiornamento della Tools Release.

Progettare una NER focalizzata per le operazioni sulle tabelle
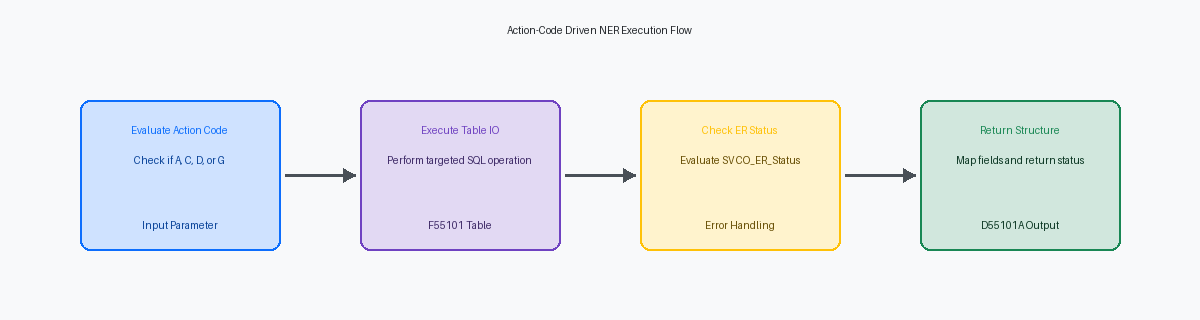
Nella nostra remediation del sistema di order entry custom di un cliente di distribuzione globale, abbiamo sostituito oltre cento singole istruzioni Table IO sparse in una dozzina di applicazioni diverse con una singola Named Event Rule (NER) dedicata. La base di questo pattern è una struttura dati unificata, D55101A, che incapsula ogni colonna della tabella di destinazione insieme a parametri di controllo critici. Invece di passare singole variabili attraverso più livelli, questa struttura raggruppa i campi funzionali della tabella con flag di controllo come Action Code (szActionCode) e Return Status (cReturnStatus).
All'interno della NER, una struttura condizionale valuta l'Action Code per determinare l'operazione del database. Imponiamo uno standard rigoroso: 'A' esegue una Insert per aggiungere un record, 'C' esegue una Update per modificarlo, 'D' esegue una Delete e 'G' attiva una Fetch Single per ottenere i dati. Questo design impedisce agli sviluppatori di scrivere loop Select/Fetch ad-hoc e incompleti nelle Event Rules dell'applicazione, forzando tutte le interazioni del database attraverso un percorso di codice prevedibile e testato.
Il consolidamento di queste operazioni in una singola NER garantisce che le transazioni del database siano gestite come un'unica unità di lavoro prevedibile, il che è fondamentale quando si mappa sui confini dell'elaborazione delle transazioni di EnterpriseOne. Se un inserimento fallisce durante un aggiornamento multi-tabella, la NER può immediatamente eseguire il rollback della transazione e restituire uno stato di errore '1' al chiamante, prevenendo record orfani in tabelle custom come la F55101. Questo layer di astrazione isola completamente il layout fisico della tabella dalle applicazioni chiamanti. Se si aggiunge una nuova colonna alla tabella o si modifica un indice, si aggiorna il codice interno della NER e la struttura dati, lasciando invariate le Event Rules chiamanti ed eliminando la necessità di ricostruire dozzine di oggetti APPL o UBE.
Gestione di Table IO complesse e stati di errore
In oltre una dozzina di audit di upgrade, ho visto NER custom fallire silenziosamente perché gli sviluppatori davano per scontato che una istruzione Select avesse sempre successo. La logica di valutazione dello stato ER deve ispezionare SV CO_ER_StatusVariabile di sistema di JD Edwards che indica se l'ultima operazione sulle tabelle è stata eseguita con successo. immediatamente dopo ogni singola istruzione Fetch Single, Update o Delete. Inserire anche solo un'assegnazione o una chiamata a una BSFN di utilità tra la Table IO e il controllo dello stato rischia di sovrascrivere la variabile di sistema, con conseguenti falsi positivi che inquinano tabelle come la F41021 con dati corrotti.
Invece di codificare il testo del glossario o chiamare Set ER Error all'interno della NER, mappate gli stati del database su un parametro di output standardizzato come cReturnCode ('0' per successo, '1' per record non trovato, '2' per chiave duplicata). Ciò consente all'APPL o all'UBE chiamante di gestire il fallimento in modo appropriato. Un'APPL di vendita al dettaglio potrebbe interrompere la transazione, mentre un UBE batch notturno potrebbe semplicemente registrare l'avviso e procedere. Passare il codice grezzo lungo lo stack mantiene la NER riutilizzabile in diversi ambienti.
Quando si gestiscono fetch a chiave parziale con un loop Select e Fetch Next, non convalidare lo stato di ritorno della Select iniziale è una trappola pericolosa. Se la Select fallisce e il codice entra in un loop While controllato da SV CO_ER_Status is equal to CO SUCCESS, si può innescare un loop infinito che impegna la CPU dell'enterprise server alla massima capacità. Inizializzate sempre le variabili di controllo del loop e controllate esplicitamente lo stato della prima Fetch Next prima di entrare nel blocco.
Implementazione passo-passo della NER per Table IO custom
La standardizzazione dell'accesso al database in una Named Event Rule (NER) custom inizia con una progettazione rigida della struttura dati. Mappiamo le chiavi primarie, i campi del payload e un Action Code di 1 carattere (cActionCode) per instradare l'esecuzione. All'interno della NER, la prima riga di Event Rules deve essere un blocco di branching condizionale—tipicamente una struttura Select—che valuta questo Action Code per instradare l'esecuzione. Questo routing centralizzato garantisce che non venga effettuata alcuna chiamata al database senza aver prima convalidato il tipo di operazione, eliminando il rischio di aggiornamenti accidentali della tabella.
Quando l'Action Code è 'G' (Get), la NER valuta i parametri chiave in entrata. Se il chiamante passa una chiave univoca completa, il codice esegue una Fetch Single diretta sulla tabella F55101; in caso contrario, avvia una sequenza di cursori Open, Fetch e Close a seconda che venga fornita o meno una chiave univoca. Quando l'Action Code è 'A' (Add), la NER intercetta l'operazione di scrittura per popolare centralmente i campi di audit standard. Invece di fare affidamento sul chiamante per passarli, la NER assegna programmaticamente l'ID utente (USER), l'ID programma (PID), la data di aggiornamento (UPMJ) e l'ora del giorno (TDAY) prima di eseguire l'istruzione Insert.
Per un'operazione 'C' (Change), la NER esegue una Fetch for Update o un'istruzione Update diretta basata sulle chiavi primarie passate nella struttura dati. Se è richiesto il blocco ottimistico, la Fetch for Update blocca la riga nel database F55101 prima di modificare il record. In caso contrario, viene eseguito un aggiornamento diretto, mappando rigorosamente sulle chiavi primarie. Ciò incapsula la durata dei blocchi del database in millisecondi, prevenendo i blocchi prolungati che si verificano quando gli sviluppatori scrivono Table IO manuali direttamente nelle form event rules.
Esempi per il chiamante: Refactoring delle Event Rules di APPL e UBE
Osservate l'evento Grid Record Is Validated su un clone custom standard della P4210L'applicazione standard di JD Edwards per l'inserimento e la gestione degli ordini di vendita.. In una tipica implementazione legacy, questo evento contiene dozzine di righe di Table I/O manuale, sparse con istruzioni Fetch Single per convalidare i record item branch. Rifattorizzando questa logica, comprimiamo quelle righe di Event Rules ridondanti in una singola e pulita chiamata BSFN passando i parametri chiave. Questo spostamento riduce la dimensione delle specifiche locali dell'APPL ed elimina il rischio di handle di tabella non chiusi durante lo scorrimento rapido della griglia.
Questo approccio di refactoring isola il layer di presentazione dell'applicazione interattiva dal layer di accesso al database, imitando una moderna architettura Model-View-Controller all'interno di JD Edwards. Quando si rimuove l'esecuzione SQL da Form Design Aid (FDA)Lo strumento di sviluppo utilizzato per creare e modificare le interfacce grafiche delle applicazioni JD Edwards. e la si incapsula all'interno di una NER, si ottiene un unico punto di manutenzione. Se una tabella custom come la F554101 richiede un nuovo indice o una nuova convalida, si modifica la NER centrale una sola volta invece di cercare tra dozzine di form di inserimento APPL.
Per l'elaborazione batch, un UBE ad alto volume come un R42565Il programma batch standard di JD Edwards utilizzato per la stampa delle fatture di vendita. personalizzato che elabora decine di migliaia di record beneficia in modo significativo di questo design. Invece di ripetere complessi blocchi Fetch Single nell'evento Do Section della sezione di dettaglio principale, l'UBE chiama la NER custom con un Action Code di 'G' per recuperare gli override dei prezzi. L'UBE gestisce la struttura dati restituita in modo pulito, valutando il flag di successo prima di formattare la riga di output.
Quando l'operazione sulla tabella comporta scritture non bloccanti, come l'aggiornamento di una tabella di log di audit custom come la F559801, gli sviluppatori possono tranquillamente selezionare il flag di esecuzione Asynchronous nelle proprietà della chiamata BSFN. Ciò consente al thread interattivo primario di continuare l'elaborazione senza attendere la conferma di scrittura del database. L'esecuzione asincrona della NER previene i ritardi dell'interfaccia utente durante le ore di picco transazionale, mantenendo standardizzata l'interazione con il database.
Successi in termini di prestazioni e manutenzione sul campo
In un recente refactoring di un sistema custom di allocazione dell'inventario per un importante distributore di metalli, abbiamo sostituito le istruzioni Table I/O sparse delle tabelle F41021 e F4111 in diverse applicazioni di inserimento con una singola NER consolidata. Questo cambiamento architettonico ha ridotto il numero di righe delle event rules custom di quasi la metà negli oggetti interessati. Eliminando i blocchi ridondanti di select, fetch e update dai singoli eventi delle form, abbiamo eliminato il codice spaghetti che in precedenza oscurava la logica di business effettiva.
Il consolidamento della Table I/O in una NER compilata riduce direttamente la dimensione delle specsSpecifiche tecniche compilate che descrivono il comportamento e l'aspetto degli oggetti JD Edwards durante l'esecuzione. per le applicazioni chiamanti e gli UBE. Quando un'APPL o un UBE ha meno istruzioni ER table I/O incorporate, il runtime engineIl motore software che esegue la logica e le applicazioni di JD Edwards sui server. impiega meno tempo a analizzare e caricare le specifiche in memoria durante l'esecuzione. Ciò si traduce in miglioramenti misurabili nei tempi di avvio delle applicazioni e nelle fasi di inizializzazione dei batch, specialmente su connessioni WAN ad alta latenza o in ambienti HTML server densi.
Gli amministratori di database beneficiano immediatamente di questo design perché standardizza i pattern di accesso alle tabelle. Invece di gestire dozzine di query SQL ad-hoc leggermente diverse generate da varie APPL, il motore del database elabora piani di esecuzione SQL altamente prevedibili e riutilizzabili generati attraverso un singolo oggetto centralizzato. Questa coerenza consente all'ottimizzatore del database di memorizzare nella cache i piani di esecuzione in modo più efficace, riducendo il sovraccarico della CPU sul server del database durante i volumi di transazione di picco.
Dal punto di vista della manutenzione, la risoluzione dei problemi del database o della corruzione dei dati non è più una caccia di più giorni tra event rules nidificate. Gli sviluppatori possono aprire JDEDebuggerStrumento di diagnostica che permette di analizzare l'esecuzione del codice JDE passo dopo passo per identificare errori., impostare un singolo breakpoint all'interno della NER Table IO designata e catturare ogni tentativo di lettura o scrittura diretto alla tabella di destinazione. Questa capacità di isolamento riduce il tempo medio di risoluzione dei bug di produzione da ore di tracciamento dei log a pochi minuti di debugging attivo.
Per le organizzazioni che stanno stabilizzando un ambiente JD Edwards 9.2, il consolidamento della logica di database ridondante in una singola Named Event Rule rappresenta un metodo altamente efficace per ridurre l'impronta del codice custom di un quinto o più, semplificare i percorsi di aggiornamento futuri e garantire la stabilità del sistema a lungo termine.
