

Ogni NER salvata nel Toolset finisce per diventare un file .c generato nella directory sorgente, eppure molti architetti le considerano una via di mezzo "sicura" senza considerare il costo di esecuzione sottostante. La decisione su JD Edwards NER vs BSFN e quando utilizzare ciascuna si riduce spesso a una scelta tra sviluppo rapido e velocità di esecuzione pura. In ambienti ad alto volume – si pensi a un R42565 modificato che elabora 50.000 righe all'ora – l'overhead incrementale della struttura del codice generato da NER e le sue inizializzazioni di variabili ridondanti possono gonfiare una finestra di batch di un margine misurabile, spesso intorno al 15%, rispetto a un'implementazione C ottimizzata.
Mentre le NER forniscono un'interfaccia leggibile per semplici validazioni, diventano un problema quando si gestiscono cache JDE complesse o puntatori di memoria su più di 10 segmenti. Incontro regolarmente "super-NER" di 2.000 righe che sono funzionalmente impossibili da debuggare rispetto a una BSFN C strutturata che utilizza API standard come jdeCacheFetch. Scegliere C non riguarda solo le prestazioni; si tratta di accedere ai puntatori lpBhvrCom e lpVoid che le NER non possono raggiungere, il che è essenziale per le funzioni business master personalizzate che devono mantenere lo stato attraverso eventi di applicazione o UBE disparati.
La Realtà Compilata delle Named Event Rules
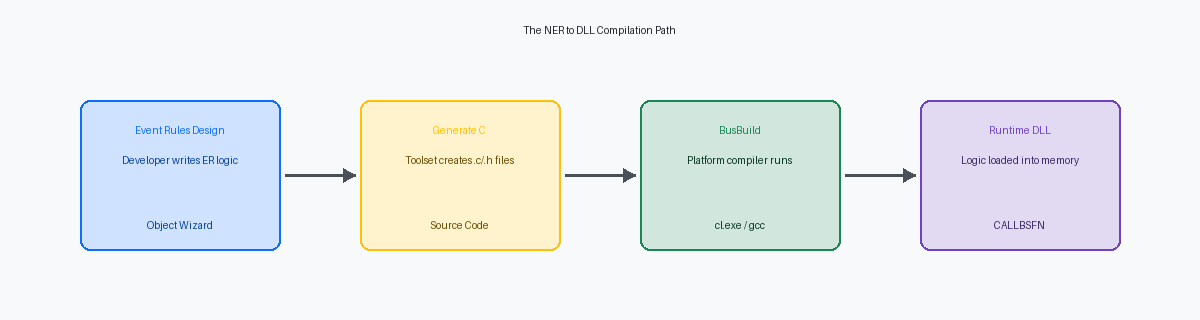
Molti sviluppatori trattano le Named Event Rules come uno strato interpretato, ma la realtà si trova nelle directory \source e \include sul server di deployment. Quando si clicca su "Genera" nel Toolset, JDE traduce le Event Rules in codice C. Questo codice sorgente Business Function generato viene poi passato al compilatore specifico della piattaforma – Visual Studio per Windows o il compilatore appropriato per Linux – per produrre la DLL o la libreria condivisa finale. L'apertura del file .c risultante per una NER di medie dimensioni rivela un output esteso dove 50 righe di logica ER spesso si trasformano in 500 righe di codice C.
Il generatore privilegia la sicurezza rispetto all'eleganza, portando a inizializzazioni di variabili ridondanti e chiamate ripetitive di pulizia degli errori prima di ogni esecuzione API. In una NER complessa con 150 variabili, l'overhead di inizializzare ogni membro della struttura lpDS e le variabili locali può aggiungere millisecondi misurabili all'esecuzione. Sebbene trascurabile per una singola chiamata, diventa un collo di bottiglia delle prestazioni quando quella NER è annidata all'interno di un ciclo in un UBE che elabora 100.000 record. Una BSFN C scritta a mano aggirerebbe questo problema inizializzando solo ciò che è necessario per il percorso logico specifico.
Le limitazioni funzionali sono intrinseche all'editor NER, confinando gli sviluppatori al sottoinsieme standard delle API JDE. Non è possibile eseguire manipolazioni dirette della memoria o chiamare DLL esterne di terze parti senza ricorrere a un wrapper C. Ogni NER è anche indissolubilmente legata alla sua Data Structure (DSTR). L'aggiunta di un singolo flag richiede la modifica della DSTR, la rigenerazione del file di intestazione e la ricompilazione dell'oggetto. Questo accoppiamento rigido rende le NER meno agili delle BSFN C, dove gli sviluppatori possono gestire tipi di dati variabili o internalizzare modifiche logiche con molta più fluidità di quanto l'editor ER consenta.
Quando le BSFN C sono Non-Negoziabili
Scrivere un algoritmo complesso di contabilità dei costi che coinvolge cicli ricorsivi o concatenazione di stringhe ad alta frequenza all'interno di una NER introduce uno strato di astrazione che degrada le prestazioni su larga scala. Sebbene una NER alla fine generi un file .c e .h, la traduzione di ogni assegnazione o ciclo da parte del motore ER aggiunge un overhead non necessario rispetto all'aritmetica diretta dei puntatori in C nativo. In un UBE ad alto volume che elabora 100.000 righe di ordini di vendita, la latenza cumulativa dell'ambiente di runtime ER può estendere il tempo di esecuzione fino al 25% rispetto a una funzione C ben ottimizzata che interagisce direttamente con le strutture dati.
Il vero controllo architetturale richiede spesso l'API JDECACHE, che è completamente inaccessibile dallo strumento di progettazione NER. L'implementazione di una cache richiede la definizione di una struttura C personalizzata per mappare le chiavi e gli attributi della cache, seguita dalla chiamata a jdeCacheInit e jdeCacheAdd utilizzando puntatori di memoria espliciti. Le NER non possono gestire la logica basata su puntatori necessaria per passare un handle tra funzioni o per iterare attraverso una cache usando un cursore. Se il tuo requisito implica l'archiviazione di dati transazionali temporanei attraverso più chiamate BSFN senza accedere al database fisico – comune in Power Forms personalizzate o nell'elaborazione EDI complessa – C è l'unica strada percorribile.
I requisiti di integrazione spesso spingono oltre i confini del toolset JDE, rendendo necessarie chiamate dirette a DLL esterne di terze parti o API a livello di sistema operativo. Che tu stia invocando una libreria crittografica specializzata di Windows per la firma del payload o un'utility basata su Linux per la manipolazione del file system, queste operazioni richiedono dichiarazioni typedef e inclusioni di header che l'ambiente NER non supporta. Tentare di colmare queste lacune tramite gli strumenti JDE standard di solito si traduce in soluzioni fragili che aumentano il debito tecnico anziché risolvere il problema di connettività sottostante.
La gestione manuale della memoria consente agli sviluppatori senior di implementare pattern di "Lazy Loading" impossibili nell'allocazione automatica della memoria di una NER. Utilizzando jdeAlloc e jdeFree in modo deliberato, uno sviluppatore può assicurarsi che le grandi strutture dati vengano istanziate solo quando assolutamente necessario e liberate immediatamente dopo l'uso. Questo controllo granulare previene il gonfiore della memoria spesso osservato nell'elaborazione batch su larga scala, dove migliaia di istanze NER potrebbero altrimenti trattenere risorse più a lungo del necessario, portando potenzialmente all'esaurimento della memoria sul server aziendale durante i cicli di fine mese di punta.

Benchmark di Prestazioni e Overhead di Esecuzione
L'elaborazione di 100.000 record tramite un caricamento batch R0911Z1 standard espone il delta di prestazioni grezzo tra NER e C. In un recente stress test su un'architettura multi-tier, una routine di validazione basata su NER ha aggiunto un aumento di latenza di circa il 17% al tempo di esecuzione totale dell'UBE rispetto a una BSFN C equivalente. Questo overhead deriva dal modo in cui il motore NER gestisce la mappatura delle variabili. Ogni volta che una NER viene chiamata, il sistema mappa la Data Structure (DSTR) alle variabili ER interne, un processo significativamente meno efficiente della manipolazione diretta dei puntatori in C.
La penalità di prestazioni implica un costo di cambio di contesto mentre il motore JDE si sposta tra il runtime ER e lo strato di esecuzione C sottostante. Quando una NER chiama un'API JDE standard, avvolge quella chiamata in strati di astrazione. Una BSFN C esegue queste API direttamente, evitando quello strato di traduzione. Per una singola chiamata, la differenza si misura in microsecondi, ma su un ciclo di 100.000 record, quei microsecondi si aggregano in minuti di cicli CPU sprecati sul Server Enterprise.
L'interazione diretta con il database offre il vantaggio di prestazioni più significativo per C. Mentre le NER si basano sul wrapper standard Table I/O, le BSFN C utilizzano direttamente JDB_OpenTable e JDB_Fetch. Ciò consente a uno sviluppatore di specificare solo le colonne richieste per l'operazione, riducendo la dimensione del buffer di recupero e minimizzando il traffico di rete. L'I/O di tabella delle NER spesso recupera l'intera riga della tabella in memoria, un'inefficienza enorme quando si ha bisogno solo di un singolo flag o campo data da una tabella ampia come F0911.
La complessità nelle NER raggiunge un limite con la logica ricorsiva o i cicli profondamente annidati. Il codice C generato da una NER è notoriamente verboso e può portare a limitazioni di profondità dello stack. Se la tua logica di business richiede la scansione di distinte base multilivello o complessi ricalcoli fiscali, la struttura del codice generato dalla NER diventa un collo di bottiglia. Spostare queste operazioni su una BSFN C consente una gestione della memoria più pulita e previene problemi di stack overflow durante l'elaborazione di fine mese.
Manutenibilità e il Gap di Competenze degli Sviluppatori
Le NER fungono da ponte, consentendo a consulenti funzionali e sviluppatori junior di diagnosticare problemi logici senza analizzare puntatori o file di intestazione. In un ambiente tipico di 10.000 oggetti, una parte significativa della logica personalizzata, spesso stimata al 60%, può essere mantenuta da personale che comprende il dizionario dati JDE ma manca di una formazione formale in C. Questa visibilità riduce l'effetto "scatola nera" comune nei sistemi legacy dove le regole di business critiche sono sepolte in migliaia di righe di codice.
L'attrito operativo tra questi formati è più visibile durante uno scenario di blocco della produzione. Il debug di una NER utilizza il Debugger ER standard, uno strumento accessibile a qualsiasi sviluppatore con un client FAT. Al contrario, la risoluzione dei problemi di una BSFN C richiede un'installazione locale di Visual Studio 2017 o 2019 e l'overhead tecnico di collegarsi al processo attivo activConsole.exe o jdenet_n.exe. Questo requisito crea spesso un collo di bottiglia, poiché molte organizzazioni limitano i diritti di amministratore locale o mancano della licenza specifica del compilatore necessaria per il debug C approfondito.
L'allocazione della memoria mal gestita nelle BSFN C è la causa principale dei "Processi Zombie" e dei crash del kernel sul Server Enterprise. Un singolo jdeFree() mancante o un puntatore inizializzato in modo improprio può causare perdite di memoria ad ogni esecuzione. In ambienti ad alto volume che elaborano 50.000 righe al giorno, queste perdite compromettono rapidamente la stabilità. Le NER mitigano questo rischio delegando la gestione della memoria al motore JDE, impedendo a uno sviluppatore junior di far crashare inavvertitamente un kernel tramite un semplice errore di sintassi.
Il costo di proprietà a lungo termine per il codice C personalizzato è più elevato perché il bacino di talenti si sta riducendo. Trovare una risorsa che comprenda le sfumature delle API JDE – come jdeCallObject e la struttura lpBhvrCom – pur mantenendo la sicurezza della memoria C sta diventando un ciclo di reclutamento di 6 mesi. I direttori IT dovrebbero verificare il loro patrimonio personalizzato e puntare a una divisione 90/10 a favore di NER o Orchestrations per evitare la dipendenza da un singolo sviluppatore senior.
Impatto su CNC e Cicli di Build dei Pacchetti
Una build completa del pacchetto server per un ambiente 9.2 tipico consuma spesso da 60 a 120 minuti di tempo CPU sul server di build. Sebbene sia le NER che le BSFN C richiedano questo ciclo di deployment per spostare la logica dal repository delle specifiche alle directory bin/lib, l'overhead CNC per le NER è silenziosamente più elevato a causa della generazione da specifica a sorgente. Se uno sviluppatore modifica una Data Structure (DSTR) legata a una NER ma non esegue manualmente il passaggio "Genera C", il busbuild fallirà nella fase di link-edit, costringendo a un riavvio del pacchetto e perdendo un tempo significativo nella finestra di manutenzione.
Le BSFN C offrono un vantaggio strategico per la manutenzione tramite lo scoping delle funzioni interne. È possibile scrivere una dozzina di subroutine interne all'interno di un singolo file .c che non sono definite nella DSTR. Ciò consente di correggere un bug o ottimizzare un calcolo senza alterare l'interfaccia pubblica dell'oggetto. Poiché la DSTR rimane invariata, si evita la catena di dipendenza in cui ogni UBE o APPL chiamante richiederebbe altrimenti un nuovo controllo o l'inclusione nel pacchetto di aggiornamento per prevenire errori di mancata corrispondenza della versione durante l'esecuzione a runtime.
La transizione all'architettura a 64 bit in Tools Release 9.2.5 ha ridotto il divario nella velocità di compilazione ma ha aumentato il rischio per il codice C manuale. Le NER gestiscono la logica sottostante della dimensione del puntatore tramite il generatore fornito da Oracle, proteggendo gli sviluppatori da problemi di allineamento della memoria. Al contrario, le BSFN C richiedono l'uso esplicito di tipi di dati specifici di JDE per rimanere portabili attraverso il kernel aziendale. Un singolo puntatore mal castato in una funzione C personalizzata si manifesterà come una violazione della memoria nei log del Server Enterprise, spesso apparendo solo dopo che il pacchetto è stato distribuito e il kernel tenta di caricare la DLL.
L'Approccio Ibrido per JDE Moderno
Un'architettura matura utilizza una NER come wrapper di interfaccia pulito che chiama funzioni worker C ottimizzate per il lavoro pesante. Ciò consente alla logica di business di rimanere visibile nel toolset JDE, mentre le operazioni matematiche complesse o la manipolazione di stringhe ad alta intensità di memoria vengono delegate a C. Questo approccio può ridurre il tempo di debug in modo sostanziale, spesso raggiungendo il 40%, perché gli sviluppatori possono tracciare il flusso di alto livello nella NER senza dover esaminare 2.000 righe di codice C ricco di puntatori.
Orchestrator sta cannibalizzando il caso d'uso per le NER semplici, in particolare per le validazioni interfunzionali e le ricerche di base nelle tabelle. In un recente rollout 9.2.7, abbiamo sostituito 15 NER personalizzate utilizzate per la validazione dei dati con Orchestrations, spostando efficacemente quella logica fuori dallo strato applicativo principale. Questo cambiamento consente modifiche in tempo reale senza un deployment completo del pacchetto. In definitiva, la scelta tra NER e BSFN C è un equilibrio tra agilità di sviluppo ed efficienza di runtime; mentre le NER rimangono lo standard per la visibilità, le BSFN C sono richieste per il controllo architetturale di basso livello e ad alte prestazioni.
