

Dalla lista grezza alla stima: come rendere difendibile un upgrade JD Edwards
Un upgrade JD Edwards non dovrebbe iniziare con una stima. Dovrebbe iniziare con una domanda molto più scomoda: qual è davvero il perimetro da stimare? In teoria, la risposta sembra semplice. Si estraggono gli oggetti custom, si confrontano con lo standard, si guarda che cosa è stato modificato e si calcola il lavoro necessario per portarli dalla release di partenza alla release di arrivo. In pratica, questa sequenza lineare esiste raramente. Gli ambienti reali contengono anni di interventi, copie di standard, report mai più eseguiti, oggetti tecnici, versioni modificate, oggetti creati per emergenze ormai dimenticate, componenti consegnati da terze parti, personalizzazioni ancora critiche e personalizzazioni che nessuno usa più. Per questo motivo la stima non può essere il primo passaggio: deve essere la conseguenza di un processo di qualificazione.
Il punto centrale è trasformare una lista grezzaElenco iniziale, ampio e volutamente prudente, di oggetti potenzialmente rilevanti per l’upgrade. in una Suggested Object ListLista ragionata degli oggetti che, dopo filtri e verifiche, meritano di entrare nel perimetro di analisi o stima.. Questa trasformazione non è un esercizio di riduzione numerica. Non si parte da migliaia di oggetti con l’obiettivo di arrivare a poche centinaia perché “meno è meglio”. Si parte da una fotografia ampia perché, in un assessment serio, è più pericoloso perdere un oggetto importante che analizzarne uno in più. La scrematura serve quindi a qualificare il perimetro: ogni oggetto deve essere escluso, mantenuto, classificato o reincluso per una ragione tecnica documentabile.
Questa distinzione cambia completamente il modo di leggere il processo. Una lista iniziale non è ancora una lista di lavoro. È una raccolta di candidati. Alcuni candidati saranno confermati, altri saranno riclassificati, altri ancora potranno essere portati fuori dal perimetro operativo dell’upgrade. Ma nessuna decisione dovrebbe essere invisibile. Un oggetto non sparisce perché qualcuno vuole abbassare il numero finale. Esce dal perimetro solo se c’è un criterio verificabile: per esempio perché risulta standard, perché appartiene a una categoria che non richiede retrofit applicativo, perché non è più usato, perché è gestito con un trattamento separato, oppure perché il cliente decide consapevolmente di non includerlo.
Perché la lista iniziale deve essere ampia
Il primo errore da evitare è cercare una lista “pulita” troppo presto. In un ambiente JD Edwards maturo, ciò che appare semplice può nascondere dipendenze complesse. Un report può sembrare custom ma essere quasi identico allo standard. Una copia può sembrare innocua ma derivare da uno standard che Oracle ha modificato nella release target. Una versione batch può sembrare secondaria ma essere usata in chiusura mese. Un oggetto tecnico può sembrare fuori perimetro, ma essere necessario per far funzionare una catena di processi. Per questo la fase iniziale deve accettare una certa ridondanza informativa: meglio partire larghi e poi qualificare, piuttosto che iniziare stretti e scoprire troppo tardi di aver perso elementi rilevanti.
Gli estrattiFile prodotti dall’ambiente cliente che descrivono oggetti, versioni, metadati, uso, differenze e altri elementi utili all’assessment. ricevuti dal cliente servono proprio a costruire questa fotografia iniziale. Non sono un semplice allegato amministrativo: sono la materia prima dell’intero processo. Devono essere ricevuti, conservati, organizzati e trasformati in dati lavorabili senza perdere il legame con la sorgente originaria. Questa separazione tra dati ricevuti, dati elaborati e risultati finali è fondamentale per mantenere tracciabilità. Se un numero viene contestato, se un oggetto viene reincluso, se una stima viene rivista, deve essere possibile risalire alla ragione e alla fonte.
La lista grezza, quindi, non è un errore da correggere. È una fase necessaria. Contiene rumore, ma contiene anche segnali importanti. Il lavoro dell’assessment consiste nel distinguere i due. Il valore non sta nel produrre subito un elenco apparentemente elegante, ma nel costruire un percorso che renda chiaro perché alcuni elementi vengono mantenuti e altri no.
La scrematura non è un taglio: è una classificazione
La parola “scrematura” può essere fuorviante. Può dare l’idea di un taglio meccanico, quasi contabile: si prende una lista, si eliminano righe, si ottiene un numero più piccolo. In un upgrade JD Edwards fatto seriamente, la scrematura è invece una classificazione progressiva. Ogni oggetto viene letto dentro una categoria tecnica. È un oggetto standard? È un custom puro? È una modifica diretta a uno standard? È una copia di uno standard? È una versione? È un report batch? È un oggetto non più eseguito? È un componente tecnico che non deve essere stimato come sviluppo applicativo? È un’anomalia da portare all’attenzione del cliente?
Questa classificazione è ciò che rende l’assessment difendibile. Non basta dire che un oggetto è stato escluso. Bisogna poter dire perché. Non basta dire che un oggetto è stato mantenuto. Bisogna poter spiegare quale rischio rappresenta. Non basta dire che una copia è stata individuata. Bisogna capire da quale standard deriva, se quello standard è cambiato, quanto la copia si è allontanata dal riferimento e quale lavoro sarà necessario per portarla sulla nuova release.
In questo senso la scrematura è più vicina a una revisione editoriale che a una pulizia automatica. Una revisione editoriale non cancella frasi a caso: distingue ciò che è necessario, ciò che è ridondante, ciò che è ambiguo e ciò che richiede riscrittura. Allo stesso modo, la scrematura tecnica distingue gli oggetti che richiedono retrofit, quelli che richiedono verifica, quelli che richiedono una decisione, quelli che non devono pesare sulla stima e quelli che non possono essere ignorati.
Oggetti standard, modifiche e custom puro
Una delle prime distinzioni riguarda la natura dell’oggetto. Un oggetto standard puro non va trattato come un oggetto custom. Se non contiene una personalizzazione cliente, non dovrebbe pesare come attività di retrofit custom. Questo non significa che lo standard sia irrilevante: lo standard è il riferimento rispetto al quale si misura l’impatto dell’upgrade. Ma la stima del lavoro custom deve concentrarsi su ciò che il cliente ha effettivamente cambiato, copiato, esteso o creato.
Diverso è il caso delle modifiche dirette a oggetti standard. Qui il problema è immediato: se lo standard Oracle cambia nella release target, la personalizzazione cliente deve essere reinterpretata nel nuovo contesto. Non si tratta solo di spostare codice o configurazioni da un ambiente all’altro. Si tratta di capire se la modifica cliente è ancora valida, se entra in conflitto con il nuovo standard, se può essere eliminata perché assorbita dalla release target, oppure se deve essere riscritta per convivere con il nuovo comportamento.
Il custom puroOggetto creato dal cliente o per il cliente, non necessariamente derivato da un oggetto standard Oracle. pone un altro tipo di problema. Se è davvero indipendente dallo standard, può non richiedere un confronto diretto con un oggetto Oracle di partenza. Ma questo non lo rende automaticamente semplice. Può dipendere da tabelle, funzioni, business views, data structures, processing options o logiche che cambiano tra release. Può compilare senza errori ma produrre risultati diversi. Può essere tecnicamente valido ma funzionalmente obsoleto. Per questo anche il custom puro va qualificato, non solo contato.
Il caso più delicato: le copie degli standard
Le copie degli standard sono spesso tra gli oggetti più critici in un upgrade JD Edwards. Una copia non è un duplicato e non è un oggetto da scartare: è un oggetto custom che conserva una relazione tecnica con un oggetto standard Oracle, il cosiddetto based-onL’oggetto standard Oracle da cui una copia custom deriva o rispetto al quale deve essere confrontata.. Questa relazione è il cuore del problema. Se una copia deriva da uno standard, il suo destino non dipende soltanto da ciò che il cliente ha fatto sulla copia, ma anche da ciò che Oracle ha fatto sullo standard nella nuova release.
Quando Oracle modifica l’oggetto standard nella release target, la copia non può essere trattata come se vivesse in isolamento. Se la copia cliente è sostanzialmente identica allo standard di partenza, il lavoro può essere relativamente semplice: può essere necessario ricrearla o riallinearla a partire dal nuovo standard. Ma anche in questo caso non viene scartata. Viene classificata come copia a basso scostamento, cioè come un oggetto che potrebbe essere semplice da gestire ma che deve comunque seguire il percorso corretto.
Il vero problema emerge quando entrambe le linee evolutive si sono mosse. Da un lato Oracle ha modificato il based-on nella release target; dall’altro il cliente ha modificato la copia nel proprio ambiente. A quel punto l’upgrade diventa un esercizio di riconciliazione tra due storie diverse dello stesso oggetto. Bisogna capire quali modifiche Oracle siano importanti, quali personalizzazioni cliente vadano preservate, quali parti siano obsolete, quali parti entrino in conflitto e quale sia il modo più sicuro per ricostruire l’oggetto finale. È qui che una copia può diventare molto più difficile di un custom puro.
Questa è la ragione per cui le copie degli standard non dovrebbero mai essere trattate come duplicati. Una copia non è una riga da eliminare per alleggerire la lista. È una categoria di analisi. In alcuni casi sarà semplice, in altri sarà complessa, in altri ancora richiederà un confronto molto dettagliato. Ma il criterio non è mai “è una copia, quindi si scarta”. Il criterio corretto è: è una copia, quindi bisogna identificare il based-on, misurare lo scostamento, verificare il cambiamento dello standard e stimare il lavoro di ricomposizione.
Questo tema merita un approfondimento autonomo, perché coinvolge tecniche di confronto, similarità, struttura, nomenclatura e conoscenza funzionale. Per una spiegazione specifica del riconoscimento delle copie standard in JD Edwards, si può fare riferimento all’articolo Copies of JD Edwards Standards: how I identify them.
Last Run Date: quando l’uso reale entra nell’assessment
Un altro criterio cruciale è la Last Run DateData dell’ultima esecuzione conosciuta di un report o di una versione batch. È usata come indicatore di utilizzo reale, non come verità assoluta., spesso abbreviata in LRD. Questo dato introduce una dimensione che il solo confronto tecnico non può dare: l’uso reale. Un oggetto può essere custom, può essere tecnicamente valido, può avere una storia importante, ma se non viene eseguito da molto tempo è ragionevole chiedersi se debba ancora entrare nel perimetro operativo dell’upgrade.
Nel caso dei report batch e delle versioni, la Last Run Date è un indicatore particolarmente utile. In termini JD Edwards, il dato di ultima esecuzione della versione batch è normalmente associato alla Versions List, cioè alla tabella F983051Tabella JD Edwards delle versioni. Il campo VRVED è comunemente usato come Date - Last Executed per le versioni batch., in particolare al campo VRVEDCampo indicato come Date - Last Executed; rappresenta la data di ultima esecuzione della versione.. Anche la storia dei job sottomessi può offrire informazioni utili, per esempio attraverso la logica dei submitted jobs e della tabella F986110Job Control Status Master: tabella che mantiene record sullo stato dei job sottomessi alle code.. Tuttavia, questi dati vanno letti con prudenza: la cronologia può essere soggetta a pulizie, retention, configurazioni e comportamenti diversi tra ambienti.
Nel processo di assessment, una soglia pratica può essere quella dei 18 mesi. Se un report non risulta eseguito da oltre 18 mesi, può diventare candidato all’esclusione dal perimetro operativo dell’upgrade. La parola importante è “candidato”. Non significa che il report venga cancellato, ignorato o dichiarato inutile in automatico. Significa che il dato di utilizzo apre una domanda: questo report serve ancora? È stato sostituito? Viene eseguito manualmente in modo raro ma critico? È usato solo in chiusura anno? È lanciato da un altro processo che non aggiorna correttamente la data attesa? È un oggetto di emergenza che il business vuole conservare?
Questa cautela è essenziale. Un criterio basato su LRD non deve diventare una ghigliottina. Deve diventare una conversazione tecnica e funzionale. Se un report non gira da due anni e nessuno sa più a cosa serva, è ragionevole non farlo pesare come oggetto pienamente operativo. Se invece non gira da due anni perché viene usato solo in scenari eccezionali ma regolatoriamente importanti, allora il discorso cambia. La Last Run Date non prende la decisione al posto dell’analista: rende visibile una domanda che altrimenti resterebbe nascosta.
La soglia dei 18 mesi non è una verità matematica
La soglia dei 18 mesi è utile perché obbliga a distinguere tra oggetti ancora vivi e oggetti probabilmente dormienti. Ma non va presentata come una verità matematica. In alcuni contesti, un report non eseguito da 18 mesi può essere irrilevante. In altri, può essere raro ma indispensabile. Un processo annuale, un adempimento fiscale, un controllo di audit o una funzione di emergenza possono avere frequenza bassa e importanza alta. Per questo il criterio temporale deve essere combinato con la conoscenza del business.
Il modo corretto di usare la LRD è inserirla in una matrice decisionale. Un report recente e custom entra con forza nel perimetro. Un report vecchio, non eseguito e non riconosciuto dal business può essere candidato all’esclusione. Un report vecchio ma confermato dal cliente resta. Un report senza Last Run Date affidabile richiede ulteriore verifica. In tutti i casi, la decisione deve restare tracciabile.
Questo è un punto importante anche dal punto di vista della relazione con il cliente. Dire “questo report non lo stimiamo perché non gira da 18 mesi” è troppo debole. Dire “questo report è candidato all’esclusione perché la Last Run Date indica assenza di utilizzo recente; chiediamo conferma funzionale prima di rimuoverlo dal perimetro operativo” è molto più solido. Nel primo caso si impone un taglio. Nel secondo si costruisce una decisione condivisa.
Oggetti tecnici, amministrativi e anomalie
Non tutti gli oggetti che compaiono nella lista iniziale devono essere trattati come sviluppo applicativo da retrofittare. Alcuni appartengono a categorie tecniche o amministrative che richiedono un trattamento diverso. Possono esserci elementi legati a configurazioni, versioni, metadati, strutture di supporto o componenti che non rappresentano una modifica applicativa nel senso tradizionale. Inserirli senza distinzione nella stima rischia di gonfiare il perimetro e di confondere il lavoro realmente necessario.
Questo non significa che tali oggetti siano irrilevanti. Significa che vanno separati. Un oggetto tecnico può non richiedere retrofit, ma può richiedere controllo. Una versione può non essere un programma, ma può contenere processing options, data selection o impostazioni operative rilevanti. Un’anomalia può non trasformarsi subito in ore di sviluppo, ma può indicare un rischio da chiarire prima di procedere. La qualità dell’assessment sta proprio nella capacità di distinguere il lavoro di sviluppo dal lavoro di verifica, configurazione, decisione o pulizia.
Le anomalie meritano un discorso a parte. In un processo maturo non vanno nascoste. Un oggetto senza corrispondenza chiara, una copia con based-on incerto, una versione associata a un report poco chiaro, un record incoerente, un nome ambiguo o un’informazione mancante non dovrebbero essere forzati dentro una categoria solo per chiudere la lista. Devono essere portati in evidenza. A volte l’anomalia si risolve con un controllo tecnico. A volte richiede il coinvolgimento del cliente. A volte diventa una nota nella stima. In ogni caso, è meglio una lista con warning espliciti che una lista apparentemente pulita ma costruita su decisioni non documentate.
Reinclusioni manuali: quando il giudizio tecnico prevale sul filtro
Un buon processo di scrematura non deve essere cieco. I filtri sono necessari, ma non devono sostituire il giudizio tecnico. Esistono casi in cui un oggetto potrebbe sembrare da escludere secondo un criterio automatico, ma deve essere reincluso perché l’analista riconosce un rischio, una dipendenza o una particolarità. Questo è particolarmente vero nei sistemi JD Edwards con molti anni di storia, dove convenzioni locali, naming non standard e soluzioni di progetto possono rendere imperfetta qualunque regola automatica.
La reinclusione manuale non è un fallimento del metodo. È una sua componente necessaria. Un assessment totalmente automatico può essere veloce, ma rischia di essere fragile. Un assessment tecnico serio combina regole, dati e giudizio. Il punto non è eliminare l’intervento umano; è renderlo tracciabile. Se un oggetto viene reincluso, deve essere chiaro perché. Se viene escluso nonostante un warning, deve essere chiaro chi ha preso la decisione e su quale base.
Questo equilibrio tra automazione e responsabilità è una delle differenze tra una lista prodotta da un tool e un vero processo di upgrade assessment. Il tool può accelerare, confrontare, evidenziare, aggregare, misurare. Ma il valore finale nasce quando i risultati vengono interpretati dentro il contesto del cliente e della release target.
Cosa mostrano i dati storici
Per dare concretezza al metodo, è utile osservare un campione storico anonimo composto da 54 run di assessment. Il campione contiene 358,046 oggetti nella lista grezza iniziale. Dopo la fase di qualificazione, la Suggested Object ListLista degli oggetti che restano nel perimetro tecnico suggerito dopo esclusioni, verifiche e classificazioni. contiene 145,773 oggetti, mentre 212,269 oggetti risultano esclusi o portati fuori dal perimetro operativo dell’upgrade.
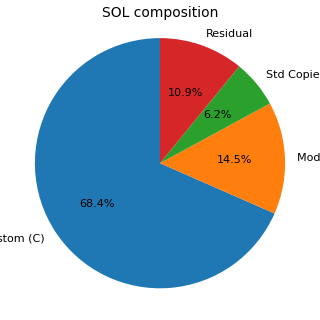
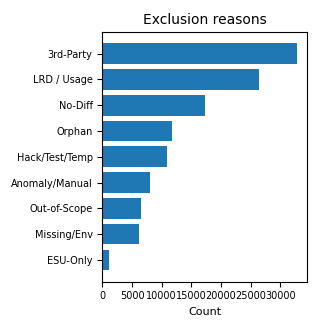
Nel primo grafico, la voce Residual indica la parte della Suggested Object List non coperta dalle tre categorie C, M e Y riportate nel riepilogo aggregato. Nel secondo grafico, i motivi di esclusione sono mostrati con un grafico a barre perché le categorie non sono esclusive e quindi non sarebbero rappresentabili correttamente come quote di una singola torta.
| Indicatore | Valore aggregato | Lettura del dato |
|---|---|---|
| Run analizzate | 54 | Assessment con dettaglio disponibile e collegabile al riepilogo. |
| Oggetti nella lista grezza | 358,046 | Perimetro iniziale volutamente ampio. |
| Oggetti nella Suggested Object List | 145,773 (40.7%) | Oggetti rimasti nel perimetro tecnico suggerito. |
| Oggetti esclusi | 212,269 (59.3%) | Oggetti rimossi dal perimetro operativo dopo l’applicazione dei criteri di scrematura. |
| Custom puri nella SOL | 99,733 | Oggetti classificati come custom. |
| Standard modificati nella SOL | 21,145 | Oggetti standard modificati dal cliente e mantenuti nel perimetro. |
| Copie di standard nella SOL | 8,989 (6.2% della SOL) | Oggetti di tipo copia standard, da trattare come categoria critica e non come duplicati. |
| Oggetti esclusi prima della classificazione | 212,188 | Oggetti usciti dal perimetro prima che fosse necessario stabilire il tipo di modifica. |
| Standard modificati esclusi come no-diff | 17,036 | Oggetti inizialmente classificati come modificati, ma poi risultati allineati allo standard. |
| UBE/UBEVER nella lista grezza | 69,567 | Report e versioni batch presenti nel perimetro iniziale. |
| UBE/UBEVER nella SOL | 30,337 | Report e versioni batch mantenuti nel perimetro suggerito. |
| UBE/UBEVER esclusi | 39,229 (56.4% degli UBE/UBEVER raw) | Report e versioni batch esclusi o candidati all’esclusione dopo la qualificazione. |
| Esclusioni LRD / uso non recente | 26,328 | Oggetti esclusi con motivazione collegata a Last Run Date o mancato utilizzo recente. |
| Esclusioni no-diff | 17,297 | Oggetti esclusi perché senza differenze rilevanti rispetto allo standard. |
| Esclusioni terze parti | 32,896 | Oggetti riconducibili a componenti non appartenenti al perimetro custom del cliente. |
| Hack, test o temporanei | 10,852 | Oggetti esclusi perché legati a test, workaround temporanei o elementi non strutturali. |
| Orfani | 11,676 | Oggetti identificati come non più collegati a un uso operativo chiaro. |
| ESU-only | 1,162 | Oggetti esclusi perché riconducibili a logiche di aggiornamento standard già coperte dal percorso di release. |
| Missing / environment | 6,098 | Oggetti la cui esclusione dipende da condizioni dell’ambiente o da dati non presenti. |
| Fuori perimetro progetto | 6,482 | Oggetti non pertinenti al perimetro operativo dell’assessment. |
| Anomalie / revisione manuale | 8,079 | Casi che richiedono attenzione, conferma o giudizio tecnico. |
| Esclusi senza motivo esplicito | 89,300 | Controllo qualità del dato: righe escluse prive di una motivazione leggibile nel campo commenti. |
Nota metodologica. Le categorie di esclusione sono flag non mutuamente esclusivi: uno stesso oggetto può avere più motivazioni documentate, per esempio essere un oggetto di test, di terze parti e con indicazione LRD. Per questo motivo le righe relative ai motivi di esclusione non devono essere sommate tra loro. Il dato aggregato mostra il peso dei criteri, non una ripartizione esclusiva.
Questi numeri rendono visibile il valore della scrematura. Nel campione storico, circa 59.3% degli oggetti iniziali non arriva alla Suggested Object List. Il dato non va letto come una semplice “riduzione”: va letto come il risultato di una classificazione tecnica. La lista grezza cattura tutto ciò che potrebbe essere rilevante; la lista suggerita conserva ciò che merita di essere discusso, analizzato o stimato. Tra questi oggetti restano quasi 8,989 copie di standard, che confermano un punto essenziale: le copie non vengono trattate come scarti, ma come una categoria critica del retrofit.
Il dato sugli UBE e sulle versioni batch è altrettanto significativo. Da 69,567 report o versioni presenti nel perimetro iniziale, 30,337 restano nella lista suggerita e 39,229 escono dal perimetro operativo. Una parte rilevante di queste esclusioni è collegata a LRD o a criteri di uso non recente. Anche qui il numero non sostituisce il giudizio: un report raro può essere critico, ma un report non eseguito da anni deve almeno essere messo in discussione prima di pesare sulla stima.
Infine, il dato sugli oggetti no-diff mostra perché non basta fidarsi della classificazione iniziale. Nel campione esistono 17,036 oggetti inizialmente riconducibili alla categoria degli standard modificati ma poi esclusi perché non mostrano differenze rilevanti. Questo è uno dei passaggi che impedisce alla stima di gonfiarsi artificialmente: un oggetto che sembra modificato non deve pesare come retrofit se il confronto dimostra che, in realtà, è allineato allo standard.
Dalla Suggested Object List alla stima
Solo dopo la fase di qualificazione ha senso stimare. La Suggested Object List non è il punto finale: è il punto in cui la stima può iniziare in modo serio. A quel punto gli oggetti non sono più semplici nomi. Sono elementi classificati: custom puro, modifica a standard, copia di standard, report batch con uso recente, report batch candidato a esclusione, versione con override, oggetto tecnico, anomalia, componente da verificare, elemento da discutere con il cliente.
La stima deve partire da questa classificazione. Un custom puro, una modifica diretta a standard e una copia di standard non hanno lo stesso profilo di rischio. Una copia quasi identica al based-on e una copia fortemente divergente non richiedono lo stesso effort. Un report usato ieri e un report non eseguito da anni non hanno lo stesso peso operativo. Un oggetto con anomalie non può essere stimato come se fosse completamente chiaro. La stima non deve essere una media generica applicata a una lista: deve essere una valutazione derivata dalla natura dell’oggetto.
In questa seconda fase, ogni oggetto viene tradotto in lavoro potenziale. Non si chiede più soltanto “che cos’è?”, ma “che cosa bisogna fare per portarlo correttamente sulla release target?”. La risposta può includere ricompilazione, confronto, retrofit, ricostruzione da nuovo standard, verifica funzionale, test, adeguamento di processing options, controllo di data selection, analisi delle dipendenze o semplice conferma di esclusione. La stima diventa così il risultato di una catena: dati iniziali, filtri, classificazione, decisioni, effort.
Perché una stima senza scrematura è pericolosa
Stimare direttamente la lista grezza è pericoloso per due ragioni opposte. La prima è sovrastimare. Se dentro la lista restano oggetti standard, oggetti non usati, elementi tecnici non applicativi o report dormienti, il cliente riceve una stima appesantita da lavoro che potrebbe non essere necessario. Questo può rendere il progetto più costoso, più difficile da approvare e meno trasparente.
La seconda ragione è sottostimare. Se le copie degli standard vengono lette come semplici duplicati, se le modifiche dirette allo standard vengono trattate come custom ordinario, se le anomalie vengono ignorate, la stima può sembrare più leggera ma diventare fragile. Il rischio emerge più tardi, quando il progetto è già avviato e gli oggetti più complessi iniziano a richiedere tempo non previsto.
La scrematura serve a evitare entrambi gli errori. Non è un meccanismo per abbassare la stima. È un meccanismo per renderla proporzionata. Toglie peso dove il lavoro non c’è, ma aggiunge attenzione dove il rischio è reale. Questo è il punto più importante da comunicare al cliente: la riduzione del perimetro non è una scorciatoia, è una forma di precisione.
La tracciabilità come valore del metodo
Un assessment di upgrade non produce solo numeri. Produce decisioni. Ogni esclusione, inclusione, reinclusione o classificazione è una decisione. Se queste decisioni non sono tracciate, la stima finale diventa difficile da difendere. Se invece sono documentate, il cliente può capire non solo quanto lavoro è previsto, ma anche perché.
La tracciabilità è importante anche per il team di progetto. Quando l’upgrade entra nella fase esecutiva, le persone che lavorano sugli oggetti devono sapere da dove arriva la classificazione. Devono capire se un oggetto è stato considerato copia, se il based-on è certo o probabile, se la Last Run Date ha inciso sulla decisione, se un report è stato escluso su conferma del cliente, se un warning è rimasto aperto. Senza questa memoria, l’assessment rischia di diventare un documento statico. Con questa memoria, diventa uno strumento operativo.
La tracciabilità serve anche a gestire le revisioni. Una stima può cambiare. Un cliente può reincludere un report. Un oggetto inizialmente considerato semplice può rivelarsi complesso. Una copia può mostrare uno scostamento maggiore del previsto. Se il processo è tracciato, la revisione è comprensibile. Se non lo è, ogni cambiamento sembra arbitrario.
Il ruolo del cliente nella validazione del perimetro
Il cliente non dovrebbe ricevere la Suggested Object List come una sentenza. Dovrebbe riceverla come un perimetro tecnico da validare. Il team tecnico può dire che un report non risulta eseguito da oltre 18 mesi, ma solo il cliente può confermare se quel report sia davvero abbandonato. Il team tecnico può identificare una copia e misurarne lo scostamento, ma spesso serve conoscenza funzionale per capire quali modifiche siano ancora rilevanti. Il team tecnico può segnalare un’anomalia, ma il cliente può sapere che quell’anomalia corrisponde a una vecchia procedura, a un workaround o a una personalizzazione critica.
La qualità dell’upgrade dipende quindi anche dal modo in cui il perimetro viene discusso. Un assessment non dovrebbe produrre una lista chiusa in isolamento. Dovrebbe produrre una lista motivata, accompagnata da criteri, note, warning e domande. In questo modo il cliente non è costretto a fidarsi di un numero: può vedere il percorso che ha prodotto quel numero.
Questo è particolarmente importante nei progetti in cui la pressione economica è forte. Una lista troppo grande spaventa. Una lista troppo piccola crea rischio. Una lista difendibile permette una discussione razionale: quali oggetti sono certamente nel perimetro, quali sono candidati all’esclusione, quali richiedono conferma, quali sono tecnicamente critici, quali sono funzionalmente sensibili.
Dal dato tecnico alla decisione di progetto
Il valore finale della procedura non è solo tecnico. È decisionale. Un upgrade JD Edwards è un progetto in cui il rischio nasce spesso dall’incertezza: non sapere quanti oggetti siano davvero coinvolti, non sapere quali copie siano critiche, non sapere quali report siano ancora usati, non sapere se una stima includa oggetti inutili o ne escluda di importanti. La procedura riduce questa incertezza trasformando informazioni disperse in decisioni visibili.
Questo non significa eliminare ogni margine di dubbio. In un sistema complesso, il dubbio non scompare. Viene gestito. Alcuni oggetti resteranno con note. Alcune decisioni richiederanno conferma. Alcune stime avranno margini. Alcune copie richiederanno analisi più profonde. Ma un margine dichiarato è molto diverso da un margine nascosto. Il primo può essere discusso. Il secondo esplode durante il progetto.
In questo senso, la procedura di upgrade assessment non è semplicemente un modo per produrre una stima. È un modo per costruire fiducia. Fiducia nel fatto che il perimetro non sia arbitrario. Fiducia nel fatto che gli oggetti critici non siano stati semplificati. Fiducia nel fatto che i report non usati siano stati trattati con criterio. Fiducia nel fatto che le copie degli standard siano state capite per ciò che sono: spesso il punto più delicato del retrofit.
Conclusione: l’upgrade come riduzione dell’incertezza
Un upgrade JD Edwards non è soltanto un passaggio tecnico da una release a un’altra. È un esercizio di riduzione dell’incertezza. All’inizio c’è una massa di oggetti potenzialmente rilevanti. Alla fine ci deve essere un perimetro spiegabile, una lista suggerita, una stima proporzionata e una serie di decisioni tracciabili. Il lavoro più importante avviene proprio nel mezzo, nella fase in cui la lista grezza viene trasformata in conoscenza.
La scrematura è il cuore di questo processo, ma solo se viene capita correttamente. Non serve a eliminare righe. Serve a distinguere. Gli oggetti standard non vanno confusi con il custom. I report non usati da oltre 18 mesi possono essere candidati all’esclusione, ma non cancellati senza giudizio. Le anomalie vanno portate in evidenza, non nascoste. Le reinclusioni manuali sono parte del metodo, non eccezioni imbarazzanti. E le copie degli standard non sono duplicati: sono spesso gli oggetti più delicati, perché obbligano a confrontare l’evoluzione del cliente con l’evoluzione dello standard Oracle.
Solo quando questo lavoro è stato fatto, la stima diventa credibile. Non perché sia perfetta, ma perché è spiegabile. E in un upgrade complesso, una stima spiegabile vale molto più di una stima apparentemente precisa ma priva di memoria tecnica.
