
"Data Dictionary Item Not Found" è l'errore che manda fuori strada più velocemente una giornata JD Edwards. Gli utenti vedono un Visual Assist rotto, un campo numerico renderizzato come testo, oppure un Find-Browse che non restituisce nulla dove ieri restituiva righe — e il primo riflesso in metà dei ticket di supporto che ho visto è dare la colpa all'applicazione, quando il problema reale è quasi sempre uno strato più sotto: una voce del Data DictionaryIl livello di metadati JDE che definisce ogni data item (alias, lunghezza, decimali, glossario, edit rules). Governa il modo in cui ogni form, BSFN e UBE interpreta le colonne sottostanti. che non corrisponde più a ciò che uno dei quattro livelli di cache sopra di essa ricorda.
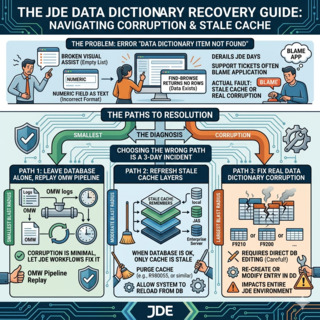
Questa guida è la procedura che uso per correggere gli errori del Data Dictionary JD Edwards quando la corruzione è reale, quando è solo cache obsoleta e quando il percorso più sicuro è lasciare stare il database e lasciare che la pipeline OMWObject Management Workbench: la console JDE che traccia check-out, check-in, promozione e cronologia di audit per ogni modifica agli oggetti, inclusi i Data Dictionary item. riproduca la modifica. I tre percorsi hanno impatti molto diversi, e la scelta sbagliata trasforma una correzione da 10 minuti in un incidente da 3 giorni.
Perché la gerarchia della cache è quasi sempre la vera responsabile
Prima di toccare una sola riga in F9200 o F9210, interiorizza questo: JDE cerca un data item attraverso quattro o cinque livelli di cache in sequenza, e ognuno di essi può contenere una copia obsoleta della definizione mentre tutti gli altri livelli sono corretti. L'errore che l'utente vede è identico, sia che la corruzione sia nel database sia che sia solo in una cache da svuotare.

Il fat client, dove esiste ancora, memorizza le voci DD localmente nei file spec della workstation. L'HTML ServerIl web server basato su Java che eroga l'interfaccia web JDE EnterpriseOne. Mantiene cache in memoria per utente e per ambiente dei metadati usati di frequente, inclusi i Data Dictionary item. mantiene una cache JVM in memoria, aggiornata in modo lazy. L'Enterprise ServerIl backend basato su C che esegue Call Object kernel, UBE kernel e altri processi server. La sua cache DD è mantenuta nella memoria di processo di ogni kernel ed è indipendente dalla cache dell'HTML Server. mantiene la propria cache dentro ogni Call Object kernel — e sì, ogni kernel ha la propria copia, ed è per questo che due utenti che eseguono la stessa form possono vedere comportamenti diversi. Sotto ci sono le tabelle spec per path code, e sotto ancora le tabelle master centrali F9200 (Data Item Master), F9202 (alpha description), F9203 (traduzioni) e F9210 (Data Item Specifications).
La regola pratica: in circa il 70-80% dei ticket di "corruzione data dictionary" su cui ho lavorato, nulla era corrotto. Una modifica DD era stata promossa, ma uno dei livelli di cache superiori non era stato aggiornato, e l'applicazione stava semplicemente leggendo una vecchia definizione. Svuotare le cache nell'ordine corretto risolve il problema in meno di 10 minuti e non tocca il database.
Il restante 20-30% è corruzione reale: una riga mancante da F9210 che esiste in F9200, una traduzione obsoleta in F9203 per un codice lingua non più attivo, oppure una collisione di chiave primaria dopo un restore fallito. Questi casi richiedono correzioni chirurgiche, ed è lì che le prossime sezioni diventano importanti.
I tre percorsi di riparazione e quando scegliere ciascuno
Una volta confermato che il problema è riproducibile tra utenti e ambienti — cioè che non è solo una cache obsoleta isolata — hai tre opzioni. La tentazione è sempre saltare direttamente a SQL, e questa è quasi sempre la scelta sbagliata.

Cache clear tramite Server Manager è sempre la prima cosa da provare. Apri Server Manager, scegli l'istanza HTML Server di destinazione, vai in Runtime Metrics e svuota la cache del Data Dictionary. Poi fai lo stesso su ogni logic kernel dell'Enterprise Server che serve gli utenti interessati. L'intera operazione richiede 5-10 minuti e modifica zero righe nel database. Se il sintomo scompare, la corruzione non è mai stata reale — era un disallineamento di cache — e hai finito.
P92001 (Data Dictionary Design) è l'applicazione JDE standard per gestire gli item DD. Se lo svuotamento della cache non ha aiutato, apri P92001 sull'alias incriminato, verifica che la definizione corrisponda a ciò che l'applicazione si aspetta e, se necessario, salva di nuovo l'item. P92001 scrive su F9200/F9210, propaga alle tabelle spec, e la modifica diventa parte dell'audit trail OMW. Questo è l'unico percorso di riparazione che sopravvive pulito a un upgrade o a un retrofit ESU, perché lascia una registrazione tracciata di chi ha cambiato cosa e quando.
Direct SQL su F9200/F9210/F9202/F9203 è l'ultima risorsa. Lo usi solo quando P92001 si rifiuta di operare sulla riga — tipicamente per un record orfano, un duplicato che non dovrebbe esistere, o una violazione di chiave primaria. La chirurgia SQL richiede un backup completo delle quattro tabelle prima di iniziare, approvazione del DBA e del team CNC, e un report di integrità eseguito subito dopo. Dal punto di vista JDE non è auditabile: la modifica non lascia traccia OMW, nessuna cronologia versione, nessun pulsante di rollback.
Le query diagnostiche che ti dicono cosa è davvero sbagliato
Prima di decidere quale percorso prendere, esegui le quattro query che localizzano la corruzione. Richiedono pochi secondi e risparmiano ore di supposizioni.
Per prima cosa, conferma che il data item esista in F9200 (master) e F9210 (specifications):
SELECT FRDTAI, FRDSCR, FRSY FROM F9200 WHERE FRDTAI = 'YOUR_ALIAS';
SELECT FROMDTAI, FROOWTP, FROODA FROM F9210 WHERE FROMDTAI = 'YOUR_ALIAS';Se F9200 restituisce una riga ma F9210 restituisce zero, hai un classico orfano: il master esiste, le specifications no, e ogni form che fa riferimento all'alias fallirà. L'inverso — F9210 senza F9200 — è più raro ma peggiore, perché il compilatore delle spec ha qualcosa contro cui compilare, ma l'applicazione non potrà mai trovare il master.
Secondo, controlla le alpha descriptions in F9202 e le traduzioni in F9203 per le lingue usate dal sito:
SELECT FRLNGP, FRALPH FROM F9202 WHERE FRDTAI = 'YOUR_ALIAS';
SELECT FRLNGP, FRALPH FROM F9203 WHERE FRDTAI = 'YOUR_ALIAS';Una riga F9203 mancante per la lingua attiva di un utente è la causa più comune delle segnalazioni di "etichetta vuota" — il campo ha una descrizione in inglese ma non in italiano, e gli utenti italiani vedono un'intestazione vuota. Questo non è quasi mai "corruzione"; è una traduzione che non è mai stata creata.
Terzo, confronta il master con le tabelle spec centrali per il path code attivo. Le tabelle spec vivono nella data source specifica del path code (DD910, DV920, PY920, PD920 a seconda della release e del path code) e sono popolate dal processo di package build. Se F9210 dice decimals = 2 e la tabella spec dice decimals = 0, l'applicazione sta leggendo la tabella spec — il master nel database è corretto, le spec compilate sono sbagliate, e ti serve una partial package build del DD item interessato, non una correzione del database.
Quarto, esegui R9202 (Data Dictionary Repair) come select sull'alias per ottenere un report generato da JDE sull'integrità delle quattro tabelle. R9202 segnala orfani, traduzioni mancanti e definizioni incoerenti in un unico output, formattato nel modo in cui Oracle Support si aspetterà di vederlo se apri un'escalation.
Ordine di cache clear: sbagliarlo spreca l'operazione
Se decidi che il problema è cache, l'ordine delle operazioni conta. Svuotare la cache dell'Enterprise Server prima della cache dell'HTML Server significa che l'HTML Server può ripopolare la cache dell'Enterprise Server con i propri dati obsoleti alla richiesta utente successiva. La sequenza corretta è top-down: prima i fat client se coinvolti, poi HTML Server, poi i kernel dell'Enterprise Server, poi verifica che le tabelle spec siano aggiornate.
Sull'HTML Server, Server Manager espone "Clear Data Dictionary Cache" sotto i Runtime Metrics dell'istanza JAS. Svuota la cache JVM in memoria senza riavviare la JVM, quindi gli utenti in sessioni attive non vengono interrotti. Il successivo DD lookup eseguito da qualsiasi utente prende una copia fresca dal livello sottostante.
Sull'Enterprise Server, la cache vive nella memoria di processo di ogni Call Object kernel. Svuotarla richiede o il riavvio del kernel (interrompe le chiamate in corso) oppure l'uso dell'interfaccia runtime command del kernel tramite Server Manager. In pratica, su un ambiente trafficato l'approccio più pulito è un rolling restart dei Call Object kernel — ne fermi una frazione alla volta, lasci che il load balancer rediriga, ripeti. L'intera operazione su una configurazione da 16 kernel richiede circa 8-12 minuti ed è invisibile agli utenti.
Le tabelle spec (DD3xxxnn-style central spec store) si aggiornano durante le package build. Se una modifica DD è stata promossa ma non è stata eseguita alcuna package build, le tabelle spec sono obsolete e nessuno svuotamento della cache aiuta — i kernel leggono cache corretta da spec scorrette. Una partial package build del DD item interessato, tipicamente 5-15 minuti a seconda della dimensione dell'ambiente, è la correzione.
Quando SQL è inevitabile, la procedura sicura
La chirurgia SQL sulle tabelle F92xx è giustificata solo quando P92001 si rifiuta di correggere la riga e il report di integrità conferma un vero orfano o duplicato. La procedura è:
Primo passo, backup completo delle tabelle F9200, F9202, F9203, F9210 nella data source interessata, con la data nel nome del backup. Non un export logico — una copia CREATE TABLE AS SELECT che consenta confronti riga per riga in seguito. Saltare questo passo è il modo in cui una correzione da 20 minuti diventa una situazione da restore-from-tape.
Secondo passo, identifica ogni riga toccata dalla modifica imminente. Se stai rimuovendo un orfano da F9210, cerca eventuali righe correlate in F9202, F9203 e nelle tabelle spec che fanno riferimento allo stesso alias. Una correzione pulita rimuove le righe correlate in una singola transazione; lasciare residui in F9203 significa che la prossima query utente per quell'alias incontrerà un errore diverso.
Terzo passo, il DML dentro una transazione con rollback esplicito in caso di errore. Per una riga F9210 orfana senza master F9200, la forma sicura è:
BEGIN;
DELETE FROM F9210 WHERE FROMDTAI = 'ORPHAN_ALIAS'
AND NOT EXISTS (SELECT 1 FROM F9200 WHERE FRDTAI = 'ORPHAN_ALIAS');
-- verify row count matches expectation before commit
COMMIT;Quarto passo, esegui di nuovo R9202. Il report dovrebbe ora tornare pulito per l'alias interessato. Se segnala ancora un problema, ripristina dal backup ed escala — hai trovato qualcosa che la semplice cancellazione non risolve.
Quinto passo, svuota le cache top-down (HTML, Enterprise, ripeti) e ricostruisci il DD item interessato nelle tabelle spec tramite una partial package build. Senza questo, il database ora è corretto ma i kernel continuano a leggere il vecchio stato rotto dalla propria cache.
Sesto passo, documenta la correzione nel change log CNC con l'alias, l'SQL eseguito, i conteggi righe prima e dopo, e l'output del report di integrità. La chirurgia SQL non è auditabile da OMW, quindi l'unico audit trail che hai è quello che scrivi.
Gli errori che trasformano una correzione da 10 minuti in un incidente da 3 giorni
Il primo errore è saltare il cache clear e andare direttamente a SQL. Circa il 75% delle volte, l'errore visibile all'utente non era mai corruzione del database — era un kernel che leggeva una cache obsoleta. La chirurgia SQL in quella situazione non aiuta, ti lascia con una modifica non auditabile da investigare più tardi, e rischia di introdurre corruzione reale sopra un non-problema.
Il secondo è svuotare le cache nell'ordine sbagliato. Svuotare prima la cache dell'Enterprise Server e poi lasciare che l'HTML Server la aggiorni con la propria copia obsoleta è un modo da manuale per passare un'ora a chiedersi perché non sia cambiato nulla. Top-down è la regola, ogni volta.
Il terzo è fare la modifica in PD senza riprodurla prima in DV e PY. Anche una correzione d'emergenza dovrebbe essere applicata in DV, verificata, poi promossa attraverso PY verso PD usando un progetto OMW tracciato — o come minimo, lo script SQL di replay dovrebbe essere rieseguito contro PY e DV dopo che PD è stabile. Lasciare gli ambienti fuori sincronia trasforma il prossimo upgrade o refresh in una caccia alle discrepanze.
Il quarto è dimenticare che i DD item sono referenziati tramite alias in codice C compilato dentro le BSFN. Se cambi la dimensione o i decimali di un DD item senza ricostruire ogni BSFN che lo usa, il runtime vede un disallineamento tra la struttura C e la nuova definizione DD. Quel disallineamento può causare errori runtime duri nel Call Object kernel — non così drammatici come piace dire agli articoli più vecchi, ma reali, e risolvibili solo con una full BSFN rebuild dei B-object interessati.
Il quinto è trattare la corruzione F9203 come un problema di database. La maggior parte dei ticket di "traduzione mancante" non sono affatto corruzione — sono righe di traduzione che semplicemente non sono mai state create per il codice lingua dell'utente. La correzione è un aggiornamento P92001 con la traduzione mancante, non una riparazione SQL su F9203.
Se questo tipo di dettaglio operativo è ciò che ti serve per il lavoro quotidiano JD Edwards CNC e database, gli articoli correlati su questo sito coprono i pattern di progetto OMW, gli internals delle package build e le ottimizzazioni lato SQL sulle tabelle standard JDE. Il portfolio dei progetti mostra dove queste tecniche sono state applicate a lavoro reale di supporto produzione.
