

"Come chiamo JD Edwards" è la domanda che ricevo più spesso dai team che costruiscono qualsiasi cosa tocchi l'ERP dall'esterno — un flusso Power Automate, uno script Python per la riconciliazione notturna, un front-end React per il personale di magazzino. Nel 2026 la risposta non è più "scrivere un wrapper BSFN custom": è AISApplication Interface Services: il gateway REST fornito con JD Edwards EnterpriseOne che espone servizi form, dati e orchestrazioni via HTTP. e RESTRepresentational State Transfer: lo stile architetturale basato su HTTP usato da AIS, in cui ogni richiesta è stateless e porta con sé la propria autenticazione., e la scelta tra form services, data services e orchestrations decide se la tua integrazione sopravviverà alla prossima Tools Release.
Questa è la guida pratica all'integrazione JD Edwards AIS REST — come funziona realmente il ciclo di vita della chiamata, quando scegliere ogni tipo di chiamata, come si comportano autenticazione e session token in produzione, e le modalità di errore che colpiscono gli integratori dopo sei mesi.
Perché AIS ha sostituito tutto ciò che lo precedeva
Prima di AIS, integrare JD Edwards significava scegliere una di tre opzioni dolorose: scrivere un wrapper BSFNBusiness Function: codice C compilato che gira dentro il kernel JDE Call Object ed espone la logica di business JDE ai chiamanti interni. custom e chiamarlo tramite il protocollo proprietario JDENet, costruire un'interfaccia flat-file Z-file, oppure usare il vecchio layer XML Interop che nessuno ama toccare. Tutte e tre accoppiavano strettamente il sistema esterno agli internals JDE, e tutte e tre si rompevano sugli upgrade di Tools Release più o meno ogni 18 mesi.
AIS, distribuito come server Java standalone da Tools 9.2, espone tre famiglie di endpoint REST: form services che guidano un'APPL come farebbe un utente, data services che leggono o scrivono direttamente su tabelle e business view, e orchestration services che raggruppano una sequenza di passaggi in un endpoint stabile. Ciascuno risolve un problema di integrazione diverso, e scegliere quello sbagliato è la causa più comune di integrazioni che funzionano in DV e crollano in PD.
Il vantaggio non è solo la modernità del protocollo. AIS sta fuori dal ciclo di build del path code: una nuova orchestration va live senza server package, e lo stesso endpoint gira su DV, PY e PD cambiando una sola voce di configurazione. Per le organizzazioni che eseguono JDE multi-site, questo da solo vale il costo di migrazione dagli stili interop più vecchi.
Il ciclo di vita di una chiamata AIS, passo dopo passo
Ogni chiamata AIS segue lo stesso percorso in cinque fasi, indipendentemente dal fatto che tu stia leggendo inventory o avviando una sales order orchestration:
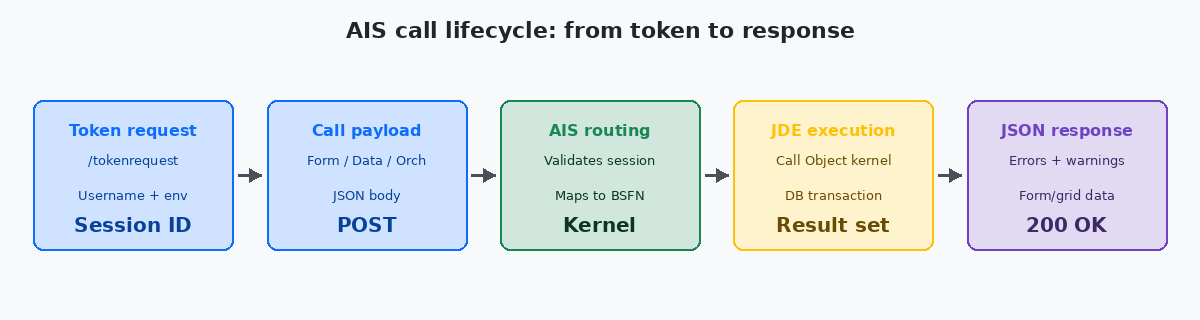
La fase uno è la richiesta del token. Il tuo client esegue un POST verso /jderest/v2/tokenrequest con username, password, environment e role. Il server AIS valida contro la sicurezza JDE, apre una sessione Call Object per tuo conto e restituisce un session token (`jasToken`) più il blocco userInfo. Questo token è valido per il timeout di sessione configurato — tipicamente 30 minuti di inattività — e rappresenta uno slot kernel reale sull'enterprise server. Trattalo come una risorsa costosa: non richiederne mai uno nuovo per ogni chiamata.
La fase due è il payload della chiamata. Esegui un POST verso /jderest/v2/formservice, /jderest/v2/dataservice, oppure /jderest/v2/orchestrator/<name>. Il body è JSON, la struttura dipende dal tipo di chiamata, e per gli endpoint v2 il session token va nel body, non in un header. L'errore più frequente la prima volta è inviare il token in Authorization: Bearer, che l'API v2 ignora silenziosamente.
La fase tre è il routing AIS. Il server valida il token, mappa la richiesta a un kernel Call Object e inoltra la chiamata attraverso il runtime JDE standard — lo stesso usato dalle sessioni HTML Server. Da questo punto in poi, la chiamata è indistinguibile da una transazione guidata da un utente: stessi record lock, stesse processing options, stesse event rules che scattano.
La fase quattro è l'esecuzione JDE. Il kernel esegue la catena di business function, raggiunge il database tramite JDBNET e assembla il risultato. Qui si consuma la maggior parte del tempo reale — tipicamente 100–800ms per una singola chiamata form service su un ambiente sano, più a lungo se l'APPL sottostante ha logica di fetch pesante o se stai colpendo una tabella contesa come F4211 durante il month-end.
La fase cinque è la risposta JSON. AIS incapsula l'output del kernel in un envelope stabile: form data, grid rows, errors, warnings e un session token aggiornato. Leggi sempre gli array errors e warnings anche con HTTP 200 — JDE restituisce errori business (inventory insufficiente, formato data non valido) dentro un body 200 OK, non come codici di errore HTTP.
Scegliere tra form, data e orchestration services
La decisione architetturale più importante in qualsiasi integrazione AIS è quale dei tre tipi di chiamata usare. Sembrano intercambiabili nella prima demo, ma in produzione non lo sono affatto.

Form services guidano un'APPL esistente esattamente come farebbe un utente. Specifichi la form (per esempio P4210_W4210A), l'azione (Find, Add, Update) e i valori dei campi. AIS esegue letteralmente le event rules della form end-to-end. Il vantaggio è che tutta la validazione, le processing options e la logica evento che hai costruito dentro l'APPL girano automaticamente. Lo svantaggio è che la tua integrazione si rompe nel momento in cui qualcuno cambia il nome di un controllo della form, riordina una colonna della grid o aggiunge un campo obbligatorio. Usa i form services per porting una tantum di interfacce legacy che già imitavano workflow utente, non per nuove integrazioni.
Data services leggono o scrivono direttamente su una tabella o business view, bypassando completamente il layer APPL. Sono veloci — tipicamente 30–80ms per chiamata — e ignorano le event rules, il che è sia una funzionalità sia una trappola. Per integrazioni di reporting read-only sono perfetti. Per le scritture sono pericolosi: un insert data service in F4211 non attiva la catena eventi del sales order, quindi il tuo NER custom che mantiene una tabella custom di impegni non gira mai, e tre settimane dopo finance chiede perché gli impegni sono fuori sync.
Orchestrations sono la scelta predefinita per qualsiasi integrazione non banale nel 2026. Le costruisci in Orchestrator Studio, le versioni come codice e le esponi come endpoint REST nominati. Una orchestration può raggruppare una chiamata form service, una lookup data service, una notification e uno step Groovy custom in una singola unità transazionale. Quando l'APPL sottostante cambia, l'orchestration assorbe la modifica — il contratto del tuo chiamante esterno resta stabile. Ogni nuova integrazione dovrebbe partire da una orchestration, salvo un motivo specifico per non farlo.
Autenticazione, session token e il costo di sbagliare
L'autenticazione AIS è lineare una volta capito che il session token rappresenta una sessione reale, che consuma risorse, sull'enterprise server. Ogni token tiene aperto uno slot kernel Call Object. Se costruisci un client che richiede un token fresco a ogni chiamata e non fa mai logout, esaurirai il pool di kernel. Su un tipico ambiente 9.2 con la configurazione kernel predefinita hai tra 50 e 200 kernel Call Object concorrenti — consumali tutti e ogni utente JDE, incluso il web client, inizierà a vedere errori "no available kernel".
Il pattern corretto è: acquisire un token per processo, riutilizzarlo per tutta la durata del lavoro e chiamare /jderest/v2/tokenrequest/logout al termine. Per i servizi long-running, aggiorna il token prima dell'idle timeout (di solito 30 minuti) effettuando una chiamata economica qualsiasi. AIS supporta anche un pattern di sessione poolable in cui più task brevi condividono un token — appropriato quando la tua integrazione è una funzione serverless che può girare centinaia di volte all'ora.
L'integrazione OAuth 2.0 con AIS esiste, ma non è un pasto gratis. AIS ha comunque bisogno di un utente JDE dietro ogni chiamata — OAuth porta il tuo utente esterno al gateway AIS, ma poi AIS mappa quell'identità a un utente JDE tramite il mapping basato su ruolo definito in Server Manager. Se il mapping è sbagliato, il tuo utente autenticato via OAuth gira con il ruolo JDE sbagliato e fallisce l'autorizzazione oppure, peggio, riesce con privilegi elevati. La tabella di mapping è l'artefatto di sicurezza più trascurato nelle distribuzioni AIS.
I service account sono la realtà pratica delle integrazioni system-to-system. Crea un utente JDE dedicato (non un account personale) per ogni sistema esterno, limita il suo ruolo esattamente a ciò che quel sistema richiede e ruota la password tramite Server Manager ogni 90 giorni. Non condividere mai un service account tra due integrazioni — quando una viene compromessa o genera rumore di audit, devi poter disabilitare solo quella.
Struttura del payload, gestione degli errori e ciò che AIS non ti dice
Il payload JSON delle chiamate AIS è verboso. Una chiamata form service a P4210 con cinque valori di campo pesa circa 1–2 KB di JSON; un fetch data service che restituisce 200 righe di grid pesa 50–150 KB. La maggior parte del volume è metadata strutturale, non dati business. Per integrazioni ad alto volume misura la dimensione reale del payload rispetto alla capacità di rete — un sito remoto su una WAN da 10 Mbps che esegue 30 fetch di grid al secondo saturerà il link molto prima che il server AIS senta qualsiasi carico.
La gestione degli errori è il punto in cui la maggior parte delle integrazioni AIS è rotta in modo silenzioso. HTTP 200 non significa successo. Analizza sempre gli array warnings e errors nel body della risposta. Un pattern tipico: l'aggiunta di un sales order restituisce 200 OK con array errors vuoto ma array warnings non vuoto contenente "Item not stocked at branch" — l'ordine è stato creato, ma con uno status che richiede revisione manuale. Trattare 200 come successo e scartare il body fa perdere completamente quel segnale. Allo stesso modo, AIS restituisce HTTP 400 per richieste malformate ma HTTP 200 con errors valorizzato per violazioni di business rule. Entrambi i casi devono essere gestiti, in percorsi di codice diversi.
L'envelope della risposta cambia tra endpoint v1 e v2. v1 (ancora vivo su Tools Releases più vecchie) incapsula i dati grid dentro fs_FORMNAME.data.gridData.rowset; v2 appiattisce questo in formOutput e gridData. Mischiare i due nello stesso client è la singola fonte più grande di bug del tipo "ieri funzionava". Scegli esplicitamente una versione nella configurazione del tuo client AIS e mantienila in tutte le integrazioni sullo stesso ambiente.
I tipi di campo meritano particolare attenzione. AIS restituisce le date come Julian JDE (CYYDDD) o ISO a seconda dell'endpoint e delle impostazioni del data dictionary della form. I campi numerici possono tornare come stringhe se il data item sottostante ha decimali — JDE li memorizza come interi e il decimale implicito vive nel data dictionary, non nel dato. Il tuo client deve riapplicare il posizionamento decimale del data dictionary, oppure riporterai silenziosamente valori sbagliati di 100x o 1000x.
Gli errori che rompono le integrazioni AIS in produzione
La prima modalità di errore è trattare AIS come se fosse una web API stateless. È in stile REST, ma il runtime JDE sottostante è profondamente stateful: lock, processing options in cache per sessione, cache a livello BSFN. Due chiamate parallele con lo stesso token possono collidere in modi in cui due chiamate parallele a un servizio REST stateless non possono. Per integrazioni concorrenti, usa un pool di token (uno per worker) oppure serializza le chiamate per business key.
La seconda è ignorare la velocità con cui AIS inoltra le chiamate al kernel. Il server AIS in sé può accettare migliaia di richieste HTTP al secondo, ma ogni chiamata inoltrata consuma uno slot kernel per la durata della transazione JDE. Se la tua integrazione spinge 200 sales orders al secondo attraverso un form service che impiega 600ms ciascuno, ti servono 120 kernel concorrenti solo per quell'integrazione — probabilmente più di quanti ne abbia l'intero ambiente. Misura il throughput end-to-end contro la capacità kernel reale, non contro il layer HTTP AIS.
La terza è costruire orchestrations che chiamano internamente form services invece di usare data services o BSFN custom per le parti che non hanno bisogno di logica APPL. Una chiamata form service dentro una orchestration porta con sé tutto l'overhead delle event rules — minimo 300–500ms — anche quando ti serviva solo una lettura da 30ms. Per orchestrations che girano migliaia di volte all'ora, mescolare correttamente i tipi di chiamata fa la differenza tra un tempo totale di esecuzione di 8 secondi e uno di 80 secondi.
La quarta è lasciare le orchestrations senza versione. Orchestrator Studio supporta le versioni per un motivo: una volta che una orchestration è consumata da un sistema esterno, il suo contratto di request e response fa parte della tua API. Modificarla in place senza aumentare la versione è il modo in cui rompi tutti i consumer downstream nello stesso momento. Tratta le versioni delle orchestrations come tratti le firme BSFN.
Se questo livello di dettaglio è ciò che ti serve per il tuo lavoro attuale di integrazione, gli articoli correlati su questo sito coprono pattern di Orchestrator Studio, misurazione delle performance BSFN e ottimizzazioni lato SQL che si abbinano alle letture AIS ad alto volume. Il portfolio progetti mostra dove queste tecniche sono state applicate a veri progetti di integrazione ERP.
