
Che cos’è davvero una Dashboard del rischio di retrofit
Al centro è uno score di rischio per oggetto, calcolato prima che inizi il lavoro di retrofit e presentato in modo che il team possa usarlo per definire le priorità. Gli input arrivano da tre fonti: l’output della fase Custom Code AnalyzerIl concetto tecnico che produce il verdetto per oggetto — tenere, fare retrofit, eliminare, riscrivere. Il suo output è l’input principale della dashboard., la telemetria runtime dell’ambiente sorgente e il grafo delle dipendenze degli oggetti JDE toccati. L’output è un singolo valore per oggetto — da 1 a 10, verde/giallo/rosso o altra scala — più il dettaglio di ciò che lo ha generato.
Un singolo numero conta perché una finestra di sviluppo di 9 settimane offre circa 70 giorni lavorativi al team dev. Con 350 oggetti impattati, sono circa cinque ore per oggetto in media, test inclusi. Una dashboard di questo tipo dice quali oggetti meritano una giornata e quali meritano quindici minuti. Senza questa vista, ogni oggetto riceve la stessa allocazione; quelli pericolosi vengono testati troppo poco e quelli banali vengono sovra-ingegnerizzati.
Anche la parte “dashboard” del nome conta. Non è una lista, non è un verdetto — è una vista che il project manager e il lead developer guardano ogni lunedì mattina per decidere dove indirizzare le prossime due settimane di effort. Statica all’inizio, poi aggiornata man mano che il retrofit procede e le ipotesi vengono validate.
Perché questa disciplina è nata
Perché l’alternativa — trattare il lavoro di retrofit come una lista piatta di 350 righe tutte con lo stesso peso — ha una modalità di fallimento prevedibile. Il team parte dall’inizio dell’alfabeto, consuma le prime sei settimane sulle UBEsUniversal Batch Engine — il motore batch report di JDE. Le UBE custom sono gli oggetti più numerosi e di solito a minor rischio in un parco retrofit. custom facili con prefissi A e B, e scopre alla settimana sette che le tre BSFNsBusiness Functions — codice C compilato nel runtime JDE. Stanno alla base del grafo delle dipendenze e rompono tutto quando falliscono. custom al centro del flusso order entry sono ingestibili nella loro forma attuale. A quel punto il budget è finito.
La dashboard del rischio inverte questo schema. Gli oggetti più pericolosi vengono lavorati per primi, quando il team è fresco e c’è ancora tempo per escalare. Quelli banali finiscono in coda al piano, dove un junior developer può chiuderne dieci in un giorno. Stesso lavoro totale, risultato completamente diverso alla settimana nove.
È anche per questo che i team con PM forti gravitano verso questa disciplina anche quando non esiste un artefatto formale. Ricostruiscono la dashboard nella testa, su una lavagna, in uno spreadsheet mezzo rotto — perché senza di essa l’upgrade va live in ritardo oppure va live rotto, e hanno già visto entrambi gli scenari.
Le tre dimensioni di input di un vero risk score
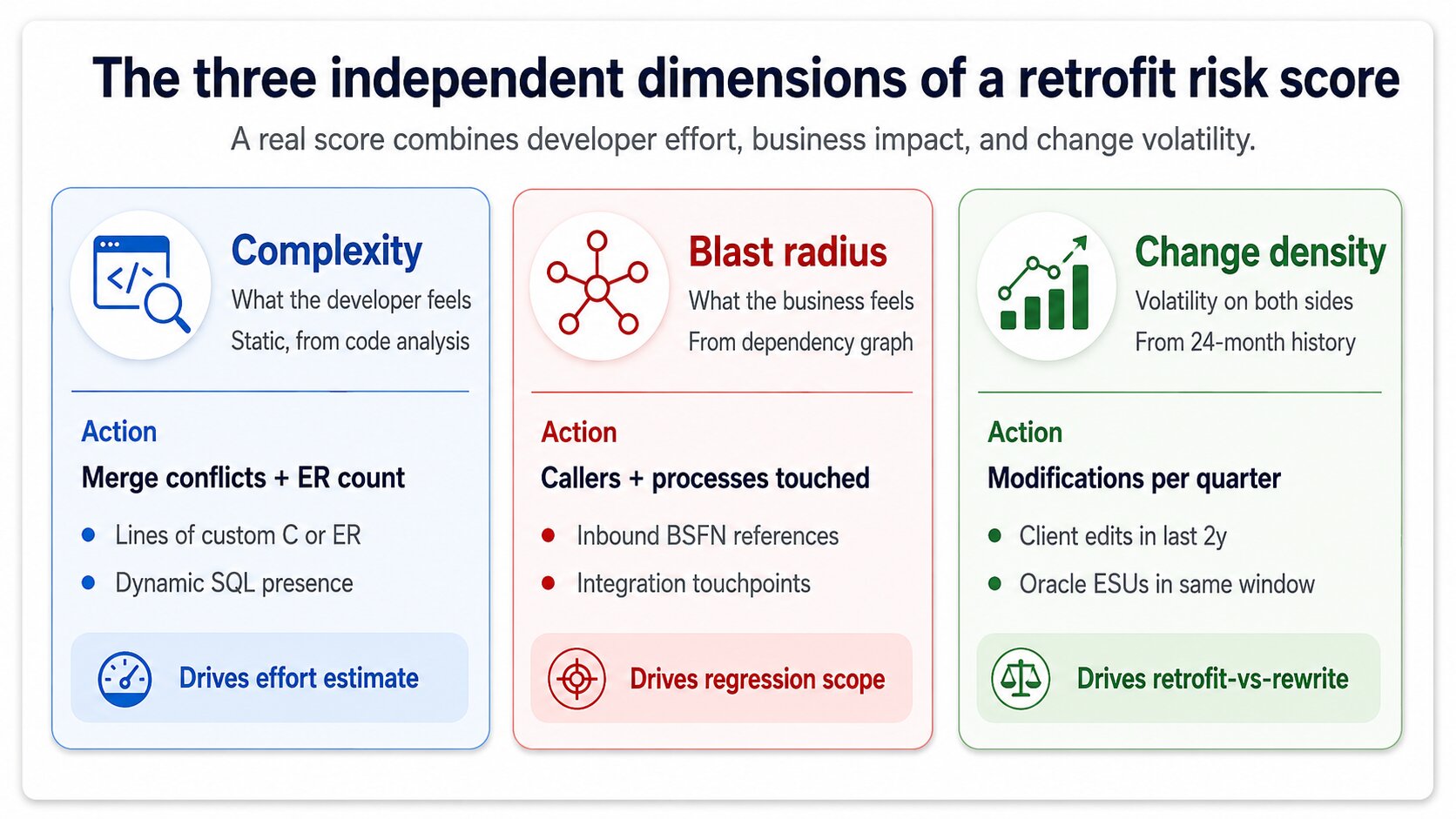
Uno score con una sola dimensione è un’ipotesi. Uno score con tre dimensioni è una valutazione tecnica difendibile. Le tre dimensioni che contano davvero sono complessità, blast radius e change density, e una dashboard seria del rischio le calcola tutte e tre in modo indipendente prima di combinarle.
La complessità è ciò che sente lo sviluppatore. Numero di conflitti di merge previsti dalla fase di fingerprint, righe di codice custom nell’oggetto, presenza di Event RulesIl livello di scripting visuale di JDE collegato a form e applicazioni. Il retrofit delle Event Rules è più difficile del retrofit del codice C perché il diff è visuale, non testuale. invece di C lineare, presenza di SQL dinamico. Una BSFN custom con 40 righe di C invariato e una variabile rinominata è complessità 1. Un’applicazione custom con 200 Event Rules e modifiche Oracle in conflitto in tre subform è complessità 9.
Il blast radius è ciò che sente il business. Quanti altri oggetti dipendono da questo, quanti processi di business lo attraversano, quante integrazioni lo chiamano. Una UBE custom che nessuno esegue ha blast radius 1 anche se il codice è complesso. Una BSFN custom chiamata da 47 applicazioni tra order entry, manufacturing e finance ha blast radius 9 anche se il suo codice è banale da mergiare. Le due dimensioni sono indipendenti, e una buona dashboard non le collassa mai troppo presto.
La change density è il segnale di volatilità. Quanto spesso l’oggetto nell’ambiente sorgente è stato modificato negli ultimi 24 mesi, quanti ESU Oracle ha rilasciato sull’equivalente standard nello stesso periodo. Change density alta su entrambi i lati significa che i retrofit futuri diventano più difficili, non solo questo — lo score dovrebbe riflettere il costo strategico del retrofit rispetto alla riscrittura sulla base Oracle corrente.
Come la telemetria runtime affina lo score
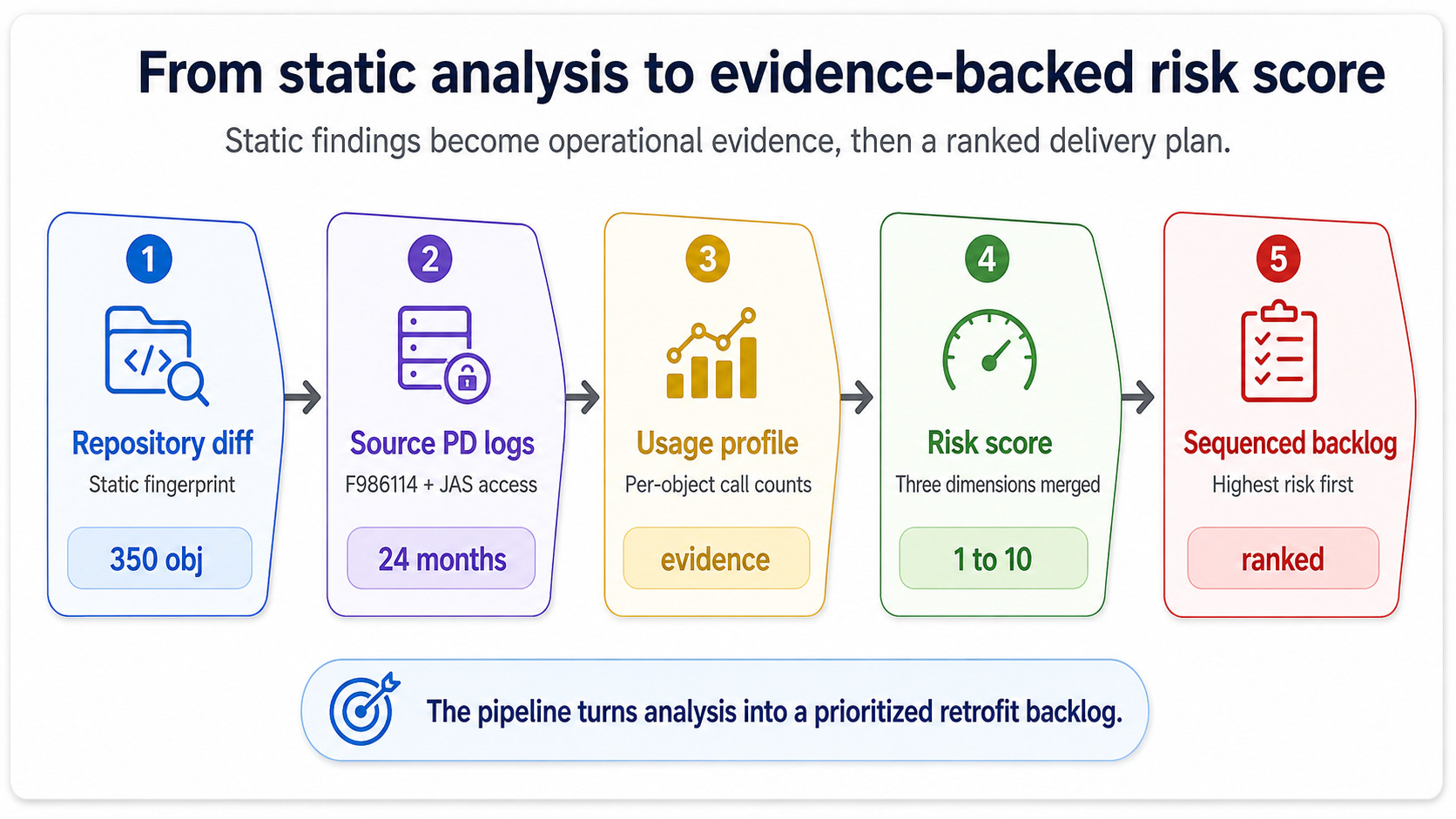
Le dimensioni sopra possono essere calcolate staticamente, dal repository e dalla cronologia delle modifiche. La dashboard del rischio diventa utile — e non solo un esercizio accademico — quando includi dati runtime dall’ambiente sorgente.
L’ambiente sorgente PDAmbiente di produzione in JDE — l’ambiente live. I log di esecuzione PD sono la fonte di verità per capire quali oggetti vengono realmente usati e quanto spesso. sa cose che l’analisi statica non vede. Sa quali UBE custom sono state eseguite zero volte nell’ultimo trimestre, quali BSFN custom sono state chiamate 11 milioni di volte, quali applicazioni custom avevano cluster di error log nelle settimane prima dell’avvio della pianificazione go-live. Estrai i conteggi di esecuzione da F986114La tabella di controllo job di JDE. Registra ogni sottomissione UBE ed è la fonte canonica per la telemetria di esecuzione batch nell’ambiente sorgente. per la parte batch e dai JAS access log per la parte interattiva, e ottieni un profilo d’uso che trasforma il “blast radius” da stima a evidenza.
È questa mossa che trasforma la dashboard da spreadsheet statico a qualcosa di cui il project manager si fida davvero. Uno score verde supportato da zero esecuzioni è onesto. Uno score verde che ignora 11 milioni di chiamate è un progetto in attesa di fallire al cutover.
Che aspetto ha la dashboard a livello di artefatto
La forma fisica varia — alcuni team usano una pagina Confluence, altri un report Power BI su un estratto SQL, quelli disciplinati usano un CSV piatto che chiunque può filtrare. La forma è irrilevante. Ciò che conta è che per ognuno dei 350 oggetti impattati tu possa rispondere a quattro domande in meno di un minuto.
Qual è lo score, e cosa lo ha generato. Chi possiede questo oggetto durante il retrofit. Qual è l’effort pianificato e qual è il perimetro di regressione previsto. Qual è lo stato corrente — non iniziato, in sviluppo, in test, approvato. Se la dashboard non può rispondere a queste quattro domande su richiesta per qualunque oggetto, non è una dashboard del rischio, è una lista. La distinzione non è pedante: le liste non cambiano i comportamenti, le dashboard sì.
L’altro requisito a livello di artefatto è che la dashboard si aggiorni. Una stima retrofit scritta alla settimana zero sarà sbagliata alla settimana tre — alcuni oggetti si riveleranno più difficili, altri banali — e la dashboard deve assorbire le correzioni senza cerimonie. I team che trattano lo scoring iniziale come verità assoluta consegnano in ritardo. I team che lo trattano come ipotesi in revisione continua consegnano in tempo.
Dove la dashboard si inserisce nel resto dell’upgrade
Alimenta due consumatori downstream. Il team di sviluppo la usa per sequenziare il lavoro, prendendo gli oggetti con score più alto alla settimana uno e salvando quelli banali per la coda del piano. Il team di test la usa per definire il perimetro di regressione: oggetti con alto blast radius trascinano più processi di business nella copertura regressiva, mentre oggetti con basso blast radius possono essere coperti solo da smoke test automatizzati.
Il terzo consumatore è lo steering committee, ed è qui che la maggior parte dei team sottovaluta l’artefatto. La dashboard, aggregata in un grafico di distribuzione, dice al CIO se il retrofit rientrerà nello scope o no — molto prima che il team di sviluppo faccia emergere questa informazione tramite il normale status reporting. Una dashboard sbilanciata sul rosso è una conversazione di budget alla settimana due, non un incendio alla settimana otto. Quel segnale precoce è il secondo output più prezioso della disciplina, dopo la prioritizzazione quotidiana.
A monte, la dashboard dipende interamente dal fatto che le fasi di smart filter e fingerprint abbiano prodotto output pulito. Garbage in, dashboard inutile out. Per questo la disciplina non vive mai in isolamento — è la terza fase di una pipeline a quattro fasi, e saltare il lavoro upstream per passare direttamente allo scoring produce numeri di cui nessuno si fida.
Cosa significa per il tuo scope di upgrade
Se il partner che gestisce il tuo retrofit non può mostrarti un backlog con scoring del rischio o un equivalente difendibile alla settimana uno di sviluppo, hai un problema che ancora non conosci. L’artefatto non deve per forza avere questo nome — sinonimi come matrice di triage retrofit, backlog ponderato per impatto e work order con risk score descrivono la stessa disciplina — ma le tre dimensioni di input e le quattro domande a livello di artefatto non sono negoziabili.
Chiedi di vederla. Chiedi quali oggetti hanno avuto lo score più alto e perché. Chiedi come è stata incorporata la telemetria runtime del tuo ambiente sorgente. Se le risposte sono vaghe, il team scoprirà gli oggetti pericolosi nel modo lento, sul tuo tempo. Il costo di questa scoperta, in un tipico ambiente da 9.1 a 9.2, si colloca tra tre e sei settimane extra di sviluppo più un impatto visibile sul superamento dei regression test.
Se vuoi una seconda opinione sul fatto che il tuo piano di retrofit abbia la struttura di scoring e prioritizzazione necessaria, prenota una consulenza gratuita. Analizzeremo le dimensioni sul tuo ambiente specifico, vedremo dove vive la telemetria runtime nel tuo ambiente sorgente e ti diremo onestamente se il lavoro davanti a te è pesato correttamente — o se il progetto è a una brutta settimana da una conversazione di budget.