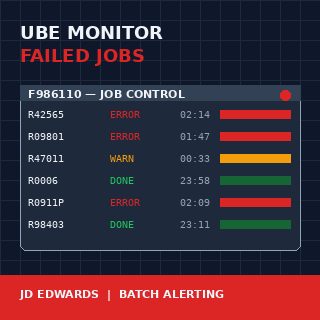
Un monitor dei job batch JD Edwards EnterpriseOne per report UBE falliti è una di quelle realizzazioni che si ripaga nel primo mese e continua a ripagarsi a ogni chiusura trimestrale successiva. La console Server Manager ti dirà che un job è terminato in errore, ma non sveglierà nessuno per questo, e non ti dirà che il run di conferma R42565 è fallito per la terza notte consecutiva alle 02:14. Quando il responsabile del magazzino chiama alle 7 del mattino chiedendo perché non sono stati stampati i pick slip, i dati sono già vecchi di quattro ore e la mattinata è già compromessa.
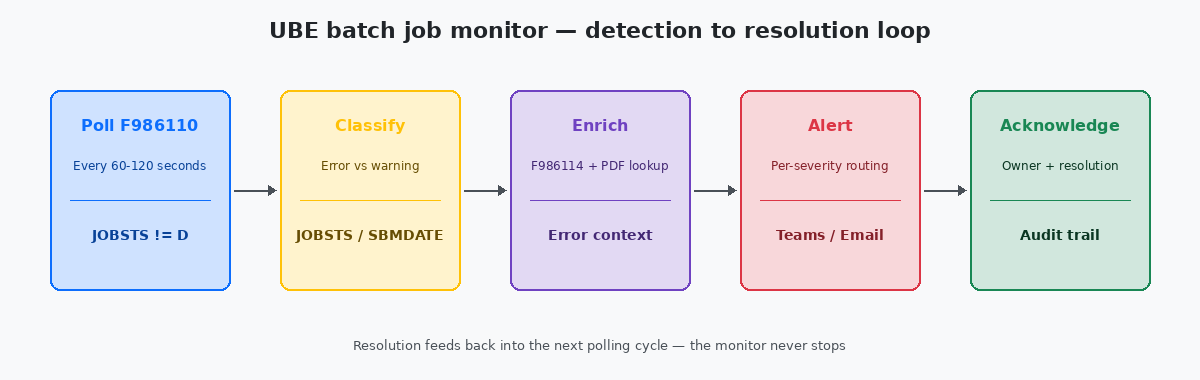
Ogni installazione JDE matura con cui ho lavorato finisce prima o poi per costruire uno di questi monitor. Quelli che funzionano condividono tre caratteristiche: interrogano F986110Job Control Master — la tabella JDE che registra ogni sottomissione UBE, il relativo codice di stato, gli orari di inizio e fine e il server su cui è stata eseguita. con una cadenza serrata, classificano gli errori per impatto e instradano gli alert verso canali coerenti con la severità. Quelli che falliscono di solito sono solo via e-mail, scattano per qualsiasi cosa e vengono silenziati dal team operations entro sei settimane.
Che cosa significa davvero "failed" in F986110
Il Job Control Master è la singola fonte di verità per l’esecuzione batch in JDE E1. Ogni sottomissione UBE scrive qui una riga, identificata da JOBNBR, con una colonna JOBSTS che attraversa un piccolo insieme di valori a singolo carattere: W (in attesa), P (in elaborazione), D (completato), E (errore), CE (annullato con errore), S (annullato dall’utente), H (trattenuto). Un monitor ingenuo controlla JOBSTS = E e invia un alert. Un monitor utile conosce la differenza tra E e CE, tratta i job H più vecchi di 30 minuti come un problema separato e riconosce che un job P che è in elaborazione da sei ore quando normalmente termina in dodici minuti è anch’esso un fallimento, solo più silenzioso.
Le colonne SBMDATE e SBMTIME forniscono il timestamp di sottomissione; ENDDATE e ENDTIME forniscono il completamento. La distanza tra la sottomissione e l’ora corrente di sistema è ciò che consente di segnalare i job bloccati. La colonna PID indica quale UBE fosse, e questo conta perché il fallimento di R0006 (EDI inbound) ha conseguenze downstream diverse dal fallimento di R09801 (Post General Ledger), e il monitor deve sapere distinguere l’uno dall’altro.
La colonna SRVRNM indica quale enterprise server ha eseguito il job. In un’installazione multi-server questa non è un’informazione cosmetica — un errore ricorrente su un server mentre gli altri funzionano correttamente è un problema infrastrutturale, non un problema UBE, e il monitor dovrebbe evidenziare quel pattern.
Il ciclo di polling e perché il timing conta più della logica
Il monitor funzionante più semplice è una query SQL su F986110 eseguita ogni 60-120 secondi da un job schedulato. Eseguirla più spesso carica il database senza alcun beneficio umano — nessuno reagirà comunque a un alert in meno di un minuto. Eseguirla meno spesso fa perdere la capacità di intercettare errori a ciclo breve prima che il job dipendente successivo provi a partire.
La query in sé è lineare: estrarre ogni riga in cui JOBSTS è in ('E','CE') e ENDDATE è maggiore o uguale all’high-water mark del ciclo di polling precedente. Traccia l’high-water mark in una piccola tabella custom, così un riavvio del monitor non riproduce ogni errore degli ultimi sei mesi. Il pattern è lo stesso principio di idempotenza che vale per qualsiasi caricamento dati — eseguire il monitor due volte dovrebbe produrre un solo insieme di alert, non due.
Il punto che la maggior parte delle implementazioni si perde è la gestione del fuso orario. F986110 memorizza le date in formato giuliano JDE e gli orari come valori interi HHMMSS, entrambi nel fuso orario dell’enterprise server. Se il monitor gira su un host diverso in un fuso orario diverso, la logica di confronto deve convertire esplicitamente. Ho fatto debug di un monitor che perdeva silenziosamente ogni errore tra le 23:00 e mezzanotte perché il confronto attraversava un cambio data dal lato sbagliato.
Classificare la severità senza scrivere mille regole
L’istinto alla prima implementazione è scrivere una regola per ogni UBE. Quando arrivi a 40 regole hai già un caos non manutenibile, e quando arrivi a 200 nessuno sa più quali regole siano ancora valide. Il pattern che scala è la severità per categoria, non per job.
Tre categorie coprono circa il 95% delle installazioni reali. Critical significa con impatto su ricavi o compliance: EDI inbound e outbound (R47*), conferma spedizione ordini di vendita (R42565), fatturazione (R42565, R03B11Z1I), chiusura periodo (R09801, R0911P, R09866), generazione payroll. Standard significa con impatto sul business ma non nello stesso giorno: report di integrità dei master file, job di riorganizzazione, monitor di replica. Noisy significa errori che ricorrono in modo prevedibile e sono di solito problemi di dati: report di integrità che segnalano record orfani noti, UBE custom che falliscono spesso su input errati.
La classificazione vive in una piccola tabella di lookup indicizzata per PID, con Standard come default per tutto ciò che non è mappato. Le nuove UBE vengono aggiunte al lookup come parte della checklist di promozione dello sviluppo, non dopo. Il monitor legge il lookup una volta per ciclo di polling e lo mantiene in cache per il resto del ciclo.

Instradare gli alert verso canali che vengono davvero letti
L’e-mail è il posto dove gli alert vanno a morire. La prima versione di ogni monitor che ho ereditato inviava messaggi a una distribution list con dodici persone; al terzo mese, dieci di loro avevano una regola Outlook che spostava i messaggi in una cartella che nessuno apre. Il pattern che funziona è il routing mappato sulla severità: gli alert critical vanno a un sistema di paging con rotazione on-call, gli alert standard vanno a un canale Teams o Slack dedicato con dentro il team operations, gli alert noisy vanno a una digest e-mail giornaliera che riassume invece di spammare.
Il pattern del canale Teams è il cavallo di battaglia per gli alert standard. Un webhook riceve un payload JSON con JOBNBR, PID, server, timestamp dell’errore e un link diretto all’output PDFIl file di output UBE generato per ogni job batch, memorizzato nella directory PrintQueue sull’enterprise server. Il contesto dell’errore di solito si trova nelle ultime pagine. e al job log nella console web di Server Manager. Il link conta — senza di esso, ogni alert costa cinque minuti di navigazione prima che l’ingegnere possa iniziare la diagnosi. Con esso, la diagnosi spesso avviene direttamente dall’alert.
Il sistema di paging, che sia PagerDutyUna piattaforma di incident response molto diffusa che gestisce turni on-call, alert telefonici, SMS ed escalation automatica quando gli alert non vengono confermati entro una finestra definita., Opsgenie o uno degli equivalenti open source, dovrebbe scattare complessivamente su circa cinque-dieci PID, non su ogni riga rossa in F986110. Meno job svegliano le persone alle 3 del mattino, più credibilità mantiene il monitor. La lista delle UBE idonee al paging dovrebbe essere rivista ogni trimestre, perché alcuni job diventano critici e altri smettono di esserlo.
La deduplicazione degli alert è il dettaglio che ogni team sbaglia alla prima implementazione. Quando la chiusura del periodo fallisce, non fallisce in isolamento — un errore di R09801 di solito significa che anche R0911P e R09866 falliranno nei successivi dieci minuti, perché dipendono dallo stesso stato dei dati. Senza deduplicazione, l’ingegnere on-call riceve quattro alert per una sola root cause e deve collassarli mentalmente. Il pattern che funziona è una finestra di alert di cinque minuti indicizzata per categoria e server, in cui il monitor emette un solo alert aggregato con l’elenco di tutti i fallimenti correlati invece di scattare quattro volte. Venti righe di logica di raggruppamento, miglioramento misurabile del tempo medio di conferma.
Arricchire gli alert con il contesto che serve davvero all’ingegnere on-call
La differenza tra un alert utile e una tassa sull’attenzione è il contesto allegato. Un semplice "R42565 failed on server JDE_ENT01" costringe l’ingegnere ad accedere al Server Manager, trovare il job, scaricare il PDF, aprirlo, scorrere fino in fondo e leggere lo stack dell’errore. Moltiplica questo per ogni alert e il monitor diventa un drenaggio di produttività.
L’arricchimento che si ripaga deriva dal join tra F986110 e F986114 (il dettaglio degli step del job) e dal portare le ultime righe del job log direttamente nel payload dell’alert. Il messaggio di errore — "Invalid Branch/Plant for Item 30000" oppure "Mandatory Processing Option PR1 not set" — dice all’ingegnere on-call in cinque secondi se si tratta di un problema dati (chiamare l’analyst) o di un problema codice (chiamare lo sviluppatore). Senza quella riga, ogni alert è un lancio di moneta.
Il secondo elemento di arricchimento che scala è il rilevamento della ricorrenza. Se lo stesso PID è fallito per tre notti di fila più o meno alla stessa ora, il payload dell’alert dovrebbe dirlo. La correzione raramente è la stessa di un errore una tantum, e chi risponde deve sapere che cosa sta guardando prima di iniziare. Una piccola tabella di ricorrenza, indicizzata per PID e azzerata settimanalmente, è fatta di cinquanta righe di SQL e fa risparmiare ore al mese.
L’ultimo elemento, spesso saltato, è il ciclo di acknowledgement. Quando l’ingegnere on-call corregge un job, dovrebbe poter marcare l’alert come risolto con un breve commento — "PO bad data, fixed in F4311 batch 1207" — e far finire quel commento in una piccola tabella di storico del monitor. Tre mesi dopo, quando la stessa UBE fallisce nello stesso giorno del mese, il responder successivo vede la risoluzione precedente e riconosce il pattern in trenta secondi invece di ripartire da zero. L’audit trail dà anche all’operations manager qualcosa di concreto da inserire nel report trimestrale di stabilità: non "il monitor ha intercettato 247 errori", ma "247 errori, tempo medio di acknowledgement 11 minuti, primi tre offender R47011, R42565, R09801, tutti risolti entro SLA". Questi sono i dati che giustificano la realizzazione.
Se il batch monitoring è il tipo di disciplina operativa che vuoi rafforzare, gli articoli correlati sulla configurazione di JDE Server Manager, sul design di checkpoint e restart delle UBE e sulle strategie di archiviazione di F986110 coprono lo stack operativo dall’altro lato. Il portfolio dei progetti tecnici su questo sito documenta due dei monitor di produzione che hanno prodotto i pattern descritti qui.