La domanda più difficile a cui rispondere in qualsiasi installazione JDE matura è una delle più semplici da fare: "se modifico questa tabella, quale applicazione custom si rompe?" Mappare le dipendenze delle business view nelle applicazioni custom JD Edwards EnterpriseOne è la disciplina che trasforma quella domanda da un esercizio forense di più giorni in una query che restituisce il risultato in pochi secondi. La maggior parte delle installazioni ha tra 80 e 400 business view custom stratificate sopra tabelle standard e custom, chiamate da un numero sconosciuto di applicazioni, UBE e form — e nessuno ha un quadro aggiornato di cosa dipenda da cosa.
Il costo di non saperlo si paga ogni volta che qualcosa cambia. Una colonna aggiunta a F4211. Un nuovo indice su F0911. Una tabella custom rinominata durante una pulizia. Ogni cambiamento si propaga attraverso tutte le business view che referenziano l’oggetto interessato, e ogni BV influenza ogni applicazione costruita sopra di essa. Senza una mappa, l’impatto viene scoperto quando qualcosa si rompe in PY, o peggio, in PD.
Perché le business view sono il punto giusto per ancorare la mappa
Una business view in JDE non è una database view. È un oggetto di metadati che seleziona colonne da una o più tabelle, definisce join tra esse ed espone il risultato come un singolo dataset rettangolare a cui form, applicazioni e UBE si collegano. La BV si trova tra le tabelle e il codice, ed è esattamente per questo che è il nodo giusto da usare come ancoraggio di qualsiasi mappa delle dipendenze.
Ancorarsi solo alle tabelle produce rumore — ogni applicazione legge tabelle, direttamente o indirettamente, e il grafo risultante è troppo denso per essere utile. Ancorarsi alle applicazioni produce lacune — le applicazioni chiamano BVs che fanno join su più tabelle, e una domanda a livello tabella instradata attraverso una mappa solo applicativa perde fedeltà. La BV è il punto di join naturale: sa quali tabelle tocca ed è conosciuta da ogni caller sopra di essa.
Sul lato upstream, ogni BV dichiara le proprie tabelle sorgente nella spec, registrata nella tabella repository F98711Tabella dei metadati delle colonne delle business view — la tabella repository JDE che registra quali colonne di quali tabelle ogni business view espone, insieme alle definizioni di join.. Sul lato downstream, ogni form, applicazione e UBE che usa una BV registra la relazione in F9860 con un source type che identifica il consumer. Due query SQL, correttamente collegate, producono il grafo completo per l’intera installazione.
L’altro motivo per ancorarsi alle BVs è che cambiano meno frequentemente del codice che le usa. Una BV con venti consumer può essere modificata una volta l’anno; le venti applicazioni sopra di essa possono essere toccate venti volte nello stesso periodo. Una mappa costruita sul livello stabile mantiene la propria accuratezza più a lungo tra un ciclo di rigenerazione e l’altro.
Le tabelle repository che contengono la verità
Il repository JDE — i metadati su ogni oggetto dell’installazione — vive in un piccolo insieme di tabelle di sistema che sono read-only dal punto di vista dello sviluppatore e costantemente sottoutilizzate per l’analisi. Le quattro che contano per il dependency mapping sono F9860, F98711, F98712 e F98750.
F9860 è l’object librarian master. Ogni BSFN, applicazione, UBE, business view e tabella ha qui una riga, con OBNM (object name), FUNO (function use, che identifica il tipo) e SRCTYPE (source type, che distingue BV da APPL, UBE e TBL). Una semplice query su F9860 filtrata sui valori FUNO delle business view restituisce la lista completa delle BVs nell’installazione; filtrata sulle applicazioni, la lista completa delle form sopra di esse. I valori di filtro sono documentati nelle definizioni delle tabelle standard e non cambiano tra Tools Releases.
F98711 è la tabella di join a livello colonna per le business view. Ogni colonna che una BV espone è una riga, con la tabella sorgente e il campo sorgente. Aggregare F98711 per nome BV fornisce il footprint completo a livello tabella di ogni view — esattamente ciò che serve al lato upstream della mappa delle dipendenze.
F98712 registra sezioni di form e report che si collegano a una BV. Un’applicazione custom che chiama tre BVs diverse attraverso le sue form produce tre righe in F98712, indicizzate per nome applicazione e nome BV. Questo è il lato downstream: quali caller usano quali view.
F98750 è il data store delle spec nelle Tools Releases moderne — il contenuto binario delle spec viene salvato qui, indicizzato per oggetto. Per il dependency mapping, F98750 di solito non è la sorgente primaria perché i metadati leggibili sono già nelle altre tre tabelle; F98750 diventa rilevante solo quando si inseguono dettagli a livello spec che le tabelle di metadati appiattiscono.
Costruire il grafo: dall’estrazione SQL alla struttura navigabile
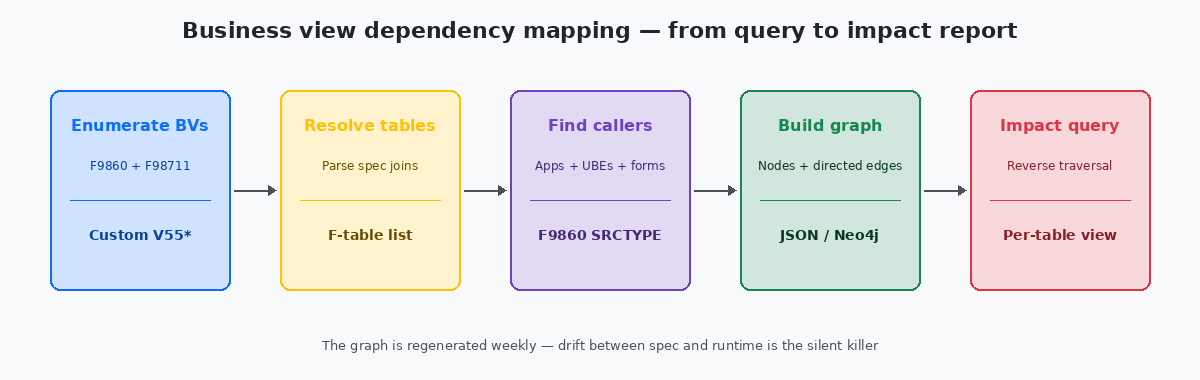
La parte meccanica del mapping è lineare e viene regolarmente complicata senza motivo. Tre query SQL contro il repository, eseguite in sequenza, producono tutto ciò che serve per un dependency graph completo per un’installazione di qualsiasi dimensione.
La prima query enumera ogni business view custom — filtrata per prefisso nome, tipicamente da V55 a V59 negli ambienti che seguono la convenzione del namespace riservato Oracle. L’output è una lista piatta con nome BV, descrizione BV e timestamp dell’ultima modifica. In una tipica installazione di medie dimensioni restituisce da 80 a 300 righe in meno di un secondo.
La seconda query risolve ogni BV sulle sue tabelle sorgente. Unendo F9860 a F98711 tramite OBNM e raggruppando per BV più nome tabella sorgente si produce una lista many-to-one — una riga per ogni relazione BV-tabella. Una BV che fa join tra F4211 e F4101 produce due righe. Una BV che tocca otto tabelle ne produce otto. Il volume totale in un’installazione reale è tipicamente tra 200 e 1.500 righe.
La terza query trova ogni caller per ciascuna BV leggendo F98712 e facendo join di ritorno su F9860 per arricchire il caller con tipo e descrizione. È il più grande dei tre output perché una BV popolare può avere venti o trenta caller; i conteggi totali arrivano alle migliaia nelle installazioni più grandi, ma restano volumi banali per qualsiasi database moderno.
I tre result set diventano gli archi di un grafo diretto: le tabelle puntano verso l’alto nelle BVs, le BVs puntano verso l’alto nei caller. Salvato come JSON, il grafo occupa poche centinaia di kilobyte e può essere caricato in qualsiasi strumento di visualizzazione, da Neo4jUn database a grafo ampiamente usato per analisi di dipendenze, reti e relazioni. Memorizza nativamente nodi e archi diretti e risponde a query di raggiungibilità con singole istruzioni Cypher. fino a una pagina HTML statica con una libreria di layout force-directed. La visualizzazione conta meno della struttura sottostante — lo stesso JSON risponde a query programmatiche tanto bene quanto a quelle visive.
Le impact query che giustificano lo sforzo
Un dependency graph che non viene mai interrogato è teatro documentale. Le query che giustificano la sua costruzione sono quelle che rispondono a domande reali che sviluppatori e team CNC fanno sotto pressione.
La prima impact query è una traversata inversa da una tabella: dato che F4211 riceverà una nuova colonna nel prossimo sprint, elenca ogni BV custom che seleziona da essa, e per ogni BV elenca ogni caller. La risposta guida il piano di regression test. Su un grafo con 200 BVs e 2.000 caller, questa query restituisce in poche decine di millisecondi e produce una lista esaustiva in un modo che nessun foglio Excel è mai stato.
La seconda impact query è una traversata in avanti da un’applicazione: dato che la custom P55020A sta per essere deprecata, elenca ogni BV che usa, e per ogni BV controlla se qualche altro caller dipende da essa. Le view senza altri consumer diventano a loro volta candidate alla deprecazione, e la catena continua fino alle tabelle che nient’altro legge. Questa è la query che guida la pulizia del debito tecnico — i candidati emergono da soli quando il grafo esiste.
La terza query è l’orphan detection. Le BVs custom in F9860 che hanno zero righe in F98712 sono orphan — esistono nel repository ma nulla le chiama. Le tabelle custom da cui nessuna BV seleziona sono orphan più profondi. In un’installazione di 20 anni, i conteggi degli orphan vanno tipicamente dal 5% al 15% dell’estate custom, e ogni orphan è codice morto che deve comunque essere portato attraverso ogni upgrade. Farli emergere è il primo uso pratico del grafo nella maggior parte delle installazioni.

Mantenere la mappa onesta: cadenza di rigenerazione e drift
Il singolo failure mode di qualsiasi dependency map è l’obsolescenza. Un grafo generato una volta all’inizio di un progetto e mai aggiornato è sbagliato entro poche settimane — ogni check-in in OMW che aggiunge o modifica una BV crea un delta che il grafo statico non conosce. La disciplina che mantiene la mappa onesta è la rigenerazione automatizzata con una cadenza che il team segue davvero.
La cadenza che funziona nella maggior parte delle installazioni è settimanale. Un job schedulato — uno shell script, una piccola UBE o uno script Python connesso al database JDE — esegue le tre query repository, costruisce il JSON, archivia la versione precedente e pubblica il nuovo grafo nel percorso usato dal team. Settimanale è abbastanza frequente perché la mappa non resti mai più di pochi giorni indietro rispetto alla realtà, e abbastanza rara perché il job non produca rumore.
Il diff tra snapshot consecutivi è più utile di qualsiasi singolo snapshot. Nuove BVs apparse questa settimana, BVs le cui tabelle sorgente sono cambiate, BVs che hanno guadagnato o perso caller — questi sono gli elementi da far emergere nella review settimanale del team. Una BV che improvvisamente ha aggiunto una quinta tabella nel proprio join è un’opportunità di code review; una BV che ha perso il suo ultimo caller rimasto è una candidata alla cancellazione. Il diff sono venti righe di script e trasforma il grafo da documento di riferimento in un feedback loop su ciò che il team sta realmente costruendo.
Per approfondire il territorio circostante, gli articoli correlati sul retrofitting delle copie dello standard, sullo scoping degli upgrade Tools Release e sulle strategie di archiviazione delle F-table coprono il livello operativo su cui questa mappa si appoggia. Il portfolio dei progetti tecnici su questo sito documenta due strumenti di dependency in produzione che hanno prodotto i pattern descritti qui.