
Un upgrade di Tools Release o un passaggio da 9.1 a 9.2 viene approvato come "successful" nel momento in cui il nuovo ambiente supera il login. Quella è la parte facile. La parte difficile — e la parte che produce le sorprese tardive post-go-live che ogni installazione JDE prima o poi impara a temere — è la validazione degli output UBE JD Edwards EnterpriseOne per i test di upgrade. Il trial balance che esce diverso di un centesimo rispetto alla baseline, l’invoice register che stampa i nomi cliente in un ordine leggermente diverso, la chiusura periodo che totalizza correttamente ma rompe il feed di consolidamento downstream perché due colonne hanno scambiato posizione: questi sono gli errori che emergono tre settimane dopo l’uso in PD, quando le persone che avrebbero potuto intercettarli sono già passate al progetto successivo.
La soluzione non è più effort o più tester; la soluzione è una pipeline di confronto strutturata che esegue la stessa UBE con gli stessi input sulla vecchia release e sulla nuova release, normalizza gli output e dice al team in pochi minuti quali job sono invariati, quali differiscono per ragioni note e quali differiscono per ragioni che richiedono indagine.
Che cosa significa davvero "lo stesso output" dopo un upgrade
La prima trappola in ogni progetto di upgrade testing è trattare "stesso output" come un controllo binario. Quasi mai lo è. Un PDF UBE che nel run baseline conteneva "Run Date: 2024-09-15" nel proprio header conterrà "Run Date: 2024-09-22" nel run target, e un diff ingenuo a livello byte segnalerà ogni pagina come diversa. Lo stesso vale per l’header JOBNBR, il nome utente stampato, il nome del server incorporato nella cover page e i numeri di pagina che si spostano se una riga dati causa un ritorno a capo su un diverso confine di pagina.
Un confronto utile degli output tratta le divergenze in tre categorie. La categoria uno è attesa e ignorabile — date, numeri job, identificativi server, timestamp di generazione. La categoria due è attesa e intenzionale — modifiche che l’upgrade dovrebbe introdurre, come una nuova colonna aggiunta da un Application Update o un campo rinominato dopo uno spec merge. La categoria tre è inattesa — qualunque cosa che l’upgrade non dovrebbe toccare ma che ora risulta diversa.
L’unico compito della pipeline di validazione è spingere ogni output in una di queste tre categorie con alta confidenza. La categoria uno viene risolta tramite regole di normalizzazione applicate prima del confronto. La categoria due viene risolta tramite un registro delle modifiche note mantenuto dal team. La categoria tre è ciò che il regression report evidenzia, e ciò che il team deve effettivamente investigare.
Costruire la baseline prima che la finestra di upgrade si chiuda
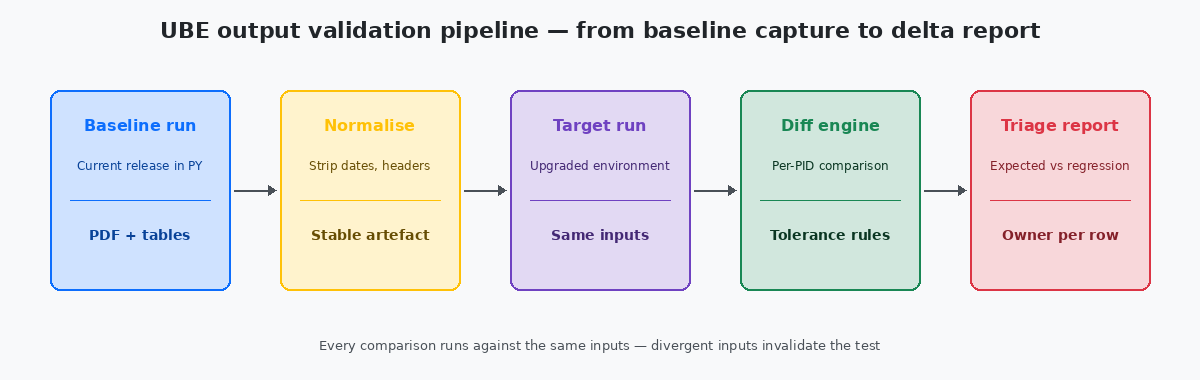
Una baseline catturata dopo che l’upgrade è già iniziato non è affatto una baseline. La prima disciplina è bloccare l’ambiente sorgente — tipicamente PYPrototype environment — il livello di test JDE in cui il codice promosso viene esercitato contro una copia dati quasi produttiva prima di essere spostato in PD. Il luogo naturale per eseguire le UBE di baseline perché i dati somigliano alla produzione. con una copia recente dei dati di produzione — ed eseguire ogni UBE in scope con input accuratamente preservati. Gli output PDF vanno in una cartella versionata; gli output tabellari, quando le UBE scrivono in tabelle F* invece di produrre solo PDF, vengono fotografati con conteggi righe, controlli di somma e un hash delle colonne rilevanti.
La lista delle UBE in scope è essa stessa un deliverable. In una tipica installazione di medie dimensioni, il catalogo UBE completo va da 300 a 700 job, ma la lista in scope per la validazione dell’upgrade è molto più piccola — i 40-80 report che il business esegue davvero regolarmente, più i report finanziari e operativi standard che guidano la chiusura periodo. La regola che applico: qualunque UBE appaia in F986110 con un run riuscito negli ultimi 90 giorni è in scope; tutto ciò che è più vecchio è dormant o sostituito da un altro meccanismo, e il team dovrebbe confermare prima di aggiungerlo.
Il set di input per ogni UBE è la parte più spesso saltata. Una UBE ha processing options, criteri di data selection e comportamento guidato dalle date. Il run baseline deve catturare tutti e tre esattamente — processing options salvate come template PO versionato, data selection serializzata in un file e data di sistema fissata tramite la data "as of" della UBE quando supportata. Senza questa disciplina, un output "diverso" tre mesi dopo può essere semplicemente un input diverso, e lo sforzo di validazione non produce alcun segnale utilizzabile.
Normalizzare gli output affinché il diff abbia significato
La normalizzazione è ciò che separa una pipeline di validazione funzionante da un generatore di rumore. La pipeline deve trasformare sia gli output baseline sia quelli target attraverso lo stesso set di regole prima di eseguire qualsiasi confronto. Le regole non sono esotiche; vengono solo trascurate regolarmente.
Per gli output PDF, la normalizzazione standard rimuove l’header della cover page, cioè run date, JOBNBR, user e server, elimina i numeri di pagina, comprime gli spazi ripetuti e sostituisce la data di sistema stampata con un token fisso ovunque compaia. Su un output regolato in cui la cover page stessa conta — registri payroll, moduli fiscali, audit report — la cover page viene esclusa dal body diff e confrontata separatamente contro un set di regole più piccolo che gli auditor accetteranno.
Per le UBE con output tabellare che scrivono su tabelle F, normalizzare significa proiettare la tabella di output sulle colonne che rappresentano davvero lo stato di business. Colonne di audit come USER, PID, JOBN, UPMJ, UPMT e TDAY vengono escluse dal diff perché differiscono sempre tra i run e non hanno significato di business in questo contesto. Le colonne rimanenti vengono ordinate in un ordine canonico prima dell’hash, così una UBE che scrive le stesse righe in una sequenza fisica diversa, cosa che può accadere dopo una modifica di indice, produce comunque lo stesso hash.
Le regole di normalizzazione vivono in un singolo file di configurazione versionato nel progetto di upgrade. Venti regole coprono circa il 90% delle UBE in una tipica installazione; di solito ne servono altre dieci per le UBE che producono output con formattazione insolita, come lettere custom, file EDI o report di calcolo payroll. Il costo di scrivere le regole si ripaga la prima volta che la pipeline gira contro una release target e il diff è leggibile invece che travolgente.
Eseguire il confronto e fare triage del diff
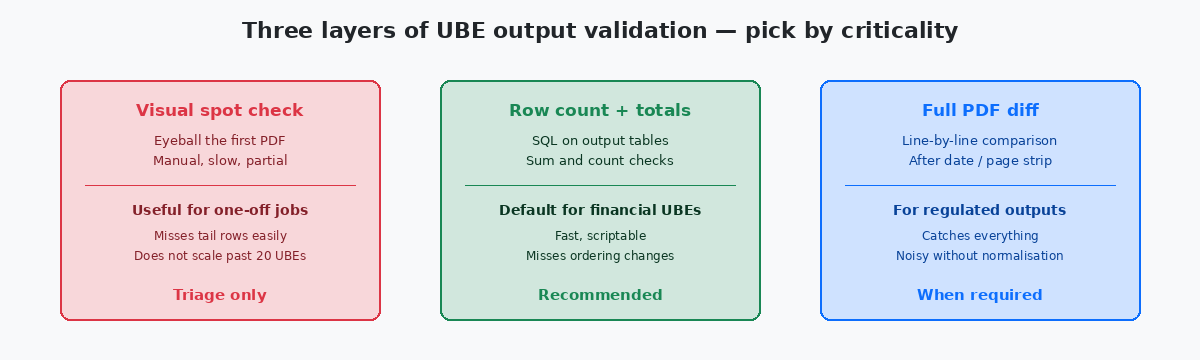
Con la baseline catturata e le regole di normalizzazione definite, il confronto vero e proprio è la parte più semplice della pipeline. Uno script — di solito 200-400 righe di Python o shell — itera la lista delle UBE in scope, recupera l’artefatto baseline per ciascuna, recupera l’artefatto target, applica la normalizzazione ed esegue il diff. L’output è un report strutturato: una riga per UBE, colonne per status (match / known-difference / regression), dimensione del diff e link alla vista side-by-side per revisione umana.
Il registro delle modifiche note è il file che mantiene significativo il report. Per ogni UBE in cui l’upgrade modifica legittimamente l’output, una voce nel registro lo dichiara, con la ragione ("Application Update 23 added column COST-CENTER to R09801 output"), e il diff per quella UBE viene marcato come known-difference invece che regression. Senza questo registro, ogni Application Update produce decine di false regressioni e il team inizia a ignorare il report — a quel punto le regressioni vere si nascondono nel rumore.
Il triage della lista di regressione avviene per criticità. Le UBE finanziarie — period close, trial balance, A/R aging, A/P proof, tax report — vengono investigate per prime e richiedono una firma nominativa da finance prima della promozione dell’upgrade. Le UBE operative — pick list, conferme spedizione, work order traveler — vengono dopo. I report interni di management arrivano ultimi; alcuni possono legittimamente essere rinviati alla settimana post-upgrade se il business lo accetta per iscritto.
Chiudere il ciclo: quando la validazione è davvero completa
Uno sforzo di validazione upgrade termina quando un documento viene firmato, non quando l’ultima UBE è stata confrontata. Il documento è un regression summary: totale delle UBE in scope, conteggio di quelle che combaciano esattamente, conteggio di quelle che combaciano dopo gli aggiustamenti per modifiche note, conteggio delle regressioni investigate e relative risoluzioni, e una lista esplicita delle UBE rinviate al follow-up post-upgrade con il business owner che ha accettato ciascun rinvio.
Le parti firmatarie non sono il team di sviluppo. Sono i business owner dei processi interessati — finance per i report finanziari, operations per quelli operativi, HR per payroll se è in scope. Il team di sviluppo prepara il documento e produce le evidenze; il business firma che accetta il risultato. Senza quella firma, la validazione è incompleta indipendentemente da quante UBE siano state confrontate.
Gli artefatti prodotti dalla pipeline — output baseline, output target, regole di normalizzazione, registro delle modifiche note, report di diff — vengono archiviati per la durata del progetto di upgrade più il tipico orizzonte di audit, di solito sette anni per gli output finanziari. Due anni dopo, quando un auditor chiede "come sapevate che R09801Post General Ledger — la UBE standard JDE che posta batch journal entries da F0911 a F0902. La UBE più validata nella maggior parte delle installazioni perché il financial reporting dipende da essa. produceva gli stessi totali di periodo prima e dopo l’upgrade?", la risposta è una cartella, non un ricordo.
L’ultima disciplina operativa è automatizzare la pipeline abbastanza da poterla rieseguire per ogni Application UpdateIl formato di delivery continuo di Oracle per JDE 9.2 che raggruppa modifiche agli oggetti standard tra i principali cicli di Tools Release. Ognuno è un mini-upgrade a sé che beneficia della stessa pipeline di validazione. cumulativo, non solo per il grande upgrade una volta ogni tre anni. Una pipeline che costa tre mesi da costruire la prima volta e una settimana da eseguire in seguito è la differenza tra un’installazione upgrade-friendly e una in cui ogni decisione di Tools Release diventa una domanda sul rischio a livello di board.
Per approfondire il territorio circostante, gli articoli correlati sui pattern di checkpoint e restart delle UBE, sullo scoping degli upgrade Tools Release e sulle strategie di archiviazione di F986110 coprono il livello operativo su cui si appoggia questa pipeline di validazione. Il portfolio dei progetti tecnici su questo sito documenta due suite di validazione in produzione che hanno prodotto i pattern descritti qui.